
Windows安装Hadoop3.x及在Windows环境下本地开发
下载安装
官网:https://hadoop.apache.org/
访问:https://archive.apache.org/dist/hadoop/common/ 下载hadoop.tar.gz并解压到指定目录
访问https://github.com/cdarlint/winutils选择合适版本对应的winutils.exe和hadoop.dll
将winutils.exe和hadoop.dll拷贝到Hadoop/bin目录下和 C:\Windows\System32目录下(可选尝试,非必须),最后重启电脑。
配置环境变量
HADOOP_HOME:D:\Development\Hadoop
HADOOP_USER_NAME:root
Path:%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
配置Hadoop
检查adoop-env.cmd文件JDK的配置,通常无需改动
set JAVA_HOME=%JAVA_HOME%
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>D:\Development\Hadoop\data\tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>D:\Development\Hadoop\data\namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>D:\Development\Hadoop\data\datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
格式化NameNode : hdfs namenode -format
2022-04-15 21:21:54,046 INFO snapshot.SnapshotManager: SkipList is disabled
2022-04-15 21:21:54,063 INFO util.GSet: Computing capacity for map cachedBlocks
2022-04-15 21:21:54,063 INFO util.GSet: VM type = 64-bit
2022-04-15 21:21:54,064 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
2022-04-15 21:21:54,064 INFO util.GSet: capacity = 2^18 = 262144 entries
2022-04-15 21:21:54,108 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2022-04-15 21:21:54,109 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2022-04-15 