
Zookeeper高级
Paxos 算法
Paxos算法:一种基于消息传递且具有高度容错特性的一致性算法。
Paxos算法解决的问题:就是如何快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常,
都不会破坏整个系统的一致性
Paxos算法描述:
- 在一个Paxos系统中,首先将所有节点划分为Proposer(提议者),Acceptor(接受者),和Learner(学习者)。(注意:每个节点都可以身兼数职)。

- 一个完整的Paxos算法流程分为三个阶段:
- Prepare准备阶段
- Proposer向多个Acceptor发出Propose请求Promise(承诺)
- Acceptor针对收到的Propose请求进行Promise(承诺)
- Accept接受阶段
- Proposer收到多数Acceptor承诺的Promise后,向Acceptor发出Propose请求
- Acceptor针对收到的Propose请求进行Accept处理
- Learn学习阶段:Proposer将形成的决议发送给所有Learners
Paxos算法流程

- Prepare: Proposer生成全局唯一且递增的Proposal ID,向所有Acceptor发送Propose请求,这里无需携带提案内容,只携带Proposal ID即可
- Promise: Acceptor收到Propose请求后,做出“两个承诺,一个应答”
- ➢ 不再接受Proposal ID小于等于(注意:这里是<= )当前请求的Propose请求。
- ➢ 不再接受Proposal ID小于(注意:这里是< )当前请求的Accept请求。
