
链接: stream.
链接: 浅谈 jdk 中的 Stream 流使用及原理.
链接: stream流排序.
链接: Java 8 Steam API map和flatMap方法使用详解.
前提了解
lambda表达式、链式编程、函数式接口
函数式接口:只有一个方法的接口
- Function函数式接口 传入参数T 返回参数R
- 断定型接口:有一个输入参数,返回值只能是 布尔值
- Consumer 消费型接口 只有输入 没有返回值
- Supplier 供给型接口 没用输入,只有返回值
为什么要使用stream
- Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。
- 能大大减轻数据库的压力,数据库专注于存储,计算交由程序处理
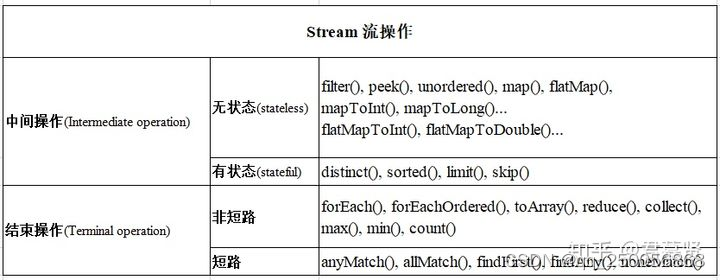

简单解释一下表格中加粗字体的含义:
- 中间操作:从字面上看是流从开始到结束中间的一环,从操作结果上看是上一个流经过中间操作生成了下一个流,从代码上看实际上是生成了一个个 stage 和 sink节点,至于 sink 节点是什么,后面的篇幅会分析
- 结束操作:和中间操作相反,结束操作之后是流的最后一个环节,不再生成新的流,从代码上看是启动整个 sink 节点从头开始运行
- 有状态:简单理解就是需要获取流中所有数据之后才能进行的操作,比如 sort 排序,肯定要获取了所有的元素之后才能排序
- 无状态:不需要获取所有元素,只需要对单个元素进行的操作,比如 filter 过滤,只针对每一个元素本身所做的操作
- 短路:终结操作中只要有一个元素可以得到操作结果的数据,比如 findAnyMatch,只要有一个节点满足筛选条件就会返回 true
- 非短路:需要遍历所有的节点才能得到预期结果,比如 forEach、max
使用时注意处理空指针异常
数据准备
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
public class Test {
public static List<User> init() {
List<User> userList = new ArrayList<User>();
userList.add(new User(1, "小a", "男", 32, BigDecimal.valueOf(1600)));
userList.add(new User(2, "小b", "男", 30, BigDecimal.valueOf(1800)));
userList.add(new User(3, "小c", "女", 20, BigDecimal.valueOf(1700)));
userList.add(new User(4, "小d", "男", 38, BigDecimal.valueOf(1500)));
userList.add(new User(5, "小e", "女", 25, BigDecimal.valueOf(1200)));
return userList;
}
public static void main(String[] args) {
List<User> list = Test.init();
}
}
常用API
Java8 根据对象某个属性值合并list
List<V> list = new ArrayList<>(tdwjcwphcqktj1.stream()
.collect(Collectors.toMap(V::getCode, a -> a, this::mergeObject)).values());
/**
* 合并对象
*
* @param o1
* @param o2
* @return o1
*/
private T mergeObject(T o1, T o2) {
o1.setYhczs(o1.getYhczs().add(o2.getYhczs()));
return o1;
}
Java8 根据对象某个属性值去重
List<LzgdJdjcPlthDTO> uniqueSkuValues = all.stream().collect(
Collectors.collectingAndThen(Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(o -> o.getJcbh()))), ArrayList::new)
);
list过滤
list.removeIf(o -> "小a".equals(o.getName()));
forEach()
list.forEach(System.out::println);
filter(T -> boolean) 过滤列表数据
list.stream().filter(o -> o.getUserId()!=null && o.getUserId() == 1)
.collect(Collectors.toList());
findAny() 和 findFirst() 获取第一条数据
搭配 filter 操作可实现 selectOne()
注意: 建议使用主键id查找,findFirst() 和 findAny() 都是获取列表中的第一条数据,但是findAny()操作,返回的元素是不确定的,对于同一个列表多次调用findAny()有可能会返回不同的值。使用findAny()是为了更高效的性能。如果是数据较少,串行地情况下,一般会返回第一个结果,如果是并行(parallelStream并行流)的情况,那就不能确保是第一个。
User user = list.stream()
.findFirst().orElse(null);
System.out.println(user);
User user1 = list.stream()
.filter(o -> o.getUserId() != null && o.getUserId() == 5)
.findAny().orElse(null);
System.out.println(user1);
map(T -> R)
使用 map() 将流中的每一个元素 T 映射为 R(类似类型转换)
List<Integer> collect = list.stream()
.map(User::getUserId).collect(Collectors.toList());
System.out.println(collect);
flatMap(T -> Stream)
使用 flatMap() 将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流
多重集合 嵌套时有妙用
//创建城市
List<List<String>> cityList = new ArrayList<>();
List<String> cityList1 = new ArrayList<String>();
cityList1.add("福州");
cityList1.add("宁德");
List<String> cityList2 = new ArrayList<String>();
