
概述
《人人都是产品经理》,诚不我欺,也!!!
前面多篇文章提过我近一年以来几乎是一个人在负责一款数据产品,一款公司内部使用的报表开发工具。市面上的类似产品如Tableau,QuickBI等。工作角色(职责)包括:后端开发,前端开发,功能测试,需求对接(售前支持),用户对接(售后支持,问题排查),产品设计,数据清洗,报表开发等。
那这篇文章就讲讲关于产品设计的杂感,不凭空乱说,会附带讲述几个案例,因此会有大量截图。
案例
登录界面
这个登录功能之前是滑动验证码(早已被AI破解)来验证,因为公司内部使用企业微信昨晚通讯工具,故而考虑把滑动验证码登录校验改为4位(6位也行)随机数字密码(会发送到用户的企微上),相当于是手机短信验证码校验。不同的是,不用接入第三方付费短信平台,而使用免费且次数近乎无限量的企微消息推送功能。关于企微API的消息推送功能,参考企业微信消息推送。
另外,这个改造是另一个后端(职级比我高)和前端协作完成,后面此后端不再参与这个产品,此为背景。
用户类型有2种,99.99%的用户都是域账户,即使用域账号和开机密码完成登录,另外有极少量的用户为普通账户,即需要设置用户名和密码,密码password字段会保存在user表里,域账户不保存(如果保存,准备自己离职吧)。
在做角色及权限验证时,需要用到普通用户。所以登录功能需要支持普通用户在修改密码后依旧可以登录。
问题,或者说是需要优化的地方:
- 前端input组件没有拦截输入数据的长度。都已经约定好验证码是4位数字,则输入框最多只能输入4位数字
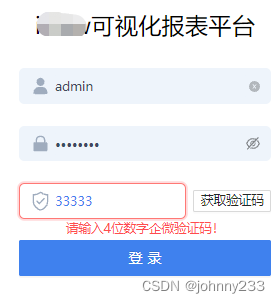

- 对于不存在的用户,不应该报错提示【账号或密码错误,请重新输入!】而应该提示【用户不存在,请联系管理员!】
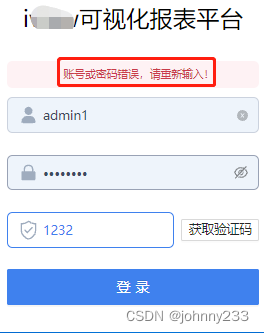
将验证码作为data数据放在responseBody里面,而不用去切换窗口:
cron
平台有如下4种功能:数据推送,数据监控,数据集,看板订阅邮件。其数据来源都是数据源,通过写SQL取数。另外,绝大多数的取数SQL依赖的数据源都是大数据平台(或叫数仓,不做概念上的严格区分),一般会有离线和实时数仓两类。离线一般是T+1,那就意味着数据推送(其他功能也是如此)需要有一个定时执行的概念。当然也有一次性执行后即可废弃的数据推送任务。提到定时任务,必然要涉及cron表达式,需要用户指定一个定时调度时间。
旧版平台是这样一种方式让用户来选择定时调度时间:
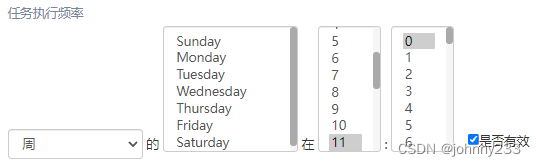
旧版的确实很简单,多个下拉列表,选择多个时间。但是,如果某个任务需要在0点到22点,共23个小时执行,则需要勾选23个选项;对于分钟也是一样,操作过于复杂。私以为这是上一代的产品设计。
于是新版平台,直接给一个输入框,改造如下:

绝大多数情况下,任务是每天执行一次的,如早上8点40分执行,写成:0 40 8 * * ?,简单明了。简洁才是美学。看看乔布斯商业帝国天才们设计的iPhone,iPod等产品,就大概知道什么叫美学吧。iPhone上手比Android难一些?但是大多数人在习惯使用iPhone之后,不会再喜欢Android手机吧。
cron表达式对于不熟悉的人,的确有一点点上手难度。新版这个功能改造之后,前前后后有几个产品或商业分析同事用户反馈:不懂,不会,好难,怎么写,为啥不用旧版那种方式。给TA们一个链接,看过之后,几乎都会写cron表达式。
事实上,上面这个截图的交互设计做得足够人性化。不会写cron?没关系,点击右侧的链接,看看里面的文档,了解6个字符的概念解释,可以在线写cron并验证。
写好cron之后,点击校验按钮。如果cron表达式有误,则弹窗提示:
