
概述
最近在负责一款数据产品,因调试需要,得经常执行impala查询SQL。公司内部维护有一个Hive/Impala查询平台,本来可以使用多账户登录此查询平台:一个是自己的域账户,当然权限非常有限,很多表不可查询;另一个是report账户,相当于管理员账户。这肯定非常不安全,无论是从安全,还是数据资产等维度来讲。
故而,最近该查询平台增加登录验证码功能。即,根据域账户,把随机数字发到域账户对应的企微账户上。这就相当于禁用report账户。
需求
于是给自己这么一个需求,或者叫问题:作为宇宙第一的数据可视化查询工具,DataGrip支持Hive/Impala数据源吗?
解决
Hive
使用的DataGrip 2021.2版本,不算太老。这个原生支持:
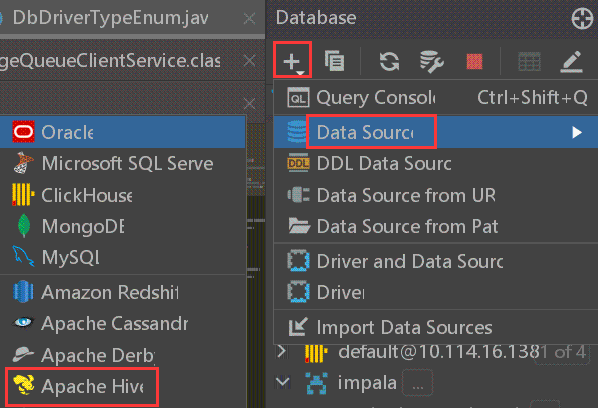
OK,常规的配置用户名,密码,连接串URL,以及驱动信息。因为程序代码里面使用如下hive-jdbc:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1-cdh6.2.1</version>
</dependency>
并且是可以成功连接到该Hive数据源的,故而配置驱动指向本地maven私服仓库:
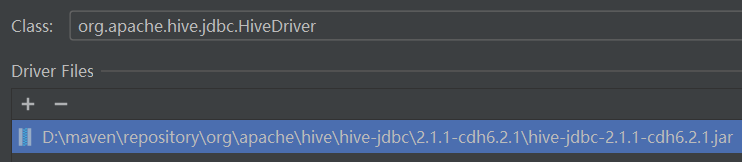
结果报错,报错信息如下:
Driver class 'org.apache.hive.service.rpc.thrift.TCLIService$Iface' not found.
这是为啥??
jar包里面没有这个类!!
通过jd-gui应用程序查看jar文件,确实没有此类。说明这个jar通过程序JDBC方式连接Hive数据源可以,但是通过DataGrip方式不行。
于是,考虑尝试使用DataGrip自带的自动下载驱动的功能,下载的驱动全都在此路径下面,C:\Users\awesome_me\AppData\Roaming\JetBrains\DataGrip2021.2\jdbc-drivers,至于我们现在配置的是hive数据源,故而具体路径是C:\Users\awesome_me\AppData\Roaming\JetBrains\DataGrip2021.2\jdbc-drivers\Hive\3.1.2。
点击Test Connection,结果报错,详细的报错信息:
[ 08S01] Could not open client transport with JDBC Uri: jdbc:hive2://111.222.333.444:10000/edw: Could not establish connection to jdbc:hive2://111.222.333.444:10000/edw: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size=1000, use:database=edw})
org.apache.hive.org.apache.thrift.TApplicationException: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size=1000, use:database=edw}).
参考:required-field-client-protocol-is-unset,意思是连接的Hive数据源版本太低,而我们使用的驱动版本太高。
解决方法只能是降低驱动版本,如果不知道数据源的Server版本,则需要联系数仓同事获取版本,或者一个个版本尝试。major.minor.fix,即 主版本号.次版本号.修订版本号,先尝试主版本号,其次是次版本号。
于是下载跟hive server版本适配的驱动,从maven:hive-jdbc下载即可:
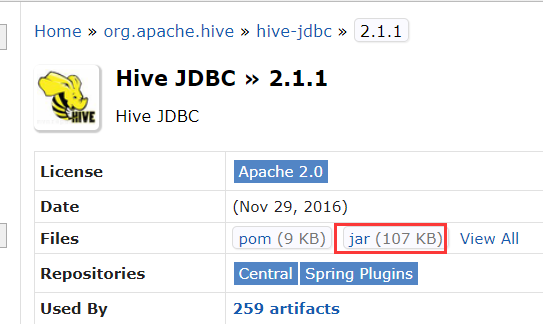
还是不对??报错信息依旧是:
Driver class 'org.apache.hive.service.rpc.thrift.TCLIService$Iface' not found.
等等,仔细看,发现DataGrip下载的文件,上面给出目录,是hive-jdbc-3.1.2-standalone.jar,带有standalone,并且文件非常大,将近70M。意思是这个jar里面有Hadoop或者Hive依赖的其他组件。
OK,那我们也去下载standalone文件。
在上面的截图,我们看到有个View All:

点进去,可以找到standalone文件的下载地址。
于是下载得到hive-jdbc-2.1.1-standalone.jar文件,更新驱动jar包,再次尝试,结果还是失败,详细的报错信息如下:
Driver class 'org.apache.hadoop.conf.Configuration' not found.
