
MapReduce的基本使用
添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
</dependencies>
运行样例程序
在MapReduce组件中,官方提供了一些样例程序,其中非常有名的就是
wordcount和pi程序。这些程序在HADOOP_HOME/share/hadoop/mapreduce/目录中
运算wordcount程序
cd HADOOP_HOME/share/hadoop/mapreduce/
hdfs dfs -put mapReduce.txt /mapReduce/input
jar hadoop-mapreduce-examples-3.1.3.jar wordcount /mapReduce/input /mapReduce/output/
运算PI程序
cd HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.1.3.jar pi 5 200
可以从官网下载Hadoop的源码包,找到
hadoop-mapreduceproject项目,在其中一个例子程序的子项目:hadoop-mapreduce-examples中找到样例程序。
WordCount计算
经典的WordCount计算,统计如下文本内容中单词的个数
vi mapReduce.txt
MapReduce is a programming
paradigm that enables
massive scalability across
hundreds or thousands of
servers in a Hadoop cluster.
As the processing component,
MapReduce is the heart of Apache Hadoop.
The term "MapReduce" refers to two separate
and distinct tasks that Hadoop programs perform.
HDFS创建目录
hdfs dfs -mkdir /mapReduce/input
上传到HDFS
hdfs dfs -put mapReduce.txt /mapReduce/input
定义Mapper
编写业务逻辑的map阶段
/**
* Mapper<KEYIN, KEYIN, KEYOUT, VALUEOUT>
* KEYIN : K1的类型 行偏移量 LongWritable
* KEYIN : V1的类型 一行数据 Text
* KEYOUT : K2的类型 每个单词 Text
* VALUEOUT : V2的类型 固定值1 LongWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 将数据切分为 Key-Value(K1和V1), 输入到第二步
* 自定义Map逻辑, 将第一步的结果转换成另外的Key-Value(K2和V2), 输出结果
* <p>
* K1 V1 K2 V2
* 0 hello world ===> hello 1
* 11 hello mapReduce world 1
*
* @param key K1
* @param value V1
* @param context MapReduce上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
LongWritable longWritable = new LongWritable();
// 对每行数据拆分处理
String row = value.toString();
String[] worlds = row.split(" ");
// 对拆分数据转换
for (String world : worlds) {
text.set(world);
longWritable.set(1);
context.write(text, longWritable);
}
}
}
定义Reduce
编写业务逻辑的reduce阶段
/**
* Reducer<KEYIN, KEYIN, KEYOUT, VALUEOUT>
* KEYIN : K2的类型 每个单词 Text
* KEYIN : V2的类型 集合中泛型的类型 LongWritable
* KEYOUT : K3的类型 每个单词 Text
* VALUEOUT : V3的类型 每个单词出现的次数 LongWritable
*/
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 将新的K2 V2转换为K3 V3
* <p>
* 新K2 新V2 K3 V3
* hello <1,1> ===> hello 2
* world <1,1,1> world 3
*
* @param key K2
* @param values V2
* @param context MapReduce上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
LongWritable longWritable = new LongWritable();
// 遍历集合对每个单词出现次数累加
for (LongWritable value : values) {
count += value.get();
}
// 写入MapReduce上下文
longWritable.set(count);
context.write(key, longWritable);
}
}
定义Job
job对象存储该程序运行的必要信息,如指定Mapper类和Reducer类
方式一:
public class WordCountJob extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 创建任务对象
Job job = Job.getInstance(super.getConf(), "mapreduce-test");
//打包到集群运行,必须要添加以下配置,指定程序的main函数
// job.setJarByClass(WordCountJob.class);
// 设置读取文件的类以及从哪里读取
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node001:9000/mapReduce/input"));
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置Map阶段, K2 V2的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// Shuffle阶段,使用默认方式
job.setReducerClass(WordCountReducer.class);
// 设置Reduce类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("hdfs://node001:9000/mapReduce/output"));
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
return waitForCompletion ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new WordCountJob(), args);
// 非零状态码表示异常终止
System.exit(run);
}
}
方式二:
复制core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等文件到项目resources目录
public class WordCountJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取配置文件
Configuration configuration = new Configuration(true);
//本地模式运行
configuration.set("mapreduce.framework.name", "local");
//创建任务
Job job = Job.getInstance(configuration);
//设置任务主类
job.setJarByClass(WordCountJob.class);
//设置任务