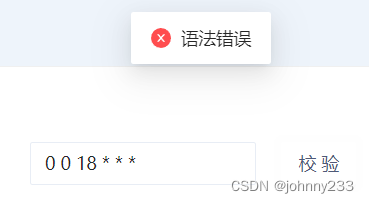
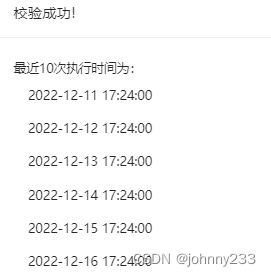
如果cron表达式正确,则弹窗显示最近10次执行时间(截图不完整):
因为疫情居家办公等原因,公司的多个部门发生几次严重的生产事故。于是我们这个平台也要求搞规范那一套流程。因而有产品和前端同事介入。接手的产品又把他心心念念的cron改造(改造的理由,1是产品自己不懂也不想弄懂更不会写cron,2是cron会写错。开玩笑呢??后端有cron表达式校验,不正确的cron表达式,任务无法保存)加入需求开发排期日程里。这个改造需求之前被我挡回去了。
因为这个是纯前端功能,前端同事是个新人(事实上,几乎绝大多数前端都对后端业务不甚关注没有兴趣,只关心后端接口的返回数据,以及数据渲染,交互实现。无关乎技术娴熟程度),接下这个改造需求。
默认情况是这样:

勾选高级模式后,就是之前的版本样式:

也就是说,改造需要实现cron表达式和多个联动下拉框的数据映射。因为第一个下拉框需要支持选择频率,所以这是一个多下拉框联动组件:
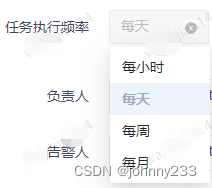
而数据映射的意思是:
- 使用基础模式,选择下拉框后,然后勾选高级模式,数据能正确无误地映射成cron表达式;
- 勾选高级模式,写好正确的cron表达式,回到基础模式,数据可以准确回显到联动下拉框。
这个改造引发的问题至少有4个:
- 页面样式真是要多丑就有多丑,顶部没有对齐,下面凸出:
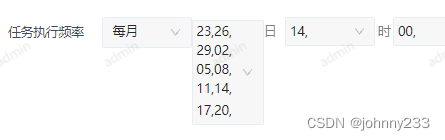
- 基础模式映射到cron有问题
发现这个问题,有两个场景:- 旧版平台的用户反馈TA写的数据集,为啥没有触发自动的定时调度执行。旧版平台使用Quartz定时调度框架。排查下来,选择的调度时间不对,ELK日志平台也能搜索到日志:
java.lang.Throwable: Based on configured schedule, the given trigger 'DEFAULT.3807' will never fire. Job id: 3807;
ERROR org.johnny.services.job.JobService - init cacheDataset error:java.lang.RuntimeException: CronExpression '0 0 5 ? * 0' is invalid.;
- 平台改造迁移,不再使用Quartz,而使用XXL-Job分布点调度平台。那旧版平台的2w多个任务要如何迁移到XXL-Job调度平台呢?总不能手动在XXL-Job管理平台一个个新增任务吧?通过XXL-Job提供的API,写接口批量同步数据上传(新增)到XXL-Job平台。数据主要包括,cron表达式,任务描述,负责人,告警人邮箱等等。接口上线发布后,手动调用接口,发现有几个任务同步失败。也就是说,本想同步1w个任务,然后发现XXL-job调度平台只有9998个任务。接口后续优化:
if (!CronUtil.checkValid(item.getCronExp())) {
logger.warn("initDataset cron checkValid failed for dataset_id=" + item.getId());
continue;
}
对Quartz和XXL-Job感兴趣的读者,请移步我的专栏文章。
3.

排查下来,是前端组件对两个符号/、-的支持问题。

比如现在从每天12时改成

改动不生效。应该还有其他情况
题外话
新入职的前端同学,在收到产品的功能改造需求后,上来就是一顿初生牛犊不怕虎精神,新增若干个文件:git add .,没有提前把整个项目结构和功能过一遍吗?
