
文章目录
需求: 视频处理
视频上传成功需要对视频的格式进行转码处理,比如:avi转成mp
1、知识背景
1.1 文件格式与编码格式
视频文件的内容主要包括视频和音频,其文件格式是按照一 定的编码格式去编码,并且按照该文件所规定的封装格式将视频、音频、字幕等信息封装在一起,播放器会根据它们的封装格式去提取出编码,然后由播放器解码,最终播放音视频。
- .mp4、.avi、.rmvb等 这些视频文件的不同扩展名, 称为文件格式
- 编码格式: 通过音视频的压缩技术,将视频格式转换成另一种视频格式,通过视频编码实现流媒体的传输。比如:一个.avi的视频文件原来的编码是a,通过编码后编码格式变为b,音频原来为c,通过编码后变为d
音视频编码格式种类繁多, 目前最常用的编码标准是视频H.264,音频AAC。
1.2 FFmpeg
下载地址:
https://www.ffmpeg.org/download.html#build-windows
下载后解压ffmpeg.zip, 在.exe文件的目录下打开cmd窗口, 运行 ffmpeg -v
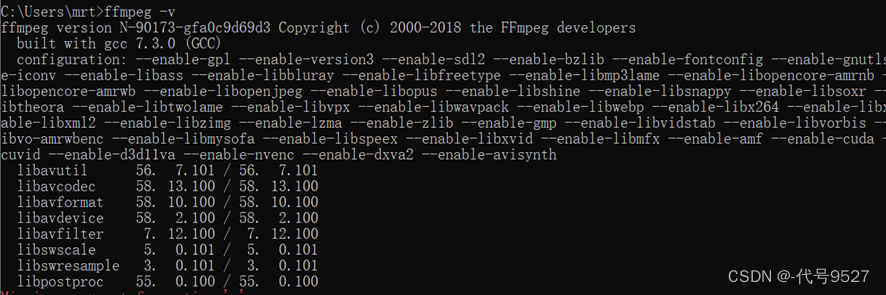
以上即安装成功
//对1.avi文件进行转码:
//先把avi转mp4
D:\soft\ffmpeg\ffmpeg.exe -i 1.avi 1.mp4
//转mp3
ffmpeg -i 1.avi 1.mp3
//转gif
ffmpeg -i 1.avi 1.gif
1.3 视频处理工具类
要通过ffmpeg对视频转码,得用Java程序去启动ffmpeg,使用java.lang.ProcessBuilder去完成
//这里以启动QQ为例
ProcessBuilder builder = new ProcessBuilder();
builder.command("C:\\Program Files (x86)\\Tencent\\QQ\\Bin\\QQScLauncher.exe");
//将标准输入流和错误输入流合并,通过标准输入流程读取信息
builder.redirectErrorStream(true);
Process p = builder.start();
对视频的转码, 直接使用工具类:
Java
public static void main(String[] args) throws IOException {
//ffmpeg的路径
String ffmpeg_path = "D:\\soft\\ffmpeg\\ffmpeg.exe";//ffmpeg的安装位置
//源avi视频的路径
String video_path = "D:\\develop\\bigfile_test\\nacos01.avi";
//转换后mp4文件的名称
String mp4_name = "nacos01.mp4";
//转换后mp4文件的路径
String mp4_path = "D:\\develop\\bigfile_test\\nacos01.mp4";
//创建工具类对象
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpeg_path,video_path,mp4_name,mp4_path);
//开始视频转换,成功将返回success
//videoUtil工具类的generateMp4方法封装了对ffmpeg的启动以及转码所用到的语句
String s = videoUtil.generateMp4();
System.out.println(s);
}
generateMp4方法源代码如下:
public String generateMp4(){
//清除已生成的mp4
// clear_mp4(mp4folder_path+mp4_name);
