
Java操作HBase API
添加依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.5</version>
</dependency>
<!--java.lang.NoSuchMethodError: 'void org.apache.hadoop.security.HadoopKerberosName.setRuleMechanism(java.lang.String)'-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
</dependencies>
添加配置文件
添加Hadoop和HBase的配置文件到项目Resources目录
core-site.xml
hbase-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
初始化与资源释放
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HelloHBaseDDL {
/**
* 获取HBase管理员类
*/
private Admin admin;
/**
* 获取数据库连接
*/
private Connection connection;
/**
* 初始化
*
* @throws IOException
*/
@Before
public void init() throws IOException {
Configuration configuration = HBaseConfiguration.create();
this.connection = ConnectionFactory.createConnection(configuration);
this.admin = connection.getAdmin();
}
/**
* 资源释放
*/
@After
public void destory() throws IOException {
if (admin != null) {
admin.close();
}
if (connection != null) {
connection.close();
}
}
}
创建命名空间
@Test
public void createNameSpace() throws IOException {
NamespaceDescriptor mkNameSpace = NamespaceDescriptor.create("hbaseNamespace").build();
this.admin.createNamespace(mkNameSpace);
}
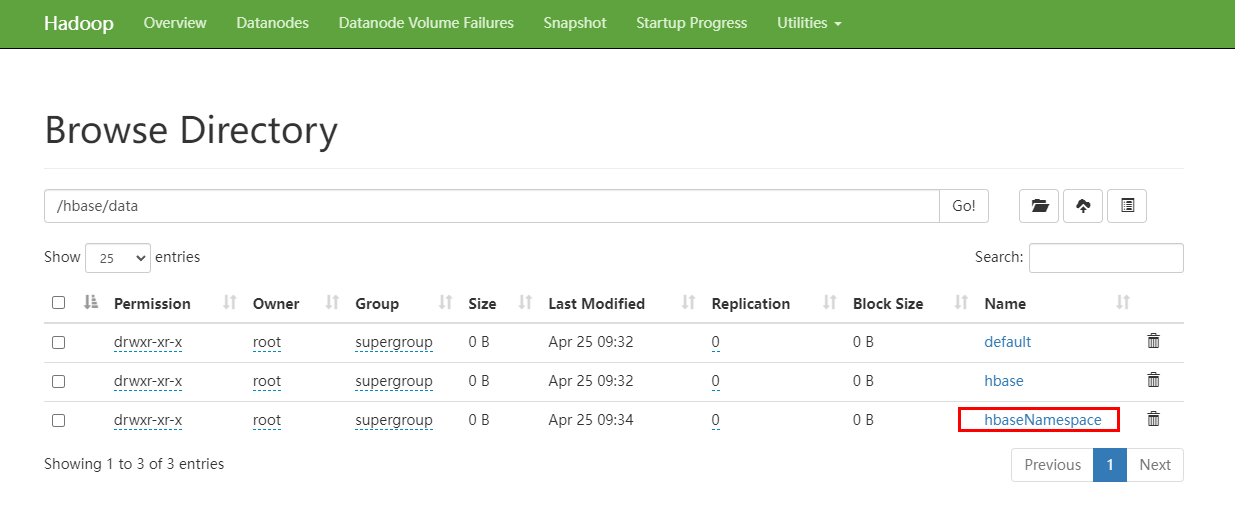
指定名称空间创建多列族的表
@Test
public void createMultiPartColumnFamilyTable() throws IOException {
TableDescriptorBuilder table = TableDescriptorBuilder.newBuilder(TableName.valueOf("hbaseNamespace:user"));
ColumnFamilyDescriptorBuilder infoCF = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
ColumnFamilyDescriptorBuilder scoreCF = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("score"));
List<ColumnFamilyDescriptor> columnFamilyDescriptors = new ArrayList<>();
columnFamilyDescriptors.add(infoCF.build());
columnFamilyDescriptors.add(scoreCF.build());
table.setColumnFamilies(columnFamilyDescriptors);
admin.createTable(table.build());
}
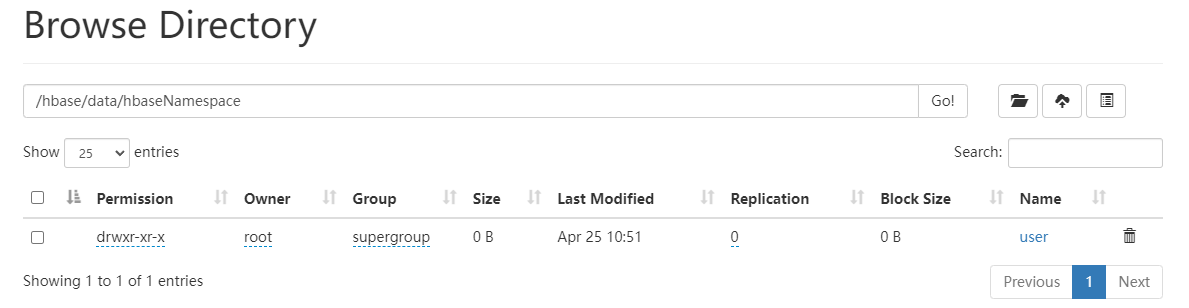
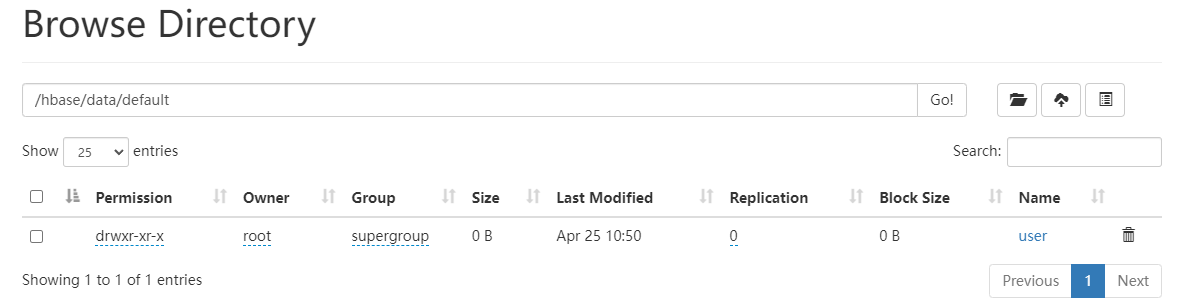
默认名称空间创建单列族的表
@Test
public void createOneColumnFamilyTable() throws IOException {
TableDescriptorBuilder table = TableDescriptorBuilder.newBuilder(TableName.valueOf("user"));
ColumnFamilyDescriptorBuilder columnBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
ColumnFamilyDescriptor familyDescriptor = columnBuilder.build();
table.setColumnFamily(familyDescriptor);
admin.createTable(table.build());
}
查询所有表信息
@Test
public void listTables() throws IOException {
TableName[] tableNames = admin.listTableNames();
for (TableName tableName : tableNames) {
System.out.println("tableName:" + tableName);
}
}
tableName:user
tableName:hbaseNamespace:user
列出指定命名空间的表信息
@Test
public void listTablesByNameSpace() throws IOException {
TableName[] tableNames = admin.listTableNamesByNamespace("hbaseNamespace");
