
HBase的伪分布式依赖于Hadoop的环境,所以需要配置Hadoop,完全分布式,HA都可以。这里依照最简单的Hadoop完全分布式配置。
HBASE 理论
1. Hadoop的配置
2.HBase完全分布式[内置zookeeper]
基于Hadoop伪分布式
[root@hadoop001 ~]# /export/conf/jps.sh
==========hadoop001的JPS=============
3859 ResourceManager
3525 DataNode
4374 Jps
3322 NameNode
3994 NodeManager
==========hadoop002的JPS=============
5296 SecondaryNameNode
5473 NodeManager
5665 Jps
5101 DataNode
==========hadoop003的JPS=============
3360 NodeManager
3552 Jps
3153 DataNode
2.1 copy文件到/export/software下并解压hbase
[root@hadoop001 software]# ls -ll
total 488868
-rw-r--r-- 1 root root 214092195 Apr 18 18:54 hadoop-2.7.3.tar.gz
-rw-r--r-- 1 root root 104659474 May 26 2021 hbase-1.2.6-bin.tar.gz
-rw-r--r-- 1 root root 146799982 Apr 18 18:55 jdk-8u311-linux-x64.tar.gz
-rw-r--r-- 1 root root 35042811 Mar 24 00:37 zookeeper-3.4.10.tar.gz
[root@hadoop001 software]# tar -xzvf /export/software/hbase-1.2.6-bin.tar.gz -C /export/servers/
[root@hadoop001 software]# cd /export/servers/
[root@hadoop001 servers]# ls -ll
total 12
drwxr-xr-x 10 root root 150 Jun 6 18:12 ha
lrwxrwxrwx 1 root root 29 Jun 6 20:41 hadoop -> /export/servers/hadoop-2.7.3/
drwxr-xr-x 10 root root 4096 Aug 17 2016 hadoop-2.7.3
drwxr-xr-x 7 root root 150 Jun 12 06:57 hbase-1.2.6
lrwxrwxrwx 1 root root 13 Apr 18 18:59 jdk -> jdk1.8.0_311/
drwxr-xr-x 8 10143 10143 4096 Sep 27 2021 jdk1.8.0_311
lrwxrwxrwx 1 root root 17 May 30 18:43 zookeeper -> zookeeper-3.4.10/
drwxr-xr-x 10 1001 1001 4096 Mar 23 2017 zookeeper-3.4.10
2.2 配置hbase环境变量
[root@hadoop001 servers]# vi /etc/profile.d/hadoop_env.sh
#在这里插入代码片
export JAVA_HOME=/export/servers/jdk
export ZOOKEEPER_HOME=/export/servers/zookeeper
export HADOOP_HOME=/export/servers/hadoop
export HBASE_HOME=/export/servers/hbase-1.2.6
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
#source /etc/profile.d/hadoop_env.sh使得配置生效
[root@hadoop001 servers]# source /etc/profile.d/hadoop_env.sh
2.3 为 $HBASE_HOME/conf/hbase-env.sh配置JAVA_HOME
由于HBase依赖JAVA_HOME环境变量,所以要编辑$HBASE_HOME/conf/hbase-env.sh文件,并取消注释以#export JAVA_HOME =开头的行,然后将其设置为Java安装路径。
[root@hadoop001 servers]# vi $HBASE_HOME/conf/hbase-env.sh
#取消JAVA_HOME的注释,并设置JAVA_HOME
export JAVA_HOME=/export/servers/jdk
2.4 配置hbase使用的 zookeeper
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
# export HBASE_MANAGES_ZK=true
语句【export HBASE_MANAGES_ZK=true】表示采用HBase自带的ZooKeeper管理。如果想用外部ZooKeeper管理HBase,可以自行安装、配置ZooKeeper,再把该句删除。
2.5 $HBASE_HOME/conf/hbase-site.xml
