

前篇文章由案例驱动,总结了Sell中的基本语法,这篇文章带大家由案例驱动学习下Sell中的自带的工具命令。
Cut
cut的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
基本用法
cut [选项参数] filename
# 默认分隔符是制表符
参数说明
- -f :列号,提取第几列
- -d :分隔符,按照指定分隔符分割列
案例:
首先进入到linux系统中,准备数据
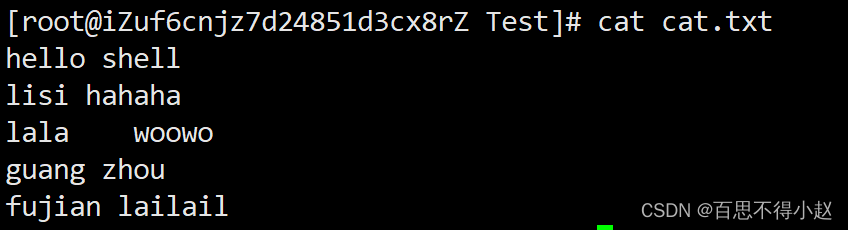
案例1:切割cat.txt第一列
cut -f 1 -d " " cat.txt
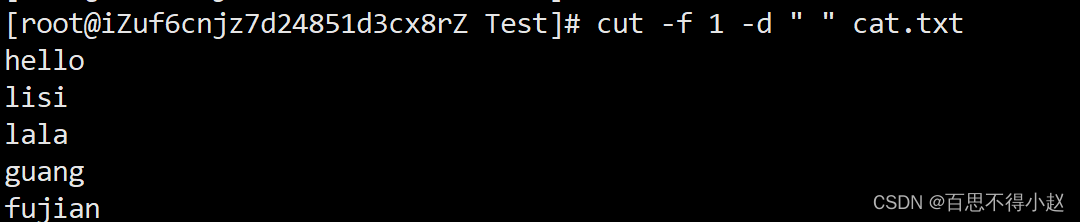
案例2:切割cat.txt第二、三列
cut -f 2,3 -d " " cat.txt
案例3:在cat.txt文件中切割出lisi
cat cat.txt | grep "lisi" | cut -f 1 -d " "

Sed
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
基本用法
sed [选项参数] ‘command’ filename
参数说明
- -e : 直接在指令列模式上进行sed的动作编辑
命令功能
- a : 新增,a的后面可以接字串,在下一行出现
- d : 删除
- s :查找并替换
案例:
准备数据
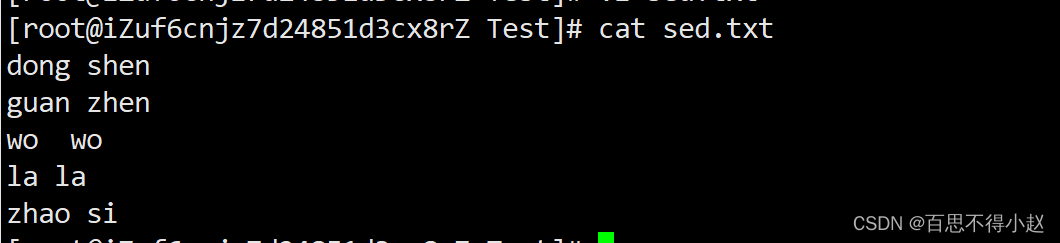
案例1:将“hello wawa”这个词插入到sed.txt第二行下,打印
sed '2a hello wawa' sed.txt
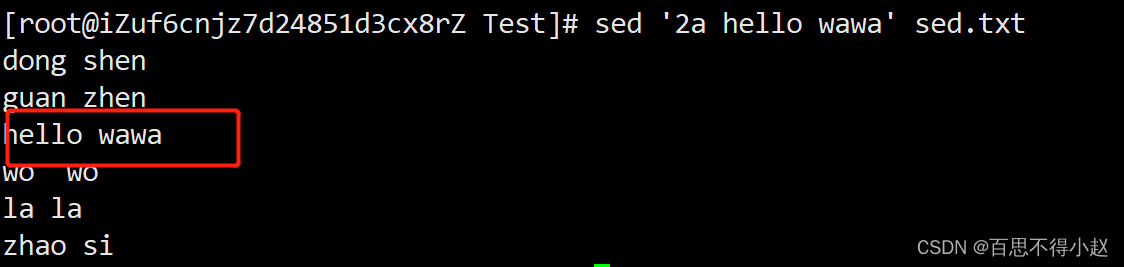
ps:文件并没有改变
案例2:删除sed.txt文件所有包含wo的行
sed '/wo/d' sed.txt

