
HBase的伪分布式依赖于Hadoop的环境,所以需要配置Hadoop,伪分布式,完全分布式,HA都可以。这里依照最简单的Hadoop分布式配置。
HBASE 理论
1. Hadoop的配置
Hadoop 伪分布式
Hadoop 完全分布式
Hadoop HA
2. HBase的伪分布式配置
基于Hadoop伪分布式
[root@single hadoop]# jps
7587 DataNode
7875 SecondaryNameNode
8243 NodeManager
8597 Jps
8103 ResourceManager
7423 NameNode
2.1 解压hbase
[root@localhost servers]# tar -xzvf /export/software/hbase-1.2.6-bin.tar.gz -C /export/servers/
[root@localhost servers]# cd /export/servers/
[root@localhost servers]# ls -ll
total 8
drwxr-xr-x. 9 root root 4096 Aug 17 2016 hadoop-2.7.3
drwxr-xr-x 7 root root 150 Jun 10 17:51 hbase-1.2.6
drwxr-xr-x. 8 10143 10143 4096 Sep 27 2021 jdk1.8.0_311
2.2 配置hbase环境变量
[root@localhost servers]# vi /etc/profile
#在这里插入代码片
export JAVA_HOME=/export/servers/jdk1.8.0_311
export HADOOP_HOME=/export/servers/hadoop-2.7.3
export HBASE_HOME=/export/servers/hbase-1.2.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
2.3.配置hbase
2.3.1 $HBASE_HOME/conf/hbase-env.sh
由于HBase依赖JAVA_HOME环境变量,所以要编辑$HBASE_HOME/conf/hbase-env.sh文件,并取消注释以#export JAVA_HOME =开头的行,然后将其设置为Java安装路径。
[root@localhost conf]# vi $HBASE_HOME/conf/hbase-env.sh
#取消JAVA_HOME的注释,并设置JAVA_HOME
export JAVA_HOME=/export/servers/jdk1.8.0_311
hbase 默认使用内置 zookeeper
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
# export HBASE_MANAGES_ZK=true
语句【export HBASE_MANAGES_ZK=true】表示采用HBase自带的ZooKeeper管理。如果想用外部ZooKeeper管理HBase,可以自行安装、配置ZooKeeper,再把该句删除。
2.3.2 $HBASE_HOME/conf/hbase-site.xml
在本地文件系统上指定HBase和ZooKeeper写入数据的目录并确认一些风险。默认情况下,在/export/data下创建一个新目录habase。默认位置/tmp,但是许多服务器配置为在重新引导时删除/ tmp的内容,因此您应该将数据存储在其他位置。
[root@localhost conf]# vi $HBASE_HOME/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://single:9000/hbase</value>
<!-- 下面是保存到本地,此时不需要部署hadoop -->
<!-- <value>file:///export/data/hbase/hbase</value> -->
</property>
<!-- false单机模式(会启动自带的zookeeper),true是分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper数据文件路径 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/data/hbase/zookeeper</value>
</property>
</configuration>
3.启动HBASE
3.1 启动
[root@localhost conf]# start-hbase.sh
starting master, logging to /export/servers/hbase-1.2.6/logs/hbase-root-master-localhost.localdomain.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
