
概述
Oracle数据库是一个非常成熟的产品,因此Oracle官方资源能够比较全面地在支持该产品,而且经过多年的发展,
形成了一个完整的学习和发展的生态圈,通过有效地利用ORACLE官方提供的各种资源,无疑会事半功倍地提高学习和应用的效率。
本文将介绍各种ORACLE官方资源并通过学习12c·In-memory 列存储等例子来介绍如何有效地利用。
OTN
OTN即Oracle Technology Network,是Oracle官方提供的技术网站,在OTN上提供包括相关软件下载、产品文档、相关技术文章、论坛及博客入口链接、博客、视频等资料和相关链接。
在系统学习Oracle知识时,可以以此为入口,通过产品文档、技术文章和实际案例深刻地理解和熟练地使用数据库。
OTN的URL如下:
英文版
http://www.oracle.com/technetwork/index.html
中文版
http://www.oracle.com/technetwork/cn/index.html
在线产品文档(用户手册)
在线产品文档是数据库等产品的最基础也是最重要的官方资源.
通过阅读在线文档,可以了解在设计层面上,数据库产品是怎么设计的,以及在正常情况下是如何运行和使用的;而文档阅读能力也会随之提高。
例:应用实践1(In-memory学习)
例如,我们在学习一个新的数据库功能(如:12c 的In-memory Column Store列存储)时,可以通过如下的步骤进行学习:
一.
最初,我们可以从在线产品文档(用户手册)的Database Concepts 了解其相关的概念.
Oracle Database Concepts for an overview of the IM column store
http://docs.oracle.com/database/121/CNCPT/memory.htm#CNCPT89659
>In-Memory Column Store
通过阅读Concepts,我们可以了解到关于In-memory 列存储的概念性的信息,如:
1.作为In-Memory option,Oracle 12.1.0.2版本推出了In-memory列存储功能。
该功能把表或者分区表的数据,以列式存储的方式复制到SGA的一个独立区域中(static SGA pool)进行相关处理。
2.内存列存储的好处,如:提高全表扫描、 =, <, >, IN等谓词过滤操作、表的部分数据查询的效率,以及大事实表和小维度表的结合速度等;同时启用In-memory功能是,应用层不需要做任何的修改。
3.如果启用In-memory功能,通过相关设定,能够使内存中的一些数据同时具有适合OLTP实时更新的行存储结构和适合OLAT的数据分析的列存储结构;并且传统的buffer cache处理方式会和In-memory列存储的处理方式共存,从而同时获得两种技术的好处。
4.Oracle会通过Worker进程(Wnnn) 把磁盘上行存储结构的数据,装载和压缩到内存列存储的 In-Memory Compression Units (IMCUs)中。
并且我们了解到Worker进程(Wnnn)数由初始化参数INMEMORY_MAX_POPULATE_SERVERS的决定;而转载的动作可能会在数据库启动或者查询开始时实施。
5.可以在建立(CREATE)或者修改(ALTER)表时,指定MEMCOMPRESS属性对In-memory列存储进行压缩,以获得更好的性能或者节省存储内存。
二.
接着,对于In-memory列存储功能的一些具体相关维护操作和详细内容我们可以阅读Oracle Database Administrator’s Guide。
Oracle Database Administrator's Guide
http://docs.oracle.com/database/121/ADMIN/memory.htm#ADMIN14257
>Using the In-Memory Column Store
通过阅读Administrator’s Guide,我们又可以进一步学习相关的内容:
1.In-memory列存储的详细。
・In-memory列存储内容存储在一个新的SGA静态池,是对buffer cache处理的一种补充。
・可以在以下级别使In-memory列存储功能有效:
列级别、表级别、物化视图、表空间、分区级别
・当要使某对象作为In-memory列存储时,需要指定INMEMORY属性。
・In-memory列存储时可以指定MEMCOMPRESS属性进行不同级别的压缩。
压缩级别可参考[文档](http://docs.oracle.com/database/121/ADMIN/memory.htm#GUID-1965B8FE-B34E-42D9-9E97-45D6579162A4__BABIHHDA)
・可以指定INMEMORY PRIORITY子属性来规定各个对象的In-memory加载级别和优先度。
2.关于In-memory列存储相关参数的介绍。
参数相关的详细信息可以参考【Database Reference】手册
SQL> show parameter inmemory
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
inmemory_clause_default string
inmemory_force string DEFAULT
inmemory_max_populate_servers integer 0
inmemory_query string ENABLE
inmemory_size big integer 0
inmemory_trickle_repopulate_servers_ integer 1
percent
optimizer_inmemory_aware boolean TRUE
3.如何使数据库的In-memory列存储功能有效。
可以通过设置inmemory_size参数,指定SGA的In-Memory Area区域大小,来使数据库In-memory列存储功能有效。
例:
SQL> show parameter inmemory_size
NAME TYPE VALUE
----------------- ----------- -------
inmemory_size big integer 0 ★
SQL> alter system set inmemory_size= 200 M scope=spfile;
System altered.