for (TableName tableName : tableNames) {
System.out.println("tableName:" + tableName);
}
}
tableName:hbaseNamespace:user
添加数据
@Test
public void putOneRowData() throws IOException {
Table table = this.connection.getTable(TableName.valueOf("hbaseNamespace:user"));
Put put = new Put(Bytes.toBytes("rowKey001"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("hbase01"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(20));
put.addColumn(Bytes.toBytes("score"), Bytes.toBytes("biological"), Bytes.toBytes(95));
put.addColumn(Bytes.toBytes("score"), Bytes.toBytes("chemistry"), Bytes.toBytes(96));
table.put(put);
table.close();
}
hbase(main):003:0> scan 'hbaseNamespace:user'
ROW COLUMN+CELL
rowKey001 column=info:age, timestamp=1650856127976, value=\x00\x00\x
00\x14
rowKey001 column=info:name, timestamp=1650856127976, value=hbase01
rowKey001 column=score:biological, timestamp=1650856127976, value=\x
00\x00\x00a
rowKey001 column=score:chemistry, timestamp=1650856127976, value=\x0
0\x00\x00`
1 row(s)
Took 0.0220 seconds
批量添加数据
@Test
public void putMoreRowData() throws IOException {
Table table = this.connection.getTable(TableName.valueOf("hbaseNamespace:user"));
List<Put> puts = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
Put put = new Put(Bytes.toBytes("rowKey00" + i));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("hbase01"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(20));
put.addColumn(Bytes.toBytes("score"), Bytes.toBytes("chemistry"), Bytes.toBytes(80+i));
put.addColumn(Bytes.toBytes("score"), Bytes.toBytes("biological"), Bytes.toBytes(80+i));
puts.add(put);
}
table.put(puts);
table.close();
}
hbase(main):007:0> count 'hbaseNamespace:user'
10 row(s)
Took 0.0450 seconds
=> 10
删除数据
@Test
public void deleteRowData() throws IOException {
Table table = this.connection.getTable(TableName.valueOf("hbaseNamespace:user"));
Delete delete = new Delete("rowKey001".getBytes());
table.delete(delete);
table.close();
}
hbase(main):008:0> count 'hbaseNamespace:user'
9 row(s)
Took 0.0060 seconds
=> 9
根据rowKey获取一行数据及获取列信息
@Test
public void getRowData() throws IOException {
Get get = new Get(Bytes.toBytes("rowKey002"));
Result rs = table.get(get);
Cell[] cells = rs.rawCells();
for (Cell cell : cells) {
String columnName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
String columnValue = null;
if (columnName.equals("name")) {
columnValue = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
} else {
int result = Bytes.toInt(cell.getValueArray());
columnValue = Integer.toString(result);
}
System.out.println("columnName:" + columnName + " columnValue:" + columnValue);
}
}
columnName:age columnValue:28
columnName:name columnValue:hbase01
columnName:biological columnValue:36
