
阿里云异构数据源离线同步工具之DataX
DataX
DataX概述
GitHub地址:https://github.com/alibaba/DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。


框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
插件体系
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
核心架构
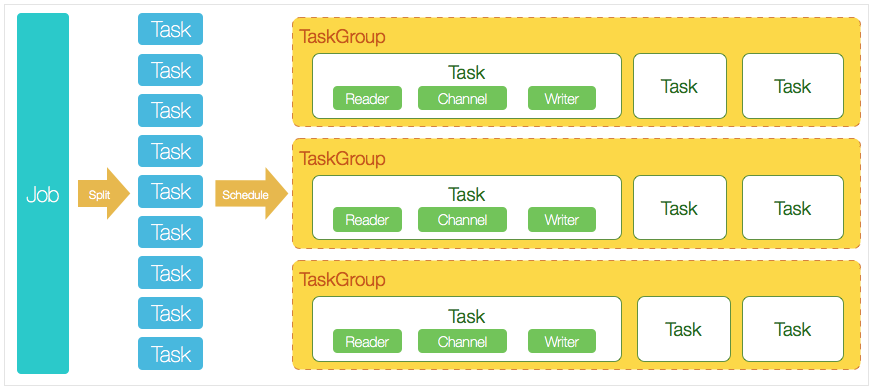
核心模块介绍:
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
DataXJob根据分库分表切分成了100个Task。
根据20个并发,DataX计算共需要分配4个TaskGroup。
4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
更多介绍
更多介绍参考官方:https://github.com/alibaba/DataX
安装DataX
安装dataX有两种方式,一种是tar.gz直接安装,一种是用源码自行编译安装。这里使用tar.gz直接安装
方法一
直接下载DataX工具包:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
自检脚本:
python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
方法二
下载DataX源码,自己编译:DataX源码
(1)、下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git
(2)、通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] -----------------------------------------------------------------
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] -----------------------------------------------------------------
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script
系统要求
Linux
JDK(1.8以上,推荐1.8)
Python(2或3都可以)
Apache Maven 3.x (Compile DataX)
下载与安装
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
tar -zxvf datax.tar.gz
cd datax
DataX基本使用
1.官方演示案例
使用官方演示案例,执行自检脚本:
cd datax
python bin/datax.py job/job.json
报错:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2022-05-12 17:02:28.374 [main] WARN ConfigParser - 插件[streamreader,streamwriter]加载失败,1s后重试... Exception:Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/program/datax/plugin/reader/._hbase094xreader/plugin.json]不存在. 请检查您的配置文件.
2022-05-12 17:02:29.382 [main] ERROR Engine -
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/program/datax/plugin/reader/._hbase094xreader/plugin.json]不存在. 请检查您的配置文件.
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)
at com.alibaba.datax.common.util.Configuration.from(Configuration.java:95)
at com.alibaba.datax.core.util.ConfigParser.parseOnePluginConfig(ConfigParser.java:153)
at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:125)
at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63)
at com.alibaba.datax.core.Engine.entry(Engine.java:137)
at com.alibaba.datax.core.Engine.main(Engine.java:204)
删除datax/plugin/reader与datax/plugin/writer/下所有._xxxx隐藏文件
rm -rf plugin/reader/._*er
rm -rf plugin/writer/._*er
再次执行:python bin/datax.py job/job.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2022-05-12 17:08:40.916 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2022-05-12 17:08:40.928 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.311-b11
jvmInfo: Linux amd64 3.10.0-1160.59.1.el7.x86_64
cpu num: 2
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2022-05-12 17:08:40.960 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"streamreader",
"parameter":{
"column":[
{
"type":"string",
"value":"DataX"
},
{
"type":"long",
"value":19890604
},
{
"type":"date",
"value":"1989-06-04 00:00:00"
},
{
"type":"bool",
"value":true
},
{
"type":"bytes",
"value":"test"
}
],
"sliceRecordCount":100000
}
},
"writer":{
"name":"streamwriter",
"parameter":{
"encoding":"UTF-8",
"print":false
}
}
}
],
"setting":{
"errorLimit":{
"percentage":0.02,
"record":0
},
"speed":{
"byte":10485760
}
}
}
2022-05-12 17:08:40.997 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2022-05-12 17:08:41.000 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2022-05-12 17:08:41.001 [main] INFO JobContainer - DataX jobContainer starts job.
