
Apache Druid单机环境搭建及基本使用
Apache Druid
Apache Druid概述
Apache Druid是一个实时分析型数据库,旨在对大型数据集进行快速的查询分析(”OLAP”查询)。Druid最常被当做数据库来用以支持实时摄取、高性能查询和高稳定运行的应用场景,同时,Druid也通常被用来助力分析型应用的图形化界面,或者当做需要快速聚合的高并发后端API,Druid最适合应用于面向事件类型的数据。
Druid的特点
列式存储,Druid使用列式存储,这意味着在一个特定的数据查询中它只需要查询特定的列,这样极地提高了部分列查询场景的性能。另外,每一列数据都针对特定数据类型做了优化存储,从而支持快速的扫描和聚合。
可扩展的分布式系统,Druid通常部署在数十到数百台服务器的集群中,并且可以提供每秒数百万条记录的接收速率,数万亿条记录的保留存储以及亚秒级到几秒的查询延迟。
大规模并行处理,Druid可以在整个集群中并行处理查询。
实时或批量摄取,Druid可以实时(已经被摄取的数据可立即用于查询)或批量摄取数据。
自修复、自平衡、易于操作,作为集群运维操作人员,要伸缩集群只需添加或删除服务,集群就会在后台自动重新平衡自身,而不会造成任何停机。如果任何一台Druid服务器发生故障,系统将自动绕过损坏。 Druid设计为7*24全天候运行,无需出于任何原因而导致计划内停机,包括配置更改和软件更新。
不会丢失数据的云原生容错架构,一旦Druid摄取了数据,副本就安全地存储在深度存储介质(通常是云存储,HDFS或共享文件系统)中。即使某个Druid服务发生故障,也可以从深度存储中恢复您的数据。对于仅影响少数Druid服务的有限故障,副本可确保在系统恢复时仍然可以进行查询。
用于快速过滤的索引,Druid使用CONCISE或Roaring压缩的位图索引来创建索引,以支持快速过滤和跨多列搜索。
基于时间的分区,Druid首先按时间对数据进行分区,另外同时可以根据其他字段进行分区。这意味着基于时间的查询将仅访问与查询时间范围匹配的分区,这将大大提高基于时间的数据的性能。
近似算法,Druid应用了近似count-distinct,近似排序以及近似直方图和分位数计算的算法。这些算法占用有限的内存使用量,通常比精确计算要快得多。对于精度要求比速度更重要的场景,Druid还提供了精确count-distinct和精确排序。
摄取时自动汇总聚合,Druid支持在数据摄取阶段可选地进行数据汇总,这种汇总会部分预先聚合您的数据,并可以节省大量成本并提高性能。
应用场景
什么场景下应该使用Druid
数据插入频率比较高,但较少更新数据
大多数查询场景为聚合查询和分组查询(GroupBy),同时还有一定得检索与扫描查询
将数据查询延迟目标定位100毫秒到几秒钟之间
数据具有时间属性(Druid针对时间做了优化和设计)
在多表场景下,每次查询仅命中一个大的分布式表,查询又可能命中多个较小的lookup表
场景中包含高基维度数据列(例如URL,用户ID等),并且需要对其进行快速计数和排序
需要从Kafka、HDFS、对象存储(如Amazon S3)中加载数据
Druid通常应用于以下场景:
点击流分析(Web端和移动端)
网络监测分析(网络性能监控)
服务指标存储
供应链分析(制造类指标)
应用性能指标分析
数字广告分析
商务智能 / OLAP
架构设计
Druid有一个多进程、分布式的架构,该架构设计为云友好且易于操作。每个Druid进程都可以独立配置和扩展,在集群上提供最大的灵活性。这种设计还提供了增强的容错能力:一个组件的中断不会立即影响其他组件。
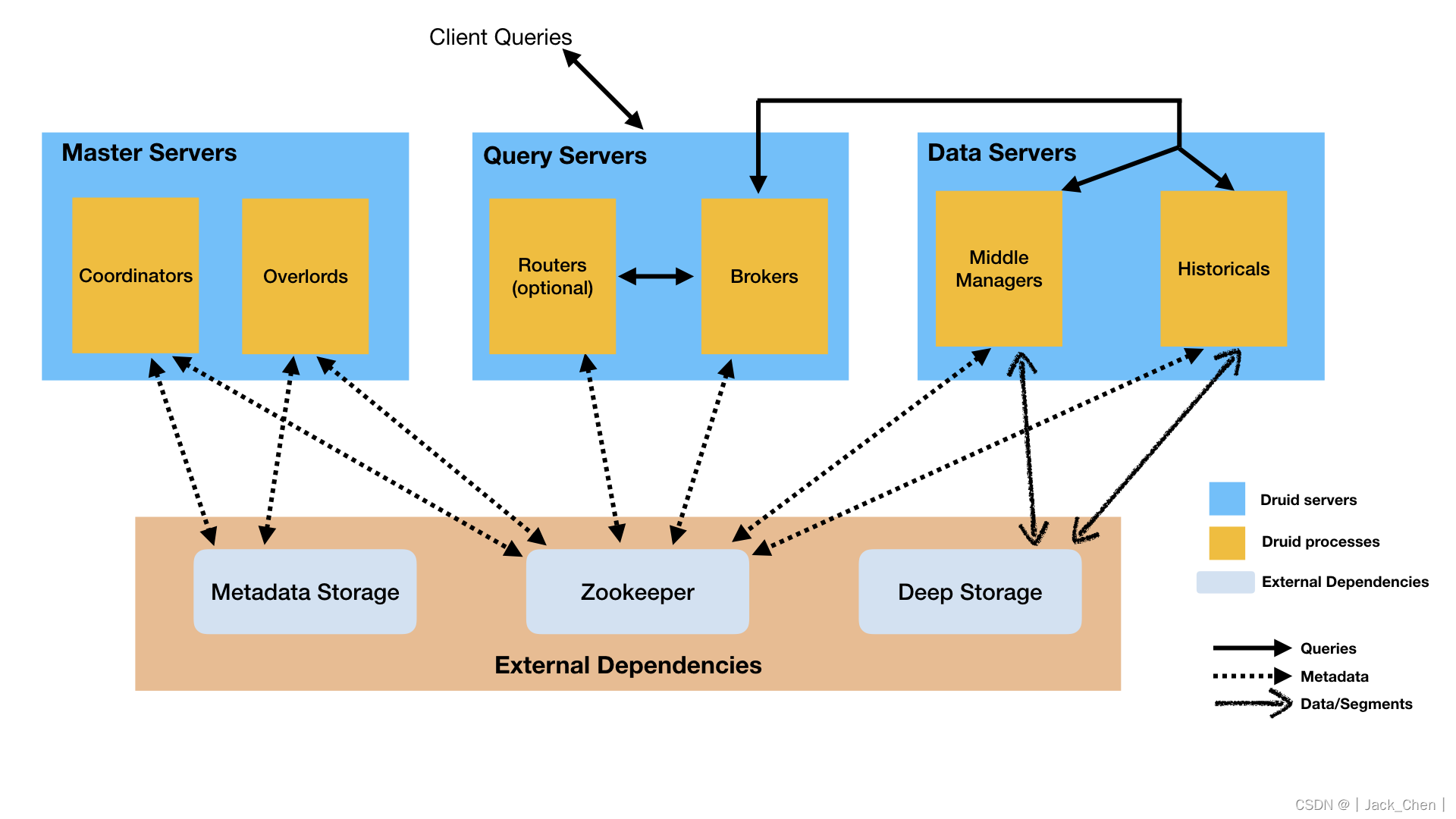
进程与服务
Druid有若干不同类型的进程,简单描述如下:
Coordinator 进程管理集群中数据的可用性
Overlord 进程控制数据摄取负载的分配
Broker 进程处理来自外部客户端的查询请求
Router 进程是一个可选进程,可以将请求路由到Brokers、Coordinators和Overlords
Historical 进程存储可查询的数据
MiddleManager 进程负责摄取数据
Druid进程可以按照喜欢的方式部署,但是为了便于部署,建议将它们组织成三种服务器类型:Master、Query和Data。
Master: 运行Coordinator和Overlord进程,管理数据可用性和摄取
Query: 运行Broker和可选的Router进程,处理来自外部客户端的请求
Data: 运行Historical和MiddleManager进程,执行摄取负载和存储所有可查询的数据
存储设计
更多概述参考中文网址:http://www.apache-druid.cn/…
Apache Druid的搭建
安装JDK
Druid服务运行依赖Java 8,下载安装JDK:https://www.oracle.com/java/technologies/downloads/#java8
解压到合适目录
tar -zxvf jdk-8u311-linux-x64.tar.gz -C /usr/local/
cd /usr/local
mv jdk1.8.0_311 jdk1.8
设置环境变量
export JAVA_HOME=/usr/local/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
配置生效命令
source /etc/profile
验证是否安装成功
java
javac
java -version
安装Druid
安装及使用参考中文网址:http://www.apache-druid.cn/
# wget https://archive.apache.org/dist/druid/0.17.0/apache-druid-0.17.0-bin.tar.gz
下载文档中的0.17版本在使用中存在问题,坑了许久,从新从官网下载最新版本0.22.1使用,暂未发现任何问题。
官网:https://druid.apache.org/
各个版本集合:https://archive.apache.org/dist/druid/
tar -zxvf apache-druid-0.17.0-bin.tar.gz
mv apache-druid-0.17.0/ druid
[root@administrator program]# cd druid
[root@administrator druid]# ls
bin conf extensions hadoop-dependencies lib LICENSE licenses NOTICE quickstart README
在安装包中有以下文件:
bin 启停等脚本
conf 用于单节点部署和集群部署的示例配置
extensions Druid核心扩展
hadoop-dependencies Druid Hadoop依赖
lib Druid核心库和依赖
quickstart 配置文件,样例数据,以及快速入门教材的其他文件
单服务器参考配置
Nano-Quickstart: 1 CPU, 4GB 内存
启动命令: bin/start-nano-quickstart
配置目录: conf/druid/single-server/nano-quickstart
Micro-Quickstart: 4 CPU, 16GB 内存
启动命令: bin/start-micro-quickstart
配置目录: conf/druid/single-server/micro-quickstart
Small: 8 CPU, 64GB 内存 (~i3.2xlarge)
启动命令: bin/start-small
配置目录: conf/druid/single-server/small
Medium: 16 CPU, 128GB 内存 (~i3.4xlarge)
启动命令: bin/start-medium
配置目录: conf/druid/single-server/medium
Large: 32 CPU, 256GB 内存 (~i3.8xlarge)
启动命令: bin/start-large
配置目录: conf/druid/single-server/large
X-Large: 64 CPU, 512GB 内存 (~i3.16xlarge)
启动命令: bin/start-xlarge
配置目录: conf/druid/single-server/xlarge
[root@administrator druid]# ./bin/start-nano-quickstart
[Fri Dec 24 10:52:06 2021] Running command[zk], logging to[/usr/local/program/druid/var/sv/zk.log]: bin/run-zk conf
[Fri Dec 24 10:52:06 2021] Running command[coordinator-overlord], logging to[/usr/local/program/druid/var/sv/coordinator-overlord.log]: bin/run-druid coordinator-overlord conf/druid/single-server/nano-quickstart
[Fri Dec 24 10:52:06 2021] Running command[broker], logging to[/usr/local/program/druid/var/sv/broker.log]: bin/run-druid broker conf/druid/single-server/nano-quickstart
[Fri Dec 24 10:52:06 2021] Running command[router], logging to[/usr/local/program/druid/var/sv/router.log]: bin/run-druid router conf/druid/single-server/nano-quickstart
[Fri Dec 24 10:52:06 2021] Running command[historical], logging to[/usr/local/program/druid/var/sv/historical.log]: bin/run-druid historical conf/druid/single-server/nano-quickstart
[Fri Dec 24 10:52:06 2021] Running command[middleManager], logging to[/usr/local/program/druid/var/sv/middleManager.log]: bin/run-druid middleManager conf/druid/single-server/nano-quickstart
访问:IP:8888
数据加载
使用Data Loader来加载数据
点击Load data进入加载数据页面,选择 Local disk 然后点击 Connect data
官方提供了一个示例数据文件,其中包含2015年9月12日发生的Wikipedia页面编辑事件。该样本数据位于Druid包根目录的quickstart/tutorial/wikiticker-2015-09-12-sampled.json.gz中,页面编辑事件作为JSON对象存储在文本文件中。
[root@administrator druid]# ll ./quickstart/tutorial/
总用量 2412
-rw-r--r-- 1 501 wheel 295 1月 22 2020 compaction-day-granularity.json
-rw-r--r-- 1 501 wheel 1428 1月 22 2020 compaction-init-index.json
.........