job.setJobName("wordcount-" + System.currentTimeMillis());
//设置Reduce的数量
job.setNumReduceTasks(2);
//设置数据的输入路径
FileInputFormat.setInputPaths(job, new Path("/mapReduce/input"));
//设置数据的输出路径
FileOutputFormat.setOutputPath(job, new Path("/mapReduce/output_" + System.currentTimeMillis()));
//设置Map的输入的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置Reduce的输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置Map和Reduce的处理类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//提交任务
job.waitForCompletion(true);
}
}
MapReduce的运行方式
本地运行模式
1.概述
1.在开发环境下本地运行,方便调试和测试
2.MapReduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
3.数据输入输出可以在本地,也可以在HDFS
2.在window端本地化执行
复制
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等Hadoop配置文件到项目resources目录
设置:
configuration.set("mapreduce.framework.name", "local");
集群运行模式
1.概述
1.打jar包,提交任务到集群运行
2.用hadoop jar的命令提交代码到YARN集群运行
3.处理的数据和输出结果应该位于HDFS文件系统
2.在Linux端执行
对项目打包,如:wordcount.jar,并上传Linux服务器
再Linux服务器执行:
hadoop jar wordcount.jar xx.xx.xx.WordCountJob
在Linux服务端运行
打Jar包运行
hadoop jar wordcount.jar cn.ybzy.mapreduce.WordCountJob
bash-4.1# hadoop jar mapreduce.jar cn.ybzy.mapreduce.WordCountJob
22/02/27 09:05:54 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
22/02/27 09:05:54 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
22/02/27 09:05:55 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
22/02/27 09:05:55 INFO input.FileInputFormat: Total input paths to process : 1
22/02/27 09:05:55 INFO mapreduce.JobSubmitter: number of splits:1
22/02/27 09:05:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1736835367_0001
22/02/27 09:05:56 INFO mapreduce.Job: The url to track the job: http://node001:8080/
22/02/27 09:05:56 INFO mapreduce.Job: Running job: job_local1736835367_0001
22/02/27 09:05:56 INFO mapred.LocalJobRunner: OutputCommitter set in config null
22/02/27 09:05:56 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
22/02/27 09:05:56 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
22/02/27 09:05:56 INFO mapred.LocalJobRunner: Waiting for map tasks
22/02/27 09:05:56 INFO mapred.LocalJobRunner: Starting task: attempt_local1736835367_0001_m_000000_0
22/02/27 09:05:56 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
22/02/27 09:05:56 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
22/02/27 09:05:56 INFO mapred.MapTask: Processing split: hdfs://node001:9000/mapReduce/input/mapReduce.txt:0+291
22/02/27 09:05:56 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
22/02/27 09:05:56 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
22/02/27 09:05:56 INFO mapred.MapTask: soft limit at 83886080
22/02/27 09:05:56 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
22/02/27 09:05:56 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
22/02/27 09:05:57 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
22/02/27 09:05:57 INFO mapred.LocalJobRunner:
22/02/27 09:05:57 INFO mapred.MapTask: Starting flush of map output
22/02/27 09:05:57 INFO mapred.MapTask: Spilling map output
22/02/27 09:05:57 INFO mapred.MapTask: bufstart = 0; bufend = 643; bufvoid = 104857600
22/02/27 09:05:57 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214224(104856896); length = 173/6553600
22/02/27 09:05:57 INFO mapred.MapTask: Finished spill 0
22/02/27 09:05:57 INFO mapred.Task: Task:attempt_local1736835367_0001_m_000000_0 is done. And is in the process of committing
22/02/27 09:05:57 INFO mapred.LocalJobRunner: map
22/02/27 09:05:57 INFO mapred.Task: Task 'attempt_local1736835367_0001_m_000000_0' done.
22/02/27 09:05:57 INFO mapred.LocalJobRunner: Finishing task: attempt_local1736835367_0001_m_000000_0
22/02/27 09:05:57 INFO mapred.LocalJobRunner: map task executor complete.