SQL> shutdown abort
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 838860800 bytes
Fixed Size 2929936 bytes
Variable Size 612371184 bytes
Database Buffers 8388608 bytes
Redo Buffers 5455872 bytes
In-Memory Area 209715200 bytes ★
Database mounted.
Database opened.
NAME TYPE VALUE
------------------- ----------- ------
inmemory_size big integer 200 M ★
4.如何使数据库的表的In-memory列存储功能有效/无效。
可以在建立(CREATE)或者修改(ALTER)表时指定INMEMORY属性,使表或者某列变为In-memory列存储对象。
例:
SQL> create table test_inmemory (id number,text varchar2(30)) INMEMORY;
Table created.
SQL> select TABLE_NAME,INMEMORY from dba_tables where TABLE_NAME='TEST_INMEMORY';
TABLE_NAME INMEMORY
-------------------- --------
TEST_INMEMORY ENABLED
5.如何使数据库的表空间的In-memory列存储功能有效/无效。
例:
SQL> CREATE TABLESPACE test_tbs1
DATAFILE 'test_tbs1.dbf' SIZE 100M ONLINE DEFAULT INMEMORY; 2
Tablespace created.
SQL> select TABLESPACE_NAME,DEF_INMEMORY from dba_tablespaces where TABLESPACE_NAME='TEST_TBS1';
TABLESPACE_NAME DEF_INME
------------------------------ --------
TEST_TBS1 ENABLED
6.如何使数据库的物理表的In-memory列存储功能有效/无效。
<略>
7.如何用Data Pump导入的In-memory列存储的对象。
<略>
三.
然后,我们可以从性能调优的角度去了解In-memory列存储功能。
通过在线产品文档的Database SQL Tuning Guide,我们可以学习到对于In-memory列存储,Oracle是如何在查询中使用的。
关于In-Memory Table Scans
Database SQL Tuning Guide
http://docs.oracle.com/database/121/TGSQL/tgsql_optop.htm#TGSQL95355
>In-Memory Table Scans
通过上面的介绍我们可以了解到:
・我们可以通过In-Memory Table Scans访问内存中以In-Memory列存储的数据(IM column store),以加快查询访问速度。
・和In-Memory查询相关的初期化参数主要包括以下几个:
INMEMORY_QUERY
OPTIMIZER_INMEMORY_AWARE
OPTIMIZER_FEATURES_ENABLE
・可以使用INMEMORY 或者 NO_INMEMORY HINT来控制单个查询是否使用In-Memory 查询
例:
SQL> create table PRODUCT_INFORMATION_IM as select * from PRODUCT_INFORMATION;
Table created.
SQL> alter table PRODUCT_INFORMATION_IM INMEMORY PRIORITY HIGH;
Table altered.
SQL> --wait for a few mins
SQL> select * from V$IM_SEGMENTS where SEGMENT_NAME='PRODUCT_INFORMATION_IM';
OWNE SEGMENT_NAME P SEGME TABLESPACE INMEMORY_SIZE BYTES BYTES_NOT_POPULATED POPULATE_ INMEMORY INMEMORY_DISTRI INMEMORY_DUPL INMEMORY_COMPRESS CON_ID
---- ------------------------ - ----- ---------- ------------- ------- ------------------- --------- -------- --------------- ------------- ----------------- ------
OE PRODUCT_INFORMATION_IM TABLE EXAMPLE ###### 131072 0 COMPLETED HIGH AUTO NO DUPLICATE FOR QUERY LOW 0
SQL> select * from table(dbms_xplan.display_cursor());
PLAN_TABLE_OUTPUT
------------------------------------------------------
SQL_ID bvrk2tacjfd7s, child number 0
-------------------------------------
select count(*) from PRODUCT_INFORMATION_IM
Plan hash value: 2219640410
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | 4 (100)| |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | ★TABLE ACCESS INMEMORY FULL| PRODUCT_INFORMATION_IM | 288 | 4 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
14 rows selected.