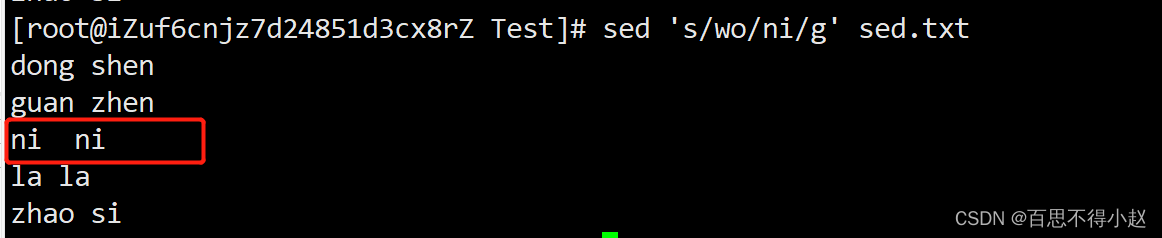
案例3:将sed.txt文件中wo替换为ni
sed 's/wo/ni/g' sed.txt
Awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
基本用法
awk [选项参数] ‘pattern1{action1} pattern2{action2}...’ filename
# pattern:表示AWK在数据中查找的内容,就是匹配模式
# action:在找到匹配内容时所执行的一系列命令
参数说明
- -F : 指定输入文件折分隔符
- -v : 赋值一个用户定义变量
案例:
准备数据
sudo cp /etc/passwd ./
搜索passwd文件以root关键字开头的所有行,并输出该行的第7列。
awk -F: '/^root/{print $7}' passwd

awk的内置变量
- FILENAME 文件名
- NR 已读的记录数
- NF 浏览记录的域的个数(切割后,列的个数)
案例:
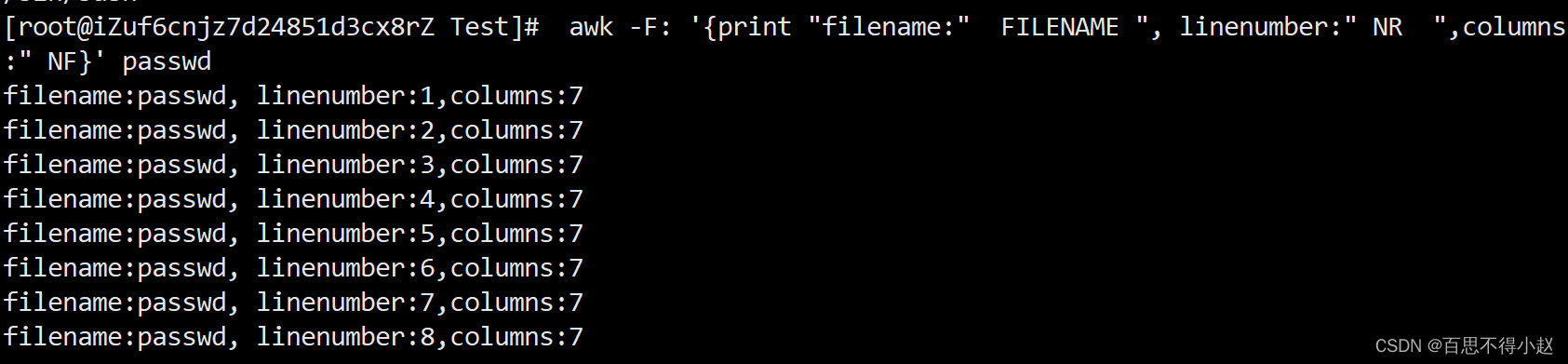
统计passwd文件名,每行的行号,每行的列数
awk -F: '{print "filename:" FILENAME ", linenumber:" NR ",columns:" NF}' passwd
Sort
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。
基本语法
sort(选项)(参数)
参数说明
- -n 依照数值的大小排序
- -r 以相反的顺序来排序
- -t 设置排序时所用的分隔字符
- -k 指定需要排序的列
案例:
准备数据
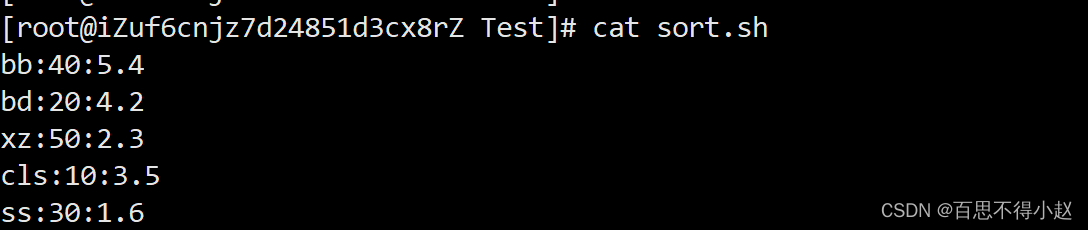
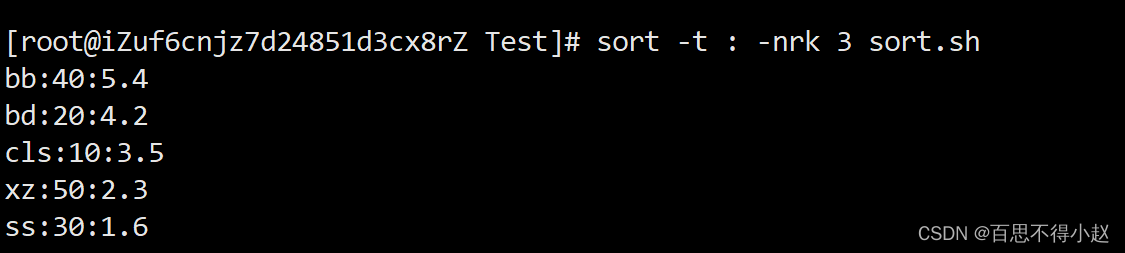
按照“:”分割后的第三列倒序排序
sort -t : -nrk 3 sort.sh
本次分享到这里就结束了,希望对大家有所帮助。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/144876.html