columnName:chemistry columnValue:35
获取多行数据
@Test
public void getRowDataList() throws IOException {
List<Get> gets = new ArrayList<>();
gets.add(new Get(Bytes.toBytes("rowKey002")));
gets.add(new Get(Bytes.toBytes("rowKey003")));
Result[] rs = table.get(gets);
for (Result r : rs) {
Cell[] cells = r.rawCells();
for (Cell c : cells) {
String columnName = Bytes.toString(c.getQualifierArray(), c.getQualifierOffset(), c.getQualifierLength());
String columnValue = null;
if (columnName.equals("name")) {
columnValue = Bytes.toString(c.getValueArray(), c.getValueOffset(), c.getValueLength());
} else {
int result = Bytes.toInt(c.getValueArray());
columnValue = Integer.toString(result);
}
System.out.println("columnName:" + columnName + " columnValue:" + columnValue);
}
}
}
columnName:age columnValue:28
columnName:name columnValue:hbase01
columnName:biological columnValue:36
columnName:chemistry columnValue:35
columnName:age columnValue:28
columnName:name columnValue:hbase01
columnName:biological columnValue:36
columnName:chemistry columnValue:35
扫描整个表空间
@Test
public void scanWholeTable() throws IOException {
//创建扫描对象
Scan scan = new Scan();
// 扫描开始的rowkey
scan.withStartRow(Bytes.toBytes("rowKey003"));
// 扫描停止的rowkey
scan.withStopRow(Bytes.toBytes("rowKey006"));
//设置扫描的列
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
// 正则表达式过滤器
Filter filter1 = new RowFilter(CompareOperator.EQUAL, new RegexStringComparator(".*01$"));
// 子字符串过滤器
Filter filter2 = new RowFilter(CompareOperator.EQUAL, new SubstringComparator("03"));
// 二进制前缀过滤器
Filter filter3 = new RowFilter(CompareOperator.EQUAL, new BinaryPrefixComparator("123".getBytes()));
//添加列族过滤器
Filter filter4 = new FamilyFilter(CompareOperator.EQUAL, new BinaryComparator(Bytes.toBytes("info")));
//添加列的过滤器
Filter filter5 = new QualifierFilter(CompareOperator.EQUAL, new BinaryComparator(Bytes.toBytes("info")));
//添加值过滤器
Filter filter6 = new ValueFilter(CompareOperator.EQUAL, new SubstringComparator("1"));
//添加列族和列与某值相等过滤器
SingleColumnValueFilter filter7 = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("biological"), CompareOperator.EQUAL, new SubstringComparator("95"));
filter.setFilterIfMissing(true);
//RowKey前缀过滤器
Filter filter8 = new PrefixFilter(Bytes.toBytes("rowKey"));
//分页过滤器
Filter filter9 = new PageFilter(5);
//时间戳过滤器
List<Long> ts = new ArrayList<Long>();
ts.add(new Long(5));
ts.add(new Long(10));
ts.add(new Long(1650856127976L));
Filter filter10 = new TimestampsFilter(ts);
//添加一组过滤器
Filter filter11 = new PrefixFilter(Bytes.toBytes("123"));
Filter filter12 = new PageFilter(3);
List<Filter> filters = new ArrayList<>();
filters.add(filter10);
filters.add(filter11);
FilterList filter13 = new FilterList(FilterList.Operator.MUST_PASS_ALL, filters);
//添加过滤器