我们可以看到通过TABLE ACCESS INMEMORY FULL方式访问了PRODUCT_INFORMATION_IM表,即访问了内存中的列存储数据。
关于In-Memory Aggregation
在在线产品文档中同时介绍了In-Memory 查询用的In-Memory Aggregation功能。
Database SQL Tuning Guide
http://docs.oracle.com/database/121/TGSQL/tgsql_transform.htm#TGSQL95256
>In-Memory Aggregation
通过上面的介绍我们可以了解到:
1.In-Memory Aggregation是12.1.0.2针对In-Memory选件推出的新的查询转换(Query Transformations)方法
2.主要用于提高大表(事实表)和很多小表(维度表)结合时,进行数据聚合操作(如求和、平均值等)的执行效率。
3.通过KEY VECTOR 、 VECTOR GROUP BY 实现操作优化。
4.关于key vector的一些概念知识
A key vector:(关键向量)
is a data structure that maps between dense join keys and dense grouping keys.
用于表示密集连接键和密集分组键的数据结构。
A dense key:(密集键)
is a numeric key that is stored as a native integer and has a range of values.
具有一定范围的一组整数值。
A dense join key:(密集连接键)
represents all join keys whose join columns come from a particular fact table or dimension.
一组整数值用于表示是事实表和维度表的连接列。
A dense grouping key:(密集分组键)
represents all grouping keys whose grouping columns come from a particular fact table or dimension.
一组整数值用于表示是事实表和维度表的分组列。
5.VECTOR GROUP BY操作主要包括以下2个处理阶段:
Phase 1.依次处理各个维度表(小表)
a.找到所有的密集分组键
b.创建key vector(关键向量)
c.创建临时表
Phase 2.处理事实表(大表)
a.利用前一阶段(Phase 1)创建的key vector(关键向量),处理所有的连接和聚合操作。
b.a的结果和临时表进行连接处理。
并且,我们还可以通过文档上例子更加直观的了解In-Memory Aggregation处理过程。
例:
SQL> show user
USER is "SH"
SQL> create table TIMES_IM as select * from times;
Table created.
SQL> create table PRODUCTS_IM as select * from products;
Table created.
SQL> create table SALES_IM as select * from sales;
Table created.
SQL> alter table TIMES_IM INMEMORY PRIORITY HIGH;
Table altered.
SQL> alter table PRODUCTS_IM INMEMORY PRIORITY HIGH;
Table altered.
SQL> alter table SALES_IM INMEMORY PRIORITY HIGH;
Table altered.
SQL> select TABLE_NAME,INMEMORY,LAST_ANALYZED from dba_tables where TABLE_NAME in ('TIMES_IM','PRODUCTS_IM','SALES_IM');
TABLE_NAME INMEMORY LAST_ANALYZED
-------------------- -------- -------------------
TIMES_IM ENABLED 2016-09-28 17:12:35
PRODUCTS_IM ENABLED 2016-09-28 17:12:41
SALES_IM ENABLED 2016-09-28 17:12:49
SQL> select * from V$IM_SEGMENTS where SEGMENT_NAME='PRODUCT_INFORMATION_IM';
no rows selected
SQL> SELECT
/*+VECTOR_TRANSFORM gather_plan_statistics*/
t.calendar_year,
p.prod_category,
SUM ( quantity_sold )
FROM
TIMES_IM t,
PRODUCTS_IM p,
SALES_IM f
WHERE
t.time_id = f.time_id
AND
p.prod_id = f.prod_id
AND
t.calendar_year = '2001'
AND
p.prod_category = 'Photo'
GROUP BY
t.calendar_year,
p.prod_category; 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
CALENDAR_YEAR PROD_ SUM(QUANTITY_SOLD)
------------- ----- ------------------
2001 Photo 34787
SQL> select * from table(dbms_xplan.display_cursor(null,null,'ADVANCED ROWS ALLSTATS LAST'));
...