2022-05-12 17:08:41.003 [main] INFO JobContainer - Set jobId = 0
2022-05-12 17:08:41.035 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2022-05-12 17:08:41.036 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do prepare work .
2022-05-12 17:08:41.037 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2022-05-12 17:08:41.038 [job-0] INFO JobContainer - jobContainer starts to do split ...
2022-05-12 17:08:41.040 [job-0] INFO JobContainer - Job set Max-Byte-Speed to 10485760 bytes.
2022-05-12 17:08:41.042 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] splits to [1] tasks.
2022-05-12 17:08:41.043 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks.
2022-05-12 17:08:41.080 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2022-05-12 17:08:41.087 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2022-05-12 17:08:41.093 [job-0] INFO JobContainer - Running by standalone Mode.
2022-05-12 17:08:41.115 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2022-05-12 17:08:41.122 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2022-05-12 17:08:41.127 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2022-05-12 17:08:41.147 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2022-05-12 17:08:41.350 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[206]ms
2022-05-12 17:08:41.351 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2022-05-12 17:08:51.134 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.084s | All Task WaitReaderTime 0.096s | Percentage 100.00%
2022-05-12 17:08:51.134 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2022-05-12 17:08:51.135 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2022-05-12 17:08:51.136 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work.
2022-05-12 17:08:51.136 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2022-05-12 17:08:51.138 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /usr/local/program/datax/hook
2022-05-12 17:08:51.139 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2022-05-12 17:08:51.139 [job-0] INFO JobContainer - PerfTrace not enable!
2022-05-12 17:08:51.140 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.084s | All Task WaitReaderTime 0.096s | Percentage 100.00%
2022-05-12 17:08:51.141 [job-0] INFO JobContainer -
任务启动时刻 : 2022-05-12 17:08:41
任务结束时刻 : 2022-05-12 17:08:51
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
2.从stream读取数据并打印到控制台
查看配置模板
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
cd datax/bin
python datax.py -r streamreader -w streamwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
创建作业配置文件
根据模板配置,创建作业配置文件vim stream2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
启动DataX
cd datax
python bin/datax.py job/stream2stream.json
......................
2022-05-12 17:15:51.107 [job-0] INFO StandAloneJobContainerCommunicator - Total 50 records, 950 bytes | Speed 95B/s, 5 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2022-05-12 17:15:51.108 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2022-05-12 17:15:51.109 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2022-05-12 17:15:51.111 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work.
2022-05-12 17:15:51.111 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2022-05-12 17:15:51.113 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /usr/local/program/datax/hook
2022-05-12 17:15:51.114 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2022-05-12 17:15:51.115 [job-0] INFO JobContainer - PerfTrace not enable!
2022-05-12 17:15:51.115 [job-0] INFO StandAloneJobContainerCommunicator - Total 50 records, 950 bytes | Speed 95B/s, 5 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2022-05-12 17:15:51.116 [job-0] INFO JobContainer -
任务启动时刻 : 2022-05-12 17:15:40
任务结束时刻 : 2022-05-12 17:15:51
任务总计耗时 : 10s
任务平均流量 : 95B/s
记录写入速度 : 5rec/s
读出记录总数 : 50
读写失败总数 : 0
3.从MySQL抽取数据到HDFS
获取配置模板
python bin/datax.py -r mysqlreader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
创建作业配置文件
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"age"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/demo"
],
"table": [
"user"
]
}
],
"password": "123456",
"username": "root",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "SMALLINT"
}
],
"compress": "GZIP",
"defaultFS": "hdfs://administrator:9000",
"fieldDelimiter": "\t",
"fileName": "mysql2hdfs.text",
"fileType": "text",
"path": "/datax",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "10"
}
}
}
}
启动DataX
cd datax
python bin/datax.py job/mysql2hdfs.json
................