clear_mp4(mp4folder_path);
/*
ffmpeg.exe -i lucene.avi -c:v libx264 -s 1280x720 -pix_fmt yuv420p -b:a 63k -b:v 753k -r 18 .\lucene.mp4
*/
List<String> commend = new ArrayList<String>();
//commend.add("D:\\Program Files\\ffmpeg-20180227-fa0c9d6-win64-static\\bin\\ffmpeg.exe");
commend.add(ffmpeg_path);
commend.add("-i");
// commend.add("D:\\BaiduNetdiskDownload\\test1.avi");
commend.add(video_path);
commend.add("-c:v");
commend.add("libx264");
commend.add("-y");//覆盖输出文件
commend.add("-s");
commend.add("1280x720");
commend.add("-pix_fmt");
commend.add("yuv420p");
commend.add("-b:a");
commend.add("63k");
commend.add("-b:v");
commend.add("753k");
commend.add("-r");
commend.add("18");
// commend.add(mp4folder_path + mp4_name );
commend.add(mp4folder_path );
String outstring = null;
try {
ProcessBuilder builder = new ProcessBuilder();
builder.command(commend);
//将标准输入流和错误输入流合并,通过标准输入流程读取信息
builder.redirectErrorStream(true);
Process p = builder.start();
outstring = waitFor(p);
} catch (Exception ex) {
ex.printStackTrace();
}
// Boolean check_video_time = this.check_video_time(video_path, mp4folder_path + mp4_name);
Boolean check_video_time = this.check_video_time(video_path, mp4folder_path);
if(!check_video_time){
return outstring;
}else{
return "success";
}
}
2、分布式任务处理
2.1 分布式任务调度
想高效的去处理一批任务,有以下两种思路:
- 多线程:充分利用单机资源
分布式加多线程:充分利用多台计算机,每台计算机使用多线程处理
关于任务调度,思考以下场景:
- 每隔24小时执行数据备份任务
- 12306网站会根据车次不同,设置几个时间点分批次放票
- 某财务系统需要在每天上午10点前结算前一天的账单数据,统计汇总
- 商品成功发货后,需要向客户发送短信提醒
以上场景的实现思路有:
思路一:线程休眠
public static void main(String[] args) {
//任务执行间隔时间
final long timeInterval = 1000;
Runnable runnable = new Runnable() {
public void run() {
while (true) {
//TODO:something
try {