21:21:54,109 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2022-04-15 21:21:54,133 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2022-04-15 21:21:54,133 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2022-04-15 21:21:54,139 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2022-04-15 21:21:54,139 INFO util.GSet: VM type = 64-bit
2022-04-15 21:21:54,140 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
2022-04-15 21:21:54,140 INFO util.GSet: capacity = 2^15 = 32768 entries
2022-04-15 21:22:03,246 INFO namenode.FSImage: Allocated new BlockPoolId: BP-9220273-192.168.179.1-1650028923233
2022-04-15 21:22:03,275 INFO common.Storage: Storage directory D:\Development\Hadoop\data\namenode has been successfully formatted.
2022-04-15 21:22:03,330 INFO namenode.FSImageFormatProtobuf: Saving image file D:\Development\Hadoop\data\namenode\current\fsimage.ckpt_0000000000000000000 using no compression
2022-04-15 21:22:03,560 INFO namenode.FSImageFormatProtobuf: Image file D:\Development\Hadoop\data\namenode\current\fsimage.ckpt_0000000000000000000 of size 391 bytes saved in 0 seconds .
2022-04-15 21:22:03,602 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2022-04-15 21:22:03,616 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at Coding/192.168.179.1
************************************************************/
启动hadoop集群
进入Hadoop解压目录的sbin目录,执行start-all,将启动以下组件

jps查看进程
D:\Development\Hadoop\sbin>jps
10016 DataNode
12592 NodeManager
13748 ResourceManager
8904 NameNode
1436 Jps
访问测试
访问http://localhost:9870
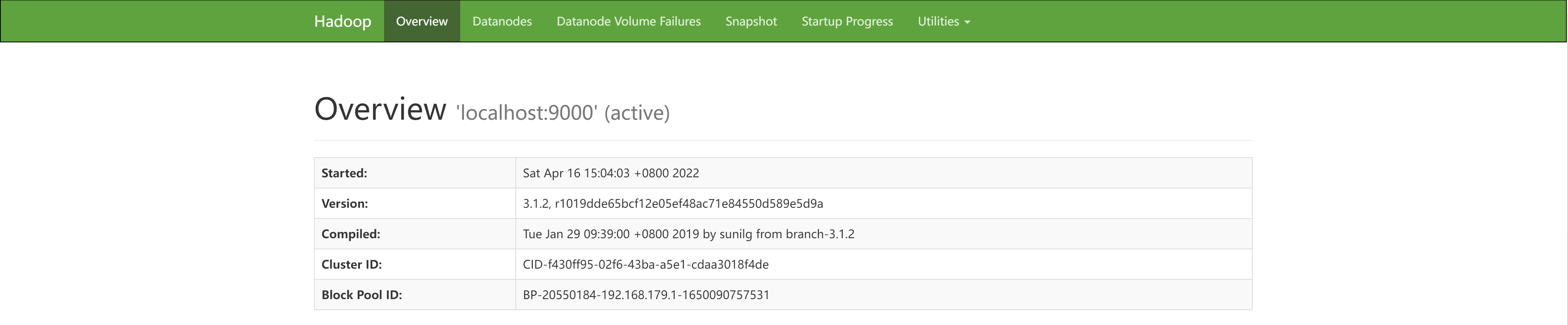
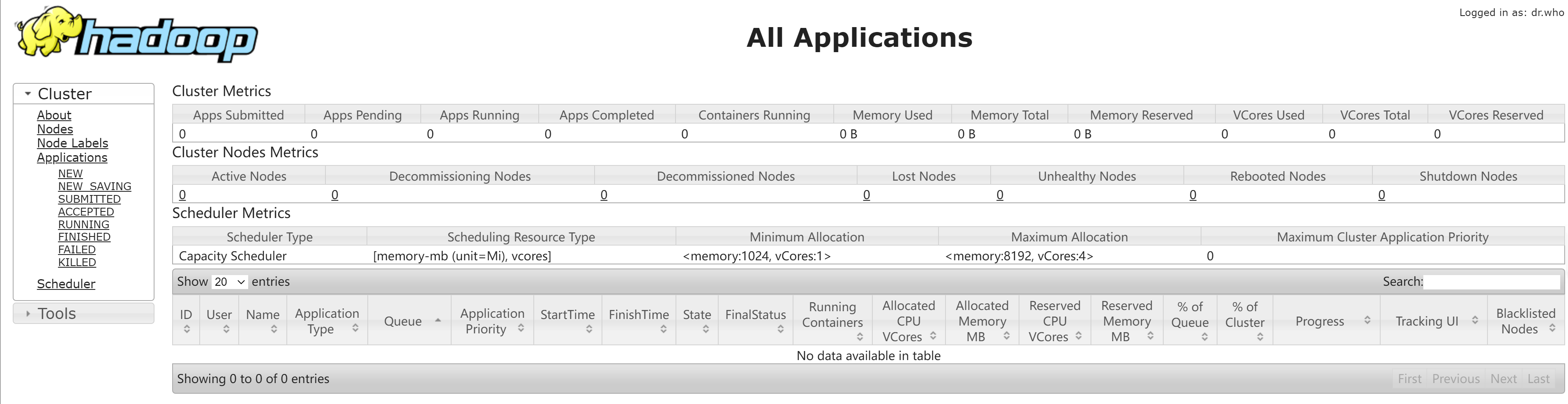
访问http://localhost:8088/cluster
Bug反馈记录
场景
由于重新安装系统,使用Windows11,安装Hadoop环境时参考上述安装配置步骤,最后发现HDFS相关组件无法启动,YARN相关组件正常启动。
看错误日志进行排查,结果未能发现有效问题,且网络搜索没有发现有效线索。断断续续折腾3次,后来在Hadoop的pull request处发现一个线索,执行winutils.exe文件是否报错,需要不报错、闪退即可。果断试试,发现还真存在该问题。

解决方案
方案A
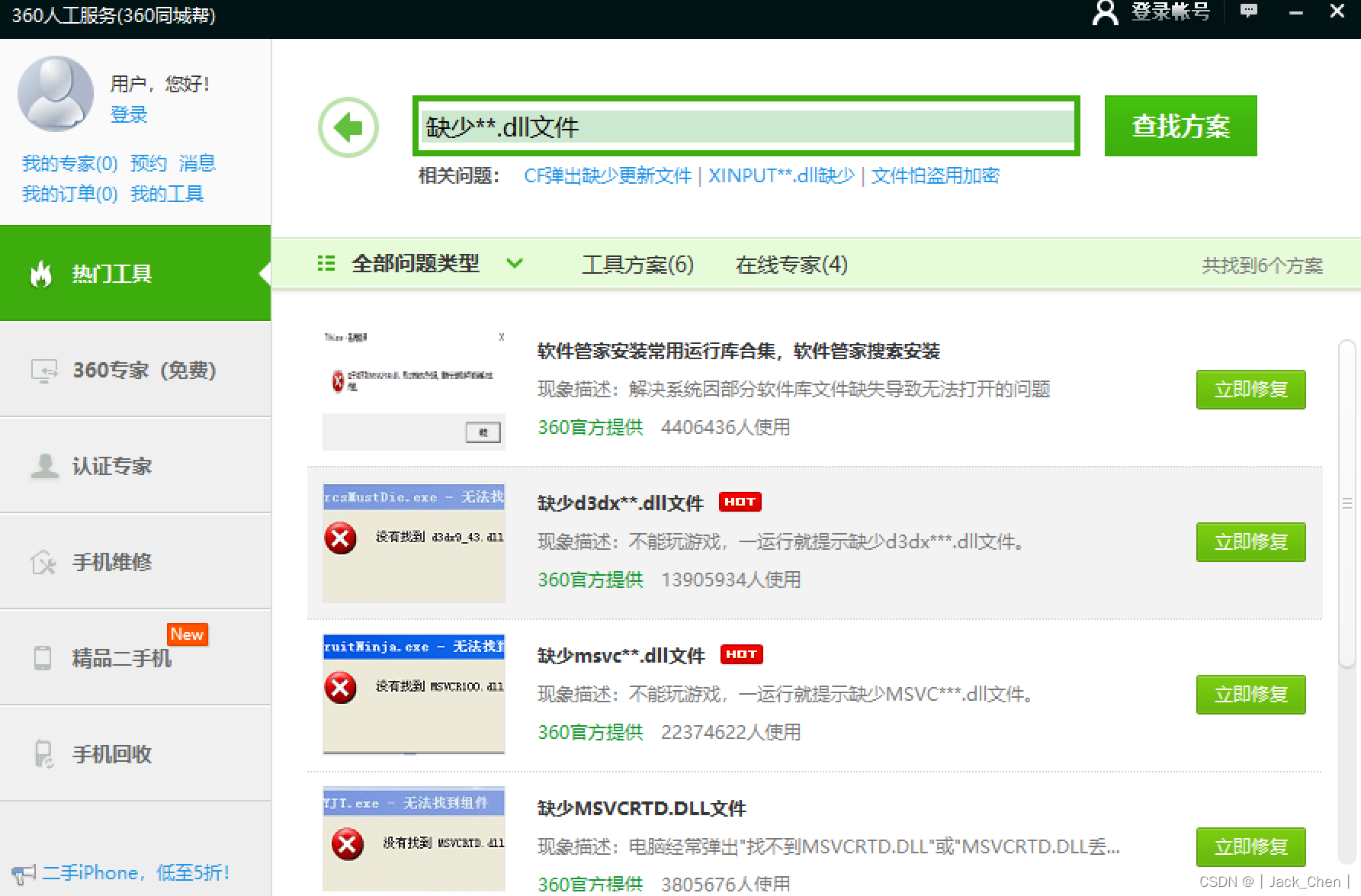
缺少MSVCR100.dll文件安装即可,记得360管家的人工服务里有修复服务
尝试了多个修复,依旧不行。
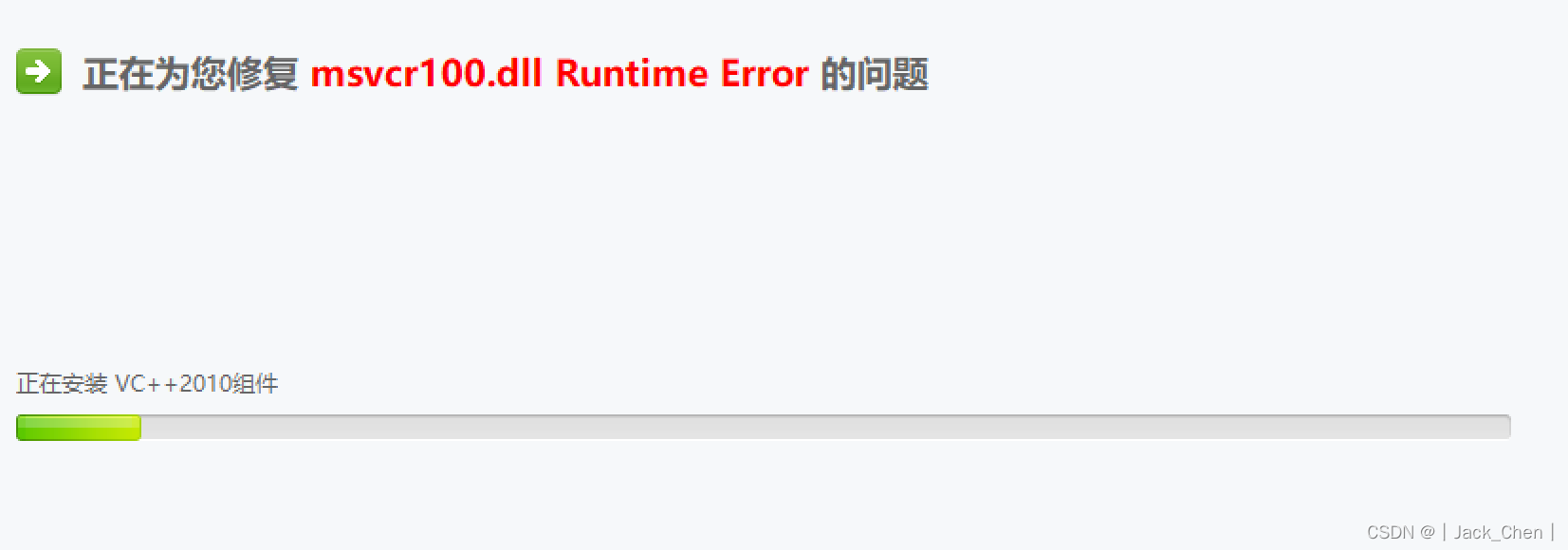
方案B