22/02/27 09:05:57 INFO mapred.LocalJobRunner: Waiting for reduce tasks
22/02/27 09:05:57 INFO mapred.LocalJobRunner: Starting task: attempt_local1736835367_0001_r_000000_0
22/02/27 09:05:57 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
22/02/27 09:05:57 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
22/02/27 09:05:57 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@16e20f40
22/02/27 09:05:57 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=333971456, maxSingleShuffleLimit=83492864, mergeThreshold=220421168, ioSortFactor=10, memToMemMergeOutputsThreshold=10
22/02/27 09:05:57 INFO reduce.EventFetcher: attempt_local1736835367_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
22/02/27 09:05:57 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1736835367_0001_m_000000_0 decomp: 733 len: 737 to MEMORY
22/02/27 09:05:57 INFO reduce.InMemoryMapOutput: Read 733 bytes from map-output for attempt_local1736835367_0001_m_000000_0
22/02/27 09:05:57 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 733, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->733
22/02/27 09:05:57 INFO mapreduce.Job: Job job_local1736835367_0001 running in uber mode : false
22/02/27 09:05:57 INFO mapreduce.Job: map 100% reduce 0%
22/02/27 09:05:57 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
22/02/27 09:05:57 INFO mapred.LocalJobRunner: 1 / 1 copied.
22/02/27 09:05:57 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
22/02/27 09:05:57 INFO mapred.Merger: Merging 1 sorted segments
22/02/27 09:05:57 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 719 bytes
22/02/27 09:05:57 INFO reduce.MergeManagerImpl: Merged 1 segments, 733 bytes to disk to satisfy reduce memory limit
22/02/27 09:05:57 INFO reduce.MergeManagerImpl: Merging 1 files, 737 bytes from disk
22/02/27 09:05:57 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
22/02/27 09:05:57 INFO mapred.Merger: Merging 1 sorted segments
22/02/27 09:05:57 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 719 bytes
22/02/27 09:05:57 INFO mapred.LocalJobRunner: 1 / 1 copied.
22/02/27 09:05:57 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
22/02/27 09:05:58 INFO mapred.Task: Task:attempt_local1736835367_0001_r_000000_0 is done. And is in the process of committing
22/02/27 09:05:58 INFO mapred.LocalJobRunner: 1 / 1 copied.
22/02/27 09:05:58 INFO mapred.Task: Task attempt_local1736835367_0001_r_000000_0 is allowed to commit now
22/02/27 09:05:58 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1736835367_0001_r_000000_0' to hdfs://node001:9000/mapReduce/output/_temporary/0/task_local1736835367_0001_r_000000
22/02/27 09:05:58 INFO mapred.LocalJobRunner: reduce > reduce
22/02/27 09:05:58 INFO mapred.Task: Task 'attempt_local1736835367_0001_r_000000_0' done.
22/02/27 09:05:58 INFO mapred.LocalJobRunner: Finishing task: attempt_local1736835367_0001_r_000000_0
22/02/27 09:05:58 INFO mapred.LocalJobRunner: reduce task executor complete.
22/02/27 09:05:58 INFO mapreduce.Job: map 100% reduce 100%
22/02/27 09:05:58 INFO mapreduce.Job: Job job_local1736835367_0001 completed successfully
22/02/27 09:05:58 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=1864
FILE: Number of bytes written=551289
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=582
HDFS: Number of bytes written=343
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=9
Map output records=44
Map output bytes=643
Map output materialized bytes=737
Input split bytes=120
Combine input records=0
Combine output records=0
Reduce input groups=38
Reduce shuffle bytes=737
Reduce input records=44
Reduce output records=38
Spilled Records=88
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=22
Total committed heap usage (bytes)=488112128
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=291
File Output Format Counters
Bytes Written=343
bash-4.1#
bash-4.1# hdfs dfs -ls /mapReduce/output
Found 4 items
-rw-r--r-- 1 root supergroup 0 2022-02-27 09:36 /mapReduce/output/_SUCCESS
-rw-r--r-- 1 root supergroup 58 2022-02-27 09:36 /mapReduce/output/part-r-00000
bash-4.1# hdfs dfs -cat /mapReduce/output/part-r-00000
"MapReduce" 1
Apache 1
As 1
Hadoop 2
Hadoop. 1
MapReduce 1
The 1
a 2
.........