-rw-r--r-- 1 501 wheel 2366222 1月 22 2020 wikiticker-2015-09-12-sampled.json.gz
[root@administrator druid]#
在 Base directory 中输入 quickstart/tutorial/ 在 File filter 中选择 wikiticker-2015-09-12-sampled.json.gz 或输入文件名称然后点击Apply确保看到的数据是正确的
点击Next:Parse data
数据加载器将尝试自动为数据确定正确的解析器。在这种情况下,它将成功确定json。可以随意使用不同的解析器选项来预览Druid如何解析您的数据。
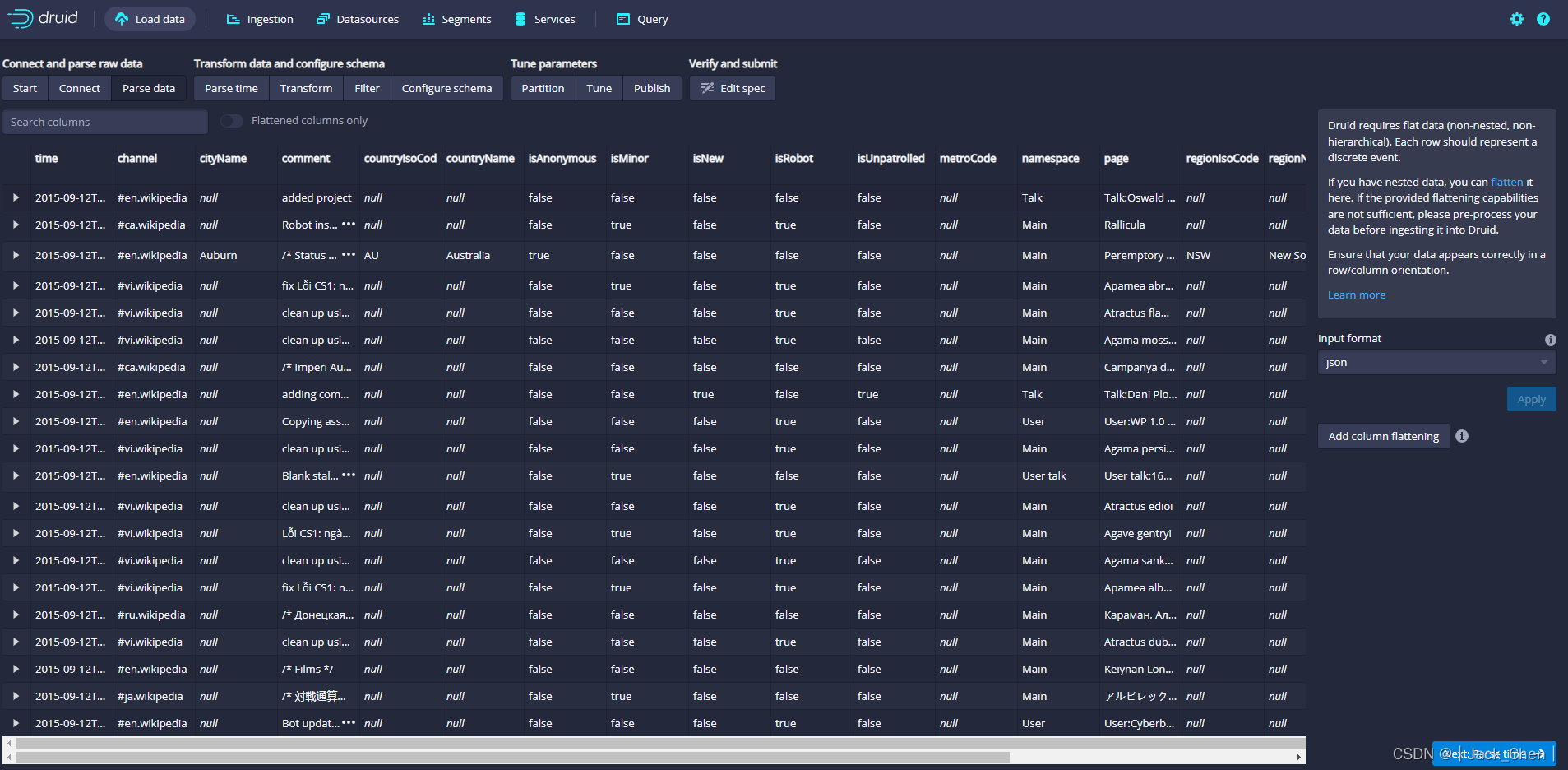
点击Next:Parse time,决定主时间列
Druid的体系结构需要一个主时间列(内部存储为名为__time的列)。如果您的数据中没有时间戳,请选择 固定值(Constant Value) 。在我们的示例中,数据加载器将确定原始数据中的时间列是唯一可用作主时间列的候选者。
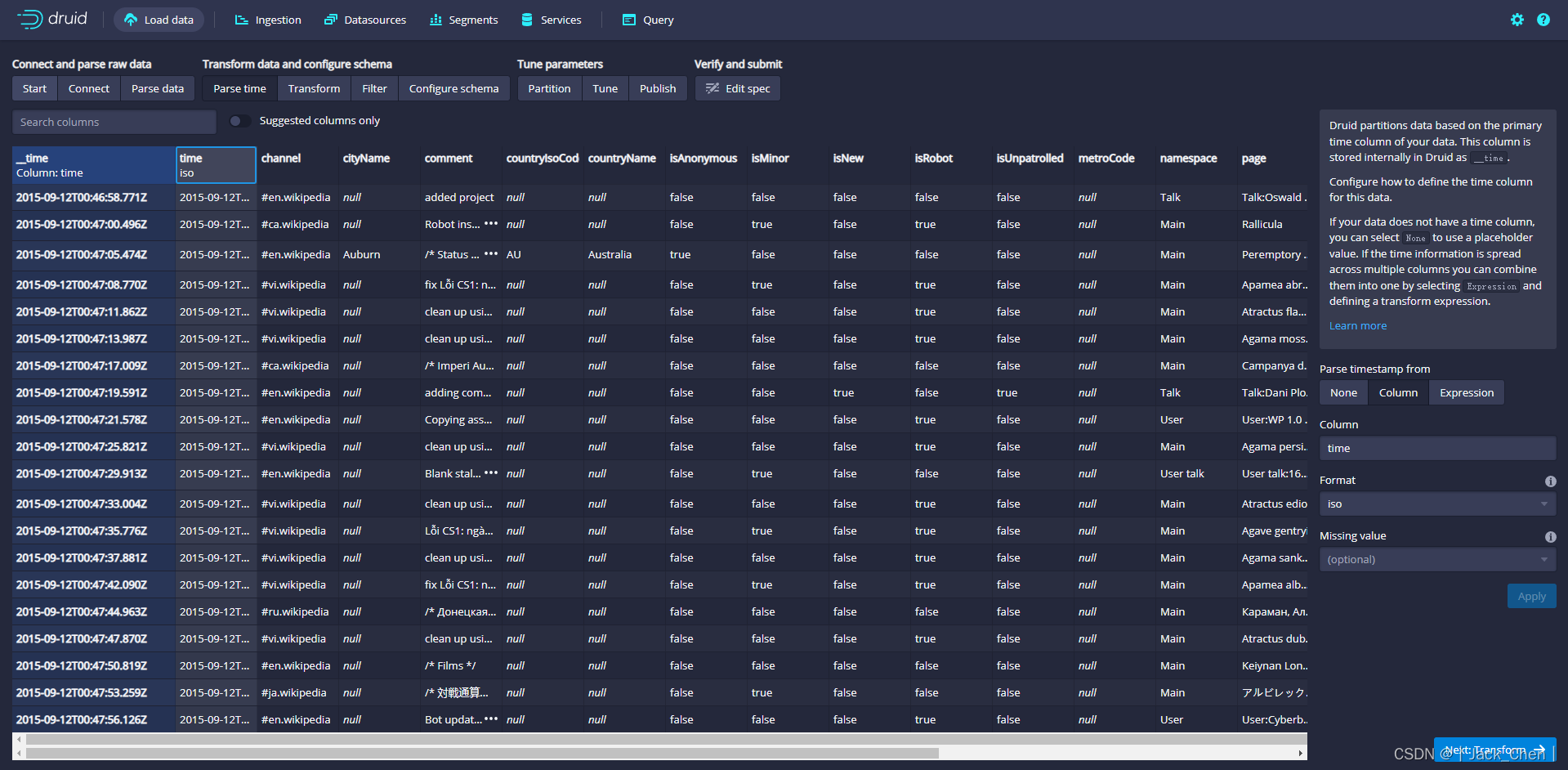
点击Next:Transform,设置使用摄取时间变换
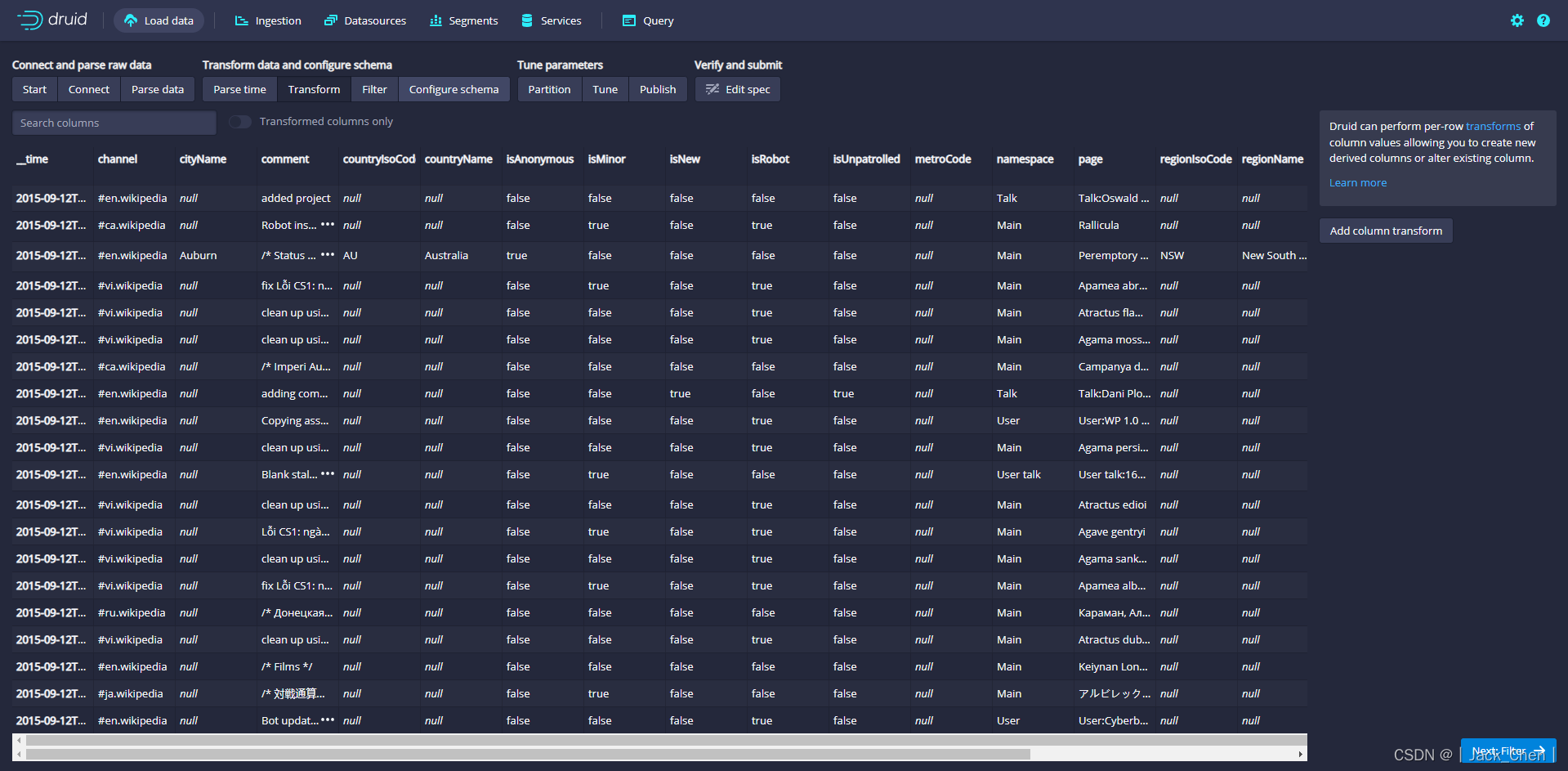
点击Next:Filter,设置过滤器
点击Next:Configure schema
配置将哪些维度和指标摄入到Druid中,这些正是数据在被Druid中摄取后出现的样子。 由于数据集非常小,关掉rollup、确认更改。
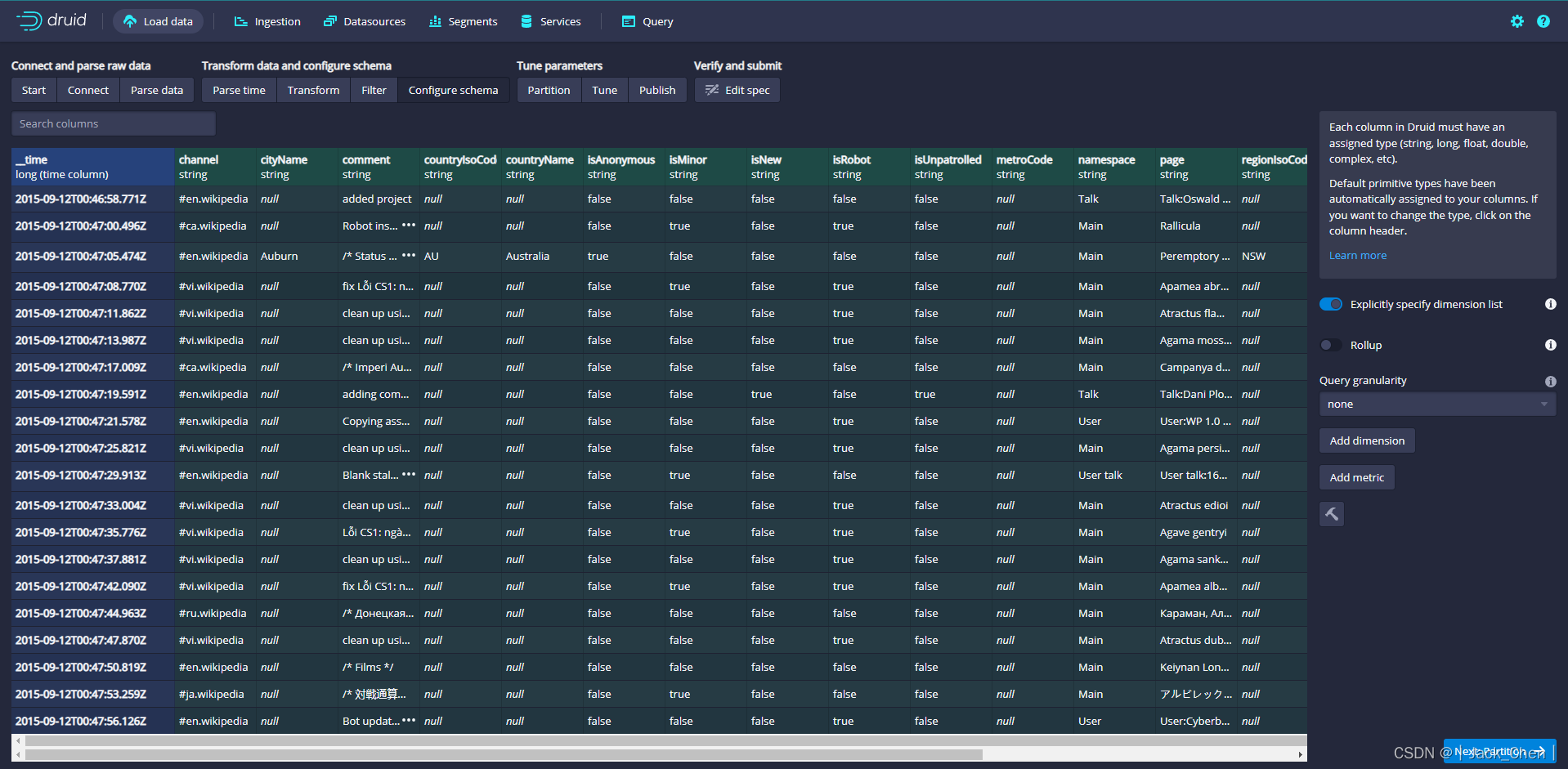
点击Next:Partition,调整数据如何划分为段文件的方式
调整如何在Druid中将数据拆分为多个段。 由于这是一个很小的数据集,因此在此步骤中无需进行任何调整。
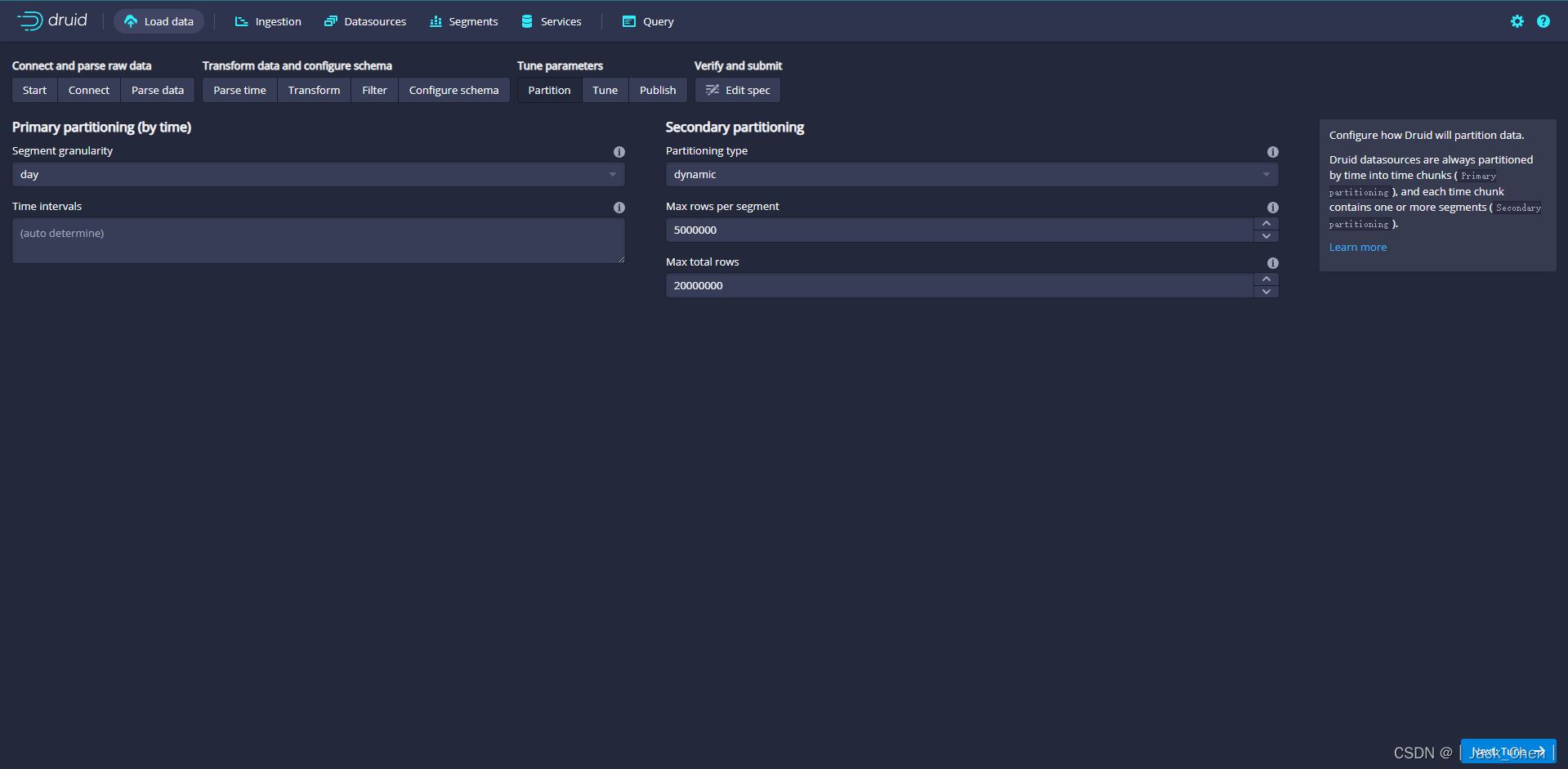
点击Next:Tune
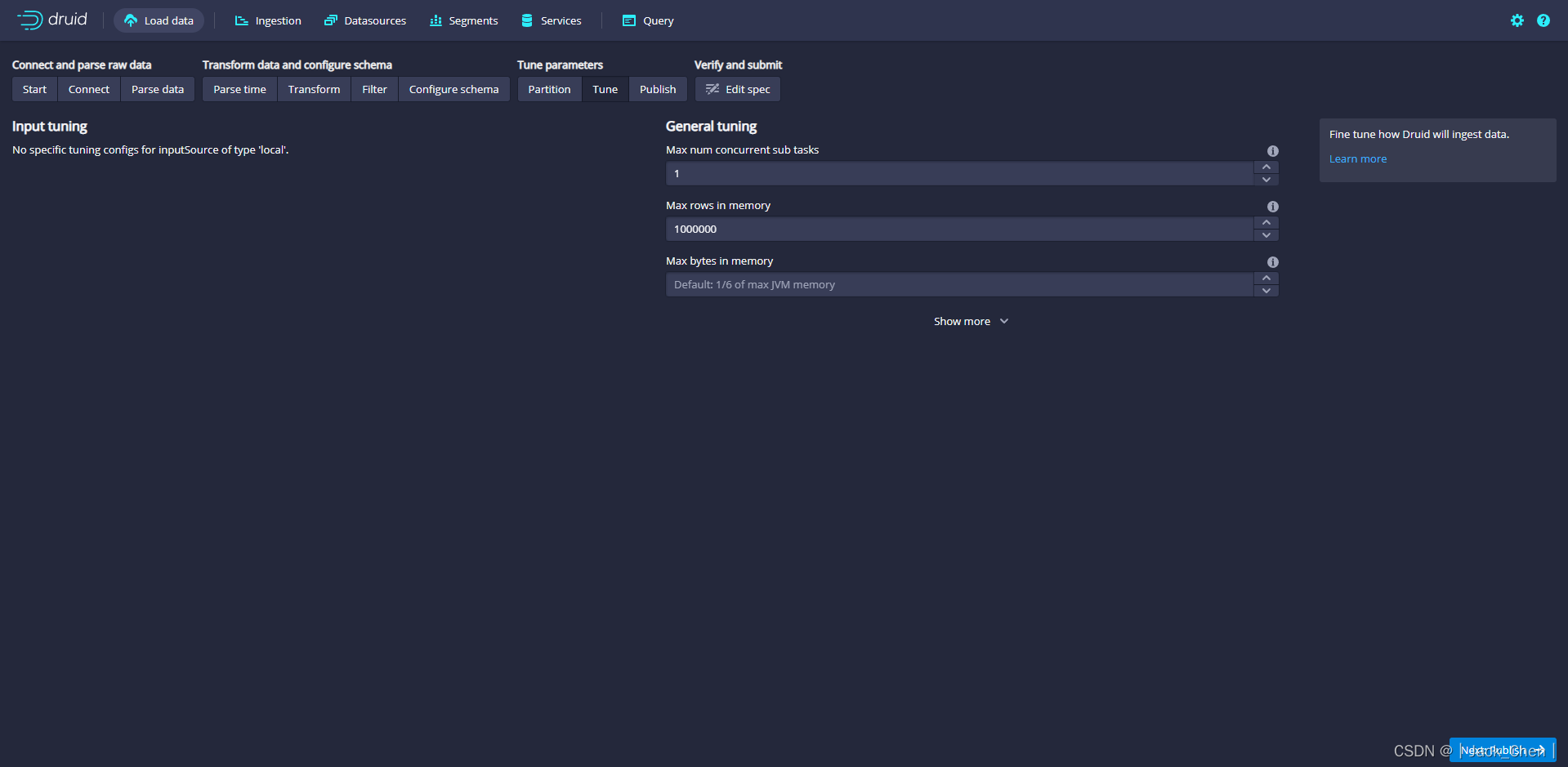
点击Next:Publish
指定Druid中的数据源名称,将此数据源命名为 wikiticker
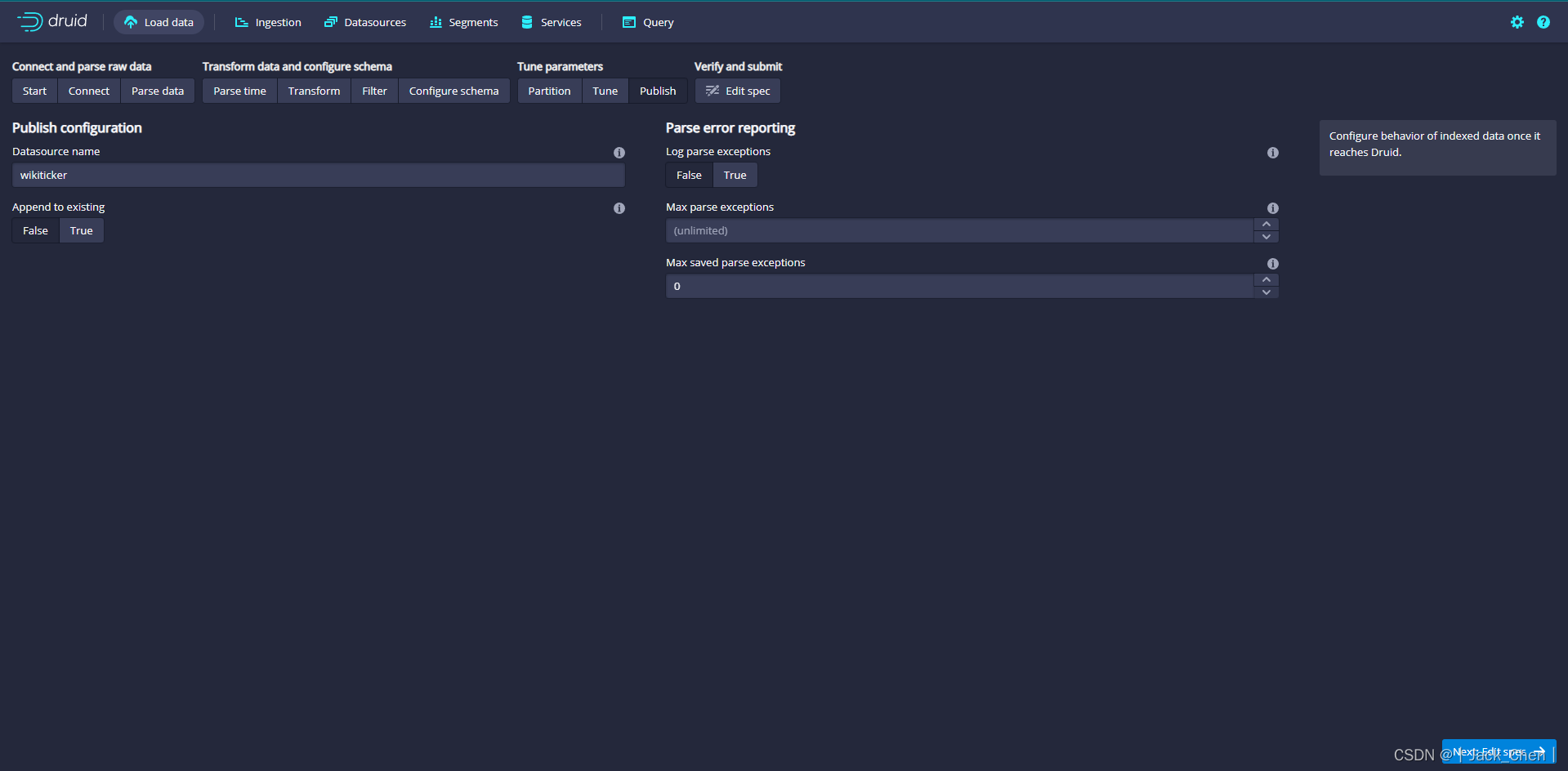
点击Next:Edit JSON spec,查看摄取规范
得到数据摄取规范JSON,由前面每个页面设置的参数最终生成了当前的json数据。
该JSON就是构建的规范,为了查看更改将如何更新规范是可以随意返回之前的步骤中进行更改,同样,也可以直接编辑规范,并在前面的步骤中看到它。
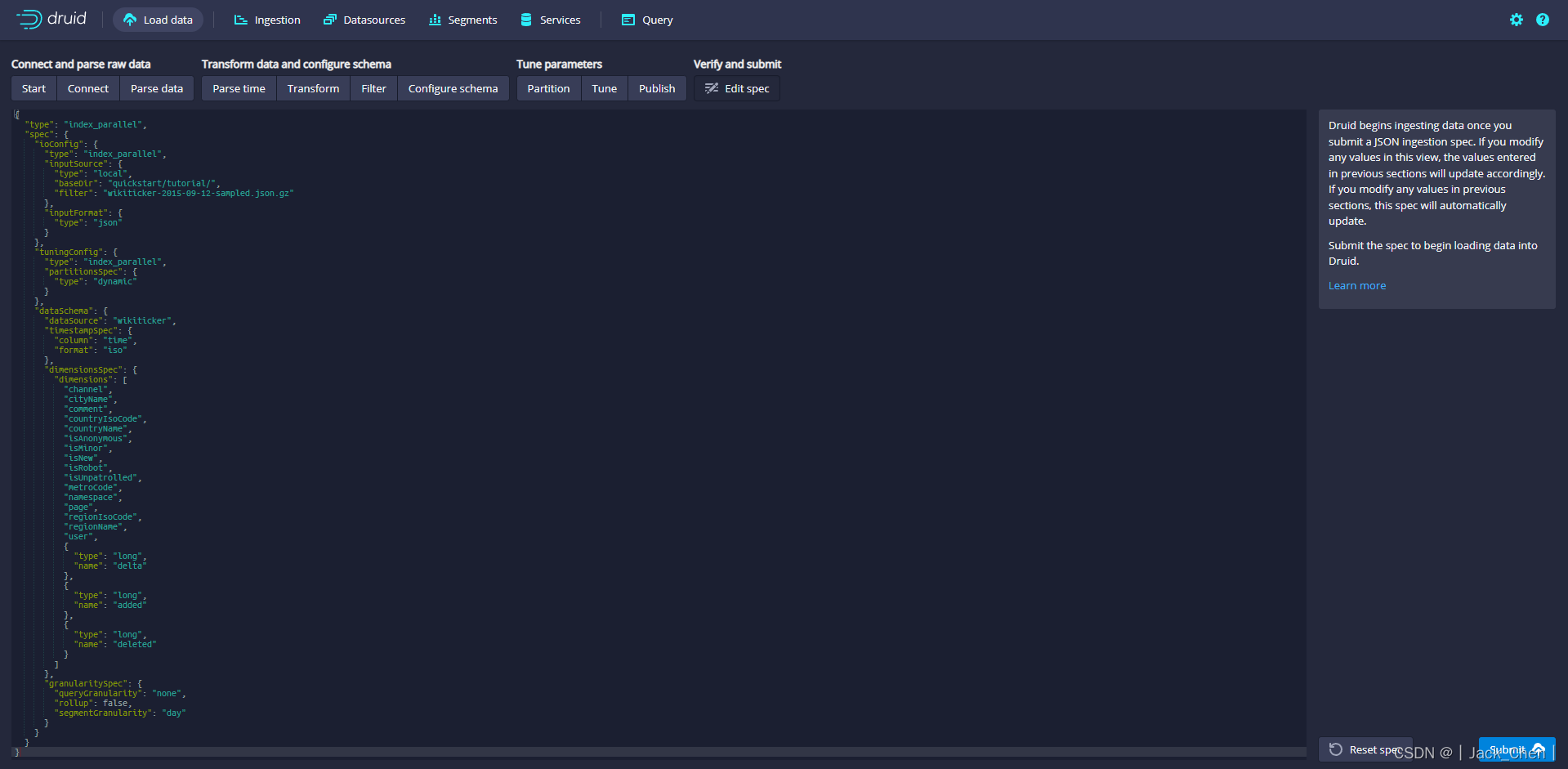
对摄取规范感到满意后,请单击 Submit,然后将创建一个数据摄取任务,跳转到任务页面
当一项任务成功完成时,意味着它建立了一个或多个段,这些段现在将由Data服务器接收。
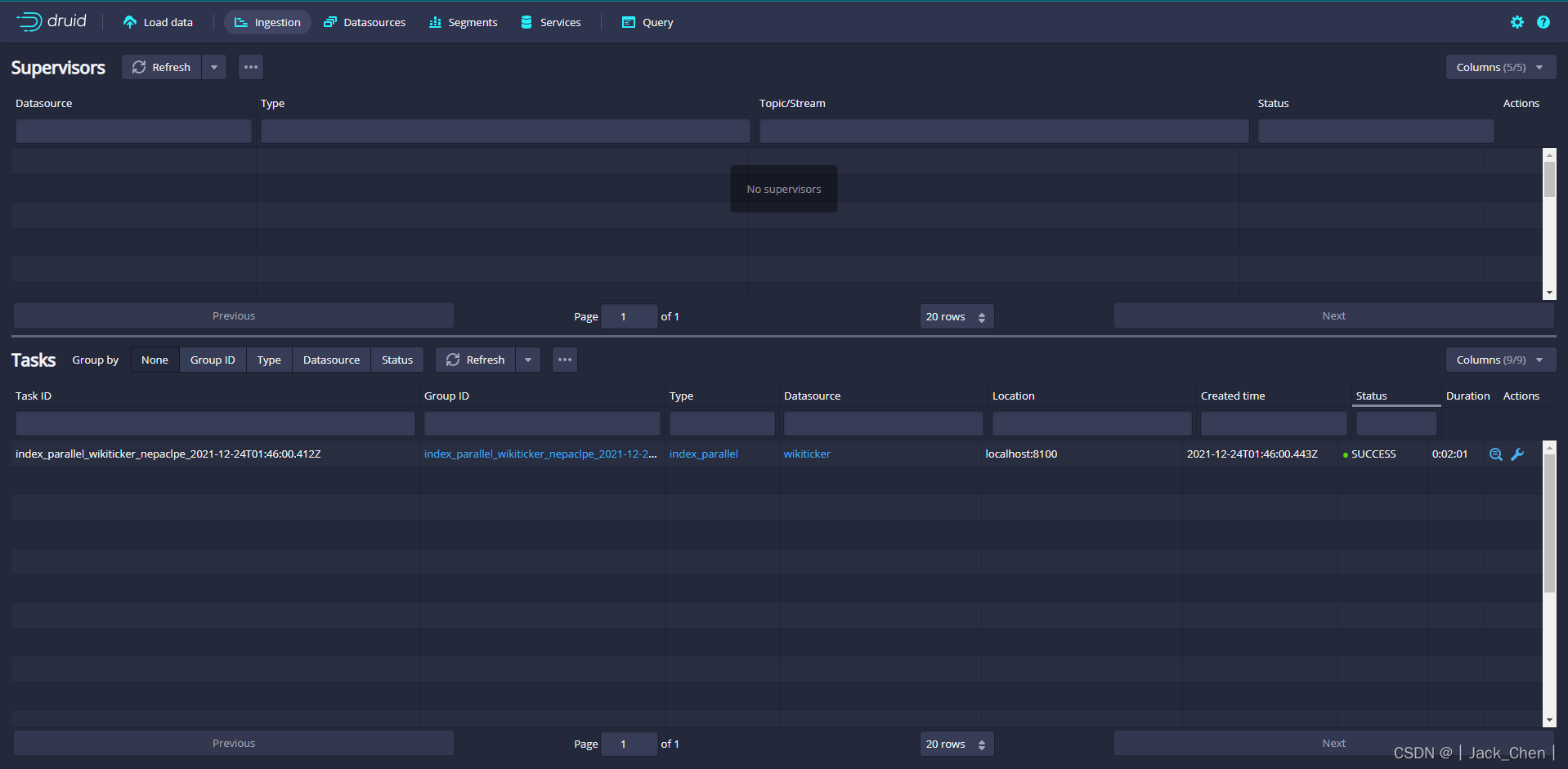
任务执行完成后,点击Datasources进入数据源页面,可以看到wikiticker数据源
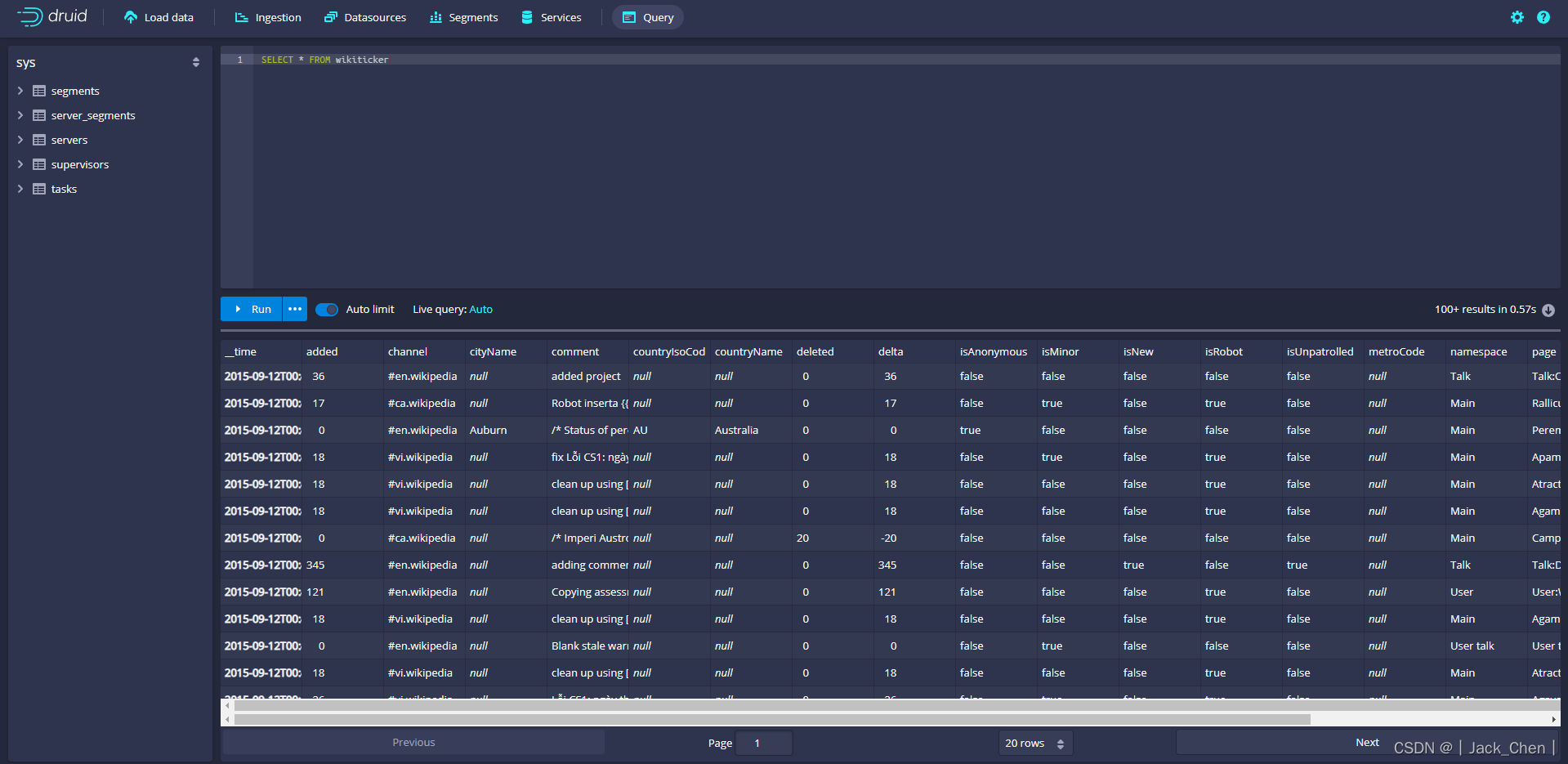
等待直到数据源(wikiticker)出现,加载段时可能需要几秒钟。一旦看到绿色(完全可用)圆圈,就可以查询数据源。此时,可以转到 Query 视图以对数据源运行SQL查询。

点击Query进入数据查询页面,可以查询数据
使用spec加载数据(通过控制台)