2022-05-13 15:07:22.405 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /usr/local/program/datax/hook
2022-05-13 15:07:22.507 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.051s | 0.051s | 0.051s
PS Scavenge | 1 | 1 | 1 | 0.029s | 0.029s | 0.029s
2022-05-13 15:07:22.508 [job-0] INFO JobContainer - PerfTrace not enable!
2022-05-13 15:07:22.508 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 24 bytes | Speed 2B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2022-05-13 15:07:22.510 [job-0] INFO JobContainer -
任务启动时刻 : 2022-05-13 15:07:09
任务结束时刻 : 2022-05-13 15:07:22
任务总计耗时 : 12s
任务平均流量 : 2B/s
记录写入速度 : 0rec/s
读出记录总数 : 4
读写失败总数 : 0
4.从Hive抽取数据到MySQL
准备Hive数据
创建Hive外部表
create external table if not exists tb_user(id int ,name string,age int) row format delimited fields terminated by ',' lines terminated by '\n';
创建vim tb_user.text并添加如下数据
1,hive1,11
2,hive2,22
3,hive3,33
4,hive4,44
5,hive5,55
上传到Hive外部表/hive/warehouse/tb_user目录下
hadoop fs -put user_data.txt /hive/warehouse/tb_user
查看tb_user表数据
hive (default)> select * from tb_user;
OK
tb_user.id tb_user.name tb_user.age
1 hive1 11
2 hive2 22
3 hive3 33
4 hive4 44
5 hive5 55
查看配置模板
cd datax/bin
python datax.py -r hdfsreader -w mysqlwriter
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [],
"defaultFS": "",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileType": "orc",
"path": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
创建作业配置文件
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "long"
}
],
"defaultFS": "hdfs://112.74.96.150:9000",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileType": "text",
"path": "/hive/warehouse/tb_user/*"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name",
"age"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/demo",
"table": [
"user"
]
}
],
"password": "123456",
"preSql": [
"delete from user"
],
"session": [
"select count(*) from user"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
启动DataX
python bin/datax.py job/hive2mysql.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2022-05-14 14:44:57.570 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2022-05-14 14:44:57.579 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.311-b11
jvmInfo: Linux amd64 3.10.0-1160.59.1.el7.x86_64
cpu num: 2
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
................
2022-05-14 14:45:01.151 [0-0-0-writer] INFO DBUtil - execute sql:[select count(*) from user]
2022-05-14 14:45:01.178 [0-0-0-reader] INFO Reader$Task - end read source files...
2022-05-14 14:45:01.512 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[519]ms
2022-05-14 14:45:01.513 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2022-05-14 14:45:11.007 [job-0] INFO StandAloneJobContainerCommunicator - Total 5 records, 40 bytes | Speed 4B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.019s | Percentage 100.00%
2022-05-14 14:45:11.007 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2022-05-14 14:45:11.008 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do post work.
2022-05-14 14:45:11.008 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] do post work.
2022-05-14 14:45:11.008 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2022-05-14 14:45:11.010 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /usr/local/program/datax/hook
2022-05-14 14:45:11.011 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.059s | 0.059s | 0.059s
PS Scavenge | 1 | 1 | 1 | 0.026s | 0.026s | 0.026s
2022-05-14 14:45:11.011 [job-0] INFO JobContainer - PerfTrace not enable!
2022-05-14 14:45:11.012 [job-0] INFO StandAloneJobContainerCommunicator - Total 5 records, 40 bytes | Speed 4B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.019s | Percentage 100.00%
2022-05-14 14:45:11.019 [job-0] INFO JobContainer -
任务启动时刻 : 2022-05-14 14:44:57
任务结束时刻 : 2022-05-14 14:45:11
任务总计耗时 : 13s
任务平均流量 : 4B/s
记录写入速度 : 0rec/s
读出记录总数 : 5
读写失败总数 : 0

DataX Web
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。
学习参考:https://blog.csdn.net/qq_38628046/article/details/124769355
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/136968.html

