
1、feapder库安装
pip install feapder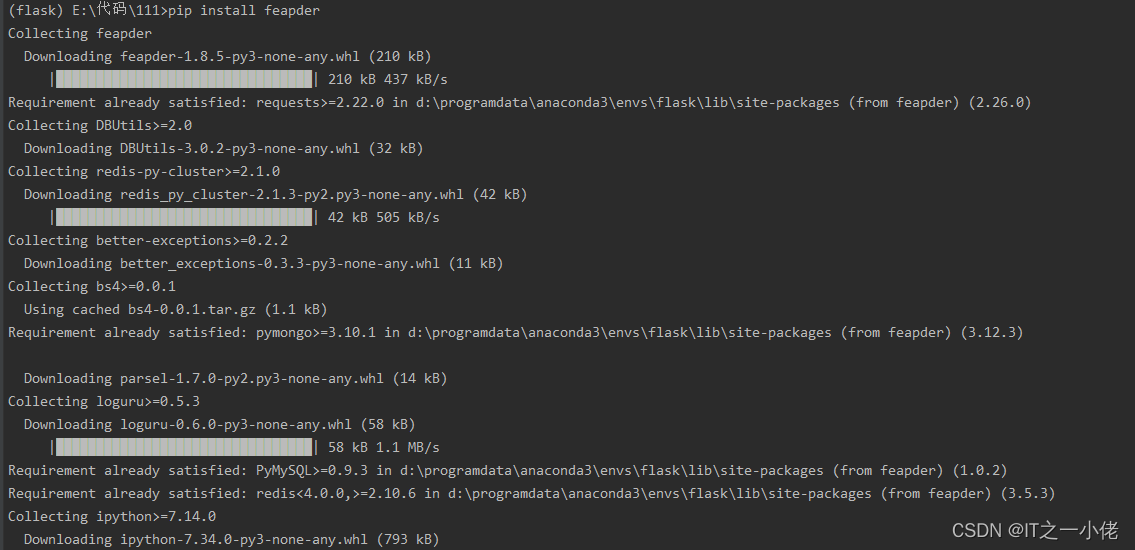

2、创建爬虫
- AirSpider 轻量爬虫:学习成本低,可快速上手
- Spider 分布式爬虫:支持断点续爬、爬虫报警、数据自动入库等功能
- BatchSpider 批次爬虫:可周期性的采集数据,自动将数据按照指定的采集周期划分。(如每7天全量更新一次商品销量的需求)
feapder对外暴露的接口类似scrapy,可由scrapy快速迁移过来。支持断点续爬、数据防丢、监控报警、浏览器渲染下载、海量数据去重等功能
feapder create -s first_spider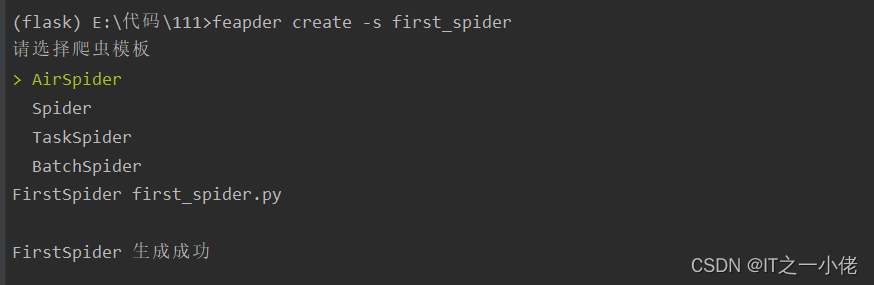
自动生成first_spider.py文件:
# -*- coding: utf-8 -*-
"""
Created on 2023-03-04 16:52:05
---------
@summary:
---------
@author: 86187
"""
import feapder
class FirstSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://spidertools.cn")
def parse(self, request, response):
# 提取网站title
print(response.xpath("//title/text()").extract_first())
# 提取网站描述
print(response.xpath("//meta[@name='description']/@content").extract_first())
print("网站地址: ", response.url)
if __name__ == "__main__":
FirstSpider().start()代码解释:
- start_requests:生产任务
- parse:解析数据