3.2 查看进程
[root@single hadoop]# jps
7587 DataNode
7875 SecondaryNameNode
8243 NodeManager
12547 HRegionServer
8103 ResourceManager
12297 HQuorumPeer
12651 Jps
12397 HMaster
7423 NameNode
HMaster进程就是HBase的主进程。HMaster进程启动表明HBase单机模式启动成功。
3.3 访问HBase的web界面
http://192.168.121.150:16010/master-status
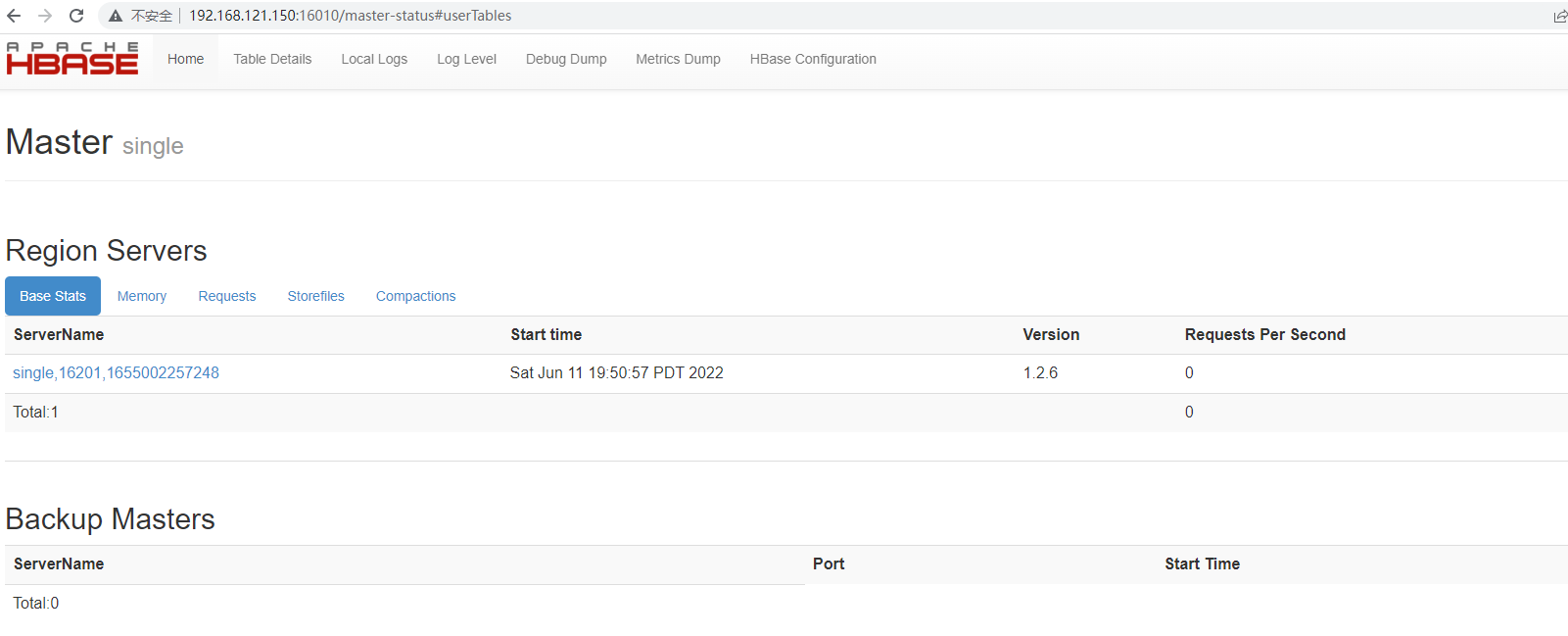
4测试
4.1 在shell端创建一个Hbase表
hbase(main):042:0> create 't2','f1'
0 row(s) in 1.2590 seconds
=> Hbase::Table - t2
4.2 查看表结构
hbase(main):047:0> describe 't2'
Table t2 is ENABLED
t2
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.0470 seconds
从上面的表结构中,我们可以看到,VERSIONS为1,也就是说,默认情况只会存取一个版本的列数据,当再次插入的时候,后面的值会覆盖前面的值。
4.3 修改表结构
修改表结构,让Hbase表支持存储3个VERSIONS的版本列数据
hbase(main):056:0> alter 't2',{NAME=>'f1',VERSIONS=>3}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.9170 seconds
再次查看表结构:
hbase(main):062:0> desc 't2'
Table t2 is ENABLED
t2
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_
ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '
65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.0250 seconds
我们会发现VERSIONS已经修改成了3.
4、插入3行数据
hbase(main):071:0> put 't2','rowkey1','f1:name','tom'
0 row(s) in 0.0240 seconds
hbase(main):075:0> put 't2','rowkey1','f1:name','jack'
0 row(s) in 0.0310 seconds
hbase(main):076:0> put 't2','rowkey1','f1:name','lily'
0 row(s) in 0.0150 seconds
hbase(main):077:0> get 't2','rowkey1','f1:name'
COLUMN CELL
f1:name timestamp=1654964444338, value=lily
1 row(s) in 0.0240 seconds
hbase(main):090:0> scan 't2'
ROW COLUMN+CELL
rowkey1 column=f1:name, timestamp=1654964444338, value=lily
1 row(s) in 0.0480 seconds
从上面可以看出,插入了3行数据到表中,并且3行数据的rowkey一致,然后使用get命令来获取这一行数据,发现只返回了最新的一行数据。
5、获取多行数据方法
hbase(main):095:0> get 't2','rowkey1',{COLUMN=>'f1:name',VERSIONS=>3}
COLUMN CELL
f1:name timestamp=1654964444338, value=lily
f1:name timestamp=1654964436752, value=jack
f1:name timestamp=1654964406100, value=tom
3 row(s) in 0.0180 seconds
hbase(main):096:0> get 't2','rowkey1',{COLUMN=>'f1:name',VERSIONS=>2}
COLUMN CELL
f1:name timestamp=1654964444338, value=lily
f1:name timestamp=1654964436752, value=jack
2 row(s) in 0.0150 seconds
从上面的测试结果中,可以看出,一次性获取了个版本的数据。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140757.html