Thread.sleep(timeInterval);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
Thread thread = new Thread(runnable);
thread.start();
}
思路2:Timer
Jdk也提供了相关支持,如Timer、ScheduledExecutor
public static void main(String[] args){
Timer timer = new Timer();
timer.schedule(new TimerTask(){
@Override
public void run() {
//TODO:something
}
}, 1000, 2000); //1秒后开始调度,每2秒执行一次
}
每个Timer对应一个线程,因此可以同时启动多个Timer并行执行多个任务,同一个Timer中的任务是串行执行
思路3:ScheduledExecutor
基于线程池设计的 ScheduledExecutor,每一个被调度的任务都会由线程池中一个线程去执行,因此任务是并发执行的,相互之间不会受到干扰
public static void main(String [] agrs){
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
service.scheduleAtFixedRate(
new Runnable() {
@Override
public void run() {
//TODO:something
System.out.println("todo something");
}
}, 1,
2, TimeUnit.SECONDS);
}
以上三种能完成简单的任务,如给定开始时间与重复间隔,重复执行某任务,但比较复杂的实现不了,如:设置每月第一天凌晨1点执行任务、复杂调度任务的管理、任务间传递数据等等
任务的调度,即指系统为了完成特定业务,基于给定时间点,给定时间间隔或者给定执行次数,去自动执行任务
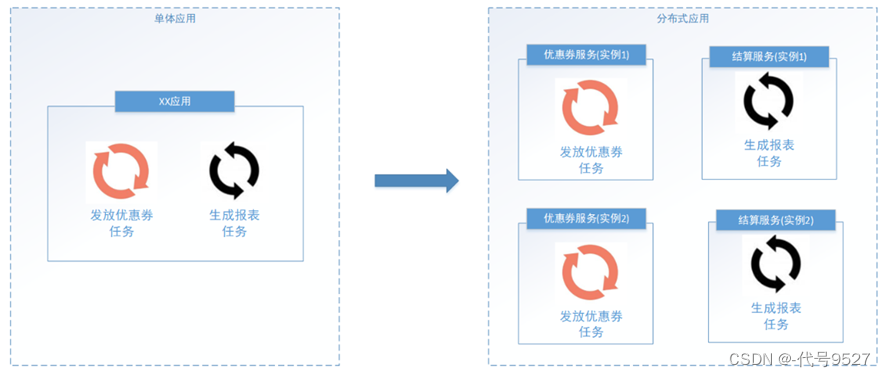
而分布式任务调度,即多台计算机共同去完成任务调度。从而可以:
- 突破单机多线程的瓶颈,并行任务调度
- 高可用
- 弹性扩容
此外,需要注意任务管理与监测,以及防止任务被重复执行。
2.2 XXL-JOB
XXL-JOB是一个分布式任务调度平台,主要有调度中心和执行器。官网:https://www.xuxueli.com/xxl-job/
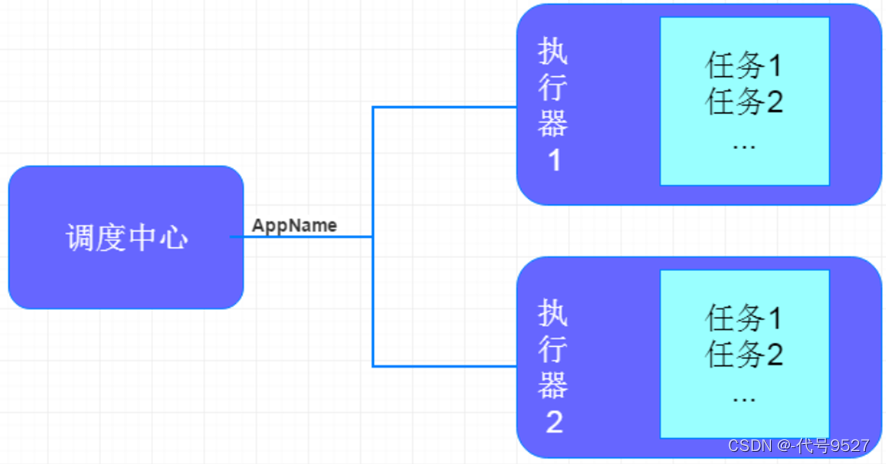
调度中心和执行器之间的工作流程:
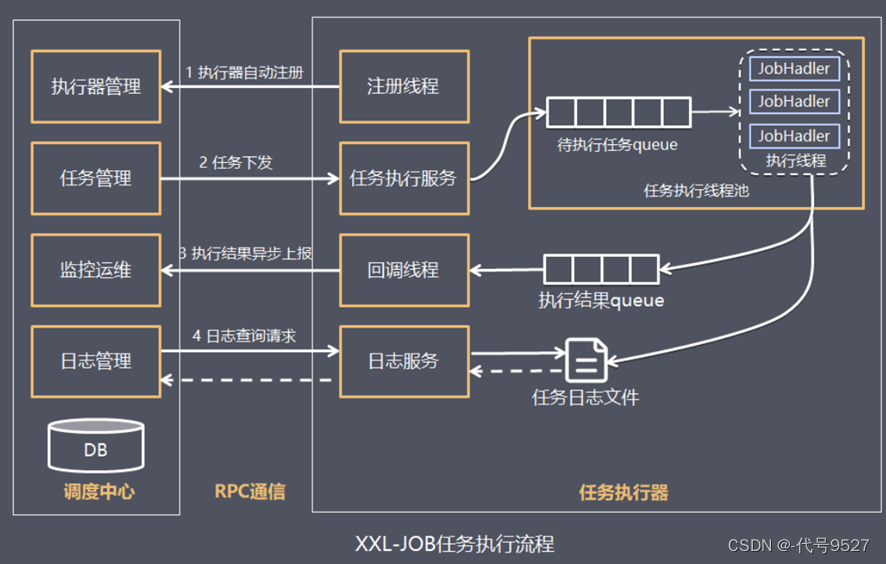
任务执行器根据配置的调度中心的地址,自动注册到调度中心当达到任务的触发条件时,调度中心下发任务给任务执行器执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中- 执行器消费内存队列中的执行结果,主动上报给调度中心
- 当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
2.3 搭建XXL-Job
调度中心部分
- 下载源码解压并用IDEA打开项目
GitHub:https://github.com/xuxueli/xxl-job
码云:https://gitee.com/xuxueli0323/xxl-job
eg: https://github.com/xuxueli/xxl-job/releases/tag/2.3.1
- 项目代码结构介绍
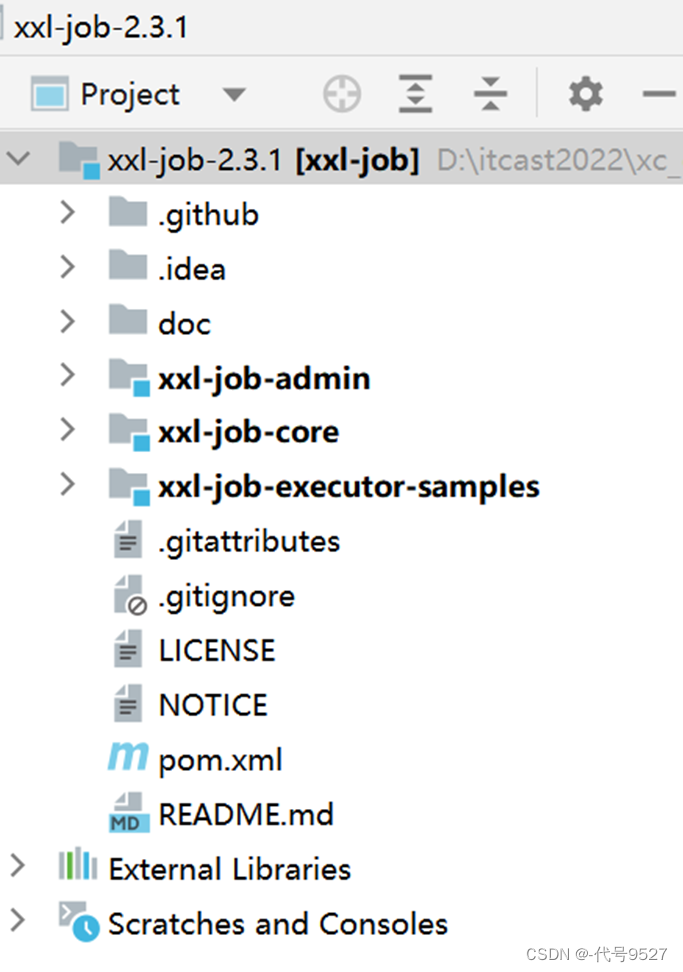

xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-frameless:无框架版本;
doc :文档资料,包含数据库脚本
-
执行doc文件中的SQL脚本,创建数据库表
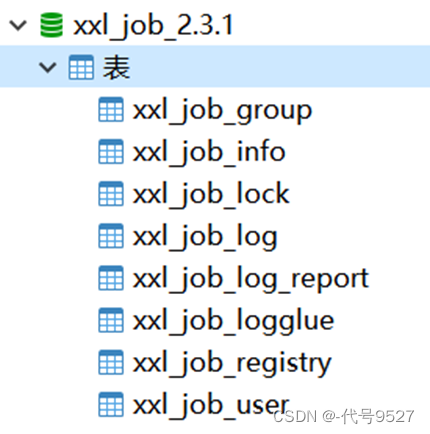
-
启动调度中心
虚拟机执行:sh /data/soft/restart.sh自动启动xxl-job调度中心
访问:http://localhost:8088/xxl-job-admin/
账号和密码:admin/123456
也可直接在IDEA中启动xxl-job-admin模块
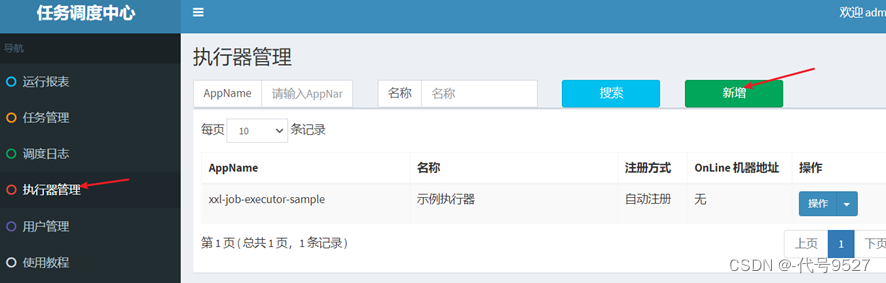
执行器部分
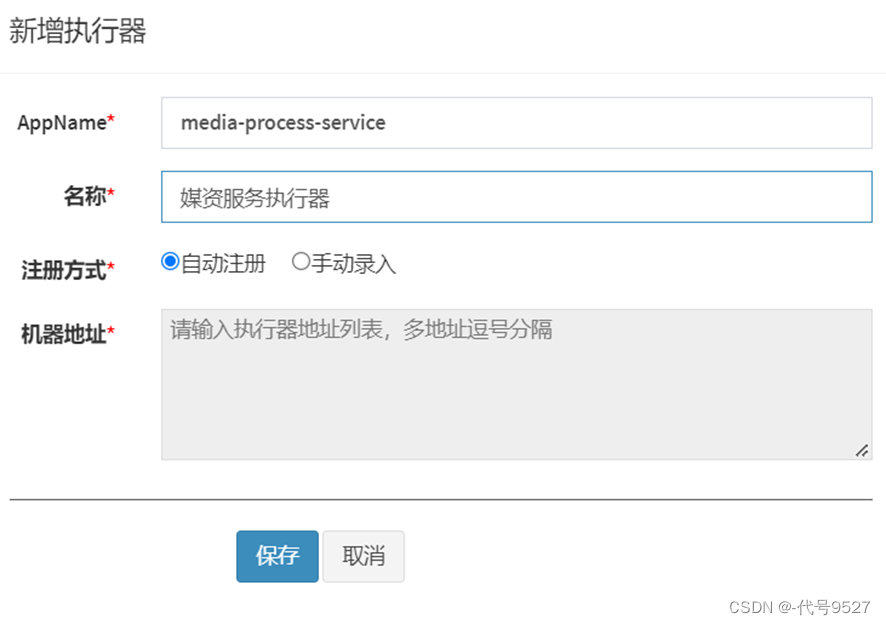
- 进入调度中心,添加执行器
- 填写执行器信息,appname是前边在nacos中配置xxl信息时指定的执行器的应用名
- 在需要跑定时任务的模块加入依赖,在项目的父工程已约定了版本2.3.1
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>
- 在nacos下对应服务的xxx-service-dev.yaml下配置xxl-job
xxl:
job:
admin:
# 调度中心地址
addresses: http://localhost:8088/xxl-job-admin
executor:
# 创建执行器时的appname
appname: media-process-service
address:
ip:
# port是执行器启动的端口,如果本地启动多个执行器注意端口不能重复
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_token
- 将xxl-job配置类拷贝到相应的工程目录下
执行任务
- 在xxxservice包下新建jobhandler存放任务类
/**
* @description 测试执行器
*/
@Component
@Slf4j
public class SampleJob {
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("testJob")
public void testJob() throws Exception {
//这里写调度任务的实现代码
log.info("开始执行.....");
}
}
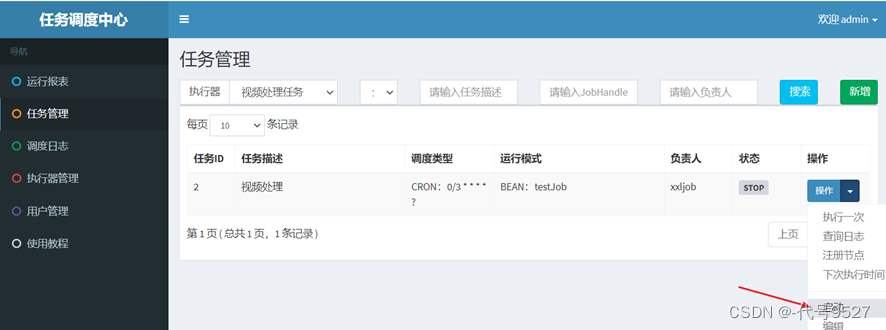
- 在调度中心选择执行器后,点击添加任务,进入任务管理
- 填写任务信息
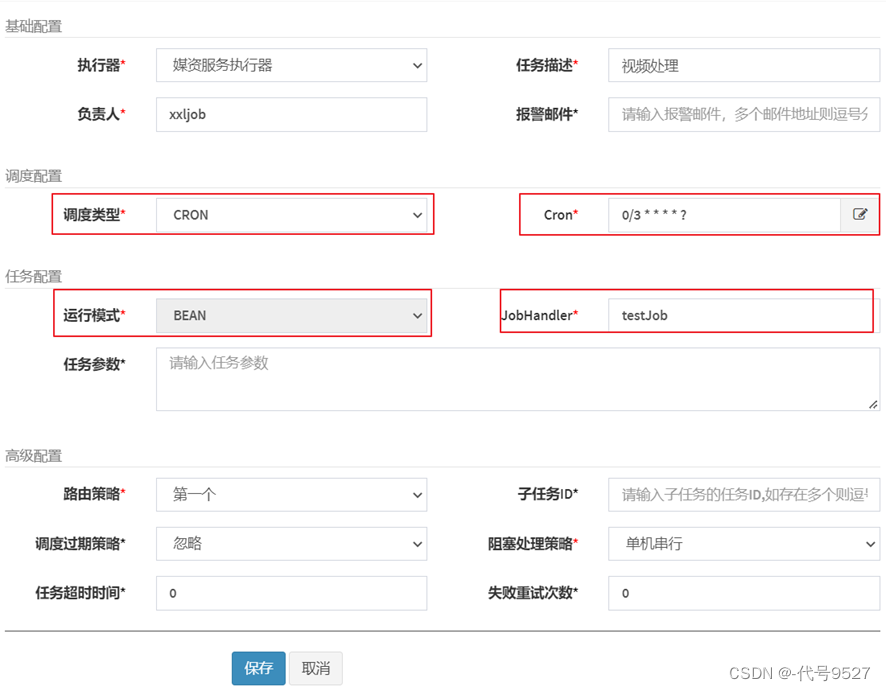
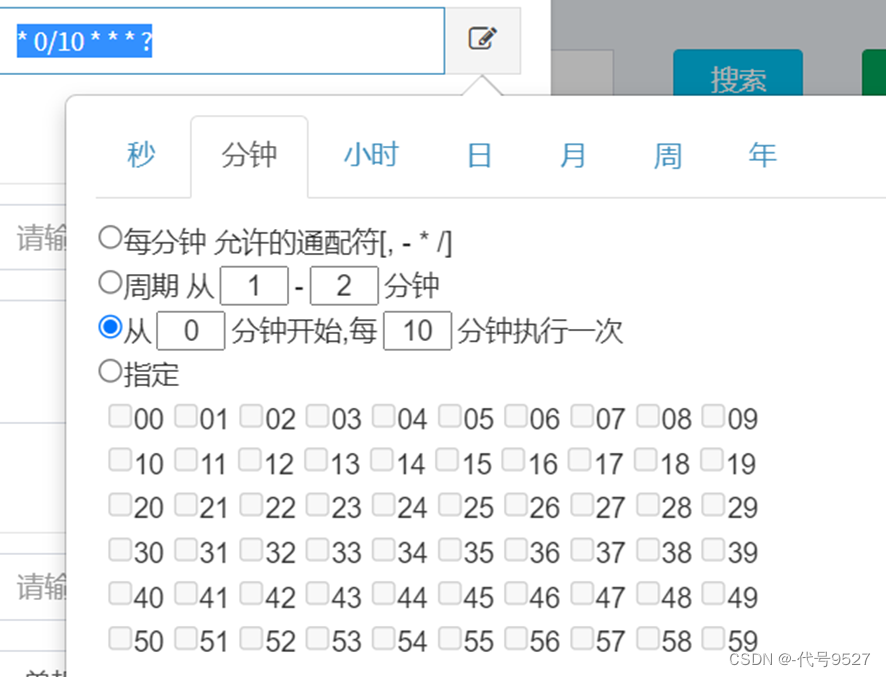
调度类型:
- 固定速度:指按固定的间隔定时调度。
- Cron:通过Cron表达式实现更丰富的定时调度策略。
cron表达式的格式为:{秒数} {分钟} {小时} {日期} {月份} {星期} {年份(可为空)}
举例:
30 10 1 * * ? 每天1点10分30秒触发
0/30 * * * * ? 每30秒触发一次
* 0/10 * * * ? 每10分钟触发一次
运行模式:
- BEAN:bean模式在项目工程中编写执行器的任务代码
- GLUE:GLUE是将任务代码编写在调度中心
JobHandler即任务方法名,填写任务方法上边@XxlJob注解中的名称
- 信息填写完成后点击启动
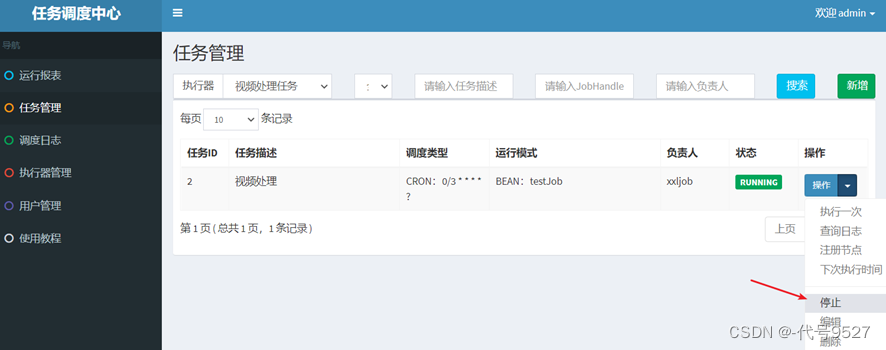
- 最后,可停止任务、手动执行一次任务、清理日志
2.4 分片广播
启动多个执行器,组成集群去执行任务,此时调度中心如何去调度这些执行器?