运行程序,结果如下:
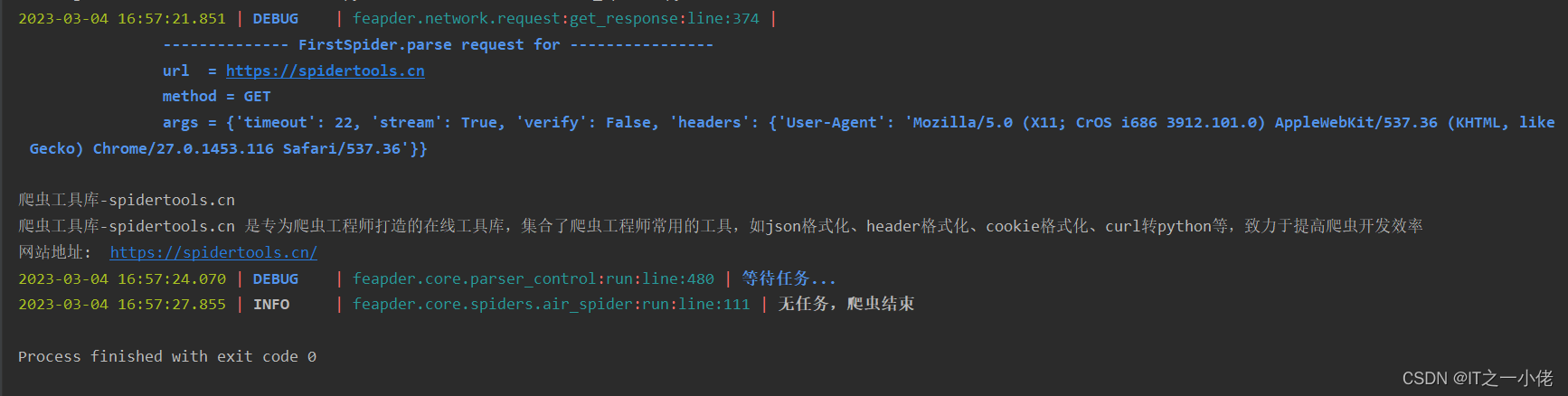
3、示例操作
以书山有路网某个网页为例,获取书籍的一些信息:
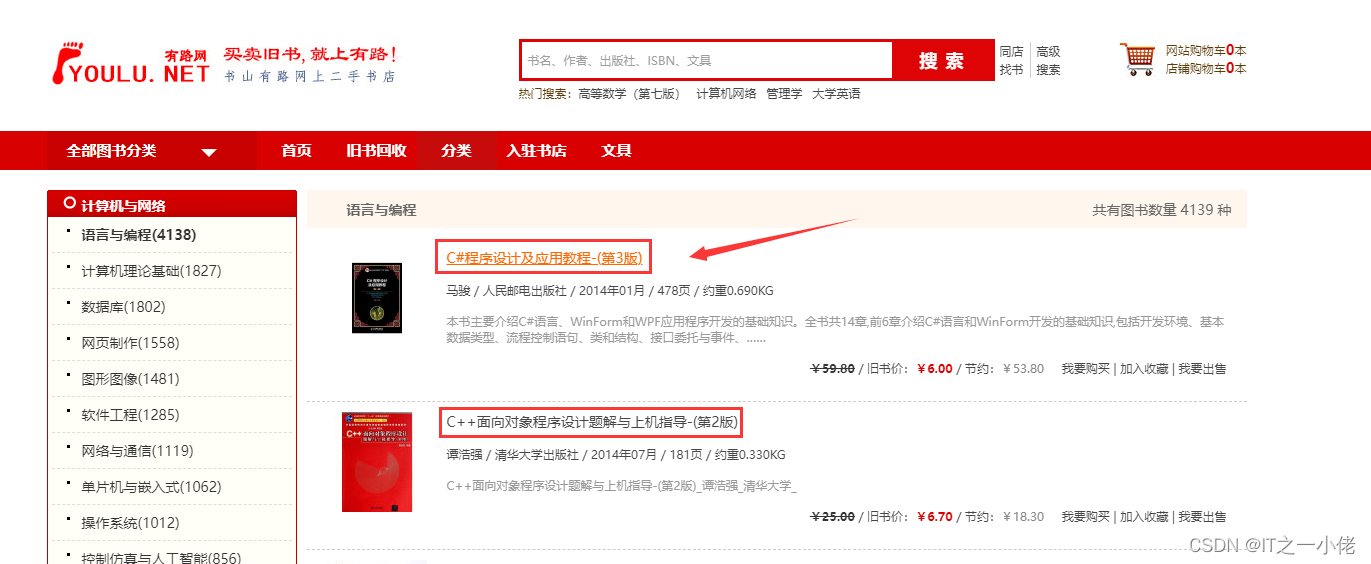
3.1 创建爬虫
create -s get_books_detail_spider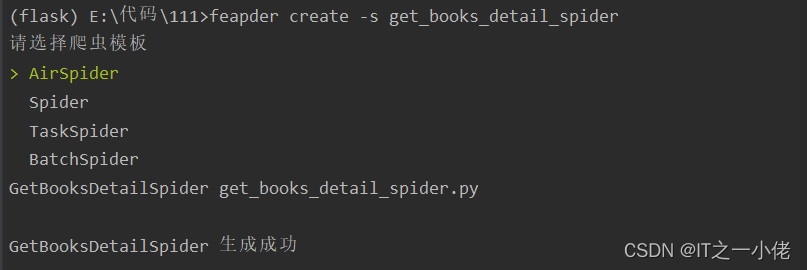
3.2 修改生成的代码
下发任务:下发1~10页列表任务:
def start_requests(self):
for i in range(1, 10):
if i == 1:
yield feapder.Request("https://www.youlu.net/classify/2-0101-4138-1.html")
else:
yield feapder.Request(f"https://www.youlu.net/classify/2-0101-4139-{i}.html")解析爬取的内容:
def parse(self, request, response):
# 提取网站title
print(response.xpath("/html/head/title/text()").extract_first())
# 提取网站所有书籍名称
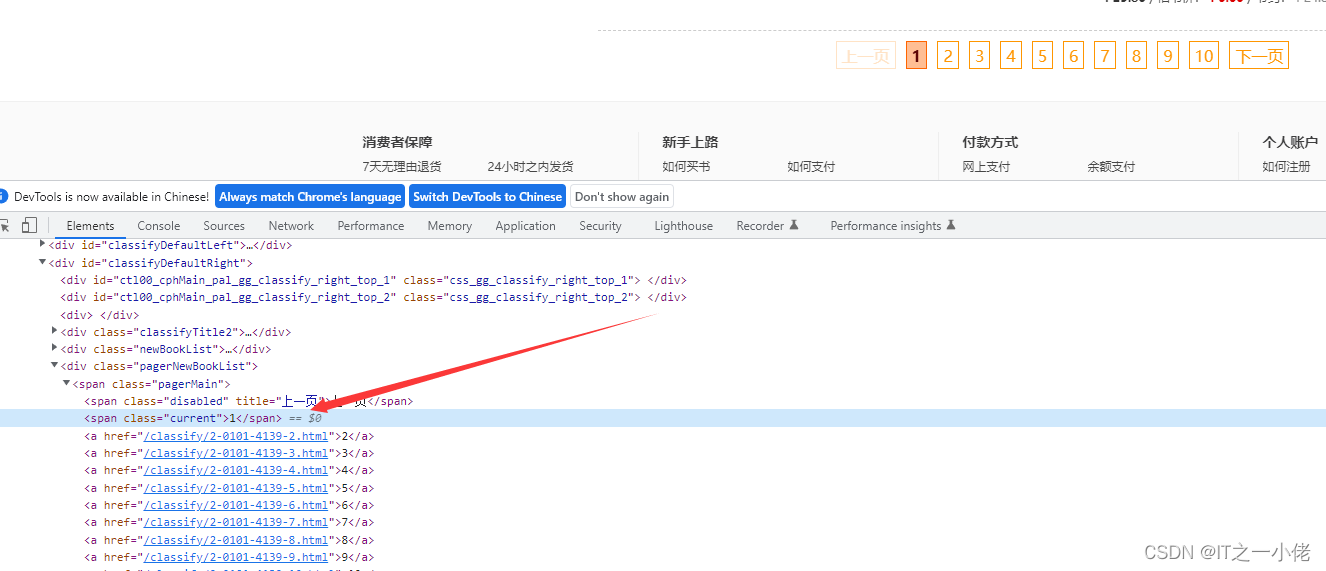
# print(response.xpath('//*[@id="classifyDefaultRight"]/div[5]/ul/li/div[2]/div[1]/a').extract_first())
print(response.xpath('//*[@id="classifyDefaultRight"]/div[5]/ul/li/div[2]/div[1]/a'))
print("网站地址: ", response.url)运行程序:
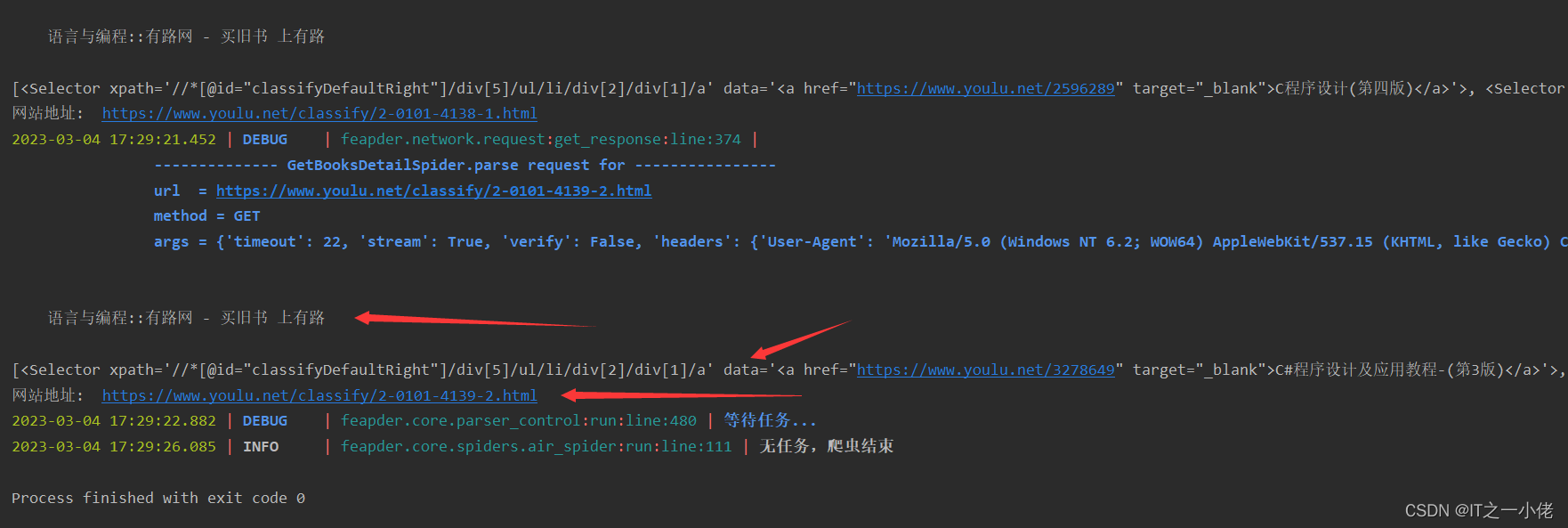