总结
MapReduce程序的业务编码分为两个大部分,一部分配置程序的运行信息,一部分编写该MapReduce程序的业务逻辑,并且业务逻辑的map阶段和reduce阶段的代码分别继承Mapper类和Reducer类
解决运行任务卡住
方案一
网上多说yarn管理的内存资源不够,修改yarn-site.xml,设置资源大小
<!-- 设置最大内存为3GB -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3000</value>
</property>
<!-- 最小内存为2GB -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 虚拟内存和物理内存的比率为2.1 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
方案二
修改mapred-site.xml,将
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改为
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://IP:9000</value>
<final>true</final>
</property>
分区Partation
概述
MapReduce中会将map输出的kv对,按照相同key分组,然后分发给不同的reducetask
1.默认的分区组件HashPartitioner
2.分发规则:根据key的hashcode%reducetask数来分发,即得到对应的Reduce个数
3.分区的数量和Reduce的数量是相等的
4.如果要按照需求进行分组,则需要改写数据分发(分组)组件Partitioner
5.自定义一个 ProvincePartitioner继承抽象类Partitioner
对上述mapReduce.txt文件中的单词进行统计分区
定义Partitioner
public class MyPartitioner extends Partitioner<Text, LongWritable> {
/**
* @param text K2
* @param longWritable V2
* @param i reduce个数
* @return
*/
@Override
public int getPartition(Text text, LongWritable longWritable, int i) {
// 单词长度<=3,进入第一个分区,即第一个ReduceTask,其编号为0
if (text.toString().length() <= 3) {
return 0;
// 单词长度>3 && 单词长度<=6,进入第二个分区,即第二个ReduceTask,其编号为1
} else if (text.toString().length() > 3 && text.toString().length() <= 6) {
return 1;
} else {
// 单词长度>6,进入第三个分区,即第三个ReduceTask,其编号为2
return 2;
}
}
}
使用Partitioner
// Shuffle阶段,使用默认方式
// 分区
job.setPartitionerClass(MyPartitioner.class);
//设置Reduce个数
job.setNumReduceTasks(3);
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
return waitForCompletion ? 0 : 1;
测试
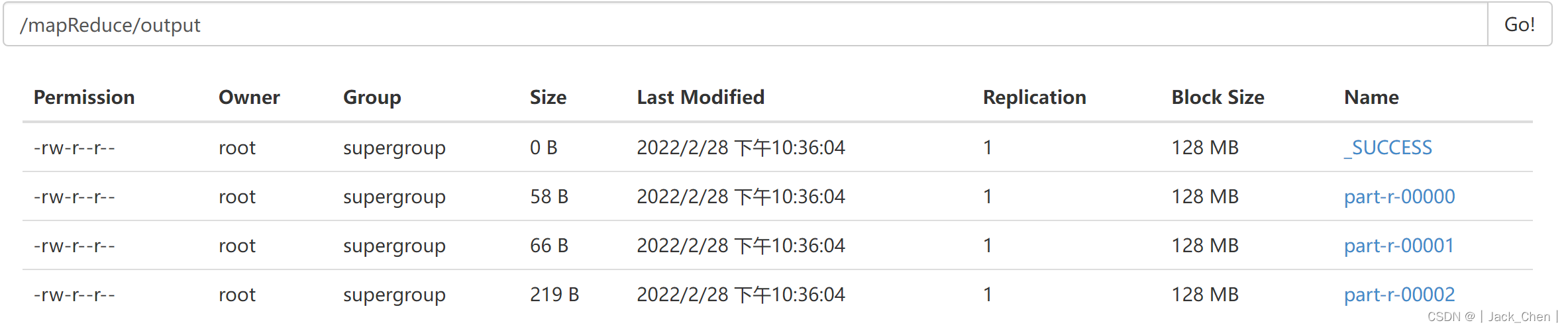
bash-4.1# hdfs dfs -ls /mapReduce/output
Found 4 items
-rw-r--r-- 1 root supergroup 0 2022-02-28 09:36 /mapReduce/output/_SUCCESS
-rw-r--r-- 1 root supergroup 58 2022-02-28 09:36 /mapReduce/output/part-r-00000
-rw-r--r-- 1 root supergroup 66 2022-02-28 09:36 /mapReduce/output/part-r-00001
-rw-r--r-- 1 root supergroup 219 2022-02-28 09:36 /mapReduce/output/part-r-00002
bash-4.1# hdfs dfs -cat /mapReduce/output/part-r-00000
As 1
The 1
a 2
and 1
bash-4.1# hdfs dfs -cat /mapReduce/output/part-r-00001
Apache 1
Hadoop 2
across 1
bash-4.1# hdfs dfs -cat /mapReduce/output/part-r-00002
"MapReduce" 1
Hadoop. 1
MapReduce 1
cluster. 1
component, 1
序列化和排序
概述
Hadoop有自己的一套序列化机制,参与序列化的对象的类都要实现Writable接口。Hadoop中的序列化框架已经对基本类型和null提供了序列化的实现了。
| 基本数据类型 | Hadoop的实现 |
|---|---|
| byte | ByteWritable |
| short | ShortWritable |
| int | IntWritable |
| long | LongWritable |
| float | FloatWritable |
| double | DoubleWritable |
| String | Text |
| null | NullWritable |
如果需要将自定义类作为key,则要实现WritableComparable接口,因为Writerable接口不具备比较功能,而MapReduce框中的shuffle过程一定会对key进行排序,所以还需要指定排序规则。如果自定义的bean只是作为value,则只需要实现Writable接口即可
结论:
1.key必须实现WritableComparable接口
2.value必须要实现Writable接口