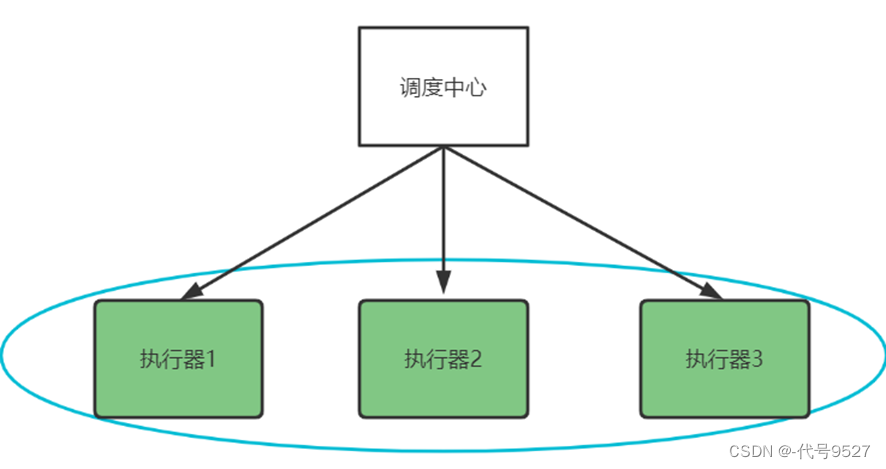
当执行器集群部署时,xxl-job可选的路由策略包括:
FIRST(第一个): 固定选择第一个机器;
LAST(最后一个): 固定选择最后一个机器;
ROUND(轮询): 轮流分配
RANDOM(随机): 随机选择在线的机器;
CONSISTENT_HASH(一致性HASH): 每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用): 使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用): 最久未使用的机器优先被选举;
FAILOVER(故障转移): 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移): 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播): 广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
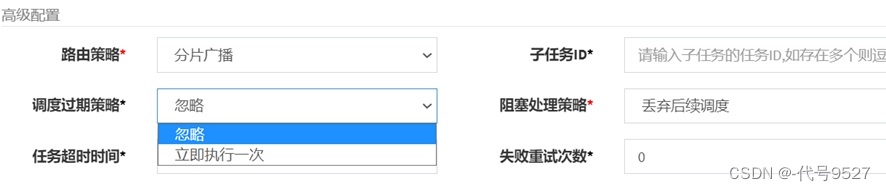
当过了任务的执行时间,而又收到了请求时,调度过期策略有:
- 忽略: 调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
- 立即执行一次: 调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
调度过于密集执行器来不及处理时的处理策略–阻塞处理策略有:
单机串行(默认): 调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度: 调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度: 调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
而分片广播策略,分片,即将集群中的执行器标上序号,广播是指每次调度会向集群中的所有执行器发送任务调度,并且请求中携带分片参数(序号,总的执行器数量)