cityList2.add("深圳");
cityList2.add("广州");
cityList.add(cityList1);
cityList.add(cityList2);
List<String> collect = cityList.stream()
.flatMap(it -> it.stream())
.collect(Collectors.toList());
System.out.println(collect);
distinct()
使用 distinct() 方法可以去除重复的数据
List<String> cityList = new ArrayList<String>();
cityList.add("福州");
cityList.add("宁德");
cityList.add("宁德");
List<String> collect = cityList.stream().distinct().collect(Collectors.toList());
System.out.println(collect);
// 根据对象的某个属性值 或 多个
List<ZbglXzpgDataTableVo> cbList = tableList
.stream()
.collect(
Collectors.collectingAndThen(
Collectors.toCollection(
() -> new TreeSet<>(
Comparator.comparing(
tc -> tc.getKey()))), ArrayList::new));
limit(long n) 和 skip(long n)
limit(long n) 方法用于返回前n条数据,skip(long n) 方法用于跳过前n条数据
List<User> collect = list.stream().limit(1).collect(Collectors.toList());
System.out.println(collect);
anyMatch(T -> boolean)
使用 anyMatch(T -> boolean) 判断流中是否有一个元素匹配给定的 T -> boolean 条件。
boolean b = list.stream().anyMatch(o -> o.getUserId().equals(1));
System.out.println(b);
allMatch(T -> boolean)
使用 allMatch(T -> boolean) 判断流中是否所有元素都匹配给定的 T -> boolean 条件。
boolean b = list.stream().allMatch(o -> o.getUserId().equals(1));
System.out.println(b);
noneMatch(T -> boolean)
使用 noneMatch(T -> boolean) 流中是否没有元素匹配给定的 T -> boolean 条件。
boolean b = list.stream()
.filter(o -> o!=null && o.getUserId()!=null)
.noneMatch(o -> o.getUserId().equals(10));
System.out.println(b);
reduce 用于组合流中的元素,如求和,求积,求最大值等
mapToInt(T -> int) 、
mapToDouble(T -> double) 、
mapToLong(T -> long)
//用户列表中年龄的最大值、最小值、总和 注意空值处理
int maxVal = list.stream().map(User::getAge).filter(Objects::nonNull).reduce(Integer::max).get();
int minVal = list.stream().map(User::getAge).filter(Objects::nonNull).reduce(Integer::min).get();
int sumVal = list.stream().map(User::getAge).filter(Objects::nonNull).reduce(0,Integer::sum);
System.out.println(maxVal);
System.out.println(minVal);
System.out.println(sumVal);
使用 count() 可以对列表数据进行统计
long count = list.stream().filter(o -> {
String gender = Optional.ofNullable(o)
.map(User::getGender)
.orElse("");
return "男".equals(gender);
}
).count();
System.out.println(count);
averagingInt()、averagingLong()、averagingDouble()
double aveAge = list.stream().collect(Collectors.averagingDouble(User::getAge));
System.out.println(aveAge);
summarizingInt()、summarizingLong()、summarizingDouble()
IntSummaryStatistics类提供了用于计算的平均值、总数、最大值、最小值、总和等方法
//获取IntSummaryStatistics对象
IntSummaryStatistics ageStatistics = list.stream().collect(Collectors.summarizingInt(User::getAge));
//统计:最大值、最小值、总和、平均值、总数
System.out.println("最大年龄:" + ageStatistics.getMax());
System.out.println("最小年龄:" + ageStatistics.getMin());
System.out.println("年龄总和:" + ageStatistics.getSum());
System.out.println("平均年龄:" + ageStatistics.getAverage());
System.out.println("员工总数:" + ageStatistics.getCount());
BigDecimal类型的统计
reduce是一个终结操作,它能够通过某一个方法,对元素进行削减操作。
该操作的结果会放在一个Optional变量里返回。
可以利用它来实现很多聚合方法比如count,max,min等。
T reduce(T identity, BinaryOperator accumulator);
第一个参数是我们给出的初值,第二个参数是累加器,可以自己用实现接口完 成想要的操作,这里使用Bigdecimal的add方法 最后reduce会返回计算后的结果