[root@hadoop001 servers]# vi $HBASE_HOME/conf/hbase-site.xml
<configuration>
<!--HBase的运行模式,false是单机模式,true是分布式模式。若为false,HBase和Zookeeper会运行在同一个JVM里面-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--region server的共享目录,用来持久化HBase-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop001:9000/hbase</value>
</property>
<!--Zookeeper集群的地址列表-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop001,hadoop002,hadoop003</value>
</property>
<!--HBase Master web 界面端口-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/data/hbase/zookeeper</value>
</property>
</configuration>
2.6 配置 $HBASE_HOME/conf/regionservers
[root@hadoop001 servers]# vi $HBASE_HOME/conf/regionservers
#修改内容如下
hadoop001
hadoop002
hadoop003
2.7 分发到Hadoop002,hadoop003
[root@hadoop001 servers]# scp /etc/profile.d/hadoop_env.sh hadoop002:/etc/profile.d/hadoop_env.sh
[root@hadoop001 servers]# scp /etc/profile.d/hadoop_env.sh hadoop003:/etc/profile.d/hadoop_env.sh
[root@hadoop001 servers]# scp -r /export/servers/hbase-1.2.6 hadoop002:/export/servers/
[root@hadoop001 servers]# scp -r /export/servers/hbase-1.2.6 hadoop003:/export/servers/
[root@hadoop001 servers]# ssh hadoop002
[root@hadoop002 ~]# source /etc/profile.d/hadoop_env.sh
[root@hadoop002 ~]# exit
logout
Connection to hadoop002 closed.
[root@hadoop001 servers]#
[root@hadoop001 servers]# ssh hadoop003
[root@hadoop003 ~]# source /etc/profile.d/hadoop_env.sh
[root@hadoop003 ~]# exit
logout
Connection to hadoop002 closed.
[root@hadoop001 servers]#
3启动后的jps和界面
[root@hadoop001 servers]# start-hbase.sh
[root@hadoop001 servers]# /export/conf/jps.sh
==========hadoop001的JPS=============
6017 HQuorumPeer
3859 ResourceManager
3525 DataNode
6150 HMaster
6710 Jps
3322 NameNode
3994 NodeManager
6314 HRegionServer
==========hadoop002的JPS=============
5296 SecondaryNameNode
5473 NodeManager
9283 HQuorumPeer
9476 HRegionServer
9770 Jps
5101 DataNode
==========hadoop003的JPS=============
3360 NodeManager
3153 DataNode
5154 Jps
4668 HQuorumPeer
4862 HRegionServer
界面
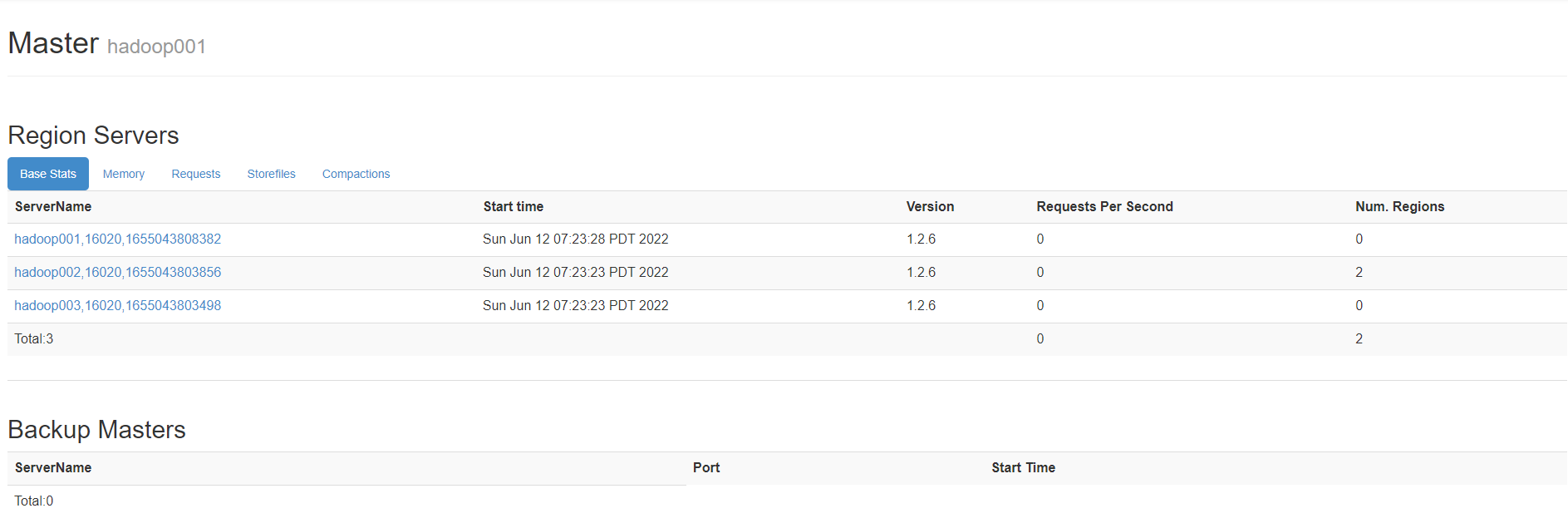
4 测试数据
(1)列举表
命令如下:
hbase(main):001:0> list
TABLE
0 row(s) in 0.5350 seconds
=> []
(2)创建表
语法格式:create
,{NAME => ,VERSIONS => }
例如,创建表t1,有两个family name:f1、f2,且版本数均为2,命令如下:
hbase(main):002:0> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
0 row(s) in 2.7600 seconds
=> Hbase::Table - t1
(3)删除表
删除表分两步:首先使用disable 禁用表,然后再用drop命令删除表。例如,删除表t1操作如下:
hbase(main):012:0> disable 't1'
0 row(s) in 2.8450 seconds