什么鬼???连个数据源而已!!!
几番折腾,才想到在Maven配置hive版本号里面,使用的CDH分发包Hadoop集群,得去这个里面找驱动包的下载地址:

即cloudera-hive
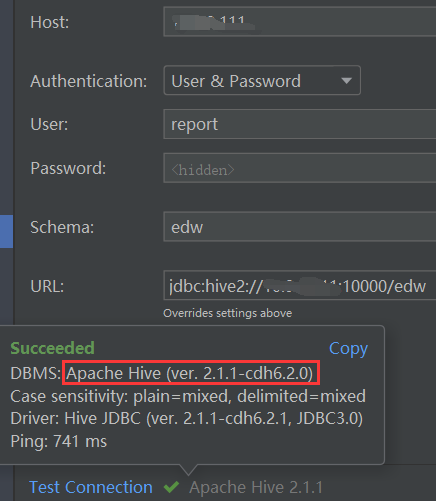
终于成功!!!
结论
前面多是废话,很多折腾和尝试。总结起来需要满足3点:
- 版本号,与Server端的版本号适配,至少相差不能太大;
- 需要使用
standalone文件; - 需要根据Server端,即集群的分发方式来选择,一般都是CDH。
Impala
DataGrip虽然不原生支持连接Impala数据源,但简单调研,参考文章Impala可视化工具DataGrip,就知道可通过如下方式实现连接。
首先,需要创建一个Driver:
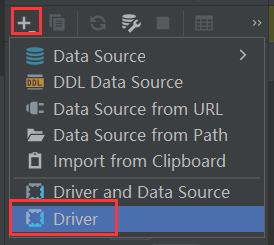
Impala JDBC驱动下载地址,添加此文件,DataGrip会自动扫码此jar包里面的所有继承官方JDBC驱动,即java.sql.Driver的类,然后从右侧的下拉列表选择com.cloudera.impala.jdbc41.Driver。
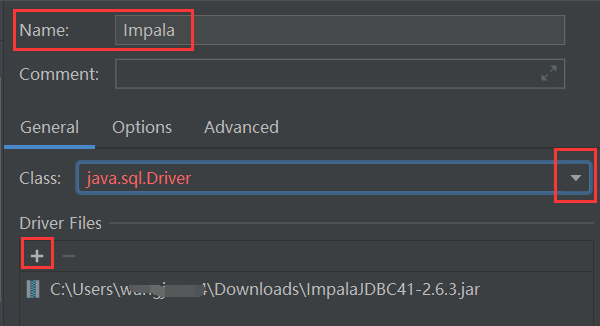
然后,就可以像添加其他数据源一样添加Impala数据源。
上面提到的参考文章说,URL的格式为:jdbc:impala://197.255.20.215:21050/,端口我21050。
但是很不幸,连接失败,报错信息如下:
[HY000][500164] [Cloudera][ImpalaJDBCDriver](500164) Error initialized or created transport for authentication: java.net.ConnectException: Connection timed out: connect.
[Cloudera][ImpalaJDBCDriver](500164) Error initialized or created transport for authentication: java.net.ConnectException: Connection timed out: connect.
报错信息跟认证和超时相关。说明这个驱动jar程序是没有问题的。但是这个报错咋解决?
网上也找不到可行的解决方案。
https://community.cloudera.com/t5/Support-Questions/Proper-jdbc-connection-string-to-connect-to-impala-with/m-p/42261
转而想到,impala本质上还是hive,那为何不考虑通过hive的方式连接Impala数据源呢?
需要注意的是,hive的端口是10000,impala的端口是25005。
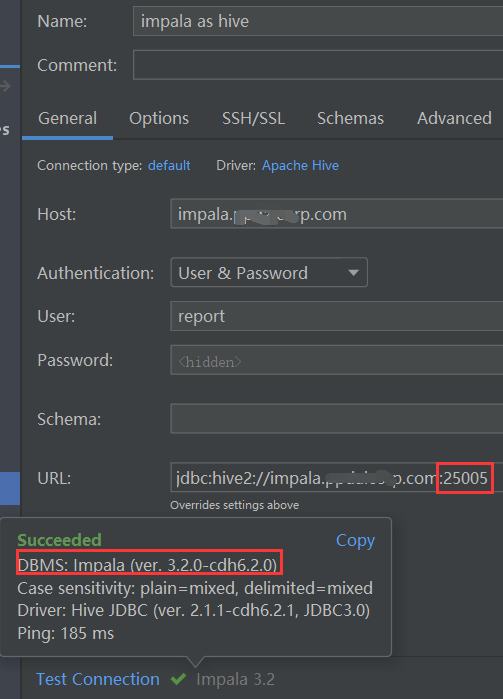
参考
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/142141.html