- ➢ 不违背以前做出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
-
Propose: Proposer收到多数Acceptor的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptor发送Propose请求
-
Accept: Acceptor收到Propose请求后,在不违背自己之前做出的承诺下,接受并持久化当前Proposal ID和提案Value
-
Learn: Proposer收到多数Acceptor的Accept后,决议形成,将形成的决议发送给所有Learner
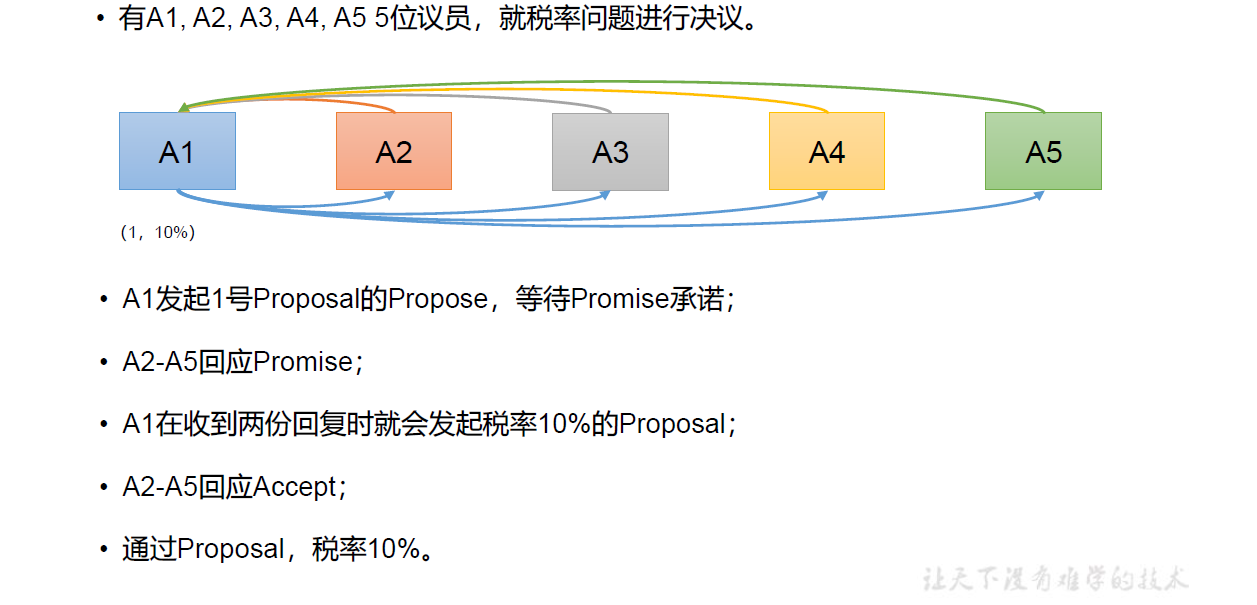
针对上述描述做三种情况的推演举例:为了简化流程,我们这里不设置Learner
