
1. hadoop自带的wordcount
1.1位置
[root@hadoop001 ~]# ls $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
/export/servers/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
1.2 使用
[root@hadoop001 ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
[root@hadoop001 ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount
Usage: wordcount <in> [<in>...] <out>
2
2.1. MapReduce的核心思想
MapReduce是一种并行编程模型,是Hadoop生态系统的核心组件之一,“分而治之”是MapReduce的核心思想,它表示把一个大规模的数据集切分成很多小的单独的数据集,然后放在多个机器上同时处理。
我们用一个通俗易懂的例子来体现“分而治之”的思想。
2.2 MapReduce的核心函数
MapReduce把整个并行运算过程高度抽象到两个函数上,一个是map另一个是reduce。Map函数就是分而治之中的“分”,reduce函数就是分而治之中的“治”。
MapReduce把一个存储在分布式文件系统中的大规模数据集切分成许多独立的小的数据集,然后分配给多个map任务处理。然后map任务的输出结果会进一步处理成reduce任务的输入,最后由reduce任务进行汇总,然后上传到分布式文件系统中。
Map函数:map函数会将小的数据集转换为适合输入的<key,value>键值对的形式,然后处理成一系列具有相同key的<key,value>作为输出,我们可以把输出看做list(<key,value>)
Reduce函数:reduce函数会把map函数的输出作为输入,然后提取具有相同key的元素,并进行操作,最后的输出结果也是<key,value>键值对的形式,并合并成一个文件。
2.3 MapReduce的工作过程
如图展示的就是MapReduce的工作过程,一共分为input、split、map、shuffle、reduce、output六个阶段。下面用三明治的例子来演示一下MapReduce的工作流程:
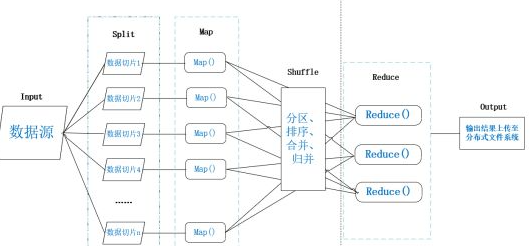
√ input阶段相当于准备食材的步骤;
√ split阶段相当于分食材的步骤,数据切片1表示面包、数据切片2表示培根、数据切片3表示西红柿、数据切片4表示生菜;
√ map阶段相当于切面包、煎培根、切西红柿、洗生菜四个步骤同时进行;
√ shuffle阶段相当于把切好的食材分类,存放、汇总;
√ reduce阶段相当于整合组装成三明治;
√ output阶段相当于打包。
有了这个通俗易懂的例子加上前面map函数和reduce函数的介绍,我们再来理解MapReduce的工作过程就很轻松了。
(1) input阶段:将数据源输入到MapReduce框架中
(2) split阶段:将大规模的数据源切片成许多小的数据集,然后对数据进行预处理,处理成适合map任务输入的<key,value>形式。
(3) map阶段:对输入的<key,value>键值对进行处理,然后产生一系列的中间结果。通常一个split分片对应一个map任务,有几个split就有几个map任务。
(4) shuffle阶段:对map阶段产生的一系列<key,value>进行分区、排序、归并等操作,然后处理成适合reduce任务输入的键值对形式。
(5) reduce阶段:提取所有相同的key,并按用户的需求对value进行操作,最后也是以<key,value>的形式输出结果。
(6) output阶段:进行一系列验证后,将reduce的输出结果上传到分布式文件系统中。
3MapReduce应用
使用MapReduce的前提:
待处理的数据集可以分解成许多小的数据集
每一个小数据集都可以完全并行地进行处理
WordCount实例
WordCount是最简单、最能体现MapReduce思想的程序之一,可以称为MapReduce版Hello World,其主要功能是:统计一系列文本文件中每个单词出现的次数。
样例:

import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 经过在 map 函数处理,输出中间结果<word,1>的形式,在 reduce 函数中完成对每个单词的词频统计<word, frequency>
*/
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 启动job任务
Job job = Job.getInstance();
job.setJobName("WordCount");
// 设置mapper类、Reducer类
job.setJarByClass(WordCount.class); // 设置程序类
job.setMapperClass(MyMapper.class); // 设置Mapper类
job.setReducerClass(MyReducer.class); // 设置Reducer类
// 设置Job输出结果<key,value>的中key和value数据类型,因为结果是<单词,个数>,所以key设置为"Text"类型,Value设置为"IntWritable"类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// hdfs文件系统
Path in = new Path("hdfs://localhost:9000/mr_demo/input/cust_fav"); //需要统计的文本所在位置
Path out = new Path("hdfs://localhost:9000/mr_demo/output"); // 输出文件夹不能存在
// 本地文件系统。若文件在本地文件系统,则替换为以下代码
// Path in = new Path("file:///usr/local/java/data/mapreduce_demo/input/data_click"); // 用本地文件输入
// Path out = new Path("file:///usr/local/java/data/mapreduce_demo/output"); // 结果输出到本地,文件夹不能已经存在
// 设置job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
// 无论程序是否执行成功,均强制退出
// 如果程序成功运行,返回true,则程序返回0;如果程序执行失败,返回false,则程序返回1
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
/**
* @param KEYIN
* →k1 表示每一行的起始位置(偏移量offset),Object类型
* @param VALUEIN
* →v1 表示每一行的文本内容,Text类型
* @param KEYOUT
* →k2 表示每一行中的每个单词,Text类型
* @param VALUEOUT
* →v2 表示每一行中的每个单词的出现次数,固定值为1,Intwritable类型
*/
static class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
// 重写map方法,将k1,v1转为k2,v2
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 单词分隔符为\t
String[] splits = value.toString().split("\t");
for(String word: splits){
context.write(new Text(word), one)
}
}
}
/**
* @param KEYIN
* →k2 表示每一行中的每个单词,Text类型
* @param VALUEIN
* →v2 表示每一行中的每个单词的出现次数,固定值为1,IntWritable类型
* @param KEYOUT
* →k3 表示每一行中的每个单词,Text类型
* @param VALUEOUT
* →v3 表示每一行中的每个单词的出现次数之和,IntWritable类型
*/
static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 遍历集合,将集合中的数字相加
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140755.html