SELECT /*+VECTOR_TRANSFORM gather_plan_statistics*/
t.calendar_year, p.prod_category, SUM ( quantity_sold ) FROM
TIMES_IM t, PRODUCTS_IM p, SALES_IM f WHERE t.time_id =
f.time_id AND p.prod_id = f.prod_id AND t.calendar_year
= '2001' AND p.prod_category = 'Photo' GROUP BY
t.calendar_year, p.prod_category
Plan hash value: 1000663867
------------------------------------------------------------------------
| Id | Operation | Name |
------------------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TEMP TABLE TRANSFORMATION | |
| 2 | LOAD AS SELECT | |--->1.c (TIMES_IM)
| 3 | VECTOR GROUP BY | |
| 4 | KEY VECTOR CREATE BUFFERED | :KV0000 |--->1.b (TIMES_IM)
|* 5 | TABLE ACCESS INMEMORY FULL | TIMES_IM |--->1.a (TIMES_IM)
| 6 | LOAD AS SELECT | |--->1.c (PRODUCTS_IM)
| 7 | VECTOR GROUP BY | |
| 8 | HASH GROUP BY | |
| 9 | KEY VECTOR CREATE BUFFERED | :KV0001 |--->1.b (PRODUCTS_IM)
|* 10 | TABLE ACCESS INMEMORY FULL | PRODUCTS_IM |--->1.a (PRODUCTS_IM)
| 11 | HASH GROUP BY | |--->2.a
|* 12 | HASH JOIN | |
| 13 | MERGE JOIN CARTESIAN | |
| 14 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6603_205EC1 |
| 15 | BUFFER SORT | |
| 16 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6602_205EC1 |
| 17 | VIEW | VW_VT_AF278325 |
| 18 | VECTOR GROUP BY | |--->2.a
| 19 | HASH GROUP BY | |
| 20 | KEY VECTOR USE | :KV0000 |
| 21 | KEY VECTOR USE | :KV0001 |
|* 22 | TABLE ACCESS INMEMORY FULL| SALES_IM |
------------------------------------------------------------------------
四.
因为In-memory列存储功能主要适应大数据或者数据仓库等应用,所以在Database Data Warehousing Guide中也由相应的记述。
Database Data Warehousing Guide
http://docs.oracle.com/database/121/DWHSG/ch2logdes.htm#DWHSG9315
About the Oracle In-Memory Column Store
http://docs.oracle.com/database/121/DWHSG/ch2logdes.htm#DWHSG9328
About In-Memory Aggregation
通过上面【一、二、三、四 】各产品文档的学习,我们从了解其概念、管理方法、相关原理等方面对12c In-memory选件功能有了一定认识。
例:应用实践2(动态视图定义)
再如,在以前的咨询案例中,有用户质疑为什么有时候对V$SQL等动态视图进行聚合操作或者多个动态视图进行结合时,得到过的结果和预想的不一样?
其实对于这个问题,在以下的Database Reference产品文档中有明确的说明:
Database Reference
>About Dynamic Performance Views
About Dynamic Performance Views
Oracle contains a set of underlying views that are maintained by the database
server and accessible to the database administrator user SYS. These views are ★
called dynamic performance views because they are continuously updated while a ★
database is open and in use, and their contents relate primarily to performance.★
Although these views appear to be regular database tables, they are not. These
views provide data on internal disk structures and memory structures. You can
select from these views, but you can never update or alter them.
Note:
You can query the dynamic performance views to extract information from ★
them. However, only simple queries are supported. If sorts, joins, GROUP BY ★
clauses and the like are needed, then you should copy the information from each
V$ view into a table (for example, using a CREATE TABLE ... AS SELECT
statement), and then query from those tables.
Because the information in the V$ views is dynamic, read consistency is not
guaranteed for SELECT operations on these views.