hbase(main):013:0> drop 't1'
0 row(s) in 1.2960 seconds
hbase(main):014:0> list
TABLE
0 row(s) in 0.0060 seconds
=> []
(4)查看表的结构
语法格式:describe
例如,查看表t1的结构,命令如下:
hbase(main):026:0> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
0 row(s) in 1.2640 seconds
=> Hbase::Table - t1
hbase(main):027:0> desc 't1'
Table t1 is ENABLED
t1
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '2', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
{NAME => 'f2', BLOOMFILTER => 'ROW', VERSIONS => '2', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.0650 seconds
(5)修改表的结构
修改表结构必须用disable禁用表,才能修改。
语法格式:alter ‘t1’,{NAME => ‘f1’},{NAME => ‘f2’,METHOD => ‘delete’}
例如,修改表t1的cf的TTL为180天,命令如下:
hbase(main):046:0> desc 't1'
Table t1 is ENABLED
t1
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '2', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
{NAME => 'f2', BLOOMFILTER => 'ROW', VERSIONS => '2', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.0280 seconds
hbase(main):047:0> disable 't1'
0 row(s) in 2.2620 seconds
hbase(main):048:0> alter 't1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 3.8880 seconds
hbase(main):049:0> enable 't1'
0 row(s) in 1.3000 seconds
hbase(main):050:0> desc 't1'
Table t1 is ENABLED
t1
COLUMN FAMILIES DESCRIPTION
{NAME => 'body', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOC
K_ENCODING => 'NONE', TTL => '15552000 SECONDS (180 DAYS)', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE =>
'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '2', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
{NAME => 'f2', BLOOMFILTER => 'ROW', VERSIONS => '2', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
{NAME => 'meta', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOC
K_ENCODING => 'NONE', TTL => '15552000 SECONDS (180 DAYS)', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE =>
'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
4 row(s) in 0.0300 seconds
(6).表数据的增删改查
1)添加数据
语法格式:put
,,
family:column,,
例如,给表t1的添加一行记录,其中,rowkey是rowkey001,family name是f1,column name是col1,value是value01,timestamp为系统默认。则命令如下:
hbase(main):095:0> put 't1','rowkey001','f1:col1','value01'
0 row(s) in 0.2320 seconds
hbase(main):096:0> put 't1','rowkey002','f2:col1','value02'
0 row(s) in 0.0290 seconds
hbase(main):097:0> scan 't1'
ROW COLUMN+CELL
rowkey001 column=f1:col1, timestamp=1655044418339, value=value01
rowkey002 column=f2:col1, timestamp=1655044427152, value=value02
