
通过指定url安装指定包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scipy #引入scipy的目的是plot.kde()需要用
pandas[数据处理]
1. 准备
导入使用的包
import pandas as pd
# %matplotlib.pyplot as pit
%matplotlib inline
导入数据
titanic = pd.read_csv("train.csv")
#train.csv数据可以从一下地方获取
#https://gitee.com/sdau20171754/machelearning2/blob/master/train.csv

快速浏览数据
titanic.head(2) #显示几条数据
titanic.head()

| 标题名字 | 中文意思 |
|---|---|
| PassengerId | 旅客编号 |
| Survived | 是否幸存 |
| Pclass | 社会阶层(1.精英 2.中层 3.船员/劳苦大众) |
| Name | 姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 兄弟姐妹配偶 个数 |
| Parch | 父母儿女 个数 |
| Ticket | 船票号 |
| Fare | 船票价格 |
| Cabin | 船舱 |
| Embarked | 登船口 |
数据信息
titanic.info() #查看数据信息
titanic.describe() #所有数值类型的字段数据做个简单的统计


统计null的数据
在这里插入代码片
titanic.isnull()
titanic.isnull().sum()

2. 处理null值
# 可以填充整个dataFrame里的Null值为o
#titanic.fillna(0)
# 可以填充某列的null值
#titanic.Age.fillna(0)
# 求中位数
titanic.median()
#年龄的中位数
titanic.Age.median()
#填充年龄的中位数
#type(titanic.Age.fillna(titanic.Age.median())) # pandas.core.series.Series
#直接填充并不返回新的Series
titanic.Age.fillna(titanic.Age.median(), inplace=True)
填充完毕后查看
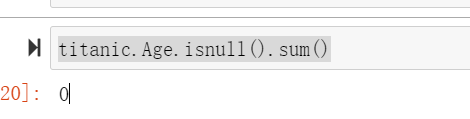
titanic.Age.isnull().sum()
3.尝试从性别开始分析生还者
做简单的汇总统计
# 做简单的汇总统计
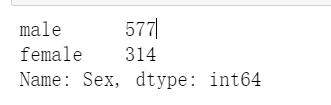
titanic.Sex.value_counts()
生还者中男女的人数
#titanic[titanic.Survived==1].Sex
#生还者中男女的人数
titanic[titanic.Survived==1].Sex.value_counts()

未生还者中男女的人数
titanic[titanic.Survived==0].Sex.value_counts()

合成一个新的dataframe
survived = titanic[titanic.Survived==1].Sex.value_counts()
dead = titanic[titanic.Survived==0].Sex.value_counts()
df = pd.DataFrame([survived, dead])
df
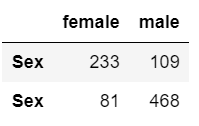
df = pd.DataFrame([survived, dead],index=['survived','dead'])
df

画图
df.plot(kind='bar') #等价于df.plot.bar()

转置dataframe
#转置dataframe
df = df.T
df.plot.bar() # 等价于df.plot(kind='bar')

另外一种效果图
df.plot(kind='bar', stacked='True')

显示百分比
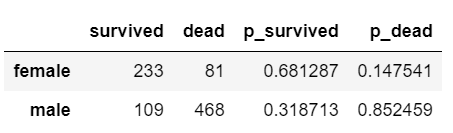
df['p_survived'] = df.survived / df.survived.sum()
df['p_dead'] = df.dead /df.dead.sum()
df
df['p_survived'] = df.survived / (df.survived + df.dead)
df['p_dead'] = df.dead /(df.survived + df.dead)
df
df[['p_survived','p_dead']].plot(kind='bar', stacked='True')

通过上图可以看出,性别对是否生还的影响还是挺大的
4.从年龄分析生还者
# 简单统计
# titanic.Age.value_counts()
survived = titanic[titanic.Survived==1].Age
dead = titanic[titanic.Survived==0].Age
df = pd.DataFrame([survived, dead],index=['survived','dead']).T
df.plot.hist(stacked='True')

直方图
# 直方图柱子多一点
df.plot.hist(stacked='True',bins=30)
# 中间很高的柱子是因为把null值都替换为中位数

密度图
#密度图
df.plot.kde()