即:
因为动态视图(v$)看起来像是普通的表,实际上是内部磁盘和内存的数据结构。
因此动态视图(v$)会不断地更新,不能提供读一致性,
因为式样上的限制,所以不能够进行 sorts, joins, GROUP BY等操作;
如果想要进行这些操作的话,你需要通过 CREATE TABLE ... AS SELECT 等命令
建一个普通表后再操作。
如果对产品文档的内容有过通读,就会有一定的印象,从而避免如上面的不必要的疑问和类似问题。
常用文档列表和简单介绍
仅仅是对数据库产品,其在线文档量也是非常庞大的,为了使大家能够对在线产品文档有一个概要的了解,以下列出了产品文档中比较常用的各个分册的列表和简单介绍,以供参考:
介绍了关于数据库的数据结构、事务管理、存储传输、实例等基础概念和整体介绍;建议最初的文档越多学习从这里开始。
关于数据库体系结构和存储、Schema相关内容管理等知识。
如果你对数据库以前的版本比较熟悉,而希望了解在新版本上有哪些变化,哪些新功能,可以阅读本手册。
一般SQL语法、表达式 、使用规则等相关的知识内容。可以作为查询手册使用。
SQL性能调优相关的优化器、执行计划、统计信息、自动调优等方面的知识。
关于数据库启动参数、字典视图、动态视图、等待事件定义等方面知识。可以作为查询手册使用。
数据库整体性能相关的调优方法和理论、内存调整、OS相关配置调优等知识
数据库提供的一些包括Data Pump、SQL*Loader、外部表等数据迁移工具,
以及LogMiner、DBVERIFY、DBNEWID ADRCI等工具的知识介绍和使用实例。
数据库相关的权限认证、审计等安全相关的知识。
Database VLDB and Partitioning Guide
分区表(Partitioning )、并行执行(Parallel Execution)等数据仓库用到的知识介绍。
Real Application Clusters Administration and Deployment Guide
Oracle Clusterware 和RAC相关的知识介绍。
更多的Oracle相关用户手册,可以通过以下的Oracle Help Center URL进行访问:
Oracle Help Center
https://docs.oracle.com/en/database/database.html
另外,学而不思则罔,在学习在线文档的过程中如果仅仅是阅读有时很难理解知识的内容,因此,建议在阅读的过程中还要实践动手进行测试。
白皮书(White Paper)
Oracle白皮书作为一种官方文件,对新推出的一些新功能或者框架,会从底层设计的角度来讲解Oracle的重要功能和新特性,同时还会提供很多可以实践的测试用例以及解释。
是对官方在线产品文档非常好的补充,利于更深入地理解Oracle。
例:应用实践1(In-memory学习)
除了在在线产品文档中对In-Memory 选件进行了关联知识的讲解外,在白皮书中会以专题的形式进一步深入和详细讲解地讲解该功能。
Oracle Database In-Memory
http://www.oracle.com/technetwork/database/in-memory/learnmore/index.html
White Paper: Oracle Database In-Memory JUL 2015
http://www.oracle.com/technetwork/database/in-memory/overview/twp-oracle-database-in-memory-2245633.html
>In-Memory Aggregation (Page:13 )
White Paper: Oracle Database In-Memory: In-Memory Aggregation JAN 2015
