
RDD Cache 缓存
RDD
通过
Cache
或者
Persist
方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM
的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的
action
算子时,该 RDD
将会被缓存在计算节点的内存中,并供后面重用
案例代码1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Persist1 {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map((_,1))
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("**************************************")
val rdd1 = sc.makeRDD(list)
val flatRDD1 = rdd1.flatMap(_.split(" "))
val mapRDD1 = flatRDD1.map((_,1))
val groupRDD = mapRDD1.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}运行这段程序,观察控制台输出效果

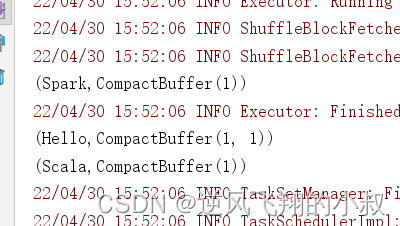
通过这段代码,尽管可以达到计算的效果,但是问题在于,每次开始一种业务的计算,都需要重新创建RDD,即达不到复用的效果,于是Spark 提供了缓存来处理这个问题;
案例代码2
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Persist3 {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Persist")
val sc = new SparkContext(sparConf)
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(word=>{
println("@@@@@@@@@@@@")
(word,1)
})
// cache默认持久化的操作,只能将数据保存到内存中,如果想要保存到磁盘文件,需要更改存储级别
//mapRDD.cache()
// 持久化操作必须在行动算子执行时完成的。
mapRDD.persist(StorageLevel.DISK_ONLY)
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("**************************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}从上面的代码可以发现,mapRDD 得到的一个个分离的单词,既可以在reduceByKey算子中使用,也可以在groupByKey的算子这中使用,而在第一次得到mapRDD之后放入缓存后,后面就可以复用这个RDD,就起到了缓存的效果;
存储级别
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)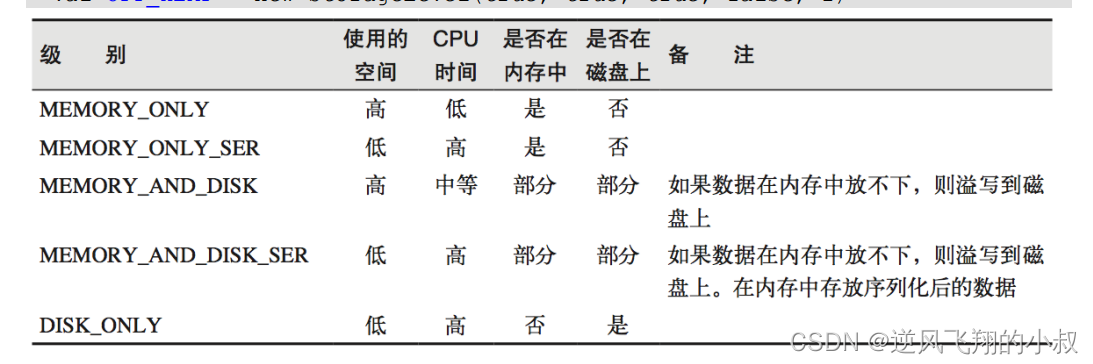
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,
RDD
的缓存容错机 制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD
的一系列转换,丢失的数 据会被重算,由于 RDD
的各个
Partition
是相对独立的,因此只需要计算丢失的部分即可, 并不需要重算全部 Partition
。
RDD
的缓存容错机 制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD
的一系列转换,丢失的数 据会被重算,由于 RDD
的各个
Partition
是相对独立的,因此只需要计算丢失的部分即可, 并不需要重算全部 Partition
。
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
CheckPoint 检查点
- 所谓的检查点其实就是通过将 RDD 中间结果写入磁盘;
- 由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销;
- 对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发;
案例代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Persist5 {
def main(args: Array[String]): Unit = {
// cache : 将数据临时存储在内存中进行数据重用
// persist : 将数据临时存储在磁盘文件中进行数据重用
// 涉及到磁盘IO,性能较低,但是数据安全
// 如果作业执行完毕,临时保存的数据文件就会丢失
// checkpoint : 将数据长久地保存在磁盘文件中进行数据重用
// 涉及到磁盘IO,性能较低,但是数据安全
// 为了保证数据安全,所以一般情况下,会独立执行作业
// 为了能够提高效率,一般情况下,是需要和cache联合使用
val sparConf = new SparkConf().setMaster("local").setAppName("Persist")
val sc = new SparkContext(sparConf)
sc.setCheckpointDir("cp")
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(word=>{
println("@@@@@@@@@@@@")
(word,1)
})
mapRDD.cache()
mapRDD.checkpoint()
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("**************************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
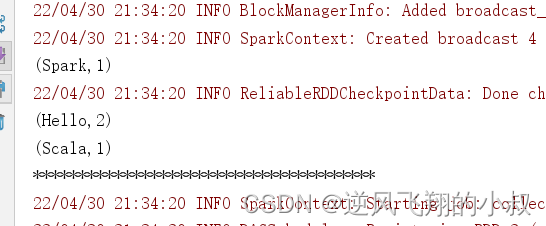
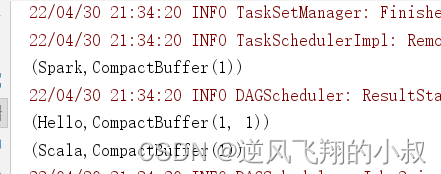
}运行上面的程序,观察控制台输出效果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/143242.html