2 row(s) in 0.1060 seconds
2)查询数据
① 查询某行记录。
语法格式:get
,,[
family:column,…]
例如,查询表t1,rowkey001中的f1下的col1的值,命令如下:
hbase(main):109:0> get 't1','rowkey001', 'f1:col1'
COLUMN CELL
f1:col1 timestamp=1655044418339, value=value01
1 row(s) in 0.0970 seconds
或者用如下命令:
hbase(main)> get ‘t1’,‘rowkey001’, {COLUMN=>‘f1:col1’}
查询表t1,rowke002中的f1下的所有列值,命令如下:
hbase(main):114:0> get 't1','rowkey001', {COLUMN=>'f1:col1'}
COLUMN CELL
f1:col1 timestamp=1655044418339, value=value01
1 row(s) in 0.0230 seconds
② 扫描表。
语法格式:scan
,{COLUMNS => [
family:column,… ],LIMIT => num}
另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能。
例如,扫描表t1的前5条数据,命令如下:
hbase(main):119:0> scan 't1',{LIMIT=>5}
ROW COLUMN+CELL
rowkey001 column=f1:col1, timestamp=1655044418339, value=value01
rowkey002 column=f2:col1, timestamp=1655044427152, value=value02
2 row(s) in 0.1160 seconds
③ 查询表中的数据行数。
语法格式:count
,{INTERVAL => intervalNum,CACHE => cacheNum}
其中,INTERVAL设置多少行显示一次及对应的rowkey,默认为1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度。
例如,查询表t1中的行数,每100条显示一次,缓存区为500,命令如下:
hbase(main):125:0> count 't1', {INTERVAL => 100, CACHE => 500}
2 row(s) in 0.0420 seconds
=> 2
3)删除数据
① 删除行中的某个值。
语法格式:delete
,,
family:column,
例如,删除表t1,rowkey001中的f1:col1的数据,命令如下:
hbase(main):130:0> delete 't1','rowkey001','f1:col1'
0 row(s) in 0.0560 seconds
hbase(main):136:0> scan 't1'
ROW COLUMN+CELL
rowkey002 column=f2:col1, timestamp=1655044427152, value=value02
1 row(s) in 0.0140 seconds
② 删除行。
语法格式:deleteall
,,
family:column,
这里可以不指定列名,也可删除整行数据。
例如,删除表t1,rowk001的数据,命令如下:
hbase(main):141:0> deleteall 't1','rowkey001'
0 row(s) in 0.0130 seconds
hbase(main):142:0> scan 't1'
ROW COLUMN+CELL
rowkey002 column=f2:col1, timestamp=1655044427152, value=value02
1 row(s) in 0.0320 seconds
③ 删除表中的所有数据。
语法格式:truncate
其具体过程是:disable table -> drop table -> create table
例如,删除表t1的所有数据,命令如下:
hbase(main):151:0> truncate 't1'
Truncating 't1' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 3.9590 seconds
4.HBase完全分布式[外部zookeeper]
4.1修改编辑$HBASE_HOME/conf/hbase-env.sh
[root@hadoop001 servers]# vi $HBASE_HOME/conf/hbase-env.sh
#使用外部zookeeper管理hbase
export HBASE_MANAGES_ZK=flase
4.2修改编辑$HBASE_HOME/conf/hbase-site.xml
添加zookeeper的地址集群列表
[root@hadoop001 servers]# vi $HBASE_HOME/conf/hbase-site.xml
#添加如下内容
<!--Zookeeper集群的地址列表-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
4.3 分发到hadoop002,hadoop003上