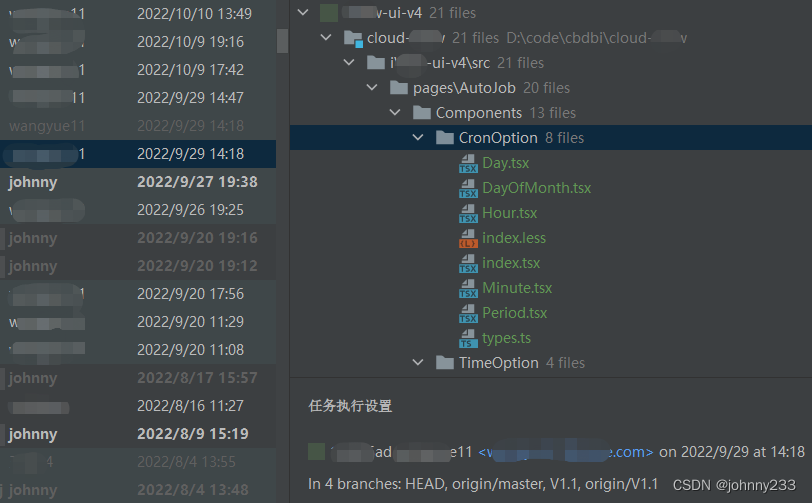
我们的平台产品不止一个功能(前面提到4个功能点)涉及到定时调度,也就是说代码是可以复用的,本来在Dataset目录下面有这些组件的,现在又在Autojob下面新增若干代码,增加项目维护复杂度(辛苦我之前复用若干前端组件和通用代码片段,删除重复的代码片段),Git代码库就是这样腐烂下去的。见如下截图:
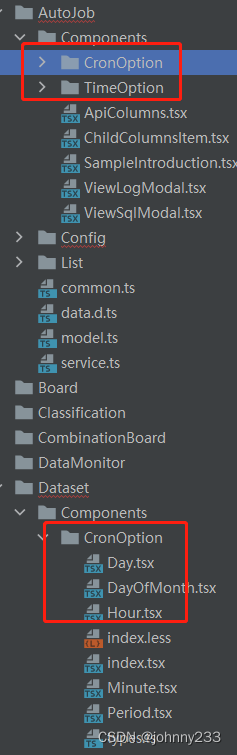
再后来,前端又变更部署方式(本来不是好好的?为啥要改?背景未知),每次部署都需要把dist文件提交到gitlab,这是什么骚操作?
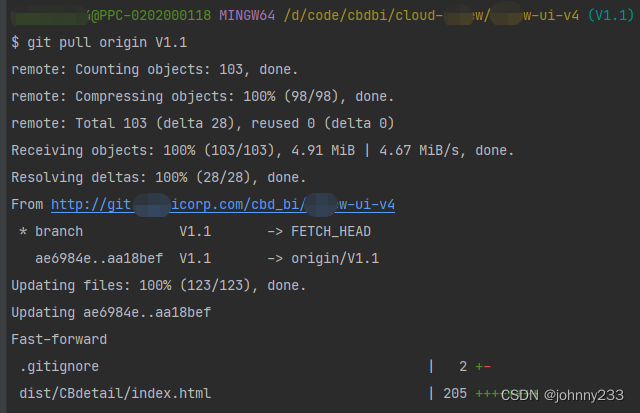
这样下去,Git代码库会越来越臃肿:
还有一个问题,前端项目启动特别慢,耗时10分钟左右才能启动成功,一直以来存在的问题。但是,只要应用启动成功后,不影响git checkout切换分支,可以实现前端代码热更新,几天甚至一两周都不需要重启,反正电脑又不关机。除非是新增依赖的组件,如watermark水印组件,必须要重启应用工程。
更换部署方式,启动慢的问题没有得到解决;增加dist目录后,不能切换分支。切换分支后,只能重新npm启动前端应用。WTF??
