
简介
Redis是一个开源的使用ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型的Key-Value存储,也是一个数据结构存储,可用作数据库、缓存和消息中间件,并提供多种语言的 API。支持多种类型的数据结构,除String、List、Hash、Set、Sorted Set范围查询、Bitmaps、Hyperloglogs 和地理空间(Geospatial)索引半径查询。Redis 内置复制(Replication)、LUA 脚本(Lua scripting)、LRU 驱动事件(LRU Eviction)、事务(Transactions)和不同级别的磁盘持久化(Persistence)如RDB与AOF,并通过 Redis 哨兵(Sentinel)和自动分区(Cluster)提供高可用性(HA),也支持发布/订阅,可实现分布式锁,其他特性:
- 单线程,避免线程切换和锁的性能消耗
- 原子操作
- 主从复制与高可用(Redis Sentinel)
- 集群(3.0版本以上)
对比
经常被面试官问,Redis和memcache的区别?真的是,有啥好问的,作为后起之秀,Redis完爆啊。
参考Redis系列之Ehcache、memcache、Redis对比
安装
按照系统区分,有Windows、Linux、Mac等;
按照模式区分,有单机、Master/Salve、Redis Sentinel、切片等。
具体参考Redis安装备忘录
数据类型
有基础和高级
基础
String
等同于一个可持久化的Memcached服务器。
常用命令:set,get,decr,incr,mget 等。
实现方式:String 在 redis 内部存储默认就是一个字符串,被 redisObject 所引用,当遇到 incr,decr 等操作时会转成数值型进行计算,此时 redisObject 的 encoding 字段为int。
散列hash
Hash是一个String类型的field/key和value之间的映射表,主要用来存储对象,可以避免序列化的开销和并发修改控制的问题。
常用命令:hget,hset,hgetall 等。
列表list
List是基于双向链表实现的,可以支持反向查找和遍历。
常用命令:lpush,rpush,lpop,rpop,lrange等。
实现方式:
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,带来部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
常用案例:聊天系统、社交网络中获取用户最新发表的帖子、简单的消息队列、新闻的分页列表、博客的评论系统。
集合Set
与list类似,但不重复的列表,Set提供判断某个成员是否在一个Set集合内的接口。
常用命令:sadd,spop,smembers,sunion 等。
实现方式:
set 的内部实现是一个 value 永远为 null 的 HashMap,实际就是通过计算 hash 的方式来快速排重的,这也是 set 能提供判断一个成员是否在集合内的原因。
有序集合zset
Sorted Set和Set类似,区别是Sorted Set会根据提供的score参数来进行自动排序(即插入有序)。用于需要一个有序的并且不重复的集合列表的场景。
常用命令:zadd,zrange,zrem,zcard等。
实现方式:
sorted set 的内部使用 HashMap 和SkipList来保证数据的存储和有序,HashMap 里放的是成员到 score 的映射,SkipList里存放的是所有的成员,排序依据是 HashMap 里存的 score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
常用案例:游戏中的排行榜。
高级数据类型
命令行
set
官方完整命令行:SET key value [EX seconds] [PX milliseconds] [NX|XX]
一般使用:set key value,或者SETEX key seconds value;一个命令行一般具有原子性,多条则不尽然。通过SET命令实现分布式锁:SET key value EX seconds NX(EX和PX任选,取决于对过期时间精度要求)。value也有要求,最好是一个类似UUID这种具备唯一性的字符串。其他实现分布式锁的方案如redlock。
keys
时间复杂度是O(N),而redis又是单线程执行,在执行keys时即使是时间复杂度只有O(1),如SET或者GET这种简单命令也会堵塞,从而导致这个时间点性能抖动,甚至可能出现timeout。即所谓性能毛刺。
强烈建议生产环境屏蔽keys命令。
scan
keys代替方案scan。如果把keys命令比作类似select * from users where username like '%afei%'这种SQL,那么scan应该是select * from users where id>? limit 10这种命令。
SCAN cursor [MATCH pattern] [COUNT count]
初始执行scan命令例如scan 0。SCAN命令是一个基于游标的迭代器。这意味着命令每次被调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。当SCAN命令的游标参数被设置为0时,服务器将开始一次新的迭代,而当redis服务器向用户返回值为0的游标时,表示迭代已结束,这是唯一迭代结束的判定方式,而不能通过返回结果集是否为空判断迭代结束。
scan 0返回结果分为两个部分:第一部分即1)就是下一次迭代游标,第二部分即2)就是本次迭代结果集。
slowlog