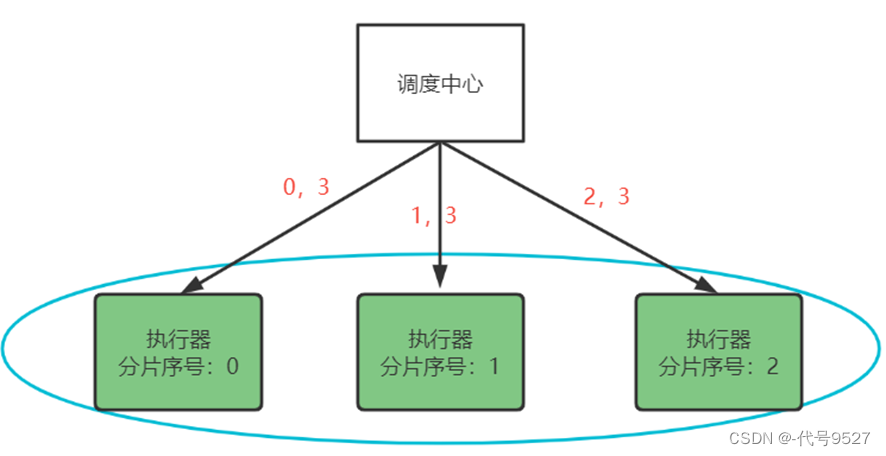
- 定义分片的任务方法:
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
log.info("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
- 在调度中心添加任务
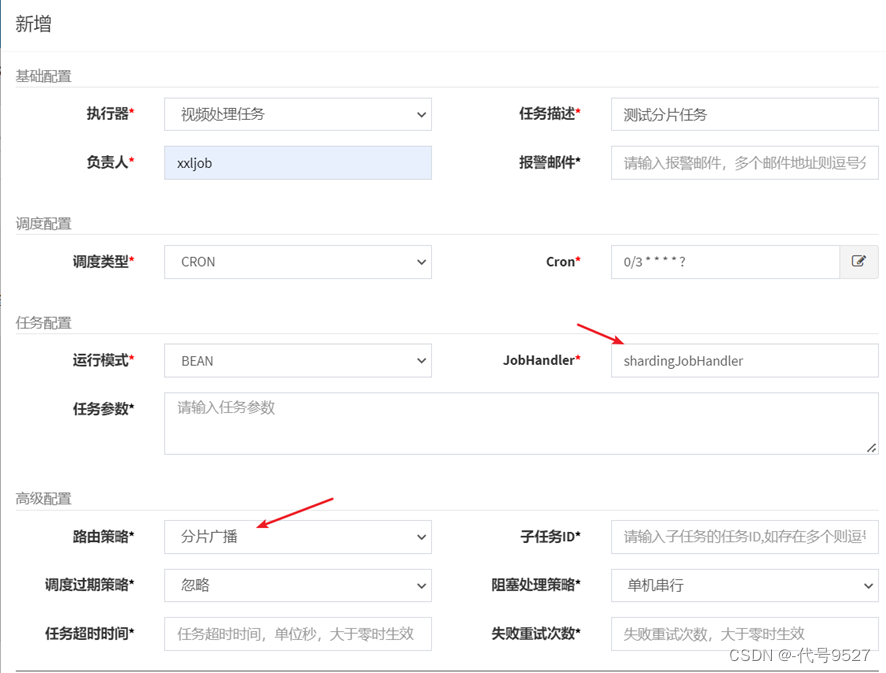
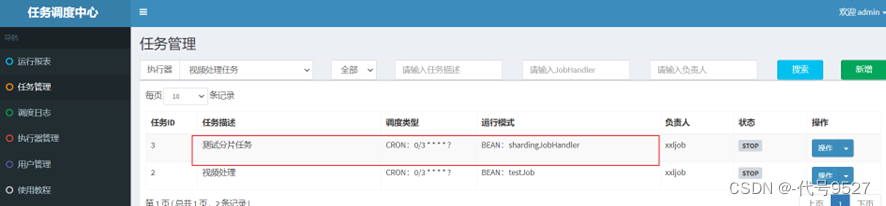
- 启动任务,查看控制台日志
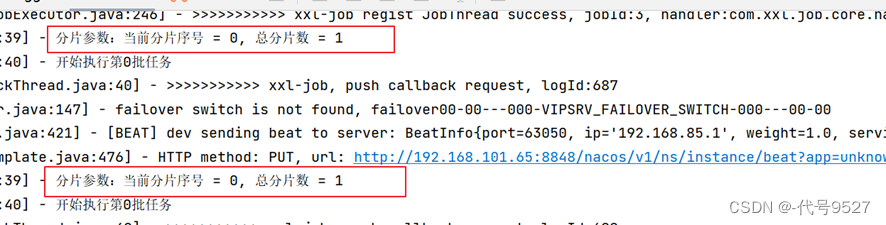
接下来启动两个执行器实例:
- 将媒资服务media-service启动两个实例:
实例1 在VM options处添加:-Dserver.port=63051 -Dxxl.job.executor.port=9998
实例2 在VM options处添加:-Dserver.port=63050 -Dxxl.job.executor.port=9999
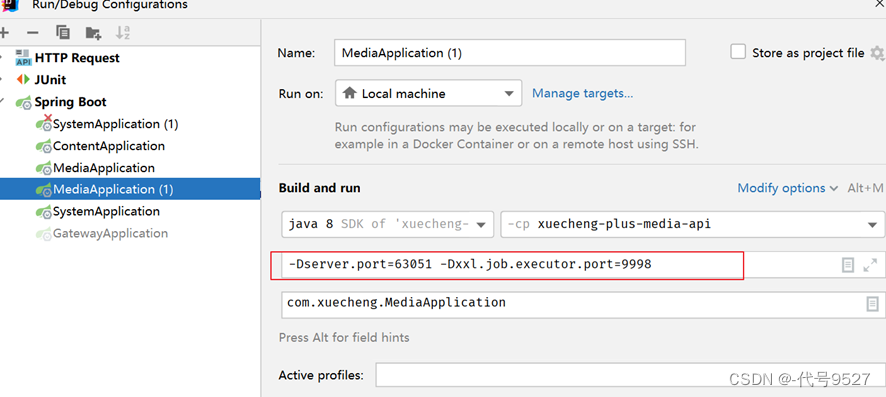
- 注意在nacos中开启本地配置优先
#配置本地优先
spring:
cloud:
config:
override-none: true
- 看到调度中心有两个执行器
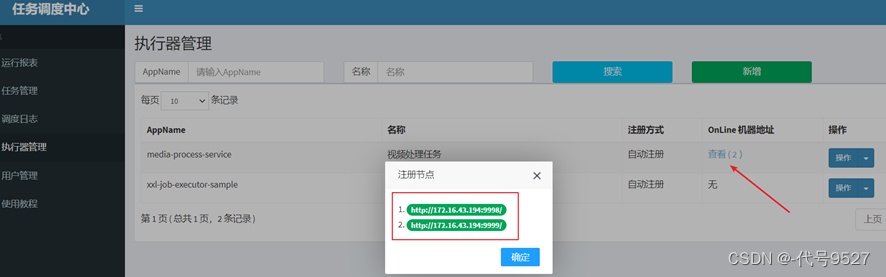

3、技术方案
XXL-JOB只会给执行器分配好分片序号,在向执行器任务调度的同时下发分片总数以及分片序号等参数。将要处理的任务会添加到待处理任务表中,多个执行器如何保证拿到的任务不重复?
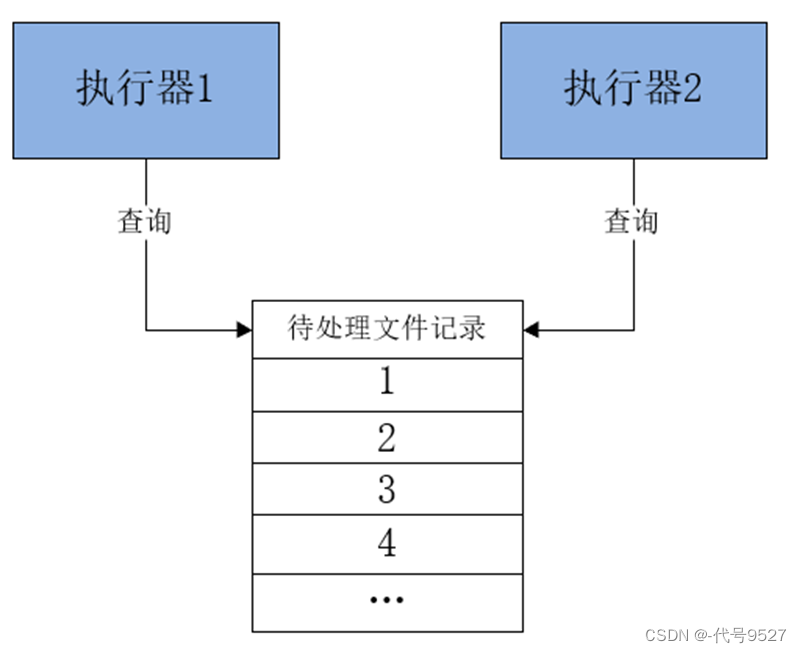
每个执行器收到广播任务有两个参数:分片总数、分片序号。让取出来的任务id模上分片总数,结果等于几,就让几号执行器处理:
1 % 2 = 1 执行器2执行
2 % 2 = 0 执行器1执行
3 % 2 = 1 执行器2执行
.....