注意:
3.3 抓取详情
抓详情需要将列表采集到的url作为新任务,然后请求,解析。
派发详情任务:
yield feapder.Request(url, callback=self.parser_detail) # callback 为回调函数需要携带3.2程序中获取的书籍标题中链接url
yield feapder.Request(
first_book_name.split('" target="')[0][9:], callback=self.parse_detail, title=title, first_book_name=first_book_name
) # callback为回调函数,将title和first_book_name传到回调函数中,为携带的字段,直接携带就行,不用放到一个meta里解析详情:
def parse_detail(self, request, response):
"""
解析详情
:param request:
:param response:
:return:
"""
# 获取url
url = request.url
# 获取title
title = request.title
# 获取第一本书名
first_book_name = request.first_book_name
# 获取第一本书详情中作者名字
author = response.xpath('//*[@id="goods_disc"]/div[2]/ul/li[3]/div[2]/a/text()').extract_first()
print(url)
print(title)
print(first_book_name)
print(author)整体代码如下:
# -*- coding: utf-8 -*-
"""
Created on 2023-03-04 17:15:29
---------
@summary:
---------
@author: 86187
"""
import feapder
class GetBooksDetailSpider(feapder.AirSpider):
def start_requests(self):
for i in range(1, 10):
if i == 1:
yield feapder.Request("https://www.youlu.net/classify/2-0101-4138-1.html")
else:
yield feapder.Request(f"https://www.youlu.net/classify/2-0101-4139-{i}.html")
def parse(self, request, response):
# 提取网站title
title = response.xpath("/html/head/title/text()").extract_first().replace('\n', '').replace(' ', '')
# print(title)
# 提取网站所有书籍名称
# print(response.xpath('//*[@id="classifyDefaultRight"]/div[5]/ul/li/div[2]/div[1]/a'))
# 提取网站第一本书籍名称
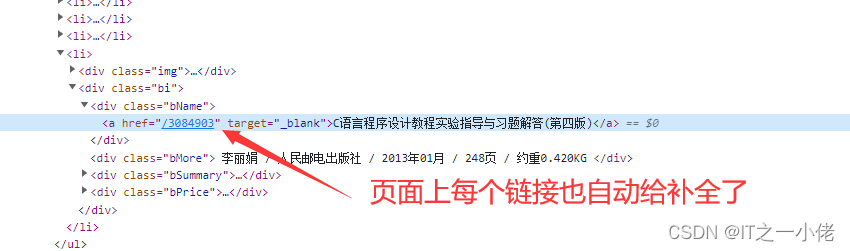
first_book_name = response.xpath('//*[@id="classifyDefaultRight"]/div[5]/ul/li/div[2]/div[1]/a').extract_first()
# print(first_book_name)
url = response.url
# print(url)
# print("网站地址: ", url)
# yield feapder.Request(
# url, callback=self.parse_detail, title=title, first_book_name=first_book_name
# ) # callback为回调函数
yield feapder.Request(