[root@hadoop001 servers]# scp /export/servers/hbase-1.2.6/conf/hbase-env.sh hadoop002:/export/servers/hbase-1.2.6/conf/hbase-env.sh
[root@hadoop001 servers]# scp /export/servers/hbase-1.2.6/conf/hbase-env.sh hadoop003:/export/servers/hbase-1.2.6/conf/hbase-env.sh
[root@hadoop001 servers]# scp /export/servers/hbase-1.2.6/conf/hbase-site.xml hadoop002:/export/servers/hbase-1.2.6/conf/hbase-site.xml
[root@hadoop001 servers]# scp /export/servers/hbase-1.2.6/conf/hbase-site.xml hadoop003:/export/servers/hbase-1.2.6/conf/hbase-site.xml
#或者
[root@hadoop001 servers]# cd /export/servers/hbase-1.2.6/conf/
[root@hadoop001 conf]# scp hbase-site.xml hbase-env.sh hadoop002:`pwd`
hbase-site.xml 100% 1896 1.9KB/s 00:00
hbase-env.sh 100% 7465 7.3KB/s 00:00
[root@hadoop001 conf]# scp hbase-site.xml hbase-env.sh hadoop003:`pwd`
hbase-site.xml 100% 1896 1.9KB/s 00:00
hbase-env.sh 100% 7465 7.3KB/s 00:00
4.4 hadoop001,hadoop002,hadoop003上启动zookeeper
[root@hadoop001 ~]# zkServer.sh start
[root@hadoop002 ~]# zkServer.sh start
[root@hadoop003 ~]# zkServer.sh start
启动后的进程如下
==========hadoop001的JPS=============
9040 QuorumPeerMain
3859 ResourceManager
3525 DataNode
9686 Jps
3322 NameNode
3994 NodeManager
==========hadoop002的JPS=============
5296 SecondaryNameNode
5473 NodeManager
11201 QuorumPeerMain
5101 DataNode
11423 Jps
==========hadoop003的JPS=============
3360 NodeManager
3153 DataNode
6774 Jps
6063 QuorumPeerMain
4.5 启动hbase
[root@hadoop001 ~]# start-hbase.sh
[root@hadoop001 ~]# /export/conf/jps.sh
==========hadoop001的JPS=============
9040 QuorumPeerMain
10146 HRegionServer
3859 ResourceManager
3525 DataNode
9991 HMaster
3322 NameNode
3994 NodeManager
10510 Jps
==========hadoop002的JPS=============
5296 SecondaryNameNode
5473 NodeManager
11201 QuorumPeerMain
11683 Jps
5101 DataNode
11487 HRegionServer
==========hadoop003的JPS=============
3360 NodeManager
3153 DataNode
6933 HRegionServer
7182 Jps
6063 QuorumPeerMain
4.5 测试
知识点之HQuorumPeer
hbase是列式数据库,既可以单机也可以以集群的方式搭建,以集群的方式搭建一般建立在hdfs之上。
分布式的hbase如何启动?
首先启动hadoop,然后就来问题了:zookeeper和hbase的启动顺序是什么?
1,先启动hbase:hbase有内置的zookeeper,如果没有装zookeeper,启动hbase的时候会有一个HQuorumPeer进程。
2.先启动zookeeper:如果用外置的zookeeper管理hbase,则先启动zookeeper,然后启动hbase,启动后会有一个QuorumPeerMain进程。
两个进程的名称不一样
HQuorumPeer表示hbase管理的zookeeper
QuorumPeerMain表示zookeeper独立的进程
知识点之Hbase Table already exist
解决方案:
进入HMaster节点,执行,bin/zkCli.sh
ls /hbase/table,查看是否有要新建的表,如果有使用rmr命令删除,之后重启Hbase,使用create即可成功
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140756.html