Druid的安装包中在 quickstart/tutorial/wikipedia-index.json 文件中包含了一个本地批摄入任务规范的示例。 该规范已经配置好读取 quickstart/tutorial/wikiticker-2015-09-12-sampled.json.gz 输入文件。
该规范将创建一个命名为”wikipedia”的数据源
[root@administrator druid]# cat ./quickstart/tutorial/wikipedia-index.json
{
"type" : "index_parallel",
"spec" : {
"dataSchema" : {
"dataSource" : "wikipedia",
"timestampSpec": {
"column": "time",
"format": "iso"
},
"dimensionsSpec" : {
"dimensions" : [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{ "name": "added", "type": "long" },
{ "name": "deleted", "type": "long" },
{ "name": "delta", "type": "long" }
]
},
"metricsSpec" : [],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2015-09-12/2015-09-13"],
"rollup" : false
}
},
"ioConfig" : {
"type" : "index_parallel",
"inputSource" : {
"type" : "local",
"baseDir" : "quickstart/tutorial/",
"filter" : "wikiticker-2015-09-12-sampled.json.gz"
},
"inputFormat" : {
"type" : "json"
},
"appendToExisting" : false
},
"tuningConfig" : {
"type" : "index_parallel",
"maxRowsPerSegment" : 5000000,
"maxRowsInMemory" : 25000
}
}
}
[root@administrator druid]#
在”Tasks”页面,点击 Submit task 后选择 Raw JSON task
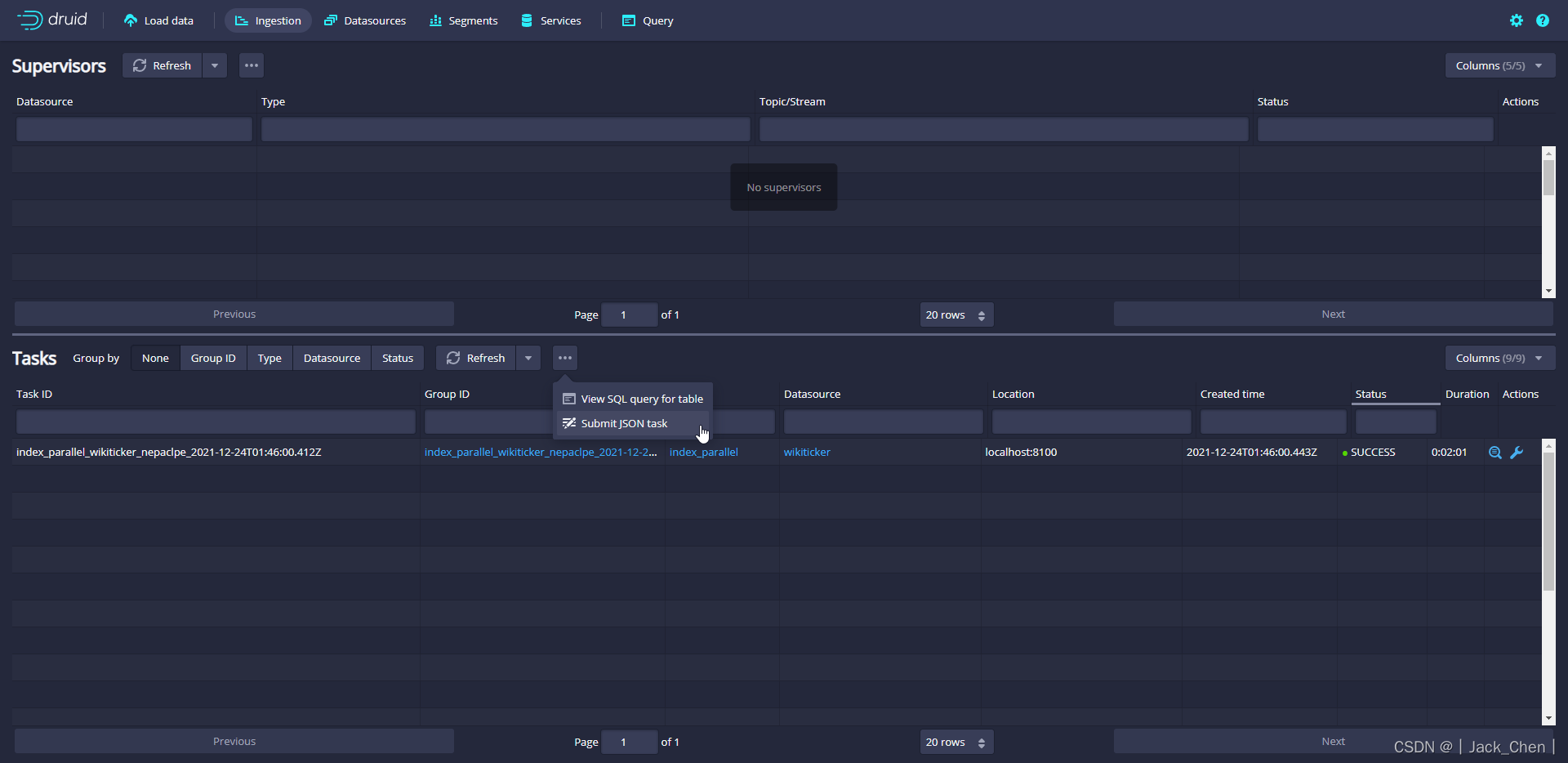
在输入框中输入数据提取规范
提交任务规范后,按照上述相同的规范等待数据加载然后查询。
使用spec加载数据(通过命令行)
在Druid的软件包中提供了一个批摄取的帮助脚本 bin/post-index-task
该脚本会将数据摄取任务发布到Druid Overlord并轮询Druid,直到可以查询数据为止。
在Druid根目录运行以下命令:
bin/post-index-task --file quickstart/tutorial/wikipedia-index.json --url http://localhost:8081
[root@administrator druid]# bin/post-index-task --file quickstart/tutorial/wikipedia-index.json --url http://localhost:8081
