
MyCat2分库分表的基本操作
分库分表概念
分库
分库又分为:水平分库与垂直分库
水平分库:把同一个表的数据按一定规则拆到不同的数据库中
垂直分库:按照业务、功能模块将表进行分类,不同功能模块对应的表分到不同的库中
分库原则:将紧密关联关系的表划分在一个库里,没有关联关系的表可以分到不同的库里
分表
分表又分为:水平分表与垂直分表
水平分表:在同一个数据库内,把同一个表的数据按一定规则拆到多个表中
垂直分表:将一个表按照字段分成多表,每个表存储其中一部分字段
分表原则:减少节点数据库的访问,分表字段尤为重要,其决定了节点数据库的访问量。
实现分库分表
添加数据源
登录Mycat,添加数据源
准备MySqL1,作为写数据源同时也作为读数据源:
写:
/*+ mycat:createDataSource{ "name":"write1","url":"jdbc:mysql://IP:3306/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"mycat","password":"123456" } */;
读:
/*+ mycat:createDataSource{ "name":"red1","url":"jdbc:mysql://IP:3306/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"mycat","password":"123456" } */;
准备MySqL2,作为写数据源同时也作为读数据源:
写:
/*+ mycat:createDataSource{ "name":"write2","url":"jdbc:mysql://IP:3307/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;
读:
/*+ mycat:createDataSource{ "name":"red2","url":"jdbc:mysql://IP:3307/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;
查询配置数据源结果
/*+ mycat:showDataSources{} */;

通过注释命名添加数据源后,在对应目录会生成相关配置文件,查看数据源配置文件:mycat/conf/datasources
[root@administrator mycat]# ls conf/datasources
prototypeDs.datasource.json red2.datasource.json write2.datasource.json
red1.datasource.json write1.datasource.json
添加集群配置
登录Mycat,把新添加的数据源配置成集群
注意:
HASH型分片算法默认要求集群名字以
c为前缀数字为后缀,c0就是分片表第一个节点,c1就是第二个节点,以此类推。
添加集群:c0
/*! mycat:createCluster{"name":"c0","masters":["write1"],"replicas":["red1"]} */;
添加集群:c1
/*! mycat:createCluster{"name":"c1","masters":["write2"],"replicas":["red2"]} */;
查看集群配置信息
/*+ mycat:showClusters{} */;

查看集群配置文件
[root@administrator clusters]# ls
cluster1.cluster.json cluster2.cluster.json prototype.cluster.json
查看集群:c0
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"write1"
],
"maxCon":2000,
"name":"c0",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"red1"
],
"switchType":"SWITCH"
}
查看集群:c1
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"write2"
],
"maxCon":2000,
"name":"c1",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"red2"
],
"switchType":"SWITCH"
}
进行分库分表
登录Mycat,运行建表语句进行数据分片
CREATE TABLE user (
id BIGINT NOT NULL AUTO_INCREMENT,
`name` VARCHAR ( 15 ) DEFAULT NULL,
age INT,
type INT,
PRIMARY KEY ( id ),
