
引入库
1.request来获取页面内容
https://requests.readthedocs.io/zh_CN/latest/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple request
2.BeautifulSoup
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bs4
import requests
from bs4 import BeautifulSoup
url = "https://bj.lianjia.com/zufang/"
response = requests.get(url)
response
soup = BeautifulSoup(response.text, "lxml")
# response.text #获取url内容
# soup #格式化的 response.text
link_div=soup.find_all('div',class_='content__list--item')
#link_div[0].a.get('href')
links=['https://bj.lianjia.com'+div.a.get('href') for div in link_div]
links


# 获取URL下的页面内容
def get_page(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
return soup
#封装成函数,名字为get_links,获取租房页面的链接,返回链接列表
def get_links(links_url):
soup = get_page(links_url)
link_div=soup.find_all('div',class_='content__list--item')
links=['https://bj.lianjia.com'+div.a.get('href') for div in link_div]
return links

house_url = "https://bj.lianjia.com/zufang/BJ2600620531699433472.html"
soup = get_page(house_url)
price = soup.find('div',class_='content__aside--title').span.text
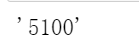
soup.find('ul',class_='content__aside__list').find_all('li')[1].text

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140779.html