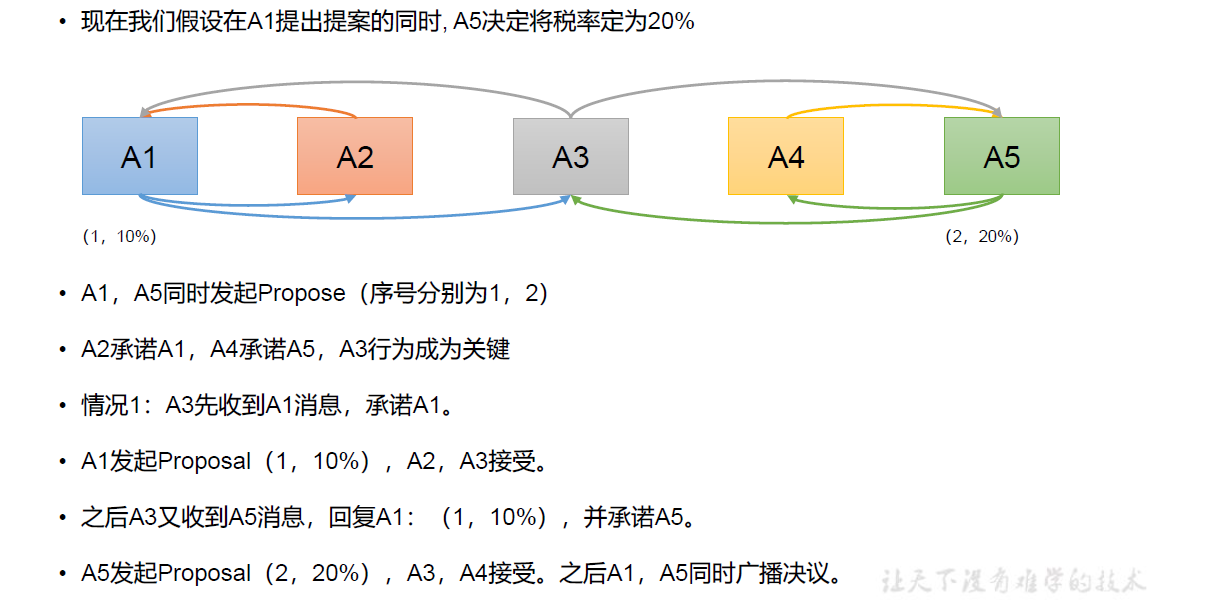
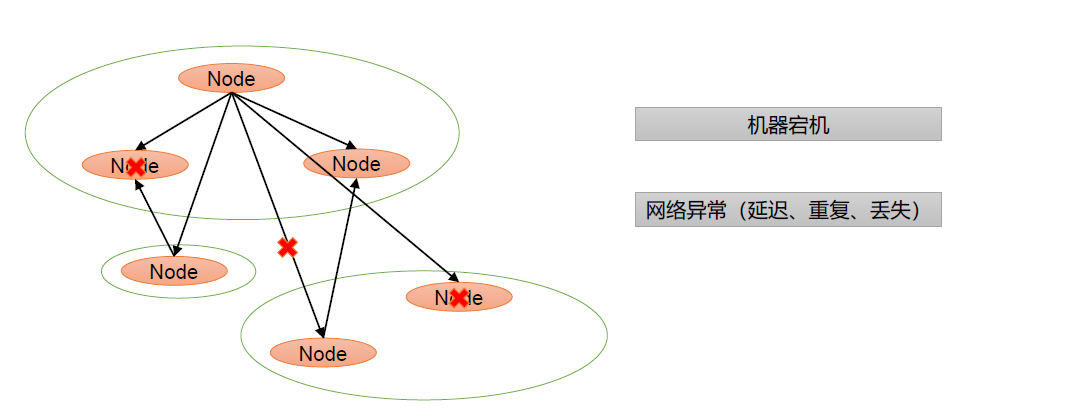
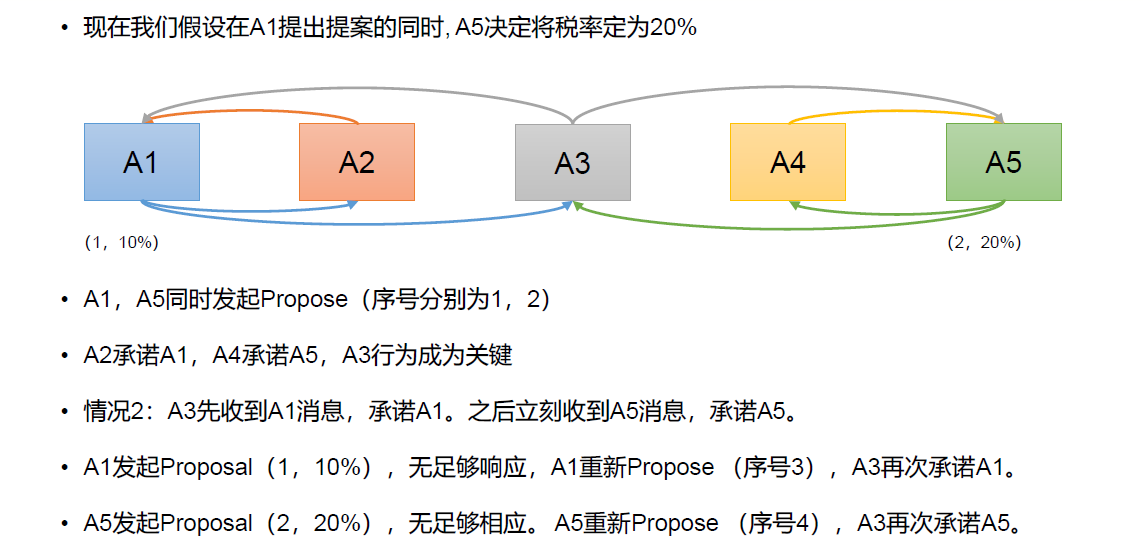
Paxos 算法缺陷:在网络复杂的情况下,一个应用Paxos 算法的分布式系统,可能很久无法收敛,甚至陷入活锁的情况
造成这种情况的原因是系统中有一个以上的Proposer,多个Proposers 相互争夺Acceptor,造成迟迟无法达成一致的情况。针对这种情况,一种改进的Paxos 算法被提出:从系统中选出一个节点作为Leader,只有Leader 能够发起提案。这样,一次Paxos 流程中只有一个Proposer,不会出现活锁的情况,此时只会出现例子中第一种情况。
ZAB协议
什么是ZAB 算法