KEY `id` ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8 dbpartition BY mod_hash ( type ) tbpartition BY mod_hash ( id ) tbpartitions 1 dbpartitions 2 ;
插入数据
INSERT INTO mydb.`user`(id,name,age,type)VALUES(1,'mycat1',10,1);
INSERT INTO mydb.`user`(id,name,age,type)VALUES(2,'mycat2',20,2);
INSERT INTO mydb.`user`(id,name,age,type)VALUES(3,'mycat3',30,1);
INSERT INTO mydb.`user`(id,name,age,type)VALUES(4,'mycat4',40,2);
dbpartition:数据库分片规则
tbpartition :表分片规则
mod_hash :分片规则
tbpartitions 1 dbpartitions 2:创建2个库且每个库各创建1个分片表
分片算法mod_hash
分片规则
mod_hash具有如下特点:
1.当分库键和分表键是同一个键:
分表下标=分片值%(分库数量*分表数量)
分库下标=分表下标/分表数量
2.当分库键和分表键是不同键:
分表下标= 分片值%分表数量
分库下标= 分片值%分库数量
由于使用mod_hash分片规则,且分库键和分表键是不同键,故
分表下表:
1%1=0;2%1=0;3%1=0;4%1=0;
分库下标:
1%2=1; 2%2=0;
查看schema:/mycat/conf/schemas/mydb.schema.json,生成配置信息如下
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"mydb",
"shardingTables":{
"user":{
"createTableSQL":"CREATE TABLE `mydb`.user (\n\tid BIGINT NOT NULL AUTO_INCREMENT,\n\t`name` VARCHAR(15) DEFAULT NULL,\n\tage INT,\n\ttype INT,\n\tPRIMARY KEY (id),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(type) DBPARTITIONS 2\nTBPARTITION BY mod_hash(id) TBPARTITIONS 1",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/mydb_${dbIndex}/user_${tableIndex}",
"tableNum":"1",
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(type)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}
登录:mysql -u root -h IP -P 3306 -p
mysql> use mydb_0;
Database changed
mysql> select * from user_0;
+----+--------+------+------+
| id | name | age | type |
+----+--------+------+------+
| 2 | mycat2 | 20 | 2 |
| 4 | mycat4 | 40 | 2 |
+----+--------+------+------+
2 rows in set (0.00 sec)
mysql>
登录:mysql -u root -h IP -P 3308 -p
mysql> use mydb_1;
Database changed
mysql> select * from user_0;
+----+--------+------+------+
| id | name | age | type |
+----+--------+------+------+
| 1 | mycat1 | 10 | 1 |
| 3 | mycat3 | 30 | 1 |
+----+--------+------+------+
2 rows in set (0.00 sec)
mysql>
登录MyCat:mysql -u root -h IP -P 8066 -p
mysql> use mydb;
Database changed
mysql> select * from user;
+----+--------+------+------+
| id | name | age | type |