# 查看年龄的分布,来决定横轴的取值范围
titanic.Age.describe()

df.plot.kde(xlim=(0,80))

区分成年人和未成年人以16岁为界
# 区分成年人和未成年人以16岁为界
age = 16
young = titanic[titanic.Age<=16]['Survived'].value_counts()
old = titanic[titanic.Age>16]['Survived'].value_counts()
df = pd.DataFrame([young, old],index=['young', 'old'])
df

df.columns=['dead', 'survived']
df
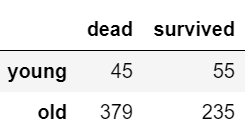
df.plot.bar(stacked=True)

df['p_survived'] = df.survived / (df.survived + df.dead)
df['p_dead'] = df.dead /(df.survived + df.dead)
df
df[['p_survived','p_dead']].plot(kind='bar', stacked='True')

5.票价特征
#票价特征和年龄相似
# titanic.Fare
survived = titanic[titanic.Survived == 1].Fare
dead = titanic[titanic.Survived == 0].Fare
df = pd.DataFrame([survived, dead], index = ['survived','dead']).T
df.plot.kde()

#设定x轴的范围
titanic.Fare.describe()

df.plot.kde(xlim=(0,513))

6.组合特征 使用matplotlib[绘图]
# 同时查看年龄和票价对生还率的影响
import matplotlib.pyplot as plt
titanic[titanic.Survived == 0].Age
plt.scatter(titanic[titanic.Survived == 0].Age, titanic[titanic.Survived == 0].Fare)

# 不美观
age = titanic[titanic.Survived == 0].Age
fare = titanic[titanic.Survived == 0].Fare
plt.scatter(age, fare, s = 10)

# 查看函数用法
plt.scatter?
#继续设置x轴y轴显示
ax = plt.subplot()
age = titanic[titanic.Survived == 0].Age
fare = titanic[titanic.Survived == 0].Fare
plt.scatter(age, fare, s = 10)
ax.set_xlabel('age')
ax.set_ylabel('fare')

#继续设置alpha透明度,linewidths,edgecolors,c(颜色)
ax = plt.subplot()
age = titanic[titanic.Survived == 0].Age
fare = titanic[titanic.Survived == 0].Fare
plt.scatter(age, fare, s = 10, alpha = 0.5, linewidths=20, edgecolors='red', c='yellow')
ax.set_xlabel('age')
ax.set_ylabel('fare')

合成同一个图形
#合成同一个图形
ax = plt.subplot()
#未生还者
age = titanic[titanic.Survived == 0].Age
fare = titanic[titanic.Survived == 0].Fare
plt.scatter(age, fare, s = 10, alpha = 0.5)
#生还者
age = titanic[titanic.Survived == 1].Age
fare = titanic[titanic.Survived == 1].Fare
plt.scatter(age, fare, s = 10, alpha = 0.5, c='red')
ax.set_xlabel('age')
ax.set_ylabel('fare')

7.隐含特征
#titanic.Name.value_counts()
#titanic.Name.describe()
titanic['title'] = titanic.Name.apply(lambda name: name.split(',')[1].split('.')[0].strip())
s = "Andersson, Miss. Ebba Iris Alfrida"
print(s.split(','))
print(s.split(',')[1])
print(s.split(',')[1].split('.'))
print(s.split(',')[1].split('.')[0])
print(s.split(',')[1].split('.')[0].strip())
titanic.title.value_counts()
# 比如被称为Mr,而年龄是未知的,可以采用Mr称为的年龄平均值来填充并不是采用所有人的年龄平均值

8.寻找隐含数据
# 夜光图,简单用灯光图的亮度来模拟gdp,学会已有的特征寻找数据
titanic['family_size'] = titanic.SibSp + titanic.Parch + 1
titanic.family_size.value_counts()

def func(family_size):
if family_size==1:
return 'Singleton'
if family_size<=4 and family_size>=2:
return 'SmallFamily'
if family_size>4:
return 'LargeFamily'
titanic['family_type'] = titanic.family_size.apply(func)

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140781.html