MR程序在处理数据的过程中会对数据排序(map输出的kv对传输到reduce之前,会排序),排序的依据是map输出的key。所以,如果要实现自己需要的排序规则,则可以考虑将排序因素放到key中,让key实现接口WritableComparable,然后重写key的compareTo方法
public class MyBean implements WritableComparable{
/**
* 排序规则
*/
@Override
public int compareTo(MyPairWritable o) {
return 0;
}
/**
* 序列化
*/
@Override
public void write(DataOutput out) throws IOException {
}
/**
* 反序列化
*/
@Override
public void readFields(DataInput in) throws IOException {
}
}
数据准备
对文本文件中的数据(字母、数字)排序 准备sort.txt
a 1
d 6
b 4
a 3
f 7
b 1
定义MyPairWritable
public class MyPairWritable implements WritableComparable<MyPairWritable> {
private String word;
private int number;
public void setWord(String word) {
this.word = word;
}
public void setNumber(int number) {
this.number = number;
}
/**
* 排序规则
*
* @param o
* @return
*/
@Override
public int compareTo(MyPairWritable o) {
//先比较单词,比较ascall码表对应的值
int res = this.word.compareTo(o.word);
//单词相同比较数字,默认升序;
if (res == 0) {
return this.number - o.number;
}
return res;
}
/**
* 序列化
*
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(word);
out.writeInt(number);
}
/**
* 反序列化
*
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.word = in.readUTF();
this.number = in.readInt();
}
}
定义SortMapper
/**
* K1 V1 转 K2 V2
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN: 行偏移量 LongWritable
* VALUEIN: 行数据 Text
* KEYOUT: 可序列化/反序列化对象 MyPairWritable
* VALUEOUT: 行数据 Text
**/
public class SortMapper extends Mapper<LongWritable, Text, MyPairWritable, Text> {
/**
* 0 a 1 a 1 a 1
* 2 d 6 d 6 d 6
* 4 b 4 ==> b 4 b 4
* 6 a 3 a 3 a 3
* 8 f 7 f 7 f 7
* 10 b 1 b 1 b 1
*
* @param key 行偏移量
* @param value 行数据
* @param context 上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
MyPairWritable myPairWritable = new MyPairWritable();
myPairWritable.setWord(split[0]);
myPairWritable.setNumber(Integer.parseInt(split[1]));
// 得到新的K2 V2
context.write(myPairWritable, value);
}
}
定义SortReduce
public class SortReduce extends Reducer<MyPairWritable, Text, MyPairWritable, NullWritable> {
/**
* a 1 a 1 a 1 a 1
* d 6 d 6 a 3 a 3
* b 4 b 4 ===> b 1 b 1
* a 3 a 3 b 4 b 4
* f 7 f 7 d 6 d 6
* b 1 b 1 f 7 f 7
*
* @param key K2 ==> k3
* @param values V2 ==> V3
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(MyPairWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(key, NullWritable.get());
}
}
}
定义Job
public class MyJob extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 创建任务对象
Job job = Job.getInstance(super.getConf(), "mapreduce-tet");
//打包到集群运行,必须要添加以下配置,指定程序的main函数
// job.setJarByClass(MyJob.class);
// 设置读取文件的类以及从哪里读取
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node001:9000/mapReduce/input/sort"));
// 设置Mapper类
job.setMapperClass(SortMapper.class);
// 设置Map阶段, K2 V2的输出类型
job.setMapOutputKeyClass(MyPairWritable.class);
job.setMapOutputValueClass(Text.class);
// Shuffle阶段,使用默认方式
// 分区
// job.setPartitionerClass(MyPartitioner.class);
// //设置Reduce个数
// job.setNumReduceTasks(3);