+----+--------+------+------+
| 1 | mycat1 | 10 | 1 |
| 3 | mycat3 | 30 | 1 |
| 2 | mycat2 | 20 | 2 |
| 4 | mycat4 | 40 | 2 |
+----+--------+------+------+
4 rows in set (0.04 sec)
mysql>
创建RER表
mycat2在涉及这两个表的join分片字段等价关系的时候可以完成join的下推
mycat2无需指定ER表,是自动识别的,具体看分片算法的接口
登录Mycat,创建RER表
CREATE TABLE user_xq (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`name` VARCHAR ( 20 ) DEFAULT NULL,
user_id INT,
PRIMARY KEY ( id ) ,
KEY `id` ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8 dbpartition BY mod_hash ( id ) tbpartition BY mod_hash ( user_id ) tbpartitions 1 dbpartitions 2;
插入数据
INSERT INTO user_xq(id,name,user_id) VALUES(1,'xq1',1);
INSERT INTO user_xq(id,name,user_id) VALUES(2,'xq2',2);
INSERT INTO user_xq(id,name,user_id) VALUES(3,'xq3',3);
INSERT INTO user_xq(id,name,user_id) VALUES(4,'xq4',4);
登录MySQL1
mysql> select * from user_xq_0;
+----+------+---------+
| id | name | user_id |
+----+------+---------+
| 2 | xq2 | 2 |
| 4 | xq4 | 4 |
+----+------+---------+
2 rows in set (0.00 sec)
登录MySQL2
mysql> select * from user_xq_0;
+----+------+---------+
| id | name | user_id |
+----+------+---------+
| 1 | xq1 | 1 |
| 3 | xq3 | 3 |
+----+------+---------+
2 rows in set (0.00 sec)
登录MyCat:mysql -u root -h IP -P 8066 -p
mysql> select * from user_xq;
+----+------+---------+
| id | name | user_id |
+----+------+---------+
| 1 | xq1 | 1 |
| 3 | xq3 | 3 |
| 2 | xq2 | 2 |
| 4 | xq4 | 4 |
+----+------+---------+
4 rows in set (0.04 sec)
查看配置的表是否具有ER关系,使用/*+ mycat:showErGroup{}*/查看
group_id表示相同的组,该组中的表具有相同的存储分布,即可以关联查询
mysql> /*+ mycat:showErGroup{}*/;
+---------+------------+-----------+
| groupId | schemaName | tableName |
+---------+------------+-----------+
| 0 | mydb | user |
| 0 | mydb | user_xq |
+---------+------------+-----------+
2 rows in set (0.00 sec)
关联查询
mysql> SELECT * FROM user a INNER JOIN user_xq b ON a.id=b.user_id;
+----+--------+------+------+-----+-------+---------+
| id | name | age | type | id0 | name0 | user_id |
+----+--------+------+------+-----+-------+---------+
| 1 | mycat1 | 10 | 1 | 1 | xq1 | 1 |
| 2 | mycat2 | 20 | 2 | 2 | xq2 | 2 |
| 3 | mycat3 | 30 | 1 | 3 | xq3 | 3 |