Beginning indexing data for wikipedia
Task started: index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z
Task log: http://localhost:8081/druid/indexer/v1/task/index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z/log
Task status: http://localhost:8081/druid/indexer/v1/task/index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z/status
Task index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z still running...
Task index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z still running...
Task index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z still running...
Task index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z still running...
Task index_parallel_wikipedia_hiapdgph_2021-12-24T02:22:25.778Z still running...
Task finished with status: SUCCESS
Completed indexing data for wikipedia. Now loading indexed data onto the cluster...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia loading complete! You may now query your data
[root@administrator druid]#

不使用脚本来加载数据
curl -X 'POST' -H 'Content-Type:application/json' -d @quickstart/tutorial/wikipedia-index.json http://localhost:8081/druid/indexer/v1/task
数据清理
数据清理需要关闭服务、集群并通过删除druid软件包下的var目录的内容来重置服务、集群状态
从Kafka中加载数据
安装Zookeeper
由于Kafka也需要使用Zookeeper,故将Zookeeper独立部署安装
docker run -id --name zk -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper:latest
docker logs -f zk
kafka安装
拉取镜像
docker pull wurstmeister/kafka
启动容器
docker run -id --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=IP:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://IP:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka
参数说明
-e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
-e KAFKA_ZOOKEEPER_CONNECT=IP:2181 配置zookeeper管理kafka的路径
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://IP:9092 把kafka的地址端口注册给zookeeper
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口
-v /etc/localtime:/etc/localtime 容器时间同步虚拟机的时间
查看容器日志
docker logs -f kafka
查看zookeeper
进入容器
docker exec -it kafka /bin/bash
进入bin目录
bash-5.1# cd /opt/kafka_2.13-2.8.1/bin/
bash-5.1# ls
connect-distributed.sh kafka-consumer-perf-test.sh kafka-producer-perf-test.sh kafka-verifiable-producer.sh
connect-mirror-maker.sh kafka-delegation-tokens.sh kafka-reassign-partitions.sh trogdor.sh
connect-standalone.sh kafka-delete-records.sh kafka-replica-verification.sh windows
kafka-acls.sh kafka-dump-log.sh kafka-run-class.sh zookeeper-security-migration.sh
kafka-broker-api-versions.sh kafka-features.sh kafka-server-start.sh zookeeper-server-start.sh
kafka-cluster.sh kafka-leader-election.sh kafka-server-stop.sh zookeeper-server-stop.sh
kafka-configs.sh kafka-log-dirs.sh kafka-storage.sh zookeeper-shell.sh
kafka-console-consumer.sh kafka-metadata-shell.sh kafka-streams-application-reset.sh
kafka-console-producer.sh kafka-mirror-maker.sh kafka-topics.sh
kafka-consumer-groups.sh kafka-preferred-replica-election.sh kafka-verifiable-consumer.sh
bash-5.1#
创建一个用来发送数据的Kafka主题/队列,名称为”wikipedia” 的队列,此队列有一个副本,一个分区
bash-5.1# kafka-topics.sh --create --zookeeper IP:2181 --replication-factor 1 --partitions 1 --topic wikipedia
Created topic wikipedia.