配置过期调度策略:
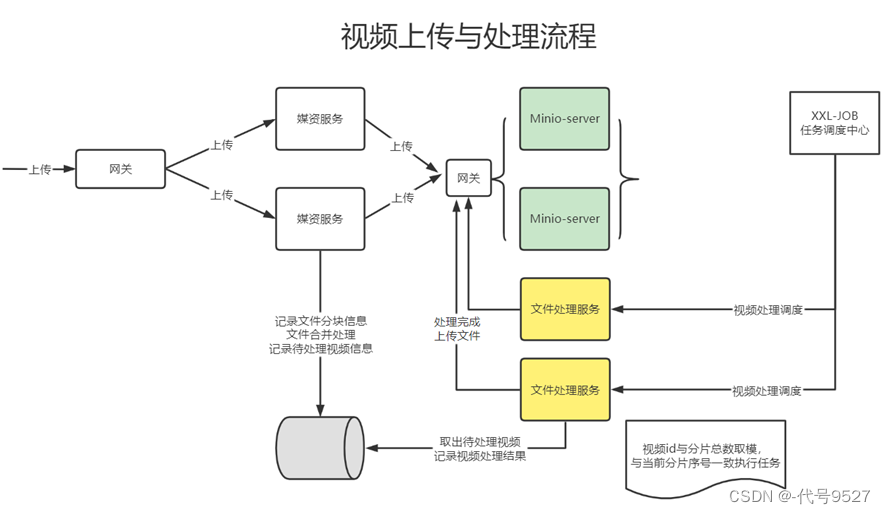
此时,任务还是有可能被重复执行,因此需要保证任务的幂等性。视频处理的业务流程图如下:
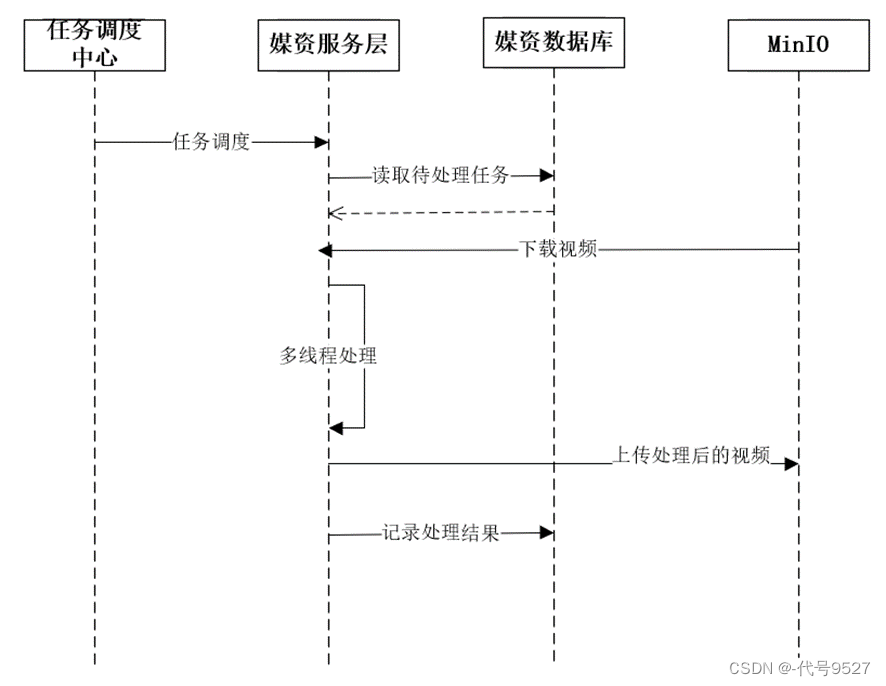
画出时序图:
4、查询待处理任务
4.1 需求分析
查询待处理任务只处理未提交及处理失败的任务,任务处理失败后进行重试,最多重试3次。
4.2 表设计
待处理任务表:
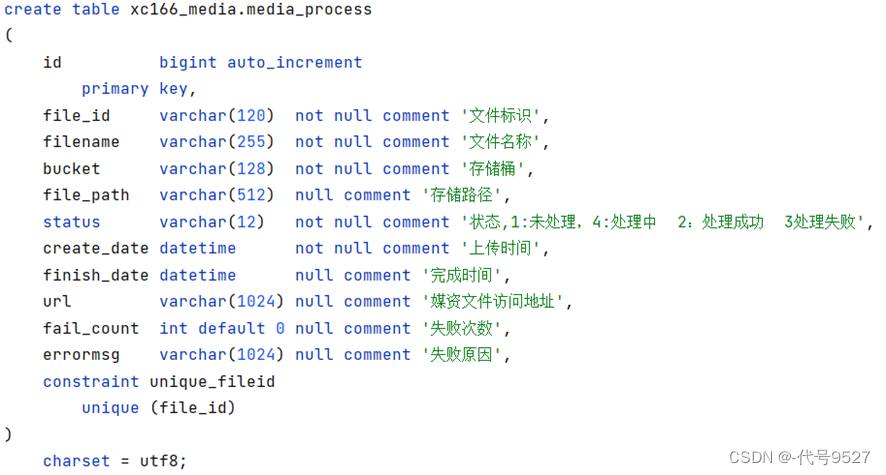
考虑到任务表要常做查询,而处理完的数据如果一直堆积,数据量会猛增,因此,引入历史记录表,将处理成功的记录从任务表移动到历史任务表,两张表结构相同。
4.3 添加待处理任务
判断如果是avi视频,需要入库任务表:
/**
* 添加待处理任务
* @param mediaFiles 媒资文件信息
*/
private void addWaitingTask(MediaFiles mediaFiles){
//文件名称
String filename = mediaFiles.getFilename();
//文件扩展名
String exension = filename.substring(filename.lastIndexOf("."));
//文件mimeType
String mimeType = getMimeType(exension);
//如果是avi视频添加到视频待处理表
if(mimeType.equals("video/x-msvideo")){
MediaProcess mediaProcess = new MediaProcess();
BeanUtils.copyProperties(mediaFiles,mediaProcess);
mediaProcess.setStatus("1");//未处理
mediaProcess.setFailCount(0);//失败次数默认为0
mediaProcessMapper.insert(mediaProcess);
}
}
修改文件信息入库的方法,在方法内部调用上面的添加待处理任务的方法
@Transactional
public MediaFiles addMediaFilesToDb(Long companyId, String fileMd5, UploadFileParamsDto uploadFileParamsDto, String bucket, String objectName) {
//从数据库查询文件
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
//拷贝基本信息
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
mediaFiles.setId(fileMd5);
mediaFiles.setFileId(fileMd5);
mediaFiles.setCompanyId(companyId);
//媒体类型
mediaFiles.setUrl("/" + bucket + "/" + objectName);
mediaFiles.setBucket(bucket);
mediaFiles.setFilePath(objectName);
mediaFiles.setCreateDate(LocalDateTime.now());
mediaFiles.setAuditStatus("002003");
mediaFiles.setStatus("1");
//保存文件信息到文件表
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert < 0) {
log.error("保存文件信息到数据库失败,{}", mediaFiles.toString());
XueChengPlusException.cast("保存文件信息失败");
}
//添加到待处理任务表
addWaitingTask(mediaFiles);
log.debug("保存文件信息到数据库成功,{}", mediaFiles.toString());
}
return mediaFiles;
}
4.4 查询待处理任务
定义Mapper层接口:
public interface MediaProcessMapper extends BaseMapper<MediaProcess> {
/**
* @description 根据分片参数获取待处理任务
* @param shardTotal 分片总数
* @param shardindex 分片序号
* @param count 任务数
*/
@Select("select * from media_process t where t.id % #{shardTotal} = #{shardIndex} and (t.status = '1' or t.status = '3') and t.fail_count < 3 limit #{count}")
List<MediaProcess> selectListByShardIndex(@Param("shardTotal") int shardTotal,@Param("shardIndex") int shardIndex,@Param("count") int count);
}
定义Service层接口:
public interface MediaFileProcessService {
/**
* @description 获取待处理任务
* @param shardIndex 分片序号
* @param shardTotal 分片总数
* @param count 获取记录数
*/
public List<MediaProcess> getMediaProcessList(int shardIndex,int shardTotal,int count);
}
实现类:
@Slf4j
@Service
public class MediaFileProcessServiceImpl implements MediaFileProcessService {
@Autowired
MediaFilesMapper mediaFilesMapper;
@Autowired
MediaProcessMapper mediaProcessMapper;
@Override
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count) {
