
背景
最近在负责的一款数据产品,其功能之一为数据推送,即把数据从源头数据源同步到目标数据源。
功能大致如下,SQL语句块需要支持多段SQL,以英文逗号;分隔:

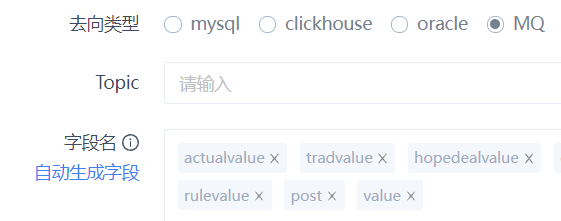
问题
自测时发现一个问题。对于select 11 as userid或select 22 as user_id这样的查询语句,自动生成字段,没有问题。但如果是select 22 as userId这种驼峰命名的SQL,自动生成字段,会全部变成小写。
这样会有什么问题呢?如果数据是推送到Oracle,Oracle的字段名(以及表名)是全部大写可带下划线,能够兼容数据源头小写。
但是如果数据是推送到MQ时,MQ消费方则需要严格匹配JSON字符串里面的字段名。也就是说,MQ消费方如果能够接受全部小写或者下划线命名的字段,则没有问题。如果希望消费驼峰命名的数据,则此时的自动生成字段派不上用场。
分析
先来看看根据SQL语句获取解析字段的代码片段:
public List<String> getSqlColumn(String sql) throws Exception {
if (StringUtils.isBlank(sql)) {
return Collections.emptyList();
}
List<String> list = new ArrayList<>();
Connection con = null;
Statement ps = null;
ResultSet rs = null;
try {
JSONObject dataSourceJson = JSONObject.parseObject(JSONObject.toJSONString(dataSource));
// dataSource是一个Map<String, String>,存放username,password,url,driver等信息
con = JdbcUtil.getConnection(dataSourceJson);
ps = con.createStatement();
String[] sqlArr = getAsSubQuery(sql).split(";");
// 先执行前面若干条准备语句
for (int y = 0; y < sqlArr.length - 1; y++) {
String subSql = getAsSubQuery(sqlArr[y]);
// 前面的执行不需要获取结果集
ps.execute(subSql);
}
// 执行最后一条子SQL获取字段(结果集)
// 即将废弃
rs = ps.executeQuery(sqlArr[sqlArr.length - 1]);
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();
if (columnCount != 0) {
list = new ArrayList<>();
for (int j = 0; j < columnCount; j++) {
String cname = metaData.getColumnLabel(j + 1);
list.add(j, cname);
}
}
// 即将废弃
} catch (Exception e) {
throw new Exception("getSqlColumn error:" + e);
} finally {
if (rs != null) {
rs.close();
}
if (ps != null) {
ps.close();
}
if (con != null) {
con.close();
}
}
return list;
}
/**
* 替换多余的空格,回车,换行符,去掉末尾的最后一个分号
*/
private String getAsSubQuery(String rawQueryText) {
String deletedBlankLine = rawQueryText.replaceAll("(?m)^[\\s\t]*\r?\n", "").trim();
return deletedBlankLine.endsWith(";") ? deletedBlankLine.substring(0, deletedBlankLine.length() - 1) : deletedBlankLine;
}
private String getDbType(String driver) {
if (StringUtils.isNotBlank(driver)) {
return DbDriverTypeEnum.getNameByDbDriverType(driver).equals("impala") ? "hive" : DbDriverTypeEnum.getNameByDbDriverType(driver);
}
return "";
}
平平常常的一段代码,从结果集里,获取查询子SQL(最后一条SQL)的字段。
问题就出在这里:metaData.getColumnLabel();,JDBC提供的API,此处拿到的数据就是纯小写,注意索引从1开始。
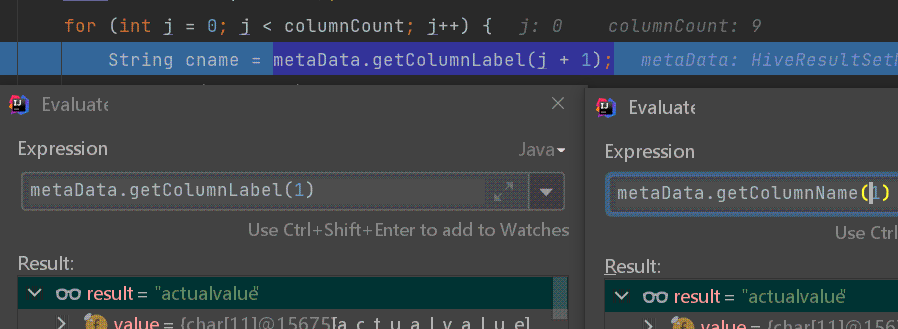
因为metaData.getColumnLabel()拿到的数据有问题,只能去看看API,源码,通过调试一个个尝试。发现都不行。
此处就引出有个疑问。metaData.getColumnLabel()和metaData.getColumnName()有啥区别?为什么JDBC规范需要提供两个API方法?