监控告警
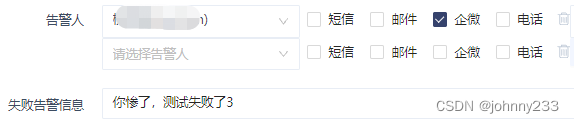
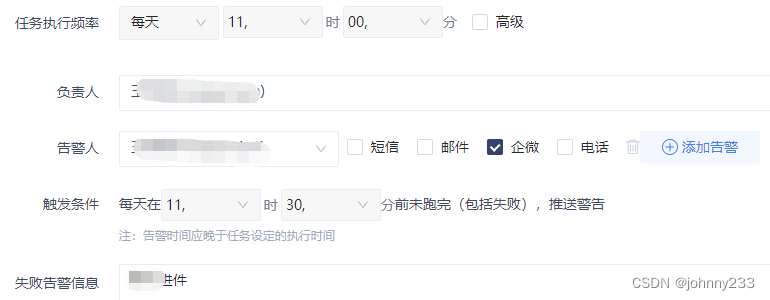
设置一个定时调度时间点执行某个任务,如果执行失败,希望系统可以自动重试。
用户的痛点是:在设置的时间点跑任务,失败,自动重试一次后,成功。则第一次失败时,不要给用户发告警,否则用户需要登录系统,来进行后续操作。
然后产品介入的改造变成这样:
#iview数据推送监控#
预警名称:中国力量挽留弹窗_非小微
预警信息:
预警时间:2022-11-08 09:16:02
数据异常,请及时处理
去向API
产品功能背景如下:用户选择一个数据源,编写SQL,然后去向类型选择API(参考下面的截图),然后设置好定时任务的调度时间,即cron表达式。定时调度平台(XXL-Job)会定时把执行命令下发到任务执行逻辑所在的服务器节点。用户可通过调用平台提供的一个接口(这就是API的命名来源)获取SQL执行结果。为了保证接口响应性能,不可能在调用接口时,才去执行用户提交的几百行包括若干个子句的SQL。定时任务触发执行时,就会把SQL结果存储到MongoDB集群里。选择MongoDB原因无外乎,支持大对象存储,写入和查询性能极高,不像关系型数据库需要提前定义集合(表)结构,入门简单易于维护,可参考博主其他MongoDB相关专栏文章。而MongoDB的集合名字,是根据用户提交的SQL采用hash函数计算出一个唯一UUID。接口调用时,根据UUID去查询MongoDB的某个集合获取数据即可,保证接口的响应性能。另外,用户的SQL变更后,根据SQL内容生成的唯一UUID就会发生变更,此时一定要确保任务执行过一次;否则,就会出现调用接口时,根据最新的SQL去查找MongoDB集合失败,接口返回数据为空的问题。
改版前的用户界面设计如下:
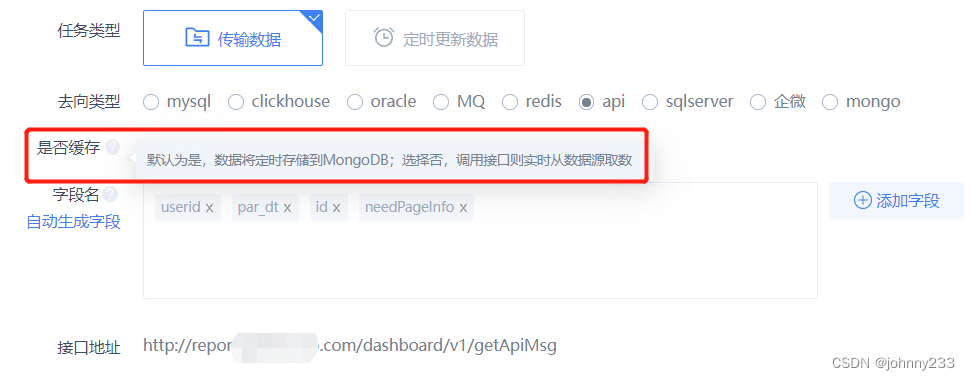