first_book_name.split('" target="')[0][9:], callback=self.parse_detail, title=title, first_book_name=first_book_name
) # callback为回调函数,将title和first_book_name传到回调函数中
def parse_detail(self, request, response):
"""
解析详情
:param request:
:param response:
:return:
"""
# 获取url
url = request.url
# 获取title
title = request.title
# 获取第一本书名
first_book_name = request.first_book_name
# 获取第一本书详情中作者名字
author = response.xpath('//*[@id="goods_disc"]/div[2]/ul/li[3]/div[2]/a/text()').extract_first()
print(url)
print(title)
print(first_book_name)
print(author)
if __name__ == "__main__":
GetBooksDetailSpider().start()
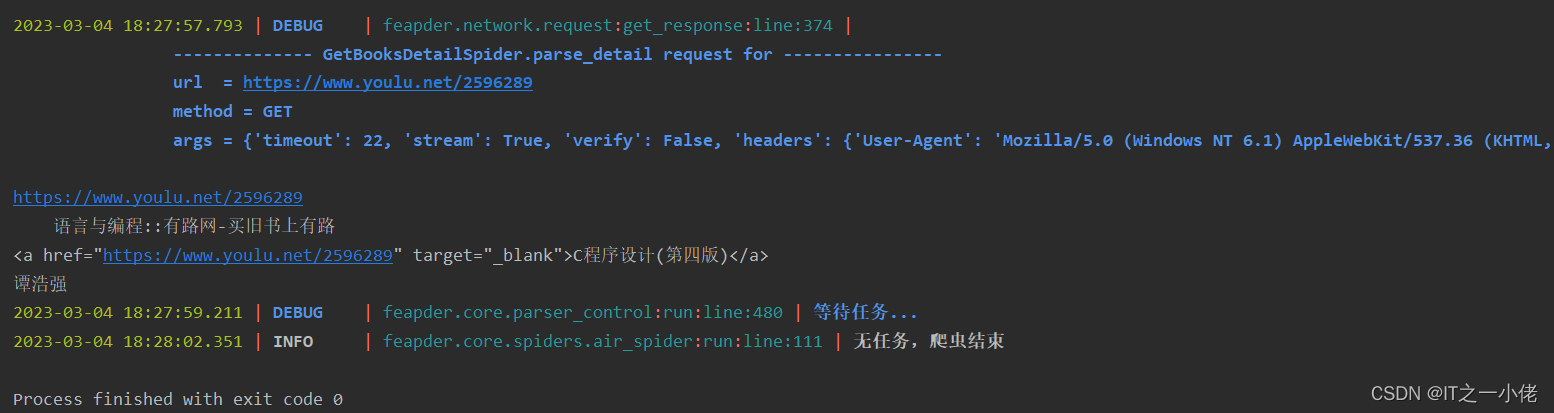
运行结果如下:
可以使用多线程来执行上述代码:
if __name__ == "__main__":
GetBooksDetailSpider(thread_count=5).start()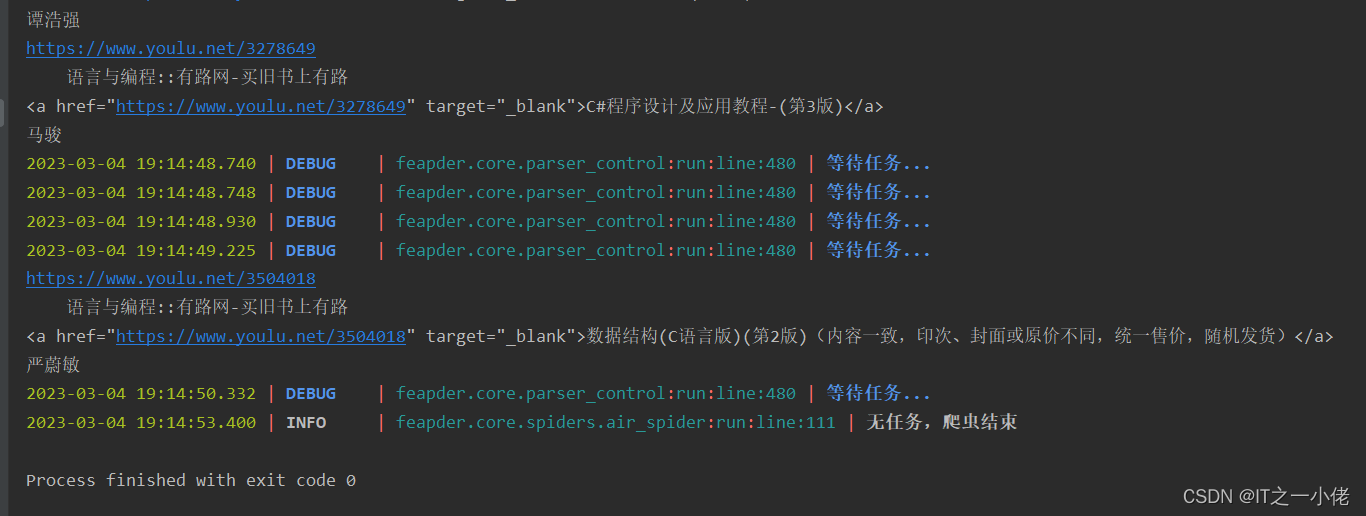
4、架构设计
4.1 框架流程图
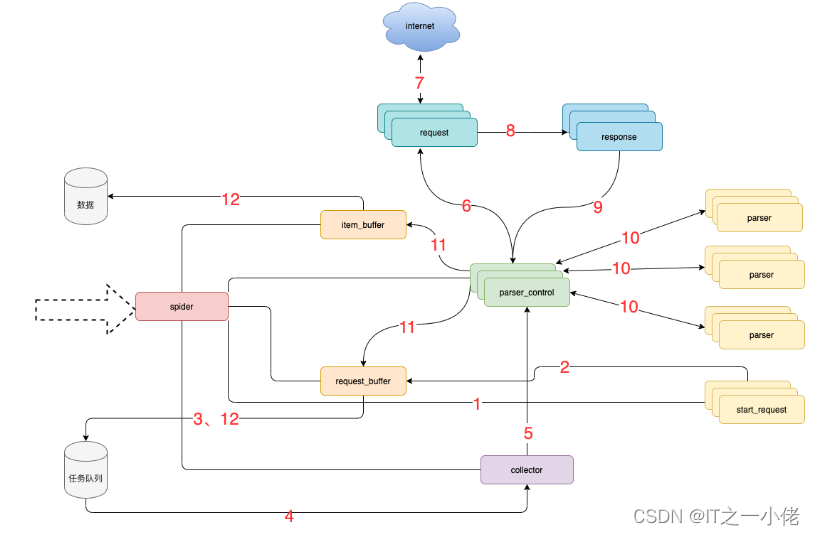
4.2 模块说明
- spider 框架调度核心