Zab 借鉴了Paxos 算法,是特别为Zookeeper 设计的支持崩溃恢复的原子广播协议。基于该协议,Zookeeper 设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader 客户端将数据同步到其他Follower 节点。即Zookeeper 只有一个Leader 可以发起提案。
Zab 协议内容
Zab 协议包括两种基本的模式:消息广播、崩溃恢复
消息广播
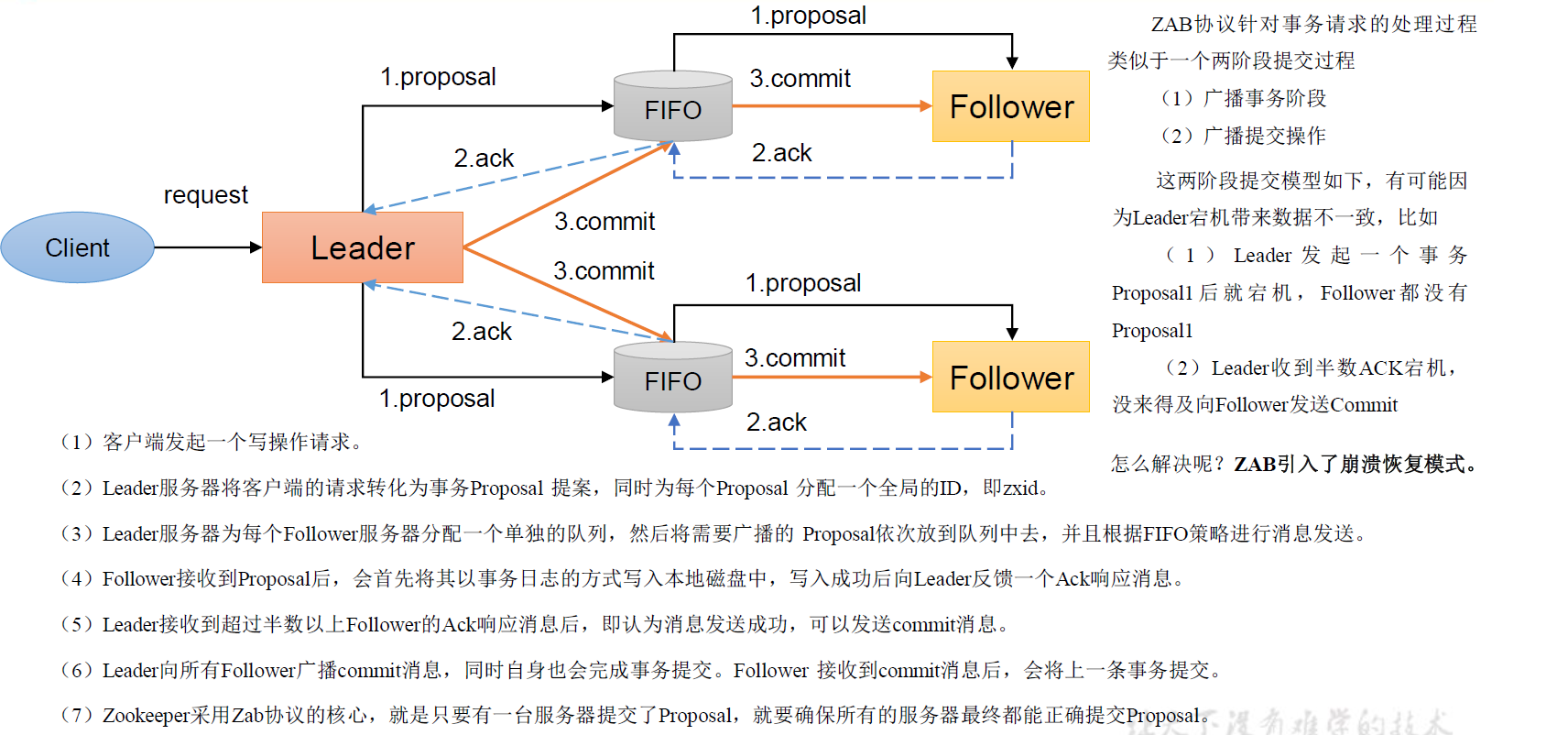
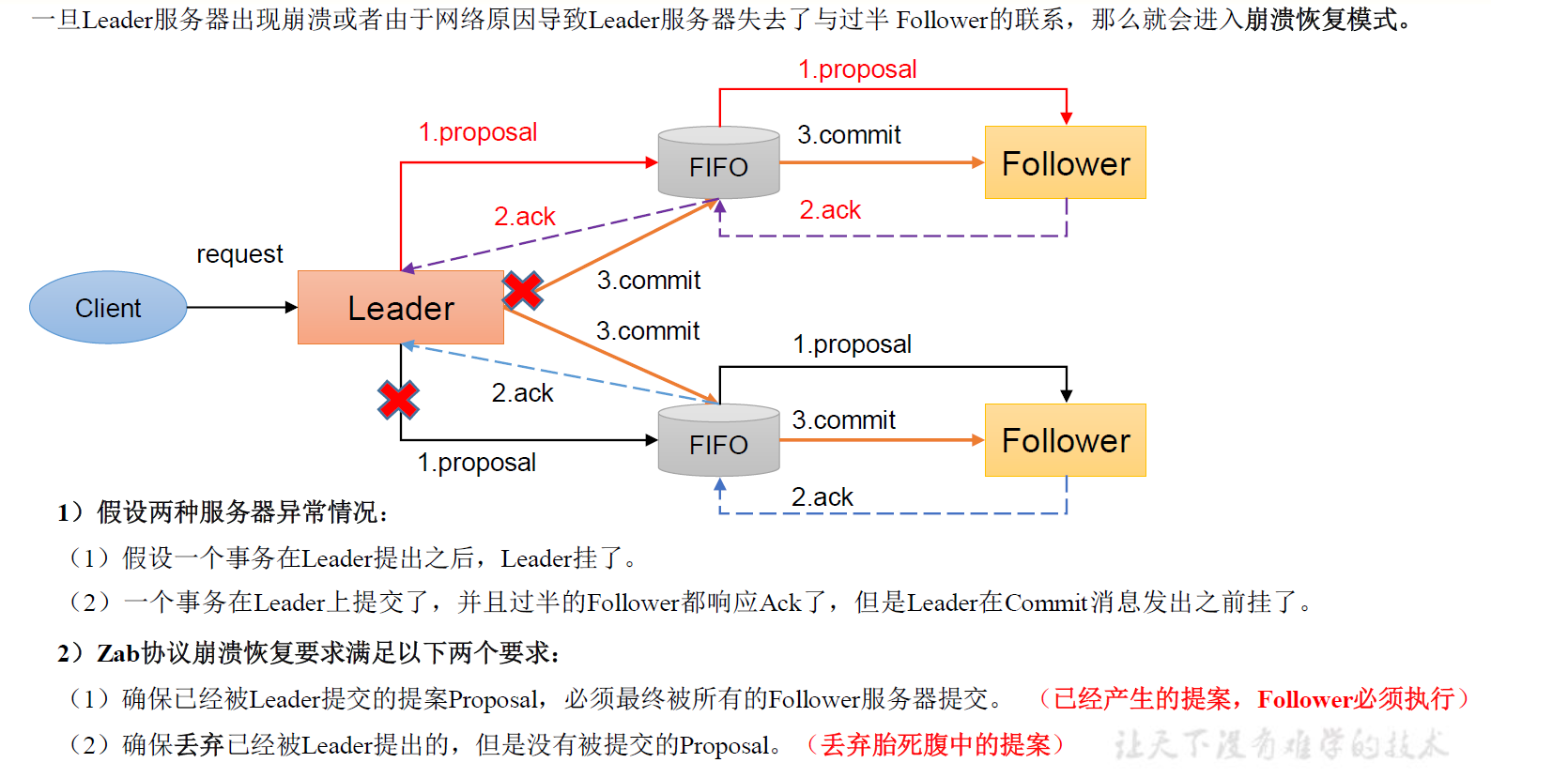
崩溃恢复
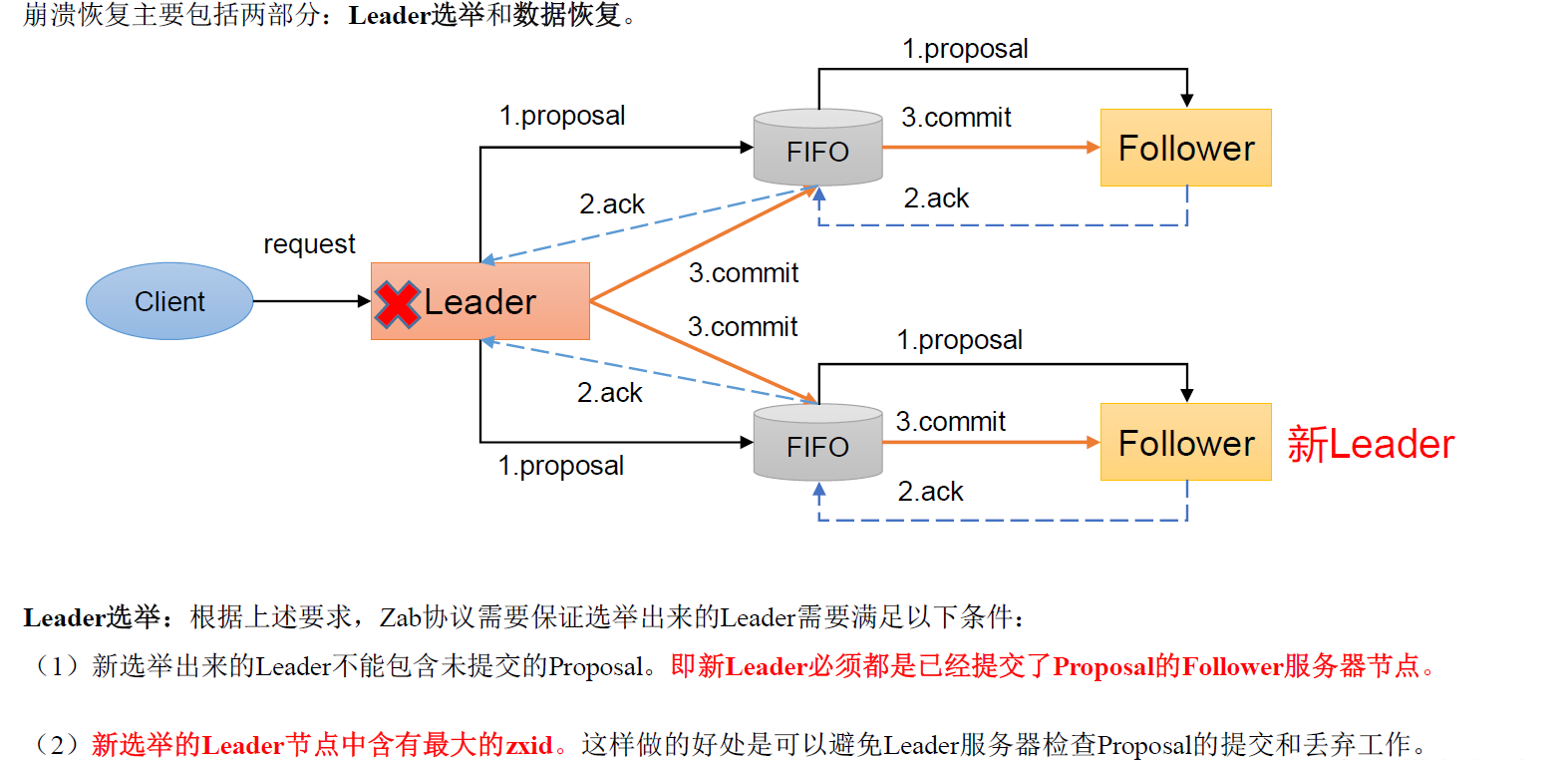
崩溃恢复——Leader选举
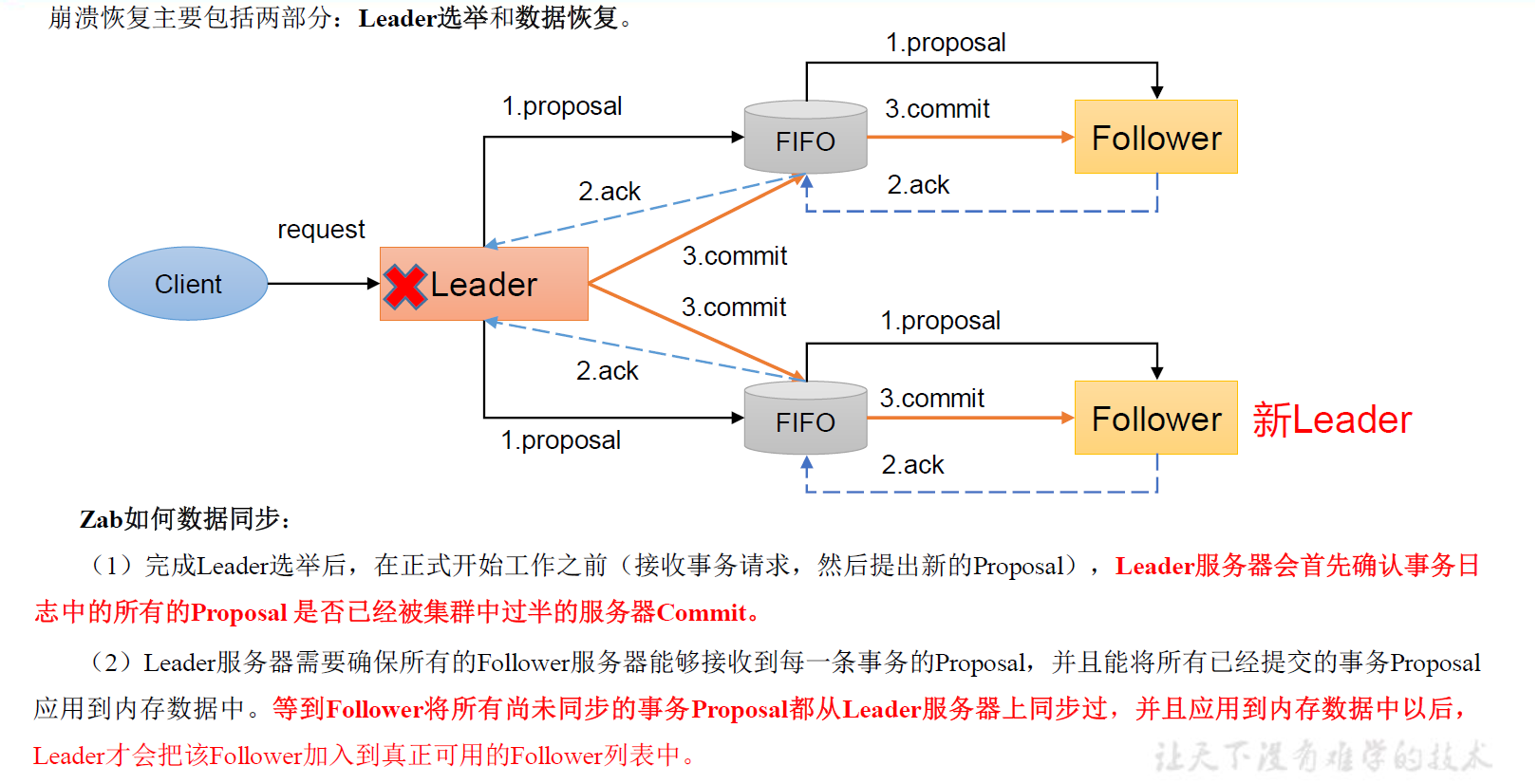
崩溃恢复——数据恢复
CAP理论
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种
⚫ 一致性(C:Consistency)
⚫ 可用性(A:Available)
⚫ 分区容错性(P:Partition Tolerance)
这三个基本需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。
(1)一致性(C:Consistency)
在分布式环境中,一致性是指数据在多个副本之间是否能够保持数据一致的特性。在一致性的需求下,当一个系统在数
据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
(2)可用性(A:Available)
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
(3)分区容错性(P:Partition Tolerance)
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络
环境都发生了故障。
ZooKeeper保证的是CP
(1)ZooKeeper不能保证每次服务请求的可用性。(注:在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要
重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
(2)进行Leader选举时集群都是不可用。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140653.html