| 4 | mycat4 | 40 | 2 | 4 | xq4 | 4 |
+----+--------+------+------+-----+-------+---------+
4 rows in set (0.04 sec)
创建广播表
广播表又称全局表,只需要在建表语句中加上关键字
BROADCAST即可
添加数据库mydb
CREATE DATABASE mydb;
创建广播表
CREATE TABLE mydb.`team` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;
查看schema配置,自动生成广播表配置信息
{
"customTables":{},
"globalTables":{
"team":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE mydb.`team` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`name` varchar(50) DEFAULT NULL,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"mydb",
"shardingTables":{},
"views":{}
}
分片算法
详细参考:MyCat2官网文档
分片算法概述
HASH型分片算法默认要求集群名字以
c为前缀数字为后缀,c0就是分片表第一个节点,c1就是第二个节点,以此类推。该命名规则允许手动改变。
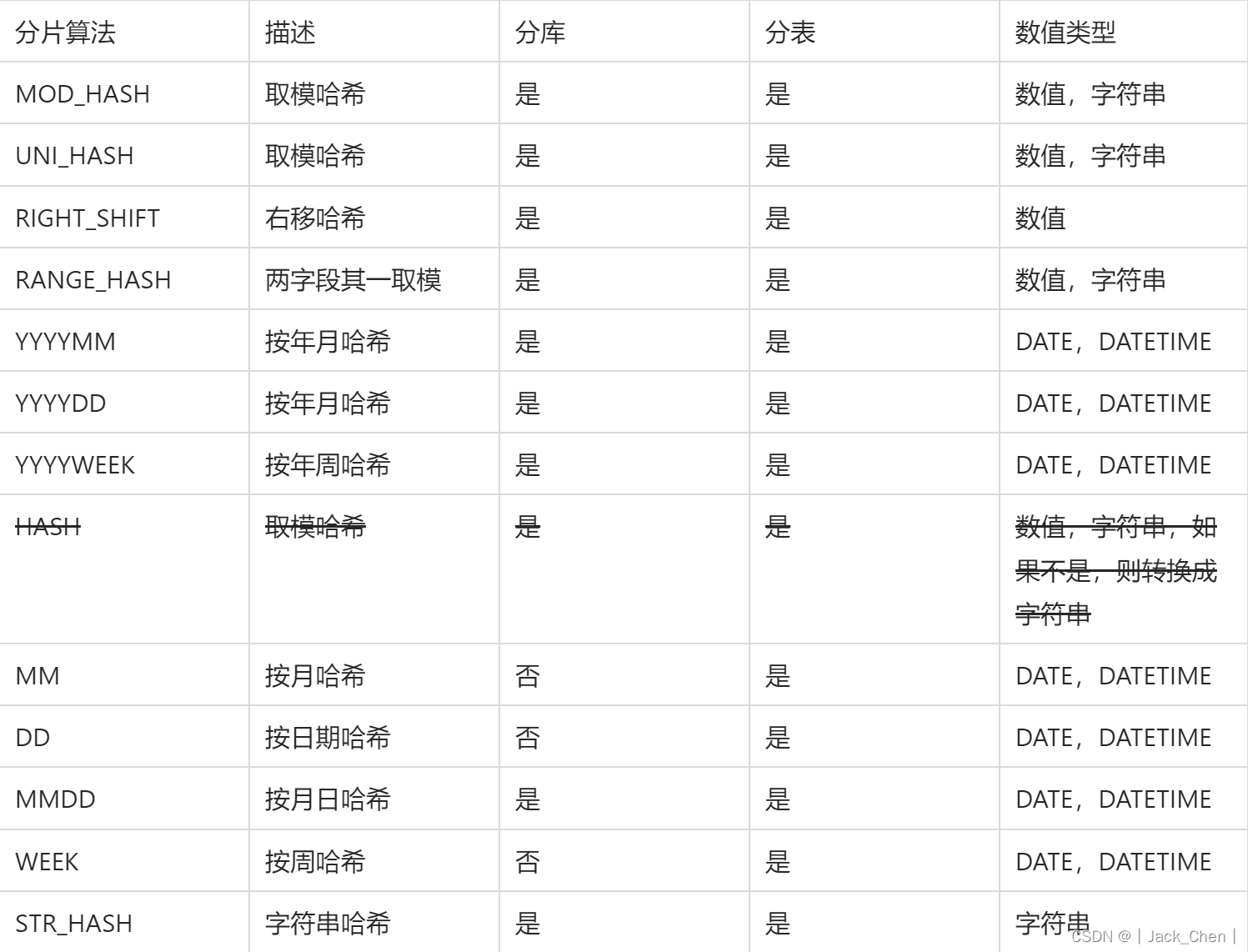
常用分片规则
详细参考:分片算法
1.MOD_HASH
如果分片值是字符串则先对字符串进行hash转换为数值类型
1.分库键和分表键是同1个键
分表下标=分片值%(分库数量*分表数量)
分库下标=分表下标/分表数量
2.分库键和分表键是不同键
分表下标= 分片值%分表数量
分库下标= 分片值%分库数量
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by MOD_HASH (id) dbpartitions 6
tbpartition by MOD_HASH (id) tbpartitions 6;
2.RIGHT_SHIFT
RANGE_HASH(字段1, 字段2, 截取开始下标)
仅支持数值类型,字符串类型,分片值右移二进制位数,然后按分片数量取余
当字符串类型时候,第三个参数生效,根据下标截取其后部分字符串(截取下标不能少于实际值的长度),然后该字符串hash成数值
两个字段的数值类型要求一致
create table travelrecord(
...
)ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by RANGE_HASH(id,user_id,3) dbpartitions 3
tbpartition by RANGE_HASH(id,user_id,3) tbpartitions 3;
3.RIGHT_SHIFT
RIGHT_SHIFT(字段名,位移数)
仅支持数值类型
分片值右移二进制位数,然后按分片数量取余
create table travelrecord(
...
)ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by RIGHT_SHIFT(id,4) dbpartitions 3
tbpartition by RIGHT_SHIFT(user_id,4) tbpartitions 3;
4.YYYYDD
(YYYY*366+DD)%分库数
仅用于分库,DD是一年之中的天数
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYMM(xxx) dbpartitions 8
tbpartition by xxx(xxx) tbpartitions 12;
5.YYYYMM
(YYYY*12+MM)%分库数
仅用于分库,MM是1-12
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYMM(xxx) dbpartitions 8
tbpartition by xxx(xx) tbpartitions 12;
6.MMDD
仅用于分表,仅DATE/DATETIME适用
一年之中第几天%分表数,tbpartitions 不超过 366
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by xxx(xx) dbpartitions 8
tbpartition by MMDD(xx) tbpartitions 366;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/136920.html