参考下面给出的stackoverflow问答链接。在有别名的情况下,即,使用as或者AS,当然这个关键词可以去掉,metaData.getColumnLabel()会返回别名字段,metaData.getColumnName()返回原始字段。
只不过,这个只是JDBC官方规范,各个不同的数据源驱动,更涉及到不同版本,其实现并没有严格遵守这个规范。上面的截图说明这个问题。注:使用的hive jdbc驱动版本为:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1-cdh6.2.1</version>
</dependency>
MySQL如下驱动版本,严格实现该JDBC规范,没有转为小写的问题:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
解决
思路1
既然JDBC这个方式行不通,那就需要自己手写SQL解析器,解析涉及到的数据表,查询字段等等。但这远远不是一个简单的工作量。故而我们需要开源组件。之前关于这个做过简单的调研。
参考SQL解析调研
将上面的代码片段中执行最后一条子SQL的逻辑替换为如下片段:
List<String> columns = SqlUtil.getSelectColumns(sqlArr[sqlArr.length - 1], this.getDbType(dataSource.get("driver")));
for (int j = 0; j < columns.size(); j++) {
list.add(j, columns.get(j));
}
思路2
推荐使用上面的解决方案。从数据源头就拿到正确的数据。
至于思路2,就目前而且,去向数据源,我们支持几个主流的支持JDBC规范的关系型数据库,如MySQL,SQL Server,Oracle,MongoDB以及ClickHouse,不存在因为驼峰命名自动生成字段,变成小写命名后,导致数据推送到目标数据源失败的情况,至少暂未发现。
但是MQ比较特殊,故而,思路2就是在MQ消费方这一端来解决这个问题。支持手动输入多个字段,多个字段之间使用英文逗号分割:


这里注意分号,分号前面几位数据源查询SQL的结果集字段,分号后面为期望的MQ字段,然后代码里面特殊处理一下:
// dataList是一个list of map,即SQL的查询结果
for (Map<String, Object> map : dataList) {
JSONObject mq = new JSONObject();
// columnArr是自动生成或者手动输入的字段,也就是希望推到目标数据源的那些字段,是源头数据源查询SQL里面的查询字段的子集.另外,手动添加字段没有限制,但是没有取数来源,故而不会推到目标数据源,或者及时推送也是null或者空
for (String s : columnArr) {
// 此处不管有没有分号,都会解析到字段
String dbKey = s.split(":")[0];
String mqKey = "";
if (s.contains(":")) {
mqKey = s.split(":")[1];
}
if (StringUtils.isBlank(mqKey)) {
mq.put(dbKey, map.get(dbKey));
} else {
// 如果有分号,则往分号后面的那个字段落数据
mq.put(mqKey, map.get(dbKey));
}
}
}
参考
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/142142.html