scan.setFilter(filter8);
//开始查询数据
ResultScanner scanner = table.getScanner(scan);
for (Result rs : scanner) {
System.out.println("rowKey:" + Bytes.toString(rs.getRow()));
Cell[] cells = rs.rawCells();
for (Cell cell : cells) {
String columnName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
String columnValue = null;
if (Arrays.asList("age", "chemistry", "biological").contains(columnName)) {
int result = Bytes.toInt(cell.getValueArray());
columnValue = Integer.toString(result);
} else {
columnValue = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
}
System.out.println("columnName:" + columnName + " columnValue:" + columnValue);
}
}
}
rowKey:rowKey003
columnName:age columnValue:28
columnName:name columnValue:hbase01
columnName:biological columnValue:36
columnName:chemistry columnValue:35
rowKey:rowKey004
columnName:age columnValue:28
columnName:name columnValue:hbase01
columnName:biological columnValue:36
columnName:chemistry columnValue:35
rowKey:rowKey005
columnName:age columnValue:28
columnName:name columnValue:hbase01
columnName:biological columnValue:36
columnName:chemistry columnValue:35
HBase和MapReduce整合
添加依赖
在Java操作HBase API的依赖基础上添加额外依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.5</version>
</dependency>
从HDFS数据写入HBase
map类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
IntWritable intWritable = new IntWritable();
// 对每行数据拆分处理
String[] split = value.toString().split("\\s+");
for (String s : split) {
text.set(s);
intWritable.set(1);
context.write(text, intWritable);
}
}
}
reduce类
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, ImmutableBytesWritable, Mutation>.Context context) throws IOException, InterruptedException {
int count = 0;
// 遍历集合对每个单词出现次数累加
for (IntWritable value : values) {
count += value.get();
}
//创建插入数据对象put
Put put = new Put(("rowKey_"+key).getBytes());
// 添加列族、列、列值
put.addColumn("info".getBytes(), key.toString().getBytes(), String.valueOf(count).getBytes());
//写出
context.write(null, put);
}
}
创建表
@Test
public void createOneColumnFamilyTable() throws IOException {
TableDescriptorBuilder table = TableDescriptorBuilder.newBuilder(TableName.valueOf("wordcount"));
ColumnFamilyDescriptorBuilder columnBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
ColumnFamilyDescriptor familyDescriptor = columnBuilder.build();
table.setColumnFamily(familyDescriptor);
admin.createTable(table.build());
}
job类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class WordCountJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = HBaseConfiguration.create();
configuration.set("mapreduce.framework.name", "local");
Job job = Job.getInstance(configuration, "HdfsToHbase-" + System.currentTimeMillis());
//设置Mapper
job.setJarByClass(WordCountJob.class);