- parser_control 模版控制器,负责调度parser
- collector 任务收集器,负责从任务队里中批量取任务到内存,以减少爬虫对任务队列数据库的访问频率及并发量
- parser 数据解析器
- start_request 初始任务下发函数
- item_buffer 数据缓冲队列,批量将数据存储到数据库中
- request_buffer 请求任务缓冲队列,批量将请求任务存储到任务队列中
- request 数据下载器,封装了requests,用于从互联网上下载数据
- response 请求响应,封装了response, 支持xpath、css、re等解析方式,自动处理中文乱码
4.3 流程说明
- spider调度start_request生产任务
- start_request下发任务到request_buffer中
- spider调度request_buffer批量将任务存储到任务队列数据库中
- spider调度collector从任务队列中批量获取任务到内存队列
- spider调度parser_control从collector的内存队列中获取任务
- parser_control调度request请求数据
- request请求与下载数据
- request将下载后的数据给response,进一步封装
- 将封装好的response返回给parser_control(图示为多个parser_control,表示多线程)
- parser_control调度对应的parser,解析返回的response(图示多组parser表示不同的网站解析器)
- parser_control将parser解析到的数据item及新产生的request分发到item_buffer与request_buffer
- spider调度item_buffer与request_buffer将数据批量入库
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/142741.html