题外话,上面这个截图里面有个是否缓存的单选框,这个需求和设计也是一个【产品】提出来的。本来最开始时是没有这个单选框。默认所有的SQL执行数据都会存储到MongoDB里。事后左思右想,半年多以前的自己为啥要接下这个需求?但是想不到原因。多干活,给老板留下干了事情的印象?完全没有必要啊,事实上本就做了很多事情。这个功能根本就是画蛇添足,多此一举。因为上线半年多,完全没有任何用户选不走缓存这种方式。
比如针对如下一个简单的SQL:
select 111 as userId, 222 as username
程序上,之前既有的逻辑是:根据上面的SQL生成一个唯一UUID,增加一个前缀。前缀名无所谓是啥,比如可以是job_api,那这个SQL对应的执行结果会存储在MongoDB的job_api_f5713c41222558fc25b95762b840adc8集合里面,这个集合的字段除了userId和username之外,默认会追加几个字段,如_id,api_mongo_index,mongoDate等。并且在insert数据到MongoDB时,自动在api_mongo_index字段上面增加递增索引。事实上,MongoDB字段的主键_id字段上面也是有索引的。如果用户在根据任务ID获取存储在MongoDB集群里面的数据时,没有传参数filtering,则利用_id字段上面的索引快速拿到数据。如果接口的requestBody里面还有sort排序字段,则利用_id和api_mongo_index字段上面的索引快速拿到数据。如果接口的requestBody里面还有filtering(比如userId,只想获取某个用户的若干条数据)传参时,则查询时就会根据入参字段(userId)创建索引,第一次查询会比较慢,后面的查询就快了。
然后我们的【产品】设计如下,增加索引设定和出参设定:
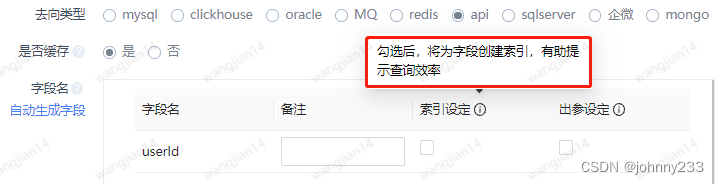
索引设定,见名知义,是想要在MongoDB集合里面增加索引的字段。