job.setReducerClass(SortReduce.class);
// 设置Reduce类
job.setOutputKeyClass(MyPairWritable.class);
job.setOutputValueClass(NullWritable.class);
// 设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("hdfs://node001:9000/mapReduce/output/sort"));
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
return waitForCompletion ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new MyJob(), args);
// 非零状态码表示异常终止
System.exit(run);
}
}
测试
代码打包上传并执行
hadoop jar mapreduce-sort.jar cn.ybzy.mapreduce.MyJob
bash-4.1# hdfs dfs -ls /mapReduce/output/sort/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2022-02-28 10:15 /mapReduce/output/sort/_SUCCESS
-rw-r--r-- 1 root supergroup 282 2022-02-28 10:15 /mapReduce/output/sort/part-r-00000
bash-4.1# hdfs dfs -cat /mapReduce/output/sort/part-r-00000
cn.ybzy.mapreduce.sort.MyPairWritable@15318ec7
cn.ybzy.mapreduce.sort.MyPairWritable@15318ec7
cn.ybzy.mapreduce.sort.MyPairWritable@15318ec7
cn.ybzy.mapreduce.sort.MyPairWritable@15318ec7
cn.ybzy.mapreduce.sort.MyPairWritable@15318ec7
cn.ybzy.mapreduce.sort.MyPairWritable@15318ec7
计数器
概述
计数器是用来记录job的执行进度和状态的。它的作用可以理解为日志,可以在程序的某个位置插入计数器,记录数据或者进度的变化情况。
MapReduce计数器(Counter)提供一个窗口,用于观察MapReduce Job运行期的各种细节数据。对MapReduce性能调优很有帮助,MapReduce性能优化的评估大部分都是基于这些Counter的数值表现出来的。
hadoop内置计数器
| 计数器 | 类 |
|---|---|
| MapReduce 任务计数器 | org.apache.hadoop.mapreduce.TaskCounter |
| 文件系统计数器 | org.apache.hadoop.mapreduce.FileSystemCounter |
| FileInputFormat计数器 | org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| FileOutputFormat计数器 | org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
| Job作业计数器 | org.apache.hadoop.mapreduce.JobCounter |
通过Context上下文对象
定义计数器,通过context上下文对象获取计数器,进行记录。
通过context上下文对象,使用计数器统计Map阶段读取了多少条数据
public class SortMapper extends Mapper<LongWritable, Text, MyPairWritable, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("MY_COUNT", "MapRecordCounter");
counter.increment(1L);
String[] split = value.toString().split(" ");
MyPairWritable myPairWritable = new MyPairWritable();
myPairWritable.setWord(split[0]);
myPairWritable.setNumber(Integer.parseInt(split[1]));
context.write(myPairWritable, value);
}
}
通过Enum枚举
通过enum枚举类型来定义计数器
通过Enum枚举,统计Reduce阶段读取了多少条数据
public class SortReduce extends Reducer<MyPairWritable, Text, MyPairWritable, NullWritable> {
public static enum Counter {
REDUCE_COUNT,
}
@Override
protected void reduce(MyPairWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.getCounter(Counter.REDUCE_COUNT).increment(1L);
for (Text value : values) {
context.write(key, NullWritable.get());
}
}
}
使用计数器后,观察Job结果,如输入的字节数、输出的字节数、Map端输入/输出的字节数和条数、Reduce端的输入/输出的字节数和条数等
22/03/01 08:26:11 INFO mapreduce.Job: map 100% reduce 100%
22/03/01 08:26:11 INFO mapreduce.Job: Job job_local1974367823_0001 completed successfully
22/03/01 08:26:11 INFO mapreduce.Job: Counters: 37
File System Counters
FILE: Number of bytes read=554
...........