bash-5.1#
查看已创建的队列
bash-5.1# kafka-topics.sh -list -zookeeper IP:2181
wikipedia
bash-5.1#
测试消息发送和接收是否正常
# 启动消费端,监听wikipedia队列
bash-5.1# kafka-console-consumer.sh --bootstrap-server IP:9092 --topic wikipedia --from-beginning
hello kafka
# 新开命令窗口,启动生产者,向wikipedia队列发送消息
bash-5.1# kafka-console-producer.sh --broker-list IP:9092 --topic wikipedia
>hello kafka
>
修改Druid
由于独立使用Zookeeper,所以需要关闭Druid关联的Zookeeper配置
注释Zookeeper配置
[root@administrator druid]# cat conf/supervise//single-server/nano-quickstart.conf
:verify bin/verify-java
:verify bin/verify-default-ports
:kill-timeout 10
# 注释!p10 zk bin/run-zk conf
# !p10 zk bin/run-zk conf
coordinator-overlord bin/run-druid coordinator-overlord conf/druid/single-server/nano-quickstart
broker bin/run-druid broker conf/druid/single-server/nano-quickstart
router bin/run-druid router conf/druid/single-server/nano-quickstart
historical bin/run-druid historical conf/druid/single-server/nano-quickstart
!p90 middleManager bin/run-druid middleManager conf/druid/single-server/nano-quickstart
去掉2181端口的检测
[root@administrator druid]# cat bin/verify-default-ports
#!/usr/bin/env perl
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
use strict;
use warnings;
use Socket;
sub try_bind {
my ($port, $addr) = @_;
socket(my $sock, PF_INET, SOCK_STREAM, Socket::IPPROTO_TCP) or die "socket: $!";
setsockopt($sock, SOL_SOCKET, SO_REUSEADDR, pack("l", 1)) or die "setsockopt: $!";
if (!bind($sock, sockaddr_in($port, $addr))) {
print STDERR <<"EOT";
Cannot start up because port $port is already in use.
If you need to change your ports away from the defaults, check out the
configuration documentation:
https://druid.apache.org/docs/latest/configuration/index.html
If you believe this check is in error, or if you have changed your ports away
from the defaults, you can skip this check using an environment variable:
export DRUID_SKIP_PORT_CHECK=1
EOT
exit 1;
}
shutdown($sock, 2);
}
my $skip_var = $ENV{'DRUID_SKIP_PORT_CHECK'};
if ($skip_var && $skip_var ne "0" && $skip_var ne "false" && $skip_var ne "f") {
exit 0;
}
my @ports = @ARGV;
if (!@ports) {
# 端口监测
# @ports = (1527, 2181, 8081, 8082, 8083, 8090, 8091, 8100, 8200, 8888);
@ports = (1527, 8081, 8082, 8083, 8090, 8091, 8100, 8200, 8888);
}
for my $port (@ports) {
try_bind($port, INADDR_ANY);
try_bind($port, inet_aton("127.0.0.1"));
}
[root@administrator druid]#
修改公共配置
[root@administrator druid]# cat conf/druid/single-server/nano-quickstart/_common/common.runtime.properties
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#
# Extensions specified in the load list will be loaded by Druid
# We are using local fs for deep storage - not recommended for production - use S3, HDFS, or NFS instead
# We are using local derby for the metadata store - not recommended for production - use MySQL or Postgres instead
# If you specify `druid.extensions.loadList=[]`, Druid won't load any extension from file system.
# If you don't specify `druid.extensions.loadList`, Druid will load all the extensions under root extension directory.
# More info: https://druid.apache.org/docs/latest/operations/including-extensions.html
druid.extensions.loadList=["druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches"]
# If you have a different version of Hadoop, place your Hadoop client jar files in your hadoop-dependencies directory
# and uncomment the line below to point to your directory.
#druid.extensions.hadoopDependenciesDir=/my/dir/hadoop-dependencies
#
# Hostname
#
# 这里使用IP还不行
druid.host=localhost
#
# Logging
#
# Log all runtime properties on startup. Disable to avoid logging properties on startup:
druid.startup.logging.logProperties=true
#
# Zookeeper
#
# druid.zk.service.host=localhost
# 填写独立部署zookeeper的IP
druid.zk.service.host=IP
druid.zk.paths.base=/druid
#
# Metadata storage
#
# For Derby server on your Druid Coordinator (only viable in a cluster with a single Coordinator, no fail-over):
druid.metadata.storage.type=derby