而出参设定,则与前置SQL的查询字段息息相关。改造前,用户SQL里面的全部查询字段都会存储到MongoDB集合里;请求接口时,也会把全部字段吐出来。事实上,只要用户稍微具备一些常识,就不会在SQL里面写出select * from table_a这样的查询语句,而是把需要的字段,即请求接口时下游业务方需要的字段一一列出来。
一一列出需要的字段,其优势不言自明:
- 减少SQL执行耗时,减少IO;
- 减少MongoDB集合大小,节省存储空间;
- 减少请求接口时查询MongoDB集合时的耗时,减少IO;
- 减少接口responseBody,减少带宽。
所以,一般情况下,默认用户列出的查询字段就是用户想要的出参设定。在数仓开发中,经常会遇到大宽表,少则20个字段,多则70~80个字段。所以,哪怕是查询字段只有10个,一一勾选出参也是一个苦力活啊。但是呢,我们的项目负责人,产品,前端,后端(不是我,我肯定不会接这样的需求),测试,都没有发现这个改造页面上面需要增加一个全选框。

改造后的程序逻辑是:索引设定可以不勾选,出参设定必须选一个。不勾选索引设定,则接口请求时,即查询MongoDB集合时不走索引,也不走主键索引。
问题:
- 勾选索引设定指定的字段和
filtering传参指定的字段不相同时,走不走索引,会不会自动创建索引? - 接口请求时,
filtering传参指定的字段变更时,走不走索引?
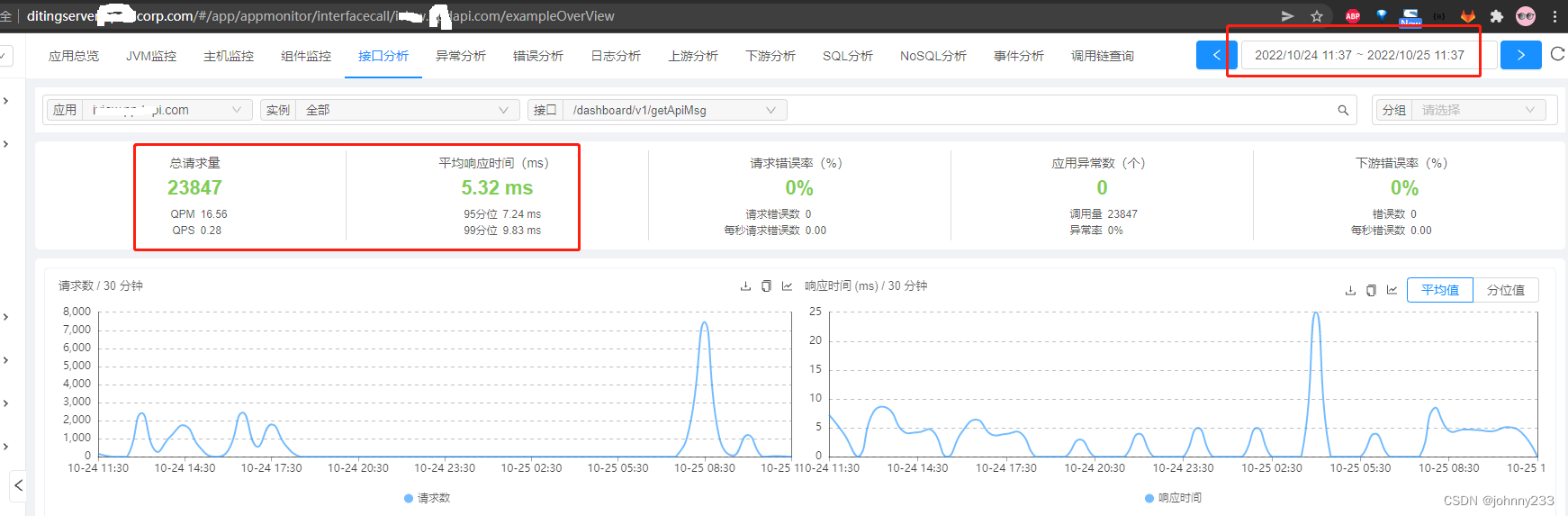
最后放两张截图证明这个改动纯属画蛇添足。改造前的接口响应耗时:
改造后的接口响应耗时:
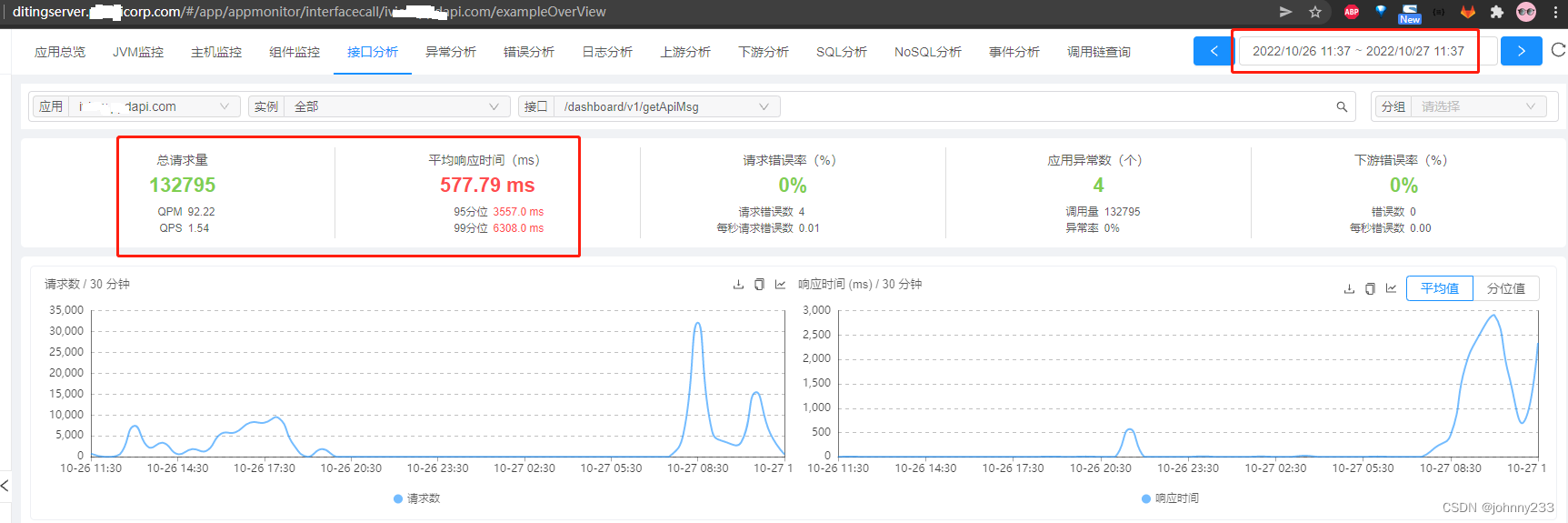
响应变慢100个数量级啊。
需要手动一个个地修改用户的推送任务,选择使用哪些索引。笑死。
总结
小公司风格,小作坊氛围,确实可以塑造一个人全方面的能力。
如果最懂某个产品的人不能决定产品的发展方向,gg了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/142101.html