HDFS: Number of write operations=4
Map-Reduce Framework
...........
Map output materialized bytes=84
...........
Total committed heap usage (bytes)=488112128
MY_COUNT
MapRecordCounter=6
Shuffle Errors
BAD_ID=0
...........
cn.ybzy.mapreduce.sort.SortReduce$Counter
REDUCE_COUNT=6
File Input Format Counters
Bytes Read=24
File Output Format Counters
Bytes Written=282
组合器Combiner
概述
在MapReduce的第一个阶段MapTask执行过程中,每一个mapTask都可能会产生大量的本地输出,Combiner是 MapReduce程序中Mapper和Reducer之外的一种组件,它的作用是在mapTask之后给mapTask的结果进行局部汇总,是一个本地化的reduce操作,主要是在mapTask计算得到结果文件前做一个简单的合并重复key值的操作以减轻reduceTask的计算负载,减少网络传输。
简而言之:Combiner是对每一个 maptask的输出先做一次合并,减少在 map 和 reduce 节点之间的数据传输量,以提高网络IO 性能
例如:
MapReduce中的WordCount程序,key是词汇,value就是次数,最终的需求是汇总每个单词的出现次数,得到一个最终结果,所以可以可优化之处就是:可以考虑在mapTask计算得到结果之前,先把相同key的value做汇总,没有必要非得得到reduceTask阶段再来做汇总。
作用
在Hadoop集群操作中,是由多台主机一起进行MapReduce, 如果加入Combiner局部聚合操作,每一台主机会在 reduce之前进行一次对本机数据的提前预聚合, 然后在通过集群进行reduce操作,这样就减少网络传输,大大节省 reduce阶段的计算时间, 从而加快 MapReduce 的处理速度。
Combiner注意事项
1、Combiner和Reducer的区别在于运行的位置
Combiner是在每一个MapTask所在的节点运行,每个Combiner接收对应的MapTask结果进行局部汇总
Reducer是接收全局所有MapTask的输出结果,进行最终的汇总
2、输入对应Mapper输出、输出对应Reducer的输入
Combiner的输入kv类型应该跟Mapper的输出kv类型对应
Combiner的输出kv类型应该跟Reducer的输入kv类型对应
3、Combiner使用的原则:有或没有都不能影响业务逻辑,都不能影响最终结果
Combiner在MapReduce过程中可能调用也可能不调用,可能调一次也可能调多次
4、并不是所有的Job都适用Combiner ,只有操作满足结合律的才可设置Combiner
如对一串数字求和、求最大值的话,可以使用,但如果是求平均值就不适用。因为任务分片后,每个MapTask保存有一定数据,如果要提前在MapTask上操作,那么MapTask数据间不能有依赖关系。
数据准备
对如下文本内容进行单词个数统计
hello world
hello hadoop
hello hdfs
hello mapreduce
自定义Combiner
Combiner和Reducer一样,编写一个类然后继承Reducer,在reduce方法中写具体的Combiner逻辑,然后在job中设置Combiner 组件。
public class MyCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
LongWritable longWritable = new LongWritable();
// 遍历集合对每个单词出现次数累加
for (LongWritable value : values) {
count += value.get();
}
// 写入MapReduce上下文
longWritable.set(count);
context.write(key, longWritable);
}
}
Job中设置Combiner
// Shuffle阶段,使用默认方式
//设置规约
job.setCombinerClass(MyCombiner.class);
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
return waitForCompletion ? 0 : 1;
测试
未使用Combiner对单词统计
Map-Reduce Framework
Reduce input records=8
Reduce output records=5
使用Combiner对单词统计
Map-Reduce Framework
Reduce input records=5
Reduce output records=5
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/136971.html