druid.metadata.storage.connector.connectURI=jdbc:derby://localhost:1527/var/druid/metadata.db;create=true
druid.metadata.storage.connector.host=localhost
druid.metadata.storage.connector.port=1527
# For MySQL (make sure to include the MySQL JDBC driver on the classpath):
#druid.metadata.storage.type=mysql
#druid.metadata.storage.connector.connectURI=jdbc:mysql://db.example.com:3306/druid
#druid.metadata.storage.connector.user=...
#druid.metadata.storage.connector.password=...
# For PostgreSQL:
#druid.metadata.storage.type=postgresql
#druid.metadata.storage.connector.connectURI=jdbc:postgresql://db.example.com:5432/druid
#druid.metadata.storage.connector.user=...
#druid.metadata.storage.connector.password=...
#
# Deep storage
#
# For local disk (only viable in a cluster if this is a network mount):
druid.storage.type=local
druid.storage.storageDirectory=var/druid/segments
# For HDFS:
#druid.storage.type=hdfs
#druid.storage.storageDirectory=/druid/segments
# For S3:
#druid.storage.type=s3
#druid.storage.bucket=your-bucket
#druid.storage.baseKey=druid/segments
#druid.s3.accessKey=...
#druid.s3.secretKey=...
#
# Indexing service logs
#
# For local disk (only viable in a cluster if this is a network mount):
druid.indexer.logs.type=file
druid.indexer.logs.directory=var/druid/indexing-logs
# For HDFS:
#druid.indexer.logs.type=hdfs
#druid.indexer.logs.directory=/druid/indexing-logs
# For S3:
#druid.indexer.logs.type=s3
#druid.indexer.logs.s3Bucket=your-bucket
#druid.indexer.logs.s3Prefix=druid/indexing-logs
#
# Service discovery
#
druid.selectors.indexing.serviceName=druid/overlord
druid.selectors.coordinator.serviceName=druid/coordinator
#
# Monitoring
#
druid.monitoring.monitors=["org.apache.druid.java.util.metrics.JvmMonitor"]
druid.emitter=noop
druid.emitter.logging.logLevel=info
# Storage type of double columns
# ommiting this will lead to index double as float at the storage layer
druid.indexing.doubleStorage=double
#
# Security
#
druid.server.hiddenProperties=["druid.s3.accessKey","druid.s3.secretKey","druid.metadata.storage.connector.password"]
#
# SQL
#
druid.sql.enable=true
#
# Lookups
#
druid.lookup.enableLookupSyncOnStartup=false
[root@administrator druid]#
重启项目查看Zookeeper
发送数据到Kafka
cd quickstart/tutorial
gunzip -c wikiticker-2015-09-12-sampled.json.gz > wikiticker-2015-09-12-sampled.json
docker cp ./wikiticker-2015-09-12-sampled.json kafka:/opt/kafka_2.13-2.8.1/bin
bash-5.1# kafka-console-producer.sh --broker-list IP:9092 --topic wikipedia < ./wikiticker-2015-09-12-sampled.json
bash-5.1#
控制台使用数据加载器
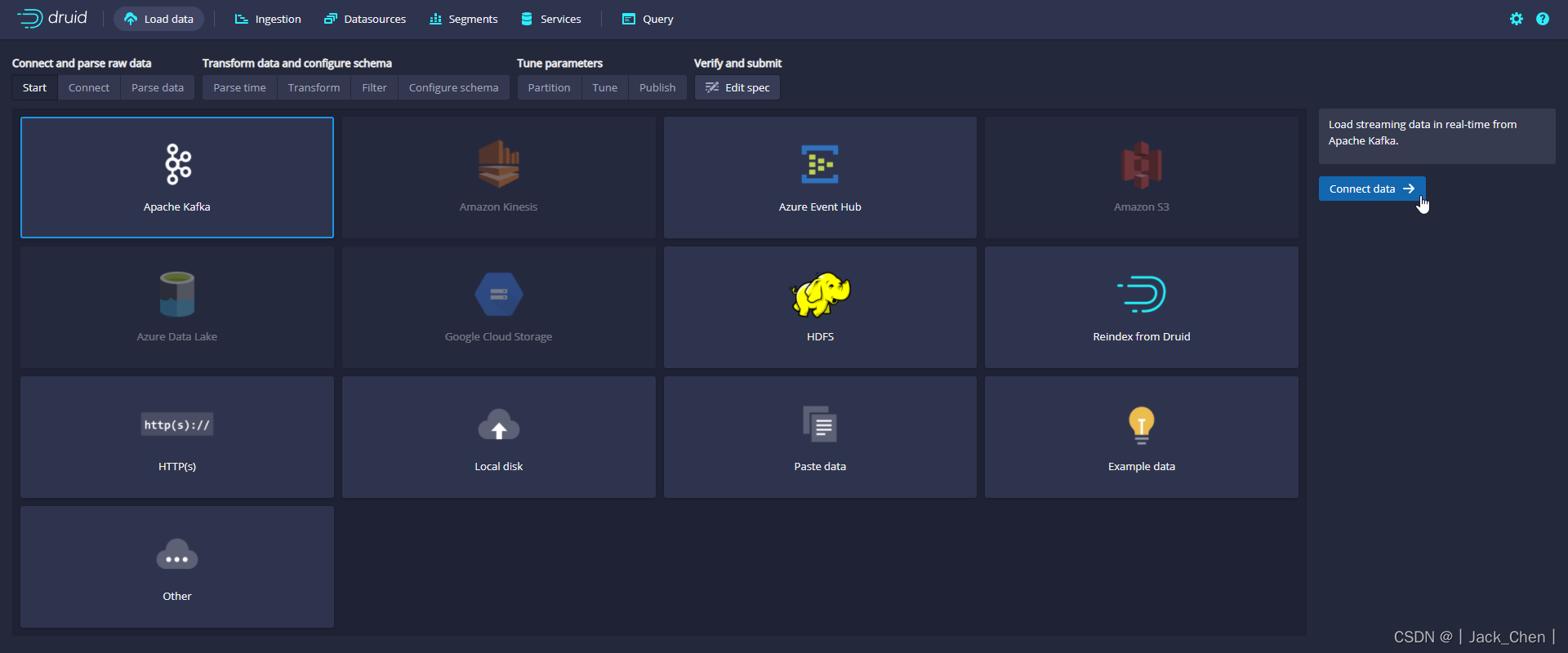
在 Bootstrap servers 输入 IP:9092, 在 Topic 输入 wikipedia
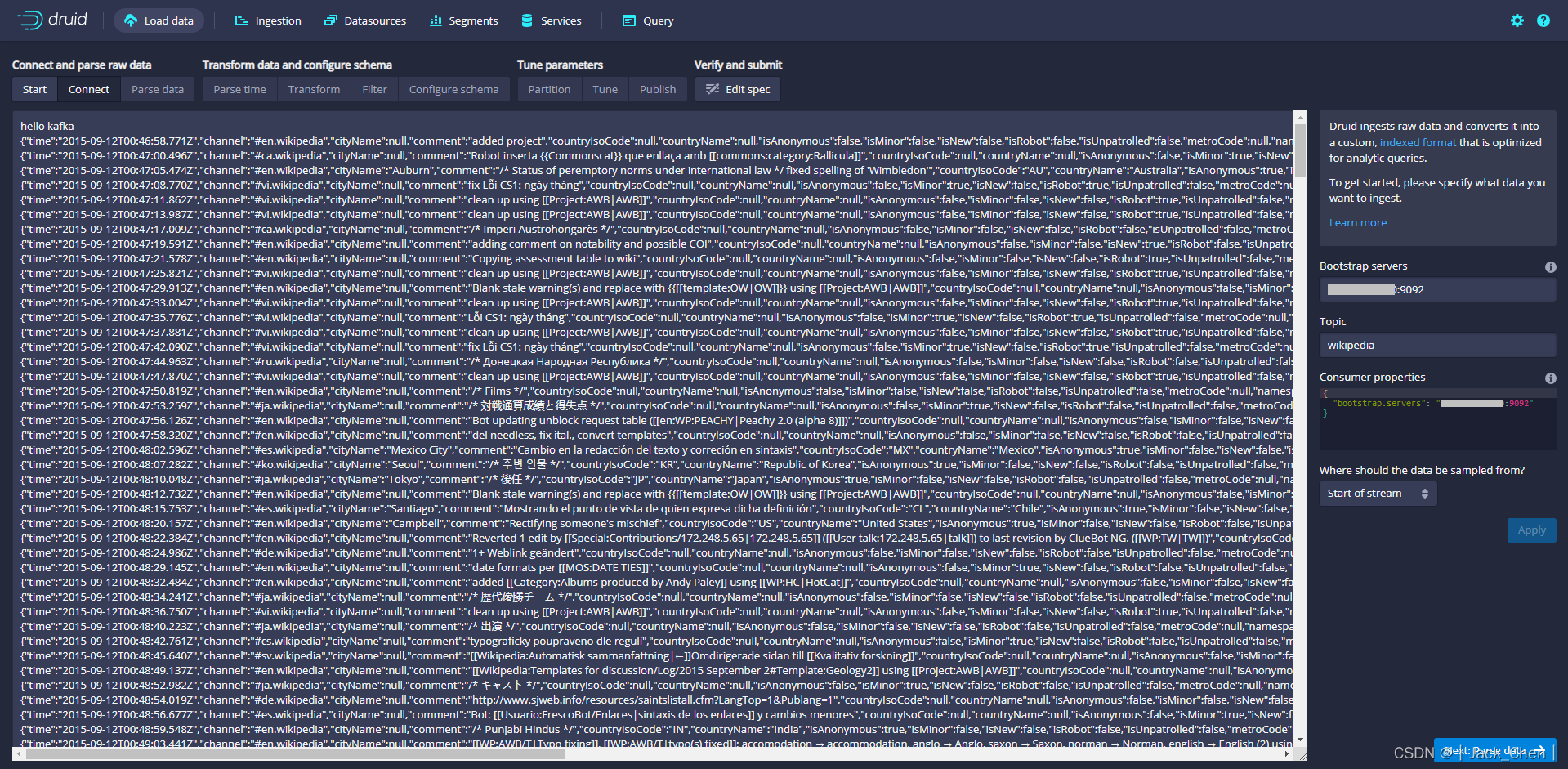
在 Tune 步骤中,将 Use earliest offset 设置为 True 非常重要,因为需要从流的开始位置消费数据。
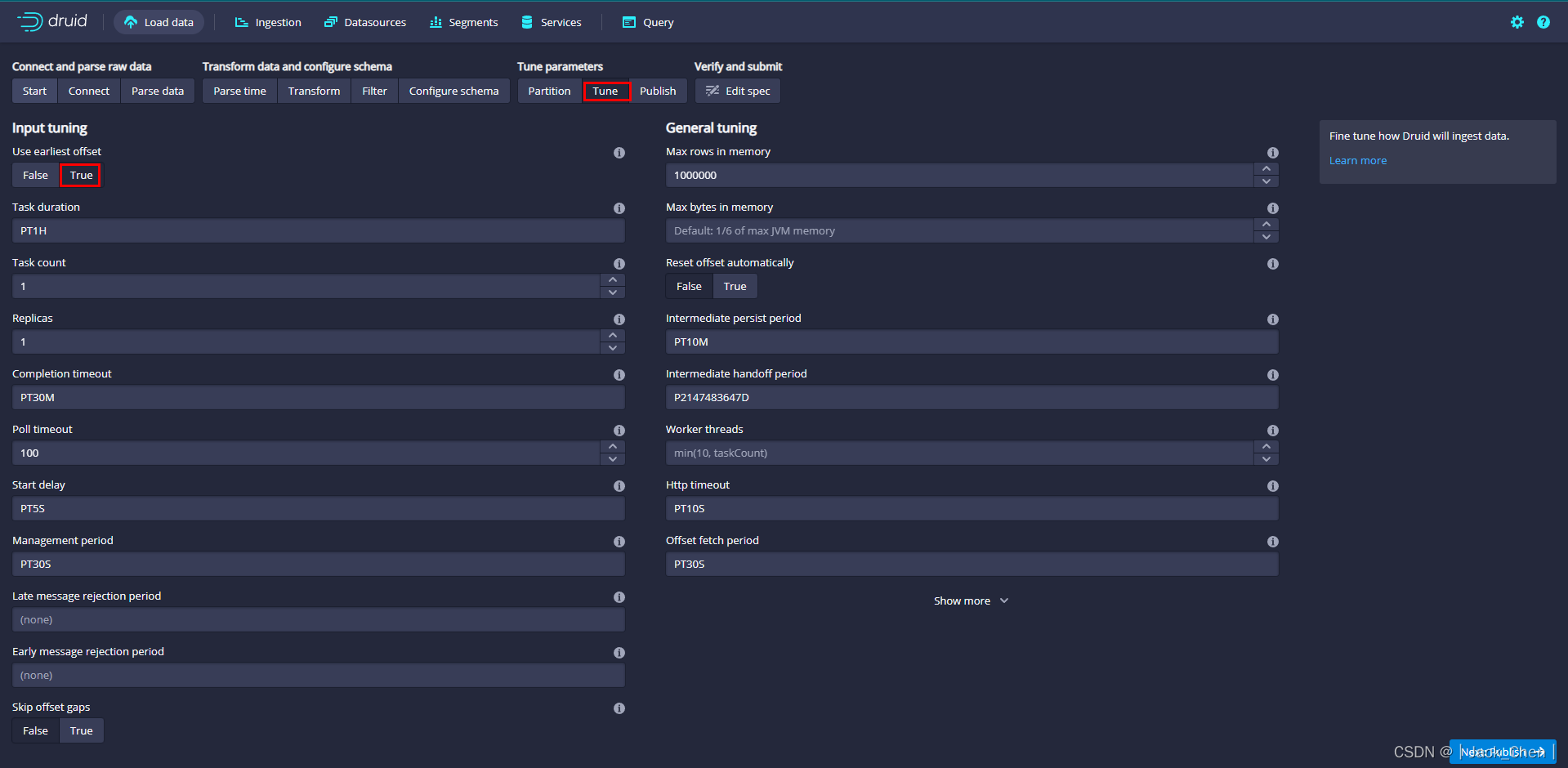
将该数据源命名为kafkadata
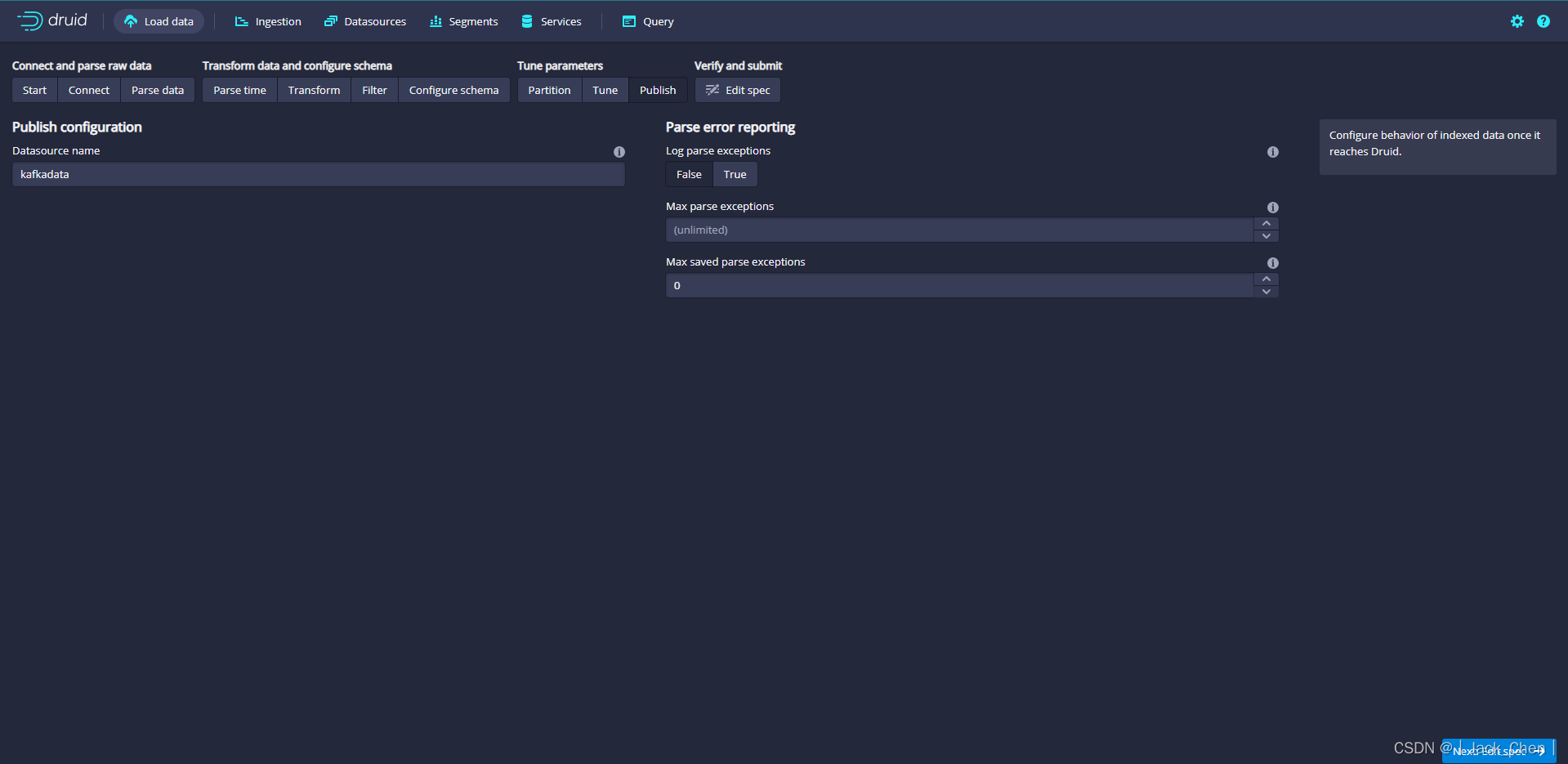
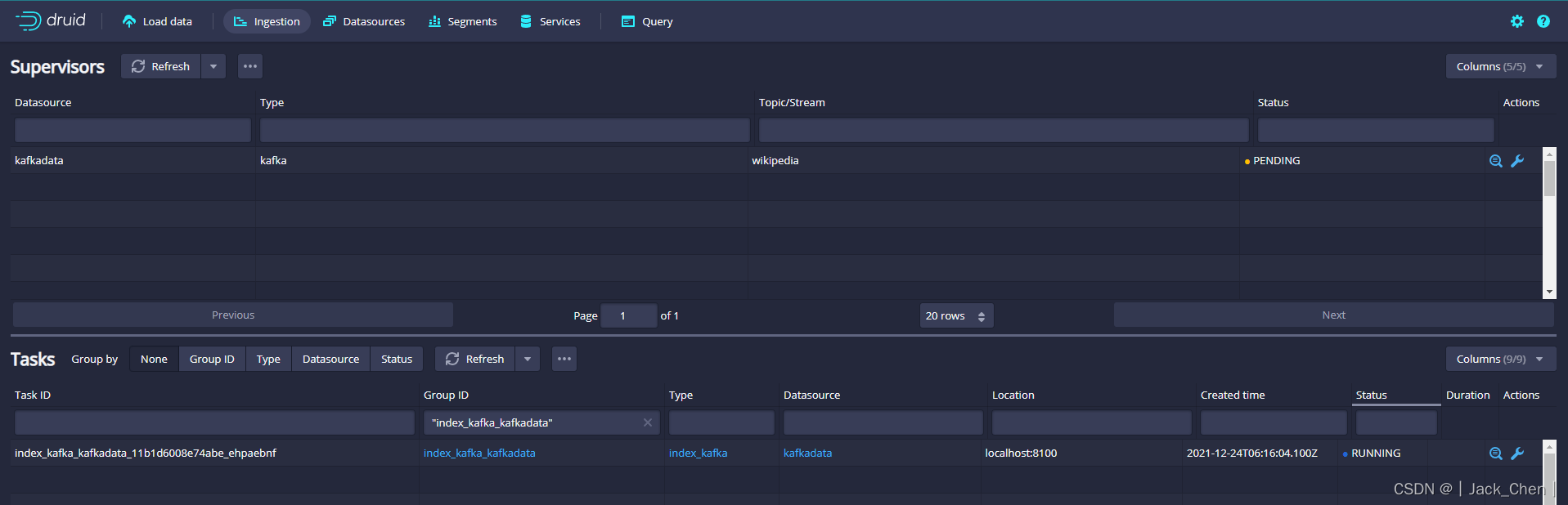
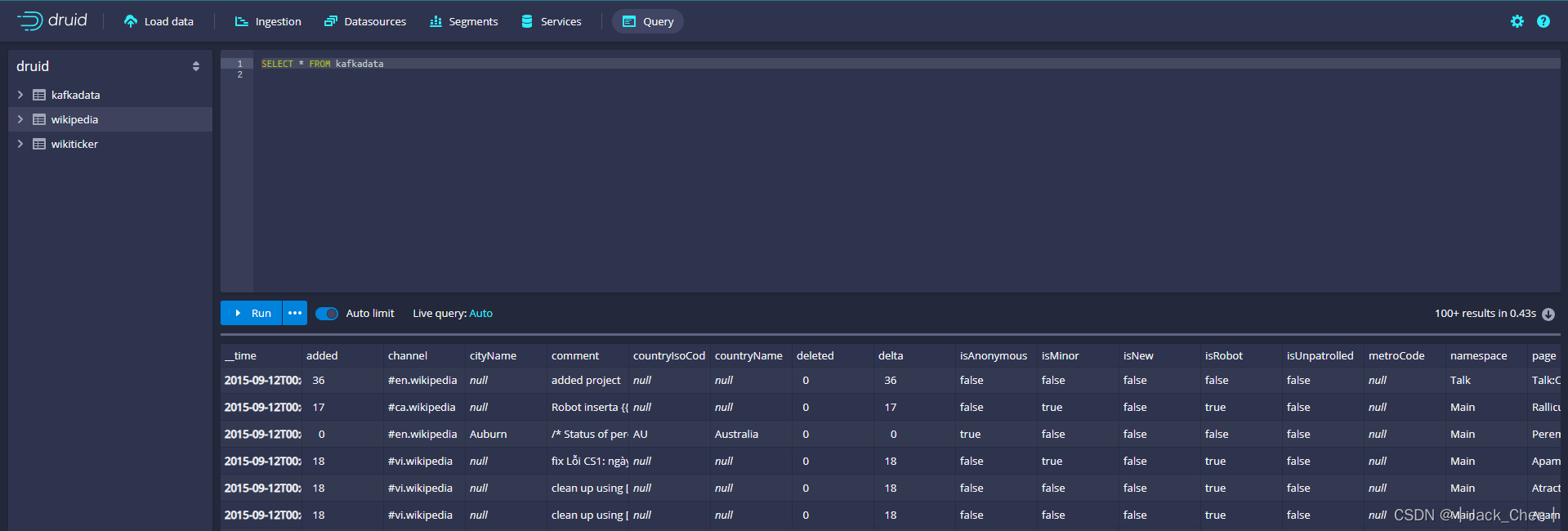
通过控制台提交supervisor
点击Tasks按钮进入任务页面
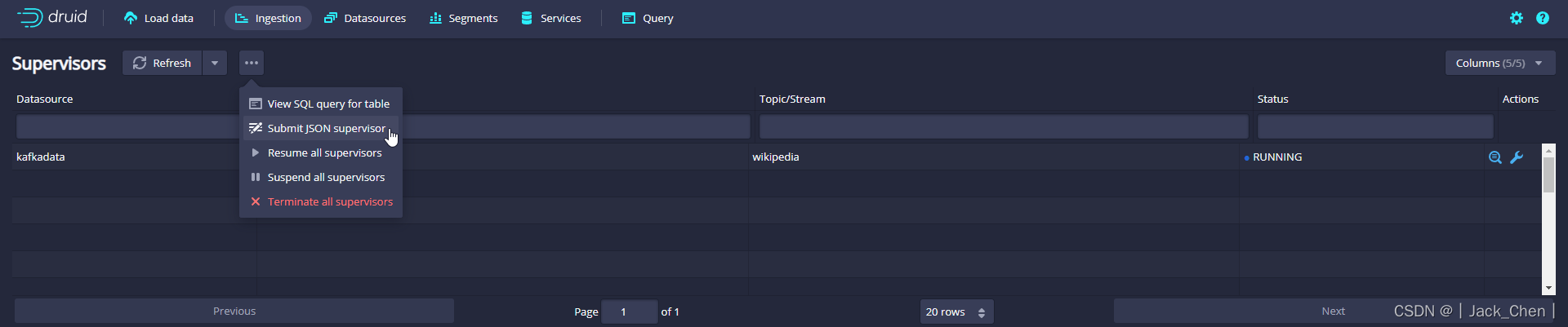
粘贴规范后点击 Submit ,这将启动supervisor,该supervisor继而产生一些任务,这些任务将开始监听传入的数据。
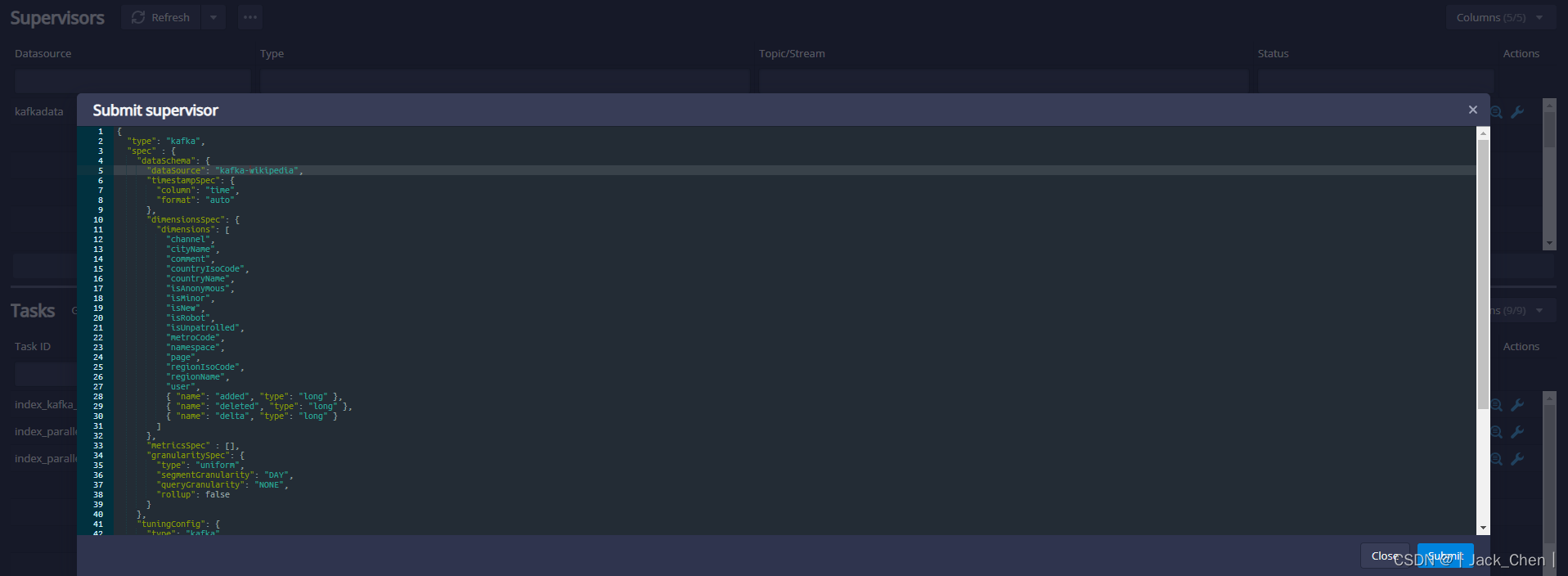
直接提交supervisor
为了直接启动服务,我们可以在Druid的根目录下运行以下命令来提交一个supervisor规范到Druid Overlord中
curl -XPOST -H'Content-Type: application/json' -d @quickstart/tutorial/wikipedia-kafka-supervisor.json http://localhost:8081/druid/indexer/v1/supervisor
Java客户端操作druid
<dependency>
<groupId>org.apache.calcite.avatica</groupId>
<artifactId>avatica-core</artifactId>
<version>1.19.0</version>
</dependency>
@Test
public void test throws Exception{
Class.forName("org.apache.calcite.avatica.remote.Driver");
Connection connection = DriverManager.getConnection("jdbc:avatica:remote:url=http://IP:8888/druid/v2/sql/avatica/");
Statement st = null;
ResultSet rs = null;
try {
st = connection.createStatement();
rs = st.executeQuery("select * from wikipedia");
ResultSetMetaData rsmd = rs.getMetaData();
List<Map> resultList = new ArrayList();
while (rs.next()) {
Map map = new HashMap();