在360软件管家下载微软VC++运行库合集安装即可,
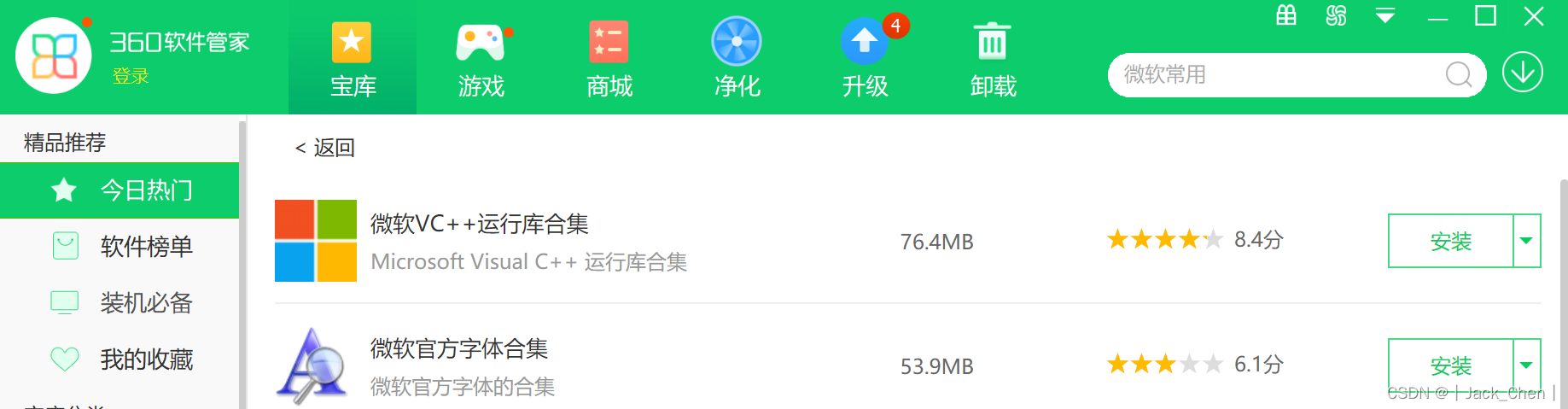
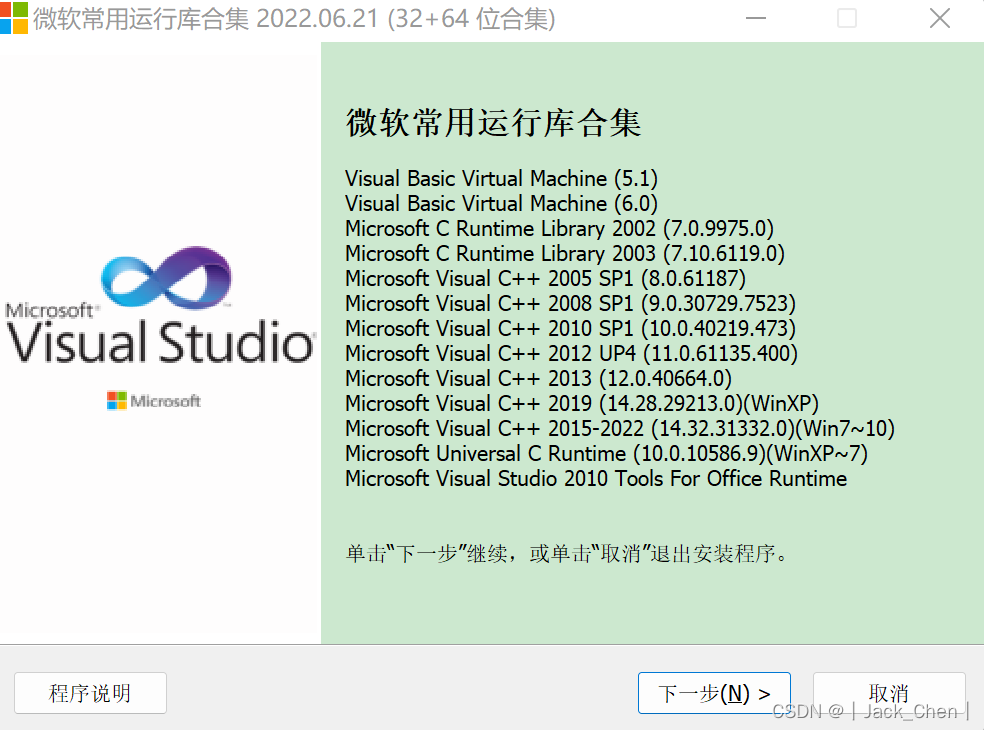
安装后,又提示安装如下图所示的东西,安装后重启电脑,启动Hadoop成功。

Windows本地开发
添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
</dependencies>
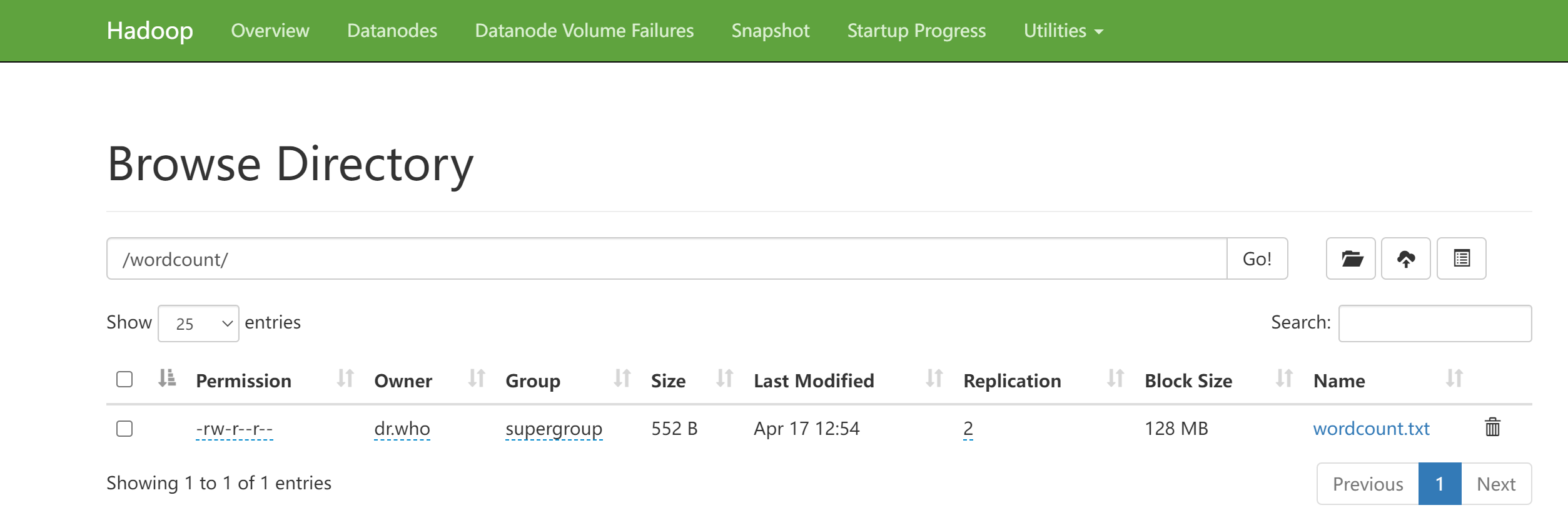
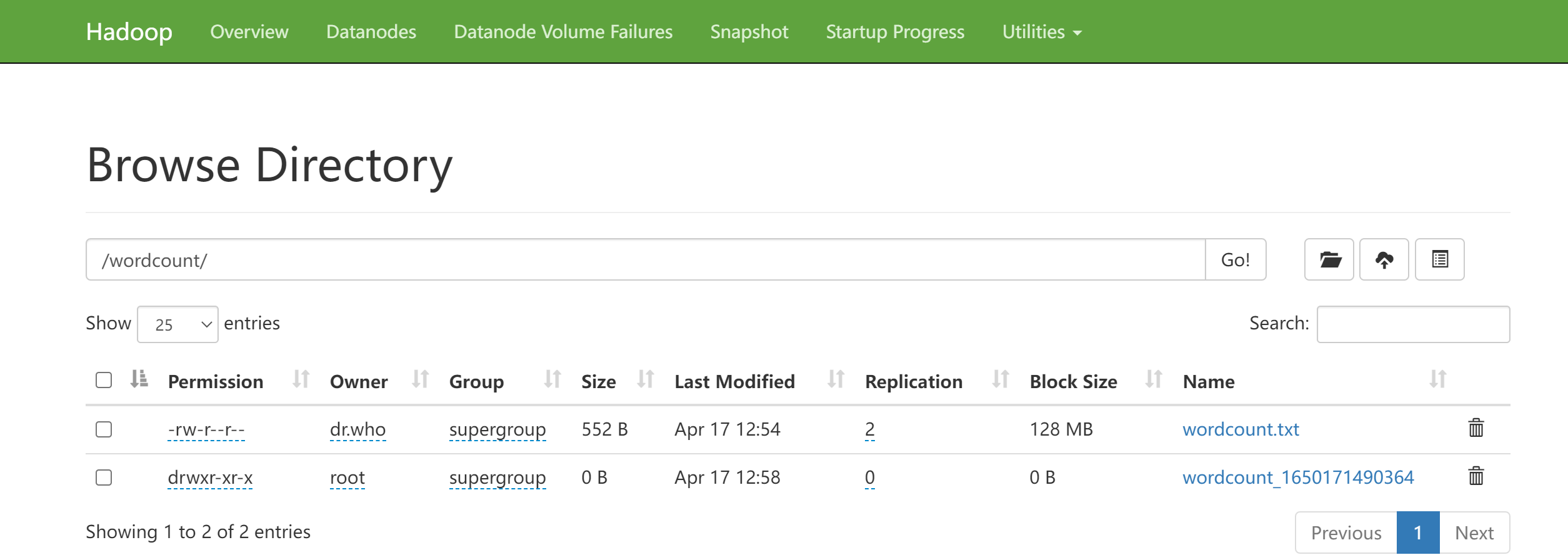
上传文件到HDFS
上传wordcount.txt文件到HDFS
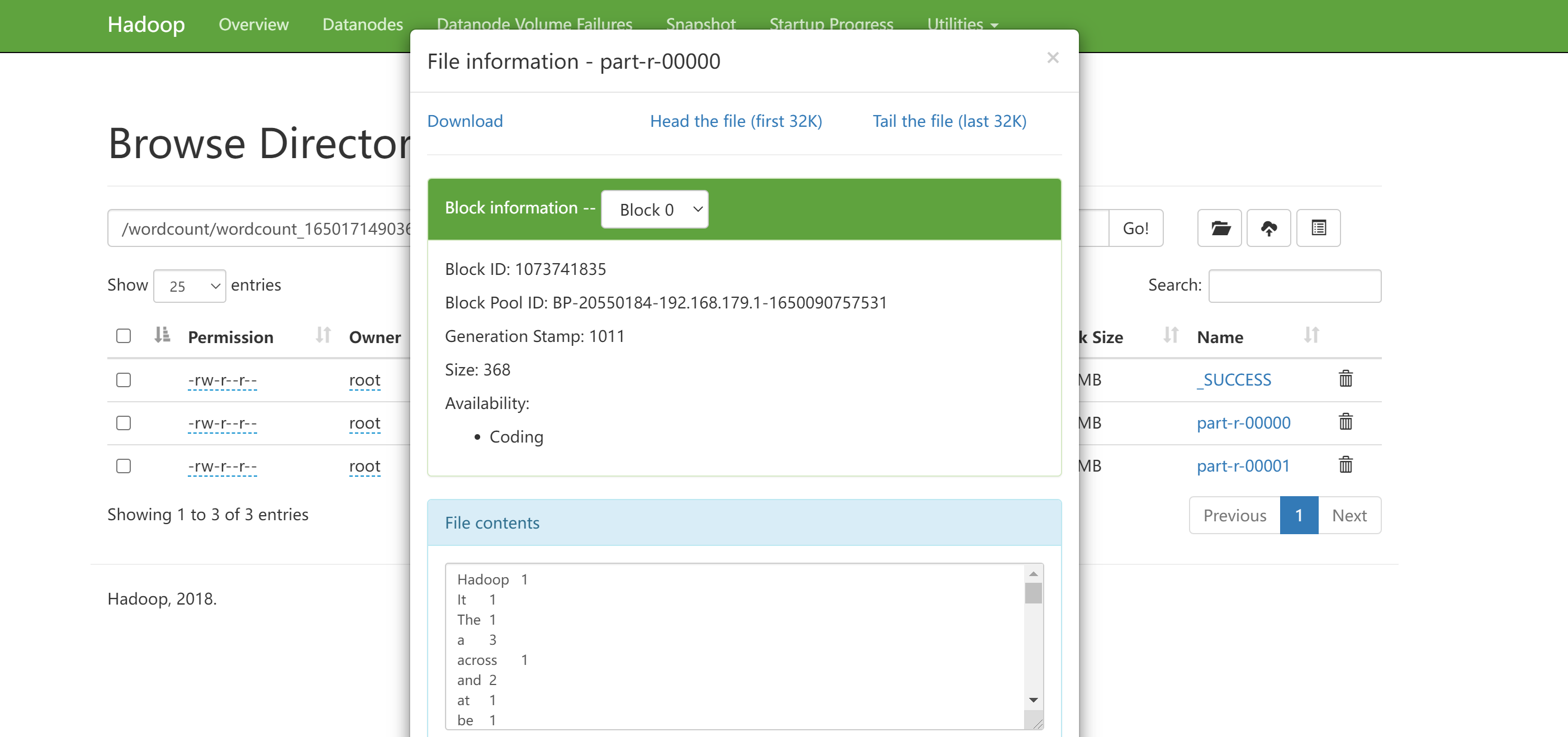
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
创建Job
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountJob {
public static void main(String[] args) throws Exception {
//获取配置文件
Configuration configuration = new Configuration(true);
//本地模式运行
configuration.set("mapreduce.framework.name", "local");