job.setNumReduceTasks(2);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("/data/word.txt"));
job.setMapperClass(WordCountMapper.class);
//设置Reduce
TableMapReduceUtil.initTableReducerJob("wordcount", WordCountReducer.class, job, null, null, null, null, false);
job.waitForCompletion(true);
}
}
测试
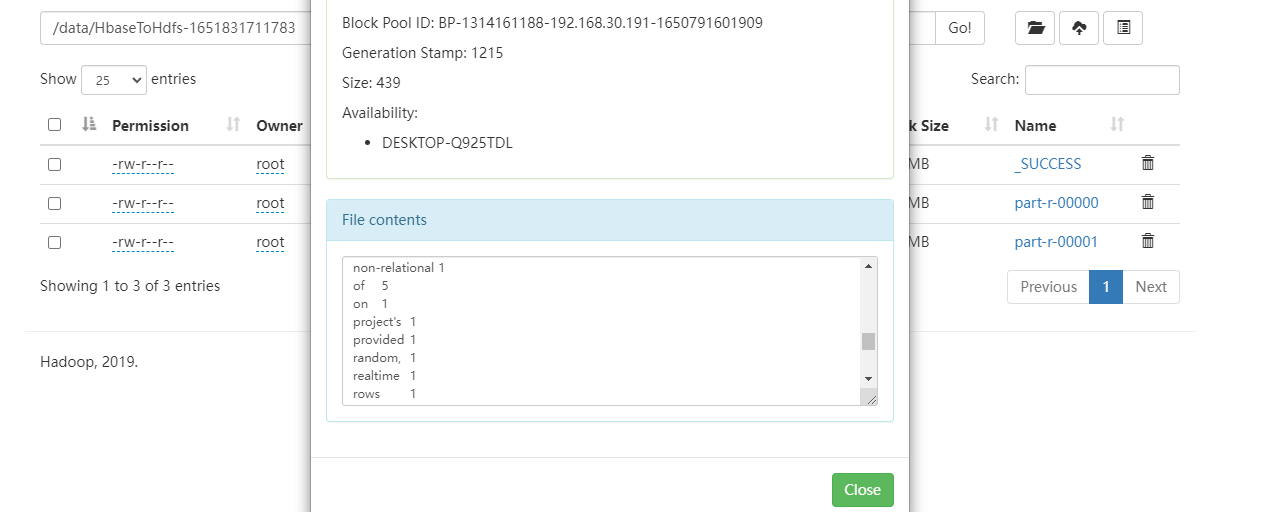
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables billions of rows X millions of columns – atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
hbase(main):003:0> scan 'wordcount'
rowKey_billions column=info:billions, timestamp=1651828315121, value=1
rowKey_by column=info:by, timestamp=1651828314989, value=2
rowKey_capabilities column=info:capabilities, timestamp=1651828315121, value=1
rowKey_clusters column=info:clusters, timestamp=1651828314989, value=1
rowKey_columns column=info:columns, timestamp=1651828314989, value=1
rowKey_commodity column=info:commodity, timestamp=1651828314989, value=1
rowKey_data column=info:data, timestamp=1651828315121, value=2
rowKey_database column=info:database, timestamp=1651828314989, value=1
rowKey_database, column=info:database,, timestamp=1651828314989, value=1
rowKey_distributed column=info:distributed, timestamp=1651828314989, value=1
rowKey_distributed, column=info:distributed,, timestamp=1651828314989, value=2
1 row(s)
Took 1.9950 seconds
从HBase导出到HDFS
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class WordCountMapper extends TableMapper<Text, IntWritable> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
String rowkey = new String(value.getRow());
String word = rowkey.split("_")[1];
byte[] bytes = value.getValue("info".getBytes(), word.getBytes());
String count = new String(bytes);
Integer integer = new Integer(count);
context.write(new Text(word), new IntWritable(integer));
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> iterable, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
// 遍历集合对每个单词出现次数累加
for (IntWritable value : iterable) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取配置文件
Configuration configuration = HBaseConfiguration.create();
configuration.set("mapreduce.framework.name", "local");
//创建任务对象
Job job = Job.getInstance(configuration, "HbaseToHdfs-" + System.currentTimeMillis());
//设置当前任务的主类
job.setJarByClass(WordCountJob.class);
//设置任务的其他信息
job.setNumReduceTasks(2);
//设置扫描器
Scan scan = new Scan();
//设置数据的map
TableMapReduceUtil.initTableMapperJob("wordcount", scan, WordCountMapper.class, Text.class, IntWritable.class, job, false);
//设置Reduce的处理类
FileOutputFormat.setOutputPath(job, new Path("/data/HbaseToHdfs-" + System.currentTimeMillis()));
job.setReducerClass(WordCountReducer.class);
//提交任务
job.waitForCompletion(true);
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/136966.html