BigDecimal result2 = list.stream().map(User::getAnnualIncome)
.filter(Objects::nonNull).reduce(BigDecimal.ZERO,BigDecimal::add);
System.out.println(result2);
排序方法
sorted() / sorted((T, T) -> int)
空值处理
List<CczgResult> collect = list.stream()
.sorted(Comparator.comparing(CczgResult::getName2)
.thenComparing(CczgResult::getName4, Comparator.nullsFirst(String::compareTo))
.thenComparing(CczgResult::getName6, Comparator.nullsFirst(String::compareTo))
).collect(Collectors.toList());
字符串 转数值排序
rwjdDtos.stream().sorted(Comparator.comparing(RwjdDto::getTpcode, Comparator.comparingInt(Integer::parseInt))) .collect(Collectors.toList());
list.stream().sorted((o1, o2)->o1.getItem().getValue().compareTo(o2.getItem().getValue())).
collect(Collectors.toList());
// 对象集合以类属性一升序排序
list.stream().sorted(Comparator.comparing(类::属性一));
// 对象集合以类属性一降序排序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed());//先以属性一升序,结果进行属性一降序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()));//以属性一降序
// 对象集合以类属性一升序 属性二升序
list.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二));
// 对象集合以类属性一降序 属性二升序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二));//先以属性一升序,升序结果进行属性一降序,再进行属性二升序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二));//先以属性一降序,再进行属性二升序
// 对象集合以类属性一降序 属性二降序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一升序,升序结果进行属性一降序,再进行属性二降序
list.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一降序,再进行属性二降序
// 对象集合以类属性一升序 属性二降序 注意两种写法
list.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二).reversed());//先以属性一升序,升序结果进行属性一降序,再进行属性二升序,结果进行属性一降序属性二降序
list.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一升序,再进行属性二降序
- Comparator.comparing(类::属性一).reversed(); 得到排序结果后再排序
- Comparator.comparing(类::属性一,Comparator.reverseOrder()); 直接进行排序
很多人会混淆导致理解出错,2更好理解,建议使用2
集合转换
list转list
list = list.stream().map(o-> {
VipInfoSear vipInfoSear = new VipInfoSear();
vipInfoSear.setId(o.getId());
return vipInfoSear;
}).collect(Collectors.toList());
List转map
// 一对多转换
Map<String, List<User>> userMapGroupByGender = list.stream().collect(
Collectors.groupingBy(User::getGender));
// 一对一转换
Map<Integer, User> userMapGroupByUserId = list.stream().collect(
Collectors.toMap(User::getUserId, o -> o));
// 一对一属性转换
Map<Integer, String> map = list.stream().collect(
Collectors.toMap(User::getUserId, User::getName));
分组
分组 注意空值处理
lisrt.stream()
.filter(t-> StringUtils.isNotBlank(t.getName12()))
.collect(Collectors.groupingBy(CczgResult::getName12));
分组多条件统计
Map<String, Long> countMap = records.stream().collect(Collectors.groupingBy(o -> o.getProductType() + "_" + o.getCountry(), Collectors.counting()));
List<Record> countRecords = countMap.keySet().stream().map(key -> {
String[] temp = key.split("_");
String productType = temp[0];
String country = temp[1];
Record record = new Record();
record.set("device_type", productType);
record.set("location", country;
record.set("count", countMap.get(key).intValue());
return record;
}).collect(Collectors.toList());
未完持续更新中~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/133909.html

