
大家好,我是百思不得小赵。
创作时间:2022 年 7 月 7 日
博客主页: 🔍点此进入博客主页
—— 新时代的农民工 🙊
—— 换一种思维逻辑去看待这个世界 👀
今天是加入CSDN的第1222天。觉得有帮助麻烦👏点赞、🍀评论、❤️收藏


一、概述
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)“和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。——来源于百度百科。
MapReduce核心特性
- 主要用于大数据计算领域,解决海量数据的计算问题。
- MR 本身只是一个编程和计算框架,或者干脆一点就是一堆可调用的 jar 包,和 mysql、hdfs、impala等有运行实例的服务不一样, MR 本身没有运行实例。
- MR 有两个阶段组成:Map 和 Reduce,用户只需实现 map() 和 reduce() 两个函数,即可实现分布式计算。
- MapReduce 编程模型只包含 Map 和 Reduce 两个过程,map 的主要输入是一对 <key,value> 值,经过 map 计算后输出一对 <key,value> 值;然后将相同 Key 合并,形成 <key,value> 集合;再将这个<key,value 集合>输入 reduce,经过计算输出零个或多个 <key,value> 对。
二、MapReduce工作原理
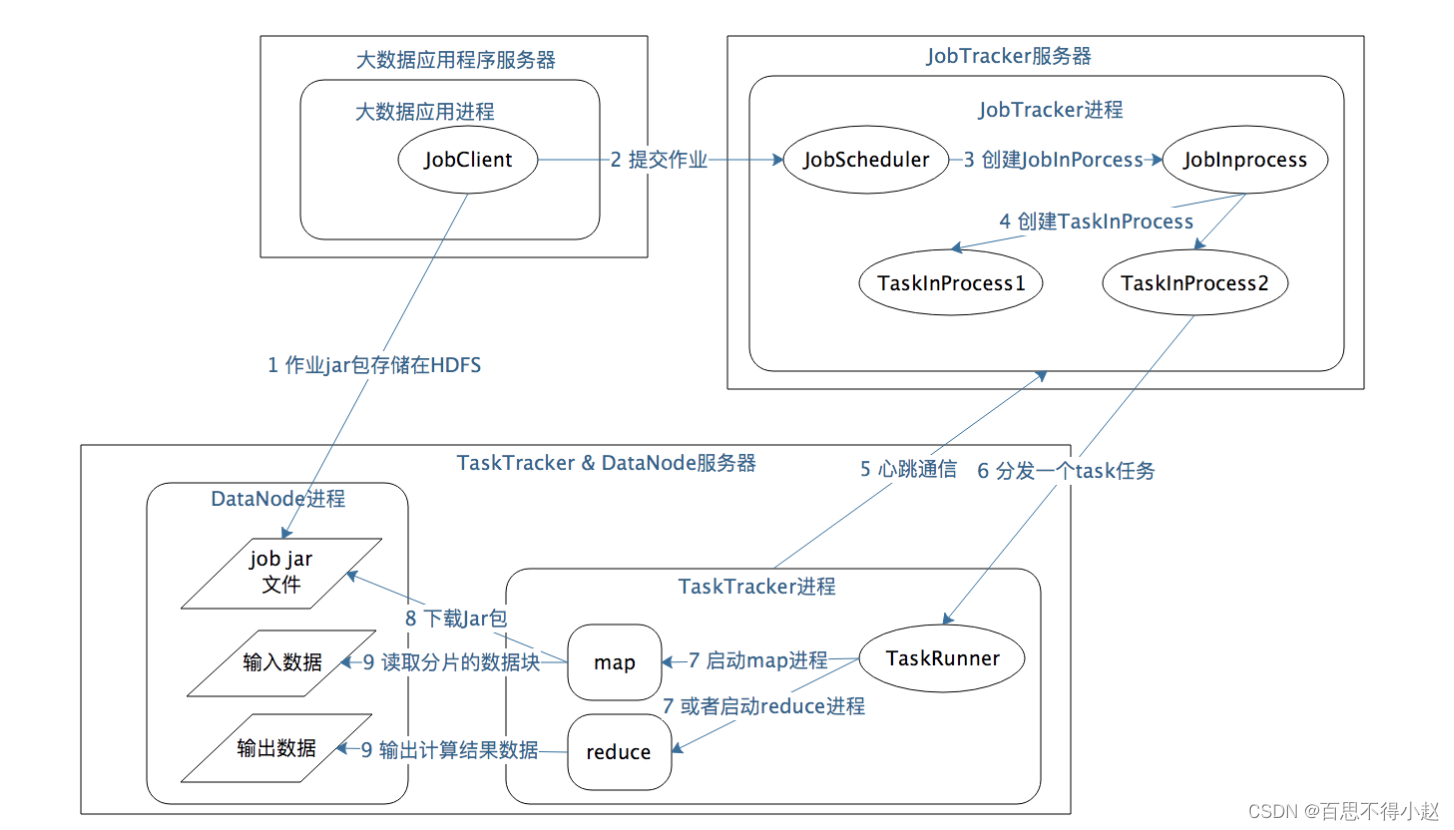
大数据应用进程(提交任务的客户端):
该进程是启动 MapReduce 程序的主入口,主要是指定 Map 和 Reduce 类、输入输出文件路径等,并提交作业给 Hadoop 集群
JobTracker进程:
Hadoop 集群常驻进程,根据要处理的输入数据量,命令 TaskTracker生成相应数量的Map和Reduce进程任务,并管理这个作业生命周期的任务的调度和监控
TaskTracker进程:
负责管理 Map 进程和 Reduce 进程。Hadoop 集群中绝大多数服务器同时运行 DataNode 进程和 TaskTracker 进程
三、MapReduce操作
运维操作:
hadoop jar jar包路径 入口程序类名 输入文件的hdfs目录 输出文件的hdfs目录
四、案例
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//针对每个单词输出一个<word ,1>
//MapReduce 计算框架会将这些<word ,1>收集起来,将相同的word放一起,形成
//<word,<1,1,1,...>>这样的<key,value集合>,然后输入给reduce
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
//reduce对每个word对应的所有1 进行求和,最终将<word,合计>输出
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/144867.html