查看慢日志:SLOWLOG subcommand [argument]
sub-command:
- get,
slowlog get [argument],获取argument参数指定数量的慢日志。返回信息包括时间戳,执行时间和执行命令; - len,
slowlog len,总慢日志数量。 - reset,
slowlog reset,清空慢日志。
命令config set slowlog-log-slower-than 2000配置命令耗时超过多少才会保存到slowlog中,不需要重启redis。单位是微妙。
monitor
用法如下:redis-cli -p 6380 monitor
如果当前redis环境OPS比较高,那么建议结合linux管道命令优化,只输出keys命令的执行情况:
redis-cli -p 6380 monitor | grep keys
1532645287.257657 [0 10.0.0.1:43544] “keyss” “44*”
执行结果中很清楚的看到keys命名执行来源。通过输出的IP和端口信息,就能在目标服务器上找到执行这条命令的进程。
info
全面反映当前redis运行情况,INFO [section]
section可选值有:
- server: 运行的redis实例信息:redis版本,操作系统信息,端口,GCC版本,配置文件路径等;
- clients: redis客户端信息:已连接客户端数量,阻塞客户端数量等;
- memory: 使用内存,峰值内存,内存碎片率,内存分配方式;
- persistence: AOF和RDB持久化信息;
- stats: 一些统计信息,最重要三个参数:OPS(instantaneous_ops_per_sec),keyspace_hits和keyspace_misses两个参数反应缓存命中率;
- replication: redis集群信息;
- CPU: CPU相关信息;
- keyspace: redis中各个DB里key的信息;
rename-command
通过配置文件重命名一些危险命令减少生产事故:
rename-command flushdb flushddbb
rename-command flushall flushallall
rename-command keys keysys
bigkeys
bigkeys用于检查生产环境上一些有问题的数据:redis-cli -p 6380 --bigkeys
返回键空间keyspace里面的keys的总数,长度,占用空间最大的String/list/set/hash/zset等类型的key名称。
bigkeys通过scan命令遍历各种不同数据结构的key,分别通过不同的命令得到最大的key:string结构,通过strlen判断;list结构,通过llen判断;hash结构,通过hlen判断;set结构,通过scard判断;sorted set结构,通过zcard判断。
故而这个bigkeys得到的最大,不一定是最大。对于String结构没有问题,可以正确筛选出最占用缓存,即最大的key。但是list不一定,llen可以理解为list.size(),但是size最大,占用空间不一定大,还和元素类型和大小有关系。其他三种数据结构hash,set,sorted set都会存在这个问题。
config
生产环境一般是不允许随意重启的,不能因为需要调优一些参数就修改conf配置文件并重启。通过config命令能热修改一些配置,不需要重启redis实例,可以通过如下命令查看哪些参数可以热修改:config get *,热修改:config set,例如:config set slowlog-max-len 100; config set maxclients 1024。值得注意的是,这种修改方式并没有持久化到配置文件中去;config rewrite即可实现持久化修改到配置文件。执行该命令后,就能在config文件中看到类似这种信息。如果conf中本来就有这个参数,通过执行config set,那么redis直接原地修改配置文件:maxclients 1024。如果conf中没有这个参数,通过执行config set,那么redis会追加在Generated by CONFIG REWRITE字样后面:
# Generated by CONFIG REWRITE
save 600 60
slowlog-max-len 100
持久化
过期淘汰机制
模糊匹配查询
内存碎片
应用场景
分布式锁
乐观锁
乐观锁在数据竞争概率比较小的情况下会带来比较大的性能提升。memcached中有CAS命令,用来实现check-and-set这样功能。Redis中可以基于Multi/EXEC/WATCH操作来实现类似的功能。
管道
Redis管道是指客户端可以将多个命令一次性发送到服务器,由服务器一次性返回所有结果。管道技术在批量执行命令的时候可以大大减少网络传输的开销,提高性能。前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
事务
Redis事务是一组命令的集合。一个事务中的命令要么都执行,要么都不执行。如果命令在运行期间出现错误,不会自动回滚。事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
指令:MULTI、EXEC、DISCARD、WATCH
管道与事务的区别:管道主要是网络上的优化,客户端缓冲一组命令,一次性发送到服务器端执行,但是并不能保证命令是在同一个事务里面执行;而事务是原子性的,可以确保命令执行的时候不会有来自其他客户端的命令插入到命令序列中。
使用规范
Key命名规范
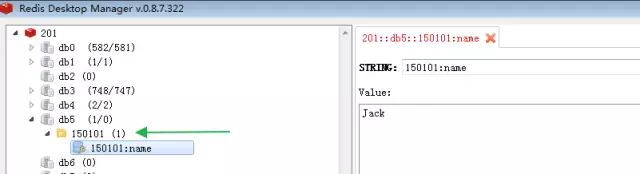
