
参考邱神的蒲公英书
目的是用有限的资源处理更重要的信息
1 注意力的分类
聚焦式注意力:自上而下的有意识的注意力;有预定目的、依赖任务的;
基于显著性的注意力:自下而上的无意识的注意力;外界刺激驱动的,任务无关的;神经网络中的max pooling;gating都可以看成基于显著性的注意力机制;
2 注意力机制
计算步骤:在所有输入信息上计算注意力分布;根据注意力分布来计算输入信息的加权平均
2.1 注意力分布
为了从N个输入信息中选择出和某个特定任务相关的信息,需要引入一个和任务相关的表示,称为查询向量Q,并通过一个打分函数计算每个输入向量和查询向量之间的相关性。
某个输入向量n,被选中的概率可以表示为
α
n
\alpha_n
αn,具体的
α
n
=
p
(
z
=
n
∣
X
,
q
)
\alpha_n = p(z = n|X, q)
αn=p(z=n∣X,q)
=
s
o
f
t
m
a
x
(
s
(
X
n
,
q
)
)
=softmax(s(X_n, q))
=softmax(s(Xn,q))
s
(
x
,
q
)
s(x,q)
s(x,q)为打分函数,一般有与i下几种方式计算:
加性模型
s
(
x
,
q
)
=
v
T
t
a
n
h
(
W
x
,
U
q
)
s(x, q) = v^T tanh(W x, U q)
s(x,q)=vTtanh(Wx,Uq)
点积模型
s
(
x
,
q
)
=
x
T
q
s(x,q) = x^T q
s(x,q)=xTq
缩放点积模型
s
(
x
,
q
)
=
(
x
T
q
)
/
D
s(x,q) = (x^T q) / \sqrt D
s(x,q)=(xTq)/D
双线性模型
s
(
x
,
q
)
=
x
T
W
q
s(x,q) = x^T W q
s(x,q)=xTWq
W,U,v为可学习的参数,D为输入向量的维度
点积模型在D较大时,会导致较大的方差,导致softmax的梯度很小,缩放点积解决了这一问题;
双线性模型相对点积模型在计算相似度时引入了非对称性;
2.2 加权平均
注意力分布
α
n
\alpha_n
αn可以解释为在给定任务相关的查询q时,第n和输入向量受关注的程度,注意力机制对输入信息进行汇总:
a
t
t
(
X
,
q
)
=
∑
n
=
1
N
α
n
x
n
att(X, q) = \sum_{n=1}^N\alpha_n x_n
att(X,q)=n=1∑Nαnxn
=
E
z
p
(