http://www.oracle.com/technetwork/database/bi-datawarehousing/inmemory-aggregation-twp-01282015-2412192.pdf
下面我们看一下白皮书中关于另一个In-Memory Aggregation功能使用例子更详细的讲解。
SQL文例:
Select st.region, p.brand, sum( s.sales )
From stores st, products p, sales s
Where st.id = s.store_id
And p.id = s.prod_id
And st.Stype = ‘Outlet’
And p.category = ‘Footwear’
Group by st.region, p.brand
处理流程图:

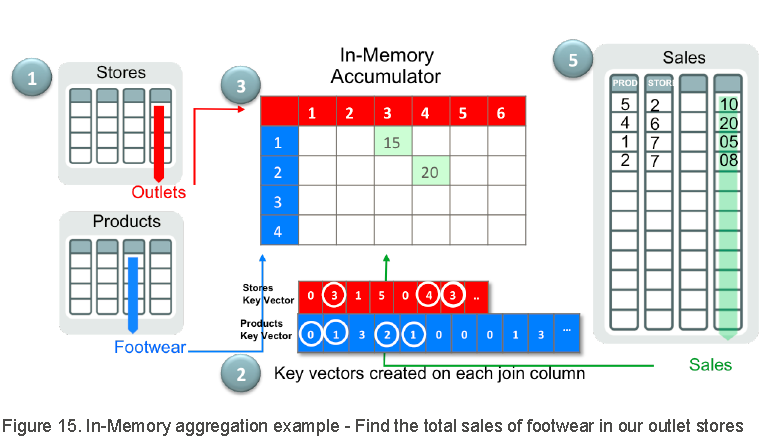
执行计划:
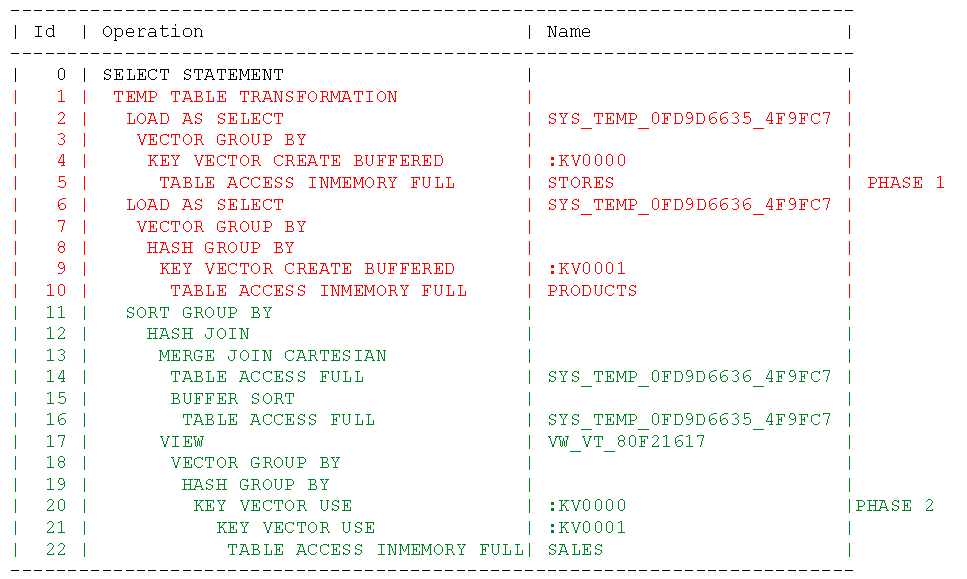
根据上面处理流程和执行计划图所示,我们通过白皮书可以更加直观地了解详细的处理流程:
Phase 1:
1.查询会从扫描2个维度表(小表)stores 和products 开始(例:执行计划的5&10行)。
2.根据维度表的扫描结果,创建称为"KEY VECTOR"的新的数据结构。(例:执行计划的4&9行)
※KEY VECTOR用于【以后的操作中,扫描事实表(大表)时,连接谓词能够作为额外的过滤条件】
3.KEY VECTOR也会被用于去创建称为“IN-MEMORY ACCUMULATOR”的额外结构.
※IN-MEMORY ACCUMULATOR是建在PGA中的一个多维数组,在扫描事实表(大表)过程中通过这个数组进行聚合或者Group by操作。
4.在Phase 1的最后,会创建临时表。
※用于保存Select列表中维度表(小表)的列。
Phase 2:
5.应用之前建立好的KEY VECTOR扫描事实表(大表)。对于事实表中满足连接谓词条件的值(如列s.sales)会被计入到“IN-MEMORY ACCUMULATOR”中 ;如果“IN-MEMORY ACCUMULATOR”的某个CELL中的值存在,则会将累加结果放在该CELL中。
6.最后,事实表的扫描结果会和之前维度表扫描时生成的临时表进行连接,得到最终结果。
通过比较在线产品文档和白皮书两方面的内容,我们可以看到在白皮书会更加系统和详细地介绍相关理论,还会通过图表等更丰富的形式进行介绍,跟有益于我们的理解。
白皮书的列表
对于各个功能更多的Oracle白皮书的列表,可以通过以下的链接进行访问:
白皮书列表:
http://www.oracle.com/technetwork/database/index.html
左侧-选择各类别的功能了解详细
中文版链接(内容有可能不是最新)
http://www.oracle.com/technetwork/cn/indexes/documentation/database-documentation-334768-zhs.html
官方博客Blog
Oracle 有很多官方博客,包括各个组件和团队的Blog,在其中会有很多重要的知识以及最佳实践的介绍。
例:应用实践1(In-memory学习)
例如还是对12c In-Memory Option的学习,除了上面提的在线产品文档(用户手册)和白皮书以外,我们还可以通过内存组件(In-Memory Option)开发团队维护的博客中了解到更多使用的信息,包括开发团队对最新用户反馈的一些回应和最佳实践等。
内存组件(In-Memory Option)开发团队维护的博客:
https://blogs.oracle.com/In-Memory/
例如在该博客中下面的博文,会对用户的常见问题和原理进行解释。
博文选摘:
When to use Oracle Database In-Memory?