for (int i = 0; i < rsmd.getColumnCount(); i++) {
String columnName = rsmd.getColumnName(i + 1);
map.put(columnName, rs.getObject(columnName));
}
resultList.add(map);
}
System.out.println("resultList = " + resultList.size());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
connection.close();
} catch (SQLException e) {
}
}
}
Kafka发送数据到Druid
<dependency>
<groupId>org.apache.calcite.avatica</groupId>
<artifactId>avatica-core</artifactId>
<version>1.19.0</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.0</version>
</dependency>
spring:
kafka:
# kafka 地址
bootstrap-servers: IP:9092
# 指定listener 容器中的线程数,用于提高并发量
listener:
concurrency: 5
producer:
# 重试次数
retries: 3
# 每次批量发送消息的数量
batch-size: 1000
# 缓冲区大小
buffer-memory: 33554432
# 指定消息key和消息体的编解码方式 Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
# 指定默认消费者group id
group-id: kafka-test
# 指定消息key和消息体的编解码方式
key-deserializer: org.apache.kafka.common.serialization.StringSerializer
value-deserializer: org.apache.kafka.common.serialization.StringSerializer
@Component
@Slf4j
public class KafkaSender {
public final static String MSG_TOPIC = "my_topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息到kafka队列
*
* @param topic
* @param message
* @return
*/
public boolean send(String topic, String message) {
try {
kafkaTemplate.send(topic, message);
log.info("消息发送成功:{} , {}", topic, message);
} catch (Exception e) {
log.error("消息发送失败:{} , {}", topic, message, e);
return false;
}
return true;
}
}
@RestController
@Slf4j
public class KafkaController {
@Autowired
private KafkaSender kafkaSender;
@PostMapping(value = "/send")
public Object send(@RequestBody JSONObject jsonObject) {
kafkaSender.send(KafkaSender.MSG_TOPIC, jsonObject.toJSONString());
return "success";
}
}
INFO 73032 --- [nio-8888-exec-1] o.a.k.clients.producer.ProducerConfig : ProducerConfig values:
acks = 1
batch.size = 1000
bootstrap.servers = [IP:9092]
buffer.memory = 33554432
client.dns.lookup = default
client.id = producer-1
compression.type = none
connections.max.idle.ms = 540000
delivery.timeout.ms = 120000
enable.idempotence = false
interceptor.classes = []
key.serializer = class org.apache.kafka.common.serialization.StringSerializer
linger.ms = 0
max.block.ms = 60000
max.in.flight.requests.per.connection = 5
max.request.size = 1048576
metadata.max.age.ms = 300000
metadata.max.idle.ms = 300000
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner
receive.buffer.bytes = 32768
reconnect.backoff.max.ms = 1000
reconnect.backoff.ms = 50
request.timeout.ms = 30000
retries = 0
retry.backoff.ms = 100
sasl.client.callback.handler.class = null
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.login.callback.handler.class = null
sasl.login.class = null
sasl.login.refresh.buffer.seconds = 300
sasl.login.refresh.min.period.seconds = 60
sasl.login.refresh.window.factor = 0.8
sasl.login.refresh.window.jitter = 0.05
sasl.mechanism = GSSAPI
security.protocol = PLAINTEXT
security.providers = null
send.buffer.bytes = 131072
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2]
ssl.endpoint.identification.algorithm = https
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLSv1.2
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
transaction.timeout.ms = 60000
transactional.id = null
value.serializer = class org.apache.kafka.common.serialization.StringSerializer
INFO 73032 --- [nio-8888-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version: 2.5.0
INFO 73032 --- [nio-8888-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId: 66563e712b0b9f84
INFO 73032 --- [nio-8888-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka startTimeMs: 1640330631065
INFO 73032 --- [ad | producer-1] org.apache.kafka.clients.Metadata : [Producer clientId=producer-1] Cluster ID: DCSWcLrOTLuv6M_hwSCSmg
INFO 73032 --- [nio-8888-exec-1] cn.ybzy.demo.druid.KafkaSender : 消息发送成功:my_topic , {"businessId":"123456","content":"kafka test"}
查看Druid

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/137008.html