Redis Key命名规范:AppID:KeyName。建议使用冒号作为AppID和KeyName的分隔符,其原因是:这么写会使Redis Key会以AppID作为分类显示在Redis Desktop Manager中,方便定位和检查Key-Value:

池化
连接的频繁创建和销毁,会浪费大量的系统资源,极限情况会造成宿主机当机。使用Redis 客户端连接池争取配置连接数。
大小限制
由于 Redis 是单线程服务,消息过大会阻塞并拖慢其他操作。保持消息内容在 1KB 以下是个好的习惯。严禁超过 50KB 的单条记录。消息过大还会引起网络带宽的高占用,持久化到磁盘时的 IO 问题。
禁用部分命令
通过rename的方式禁用这些命令。
Flush
flush 命令会清空所有数据,属于高危操作。
keys
Keys 命令效率极低,属于 O(N)操作,会阻塞其他正常命令,在 cluster 上,会是灾难性的操作。
严禁作为消息队列使用
如没有非常特殊的需求,严禁将 Redis 当作消息队列使用。Redis 当作消息队列使用,会有容量、网络、效率、功能方面的多种问题。如需要消息队列,可使用高吞吐的 Kafka 或者高可靠的 RocketMQ。
集群搭建
Redis集群搭建,比较成熟的可选方案包括:
twemproxy
Twitter开源。
codis
目前用的最多的集群方案,基本和twemproxy一致的效果,支持在节点数量改变情况下,旧节点数据可恢复到新hash节点。
redis cluster3.0
自带的集群,特点在于他的分布式算法不是一致性hash,而是hash槽的概念,以及自身支持节点设置从节点。
业务代码层
自己实现,起几个毫无关联的redis实例,在代码层,对key 进行hash计算,然后去对应的redis实例操作数据。 这种方式对hash层代码要求比较高,考虑部分包括,节点失效后的替代算法方案,数据震荡后的自动脚本恢复,实例的监控,等等。
Redis客户端工具
RDM
Redis Desktop Manager,
Jedis
Jedis是Redis的Java实现的客户端,其API提供比较全面的Redis命令的支持;Jedis中的方法调用是比较底层的暴露的Redis的API。Jedis仅支持基本的数据类型如:String、Hash、List、Set、Sorted Set。
Jedis使用阻塞的I/O,其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
redisson
Redisson是一个高级的分布式协调Redis客服端,能帮助用户在分布式环境中轻松实现一些Java的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
相比较于Jedis,Redisson中的方法则是进行比较高的抽象,每个方法调用可能进行一个或多个Redis方法调用。实现分布式和可扩展的Java数据结构,和Jedis相比,功能较为复杂,不仅支持字符串操作,且还支持排序、事务、管道、分区等Redis特性。
Redisson使用非阻塞的I/O和基于Netty框架的事件驱动的通信层,其方法调用是异步的。Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作。
Redisson提供一系列的分布式Java常用对象,基本可以与Java的基本数据结构通用,还提供许多分布式服务,包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service)。
在分布式开发中,Redisson可提供更便捷的方法。
Redisson提供和Spring框架的各项特性类似的,以Spring XML的命名空间的方式配置RedissonClient实例和它所支持的所有对象和服务;
Redisson完整的实现Spring框架里的缓存机制;
Redisson在Redis的基础上实现Java缓存标准规范;
Redisson为Apache Tomcat集群提供基于Redis的非黏性会话管理功能,支持Tomcat的6、7和8版。
Redisson还提供Spring Session会话管理器的实现。
Spring Data Redis
Lettuce
对比
| 名 | 优点 | 缺点 |
|---|---|---|
| Jedis | 简单,提供比较全面的Redis命令的支持 | – |
| Spring Data Redis | Spring提供,便于集成Spring项目 | – |
| Redisson | 对业务松耦合 | 不支持字符串操作,不支持排序、事务、管道、分区等Redis特性? |
监控
常见应用问题
- 缓存穿透:当根据Redis key在缓存中查询后,不存在对应Value,就应该会在后端系统如DB中去查找,该Key的并发请求量一旦变大,那么就会对DB造成很大的压力。解决办法有:a.前端风险控制,将恶意穿透情况排除在外;b.对查询结果为空的情况依然进行缓存,但缓存时间会设置得很短,一般是几分钟。
- 缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。解决办法有:后端连接数限制,错误阈值限制,超时处理,缓存失效时间均匀分布,前端永不失效及后端主动更新。
- 缓存时长:策略定位复杂,需要多维度的计算。
- 缓存失效:按时失效,事件失效,后端主动更新。
- 缓存Key:Hash、规则、前缀+Hash,异常情况可人工干预。
- Lua脚本:服务端批量处理及事务能力,有条件逻辑的可扩展脚本。使用它的好处有:减少网络开销、原子操作、可复用。
- Limit:可滑动时间窗口,如应用于Session,Memcached需每次传Key和Value。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/142397.html