//创建任务
Job job = Job.getInstance(configuration);
//设置任务主类
job.setJarByClass(WordCountJob.class);
//设置任务
job.setJobName("wordcount-" + System.currentTimeMillis());
//设置Reduce的数量
job.setNumReduceTasks(2);
//设置数据的输入路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/wordcount.txt"));
//设置数据的输出路径
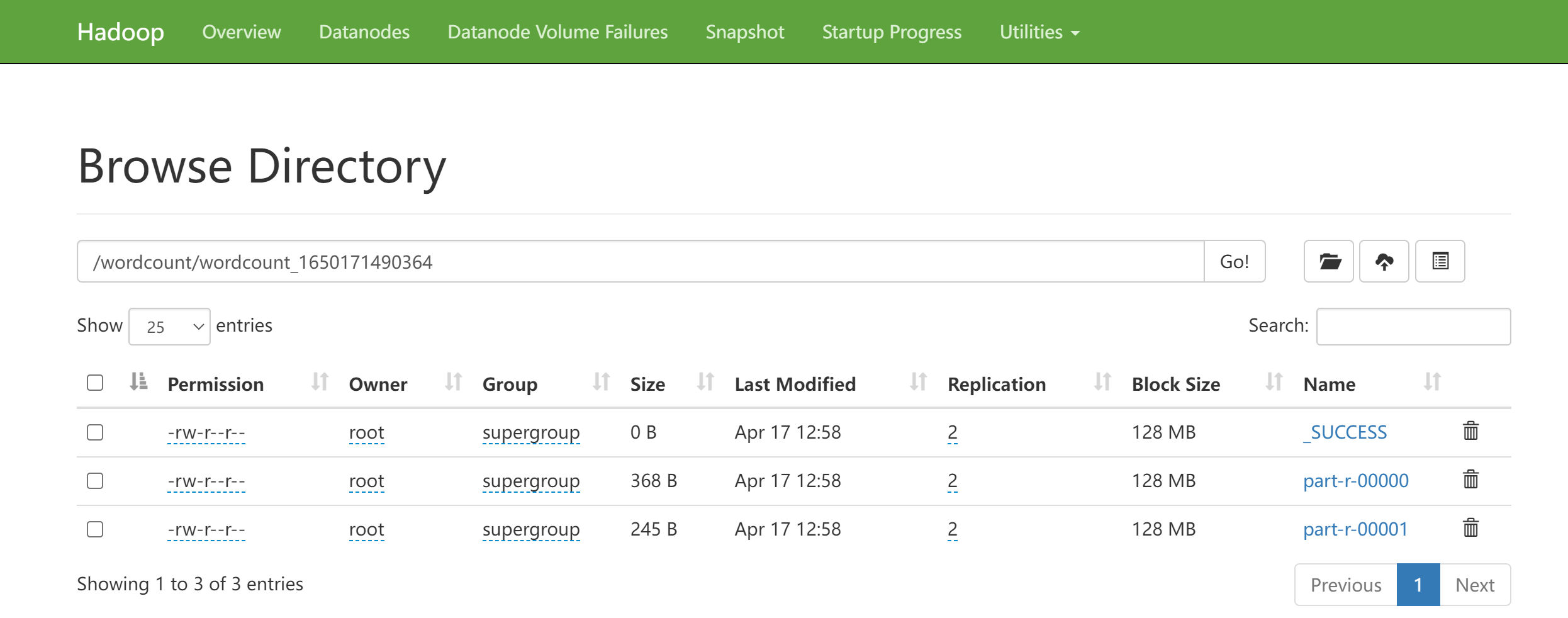
FileOutputFormat.setOutputPath(job, new Path("/wordcount/wordcount_" + System.currentTimeMillis()));
//设置Map的输入的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Map和Reduce的处理类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//提交任务
job.waitForCompletion(true);
}
}
创建Mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//创建对象
private IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String valueString = value.toString();
//切分字符串
String[] values = valueString.split(" ");
//向context添加数据
for (String val : values) {
context.write(new Text(val), one);
}
}
}
创建Reducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//获取迭代器对象
Iterator<IntWritable> iterator = values.iterator();
// 相同单词计数累加
int count = 0;
while (iterator.hasNext()) {
count += iterator.next().get();
}
//输出数据
context.write(key, new IntWritable(count));
}
}
添加配置文件
在资源resources目录,添加Hadoop相关配置文件
yarn-site.xml
core-site.xml
hdfs-site.xml
mapred-site.xml
执行Job
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/136981.html