How do I identify analytic queries that will benefit from Database In-Memory?
What is an In-Memory Compression Unit (IMCU)?
Questions you asked: What happens if a column is not In-Memory?
Do I really have to drop all of my reporting indexes?
…等等…
其他有用的官方博客
下面是数据库产品相关的几个比较重要的Blog链接地址:
Oracle Blog主页:
https://blogs.oracle.com/
中文技术支持团队的博客:
https://blogs.oracle.com/Database4CN/
优化器(Optimizer )开发团队的博客:
https://blogs.oracle.com/optimizer/
内存组件(In-Memory)开发团队的博客:
https://blogs.oracle.com/In-Memory/
数据仓库和大数据(The Data Warehouse Insider)开发团队的博客:
https://blogs.oracle.com/datawarehousing/
Oracle社区论坛
Oracle社区(Community)论坛提供了用户之间交流平台,用户可以免费地提出自己的问题,分享知识,开展协作。
另外,Oracle也会有一些资深的技术支持工程师定期地去查看相关的一些问题,并作出解答。
例:应用实践1(In-memory学习)
同样是针对In-Memory的学习,我们还可以访问in-memory的子社区论坛,了解其他用户的问题;
以及提出自己的问题,等待其他用户或者Oracle技术支持工程师的回答。
https://community.oracle.com/community/database/oracle-database-options/in-memory
同时也可以通过关键字查询,查找其他子社区中关于In-Memory相关的一些问答和知识:
https://community.oracle.com/search.jspa?q=IN-MEMORY
有用的社区链接
以下是一些有用的社区链接地址,可根据需要选择查看。
技术支持相关的社区列表:
https://community.oracle.com/community/support
数据库相关的社区列表:
https://community.oracle.com/community/database
数据库各个组件相关的社区列表:
https://community.oracle.com/community/database/oracle-database-options
Oracle Magazine
Oracle 官方杂志,更适合作为日常的浏览,可以看到一些热点问题和技术文章
http://www.oracle.com/technetwork/oramag/magazine/home/index.html
其主要包括以下方面的内容:
・FEATURED PODCASTS AND VIDEOS:精选播客和视频
・CURRENT ISSUE:当前的一些热点问题
・BACK ISSUES:过去的一些热点问题
・FEATURED COLUMNS:特色栏目
如DBA相关的栏目、Ask Tom问题的整理集、SQL相关的栏目、认证相关的栏目等
・ORACLE TECHNOLOGY NETWORK ARTICLES:一些技术文章
...等等...
Ask Tom网站
Ask Tom网站是最初由Oracle架构师Tom Kyte维护的回答用户问题的网站,网站中很多问题都和应用程序开发以及SQL有关,当然也包括一些Oracle体系结构的问题。
如果有问题的话可以在上面提出,会由Oracle资深的架构师做出相应的回答。
同时也可以浏览和下载过去结束的问答集合,以丰富自己的学习。
在线学习SQL
Oracle提供了一个在线学习SQL的网站LiveSQL。
通过这个网站你不需要安装任何数据库,就可以访问Oracle数据库,在线练习SQL和查看一些常用的SQL脚本和教程。
例如通过网站上【Code Library–>Types:Tutorials】你就可以看到看到关于SQL、物化视图、序列等的介绍和练习脚本,然后通过【SQL Worksheet】进行执行练习等。。
总结
本文介绍了Oracle官方提供的数据库免费学习资源,并通过学习12c·In-memory 列存储等例子来介绍如何有效地利用这些资源。
版权声明:本文为博主原创文章,转载必须注明出处,本人保留一切相关权力!http://blog.csdn.net/lukeunique
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/141619.html