z
∣
X
,
q
)
[
X
z
]
= E_{z~p(z|X,q)[X_z]}
=Ez p(z∣X,q)[Xz]
软性注意力机制是可微的,硬性是不可微的。
3 注意力机制的变体
3.1 键值对注意力
使用键值对格式表示输入信息,其中“健”来计算注意力分布,值用来计算聚合信息。
像用于用(k,v)替换了之前的x,k==v时,等价于普通的注意力机制。
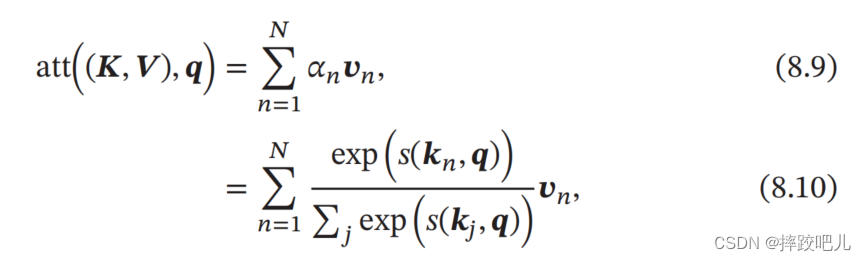
3.2 多头注意力
多头注意力(Multi-Head Attention)是利用多个查询
Q
=
[
q
1
,
⋯
,
q
M
]
Q = [q_1, ⋯ , q_M]
Q=[q1,⋯,qM],来并行地从输入信息中选取多组信息.每个注意力关注输入信息的不同部分。
自注意力模型
基于CNN或者RNN的编码都是局部的编码方式,建模了局部依赖关系,全连接网络可以直接建模远连接依赖,但无法处理变长输入,可以利用注意力机制动态生成不同连接的权重,即自注意力模型。
为了提高模型能力,自注意力机制经常采用QKV的模型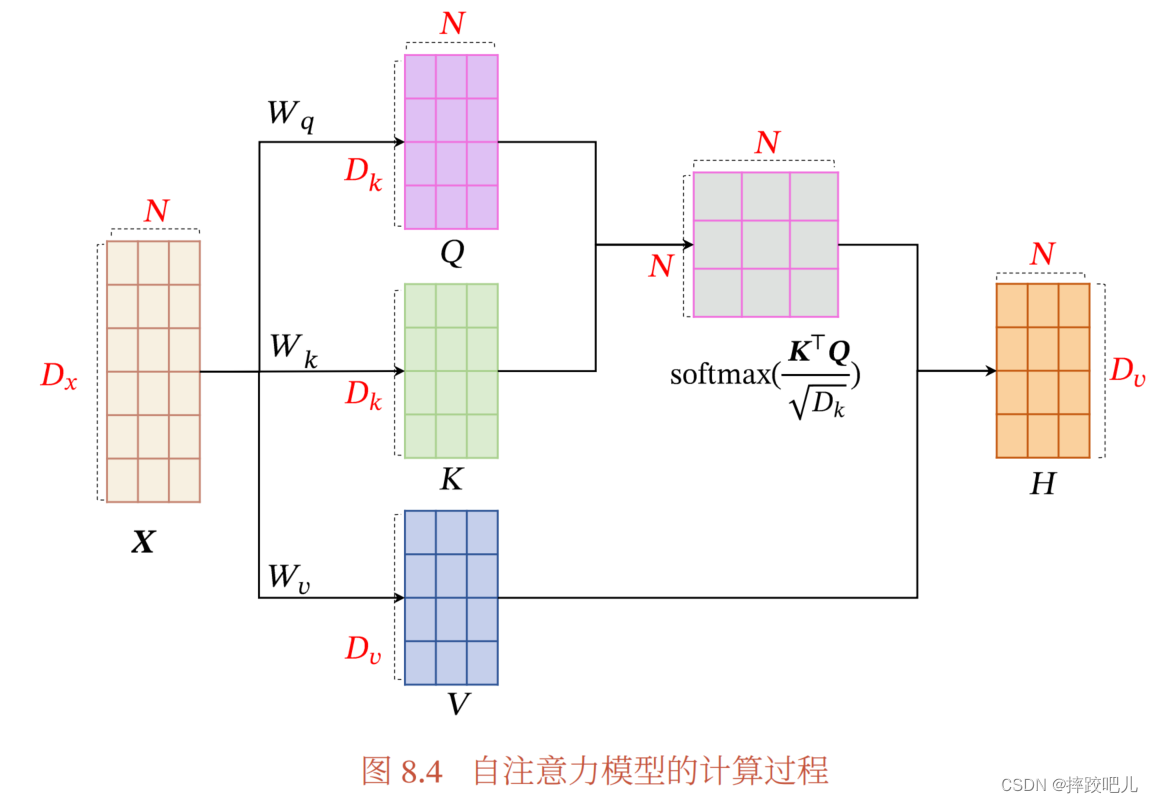
h
n
=
a
t
t
(
(
K
,
V
)
,
q
n
)
h_n = att((K,V), q_n)
hn=att((K,V),qn)
=
∑
j
=
1
N
α
n
j
v
j
= \sum^N_{j=1} \alpha_{nj}v_{j}
=j=1∑Nαnjvj
=
∑
j
=
1
N
s
o
f
t
m
a
x
(
s
(
k
j
,
q
n
)
)
v
j
=\sum_{j=1}^{N} softmax(s(k_j,q_n))v_j
=j=1∑Nsoftmax(s(kj,qn))vj
自注意力模型可以作为神经网络中的一层来使用,既可以用来替换卷积层和循环层,也可以和它们一起交替使用(比如 𝑿 可以是卷积层或循环层的输出).自注意力模型计算的权重𝛼𝑖𝑗 只依赖于
q
i
q_i
qi 和
k
j
k_j
kj 的相关性, 而忽略了输入信息的位置信息.因此在单独使用时,自注意力模型一般需要加入位置编码信息来进行修正.自注意力模型可以扩展为多头自注意力(Multi-Head Self-Attention)模型,在多个不同的投影空间中捕捉不同的交互信息.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/133479.html