List<MediaProcess> mediaProcesses = mediaProcessMapper.selectListByShardIndex(shardTotal, shardIndex, count);
return mediaProcesses;
}
}
5、任务执行
5.1 分布式锁
synchronized(锁对象){
执行任务...
}
synchronized只能保证同一个虚拟机中多个线程去争抢锁。如果是多个执行器分布式部署,多个虚拟机共用一个锁,该锁已不属于某个虚拟机,而是分布式部署,由多个虚拟机所共享,这种锁叫分布式锁。
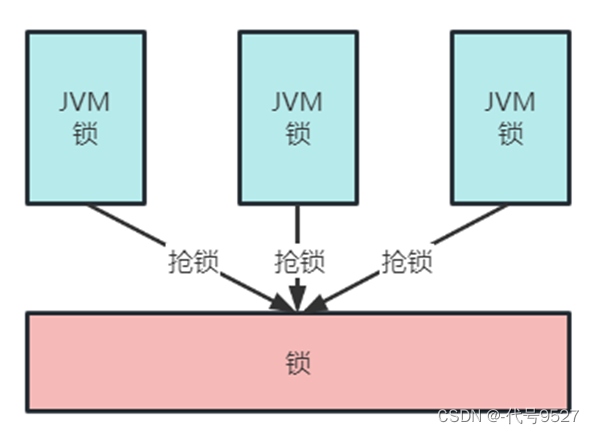
实现分布式锁可以:
- 基于数据库
- 基于Redis
- 基于zookeeper
5.2 开启任务
基于数据库实现,基本SQL是:
update media_process m set m.status='4' where m.id=?
引入乐观锁:
update media_process m
set m.status='4'
where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=?
这里的status字段和乐观锁常用的version一样的效果,不用再额外加version。
定义Mapper层:
public interface MediaProcessMapper extends BaseMapper<MediaProcess> {
/**
* 开启一个任务
* @param id 任务id
* @return 更新记录数
*/
@Update("update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=#{id}")
int startTask(@Param("id") long id);
}
Service层接口与实现:
/**
* 开启一个任务
* @param id 任务id
* @return true开启任务成功,false开启任务失败
*/
public boolean startTask(long id);
//实现如下
public boolean startTask(long id) {
int result = mediaProcessMapper.startTask(id);
return result<=0?false:true;
}
5.3 更新任务状态
任务处理完成需要更新任务处理结果,逻辑是:
- 任务执行成功更新视频的URL、及任务处理结果
- 将待处理任务记录删除,同时向历史任务表添加记录
Service层接口定义:(传参先写你能确定的,后续写实现类,缺什么传参再回来加)
/**
* @description 保存任务结果
* @param taskId 任务id
* @param status 任务状态
* @param fileId 文件id
* @param url url
* @param errorMsg 错误信息
* @return void
*/
void saveProcessFinishStatus(Long taskId,String status,String fileId,String url,String errorMsg);
实现类:
@Slf4j
@Service
public class MediaFileProcessServiceImpl implements MediaFileProcessService {
@Autowired
MediaFilesMapper mediaFilesMapper;
@Autowired
MediaProcessMapper mediaProcessMapper;
@Autowired
MediaProcessHistoryMapper mediaProcessHistoryMapper;
@Transactional
@Override
public void saveProcessFinishStatus(Long taskId, String status, String fileId, String url, String errorMsg) {
//查出任务,如果不存在则直接返回
MediaProcess mediaProcess = mediaProcessMapper.selectById(taskId);
if(mediaProcess == null){
return ;
}
//处理失败,更新任务处理结果
LambdaQueryWrapper<MediaProcess> queryWrapperById = new LambdaQueryWrapper<MediaProcess>().eq(MediaProcess::getId, taskId);
//处理失败
if(status.equals("3")){
MediaProcess mediaProcess_u = new MediaProcess();
mediaProcess_u.setStatus("3");
mediaProcess_u.setErrormsg(errorMsg);
mediaProcess_u.setFailCount(mediaProcess.getFailCount()+1);
mediaProcessMapper.update(mediaProcess_u,queryWrapperById);
log.debug("更新任务处理状态为失败,任务信息:{}",mediaProcess_u);
return ;
}
//任务处理成功
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileId);
if(mediaFiles!=null){
//更新媒资文件中的访问url
mediaFiles.setUrl(url);
mediaFilesMapper.updateById(mediaFiles);
}
//处理成功,更新url和状态
mediaProcess.setUrl(url);
mediaProcess.setStatus("2");
mediaProcess.setFinishDate(LocalDateTime.now());
mediaProcessMapper.updateById(mediaProcess);
//添加到历史记录
//这里直接new同结构表的对象后copyProperties
MediaProcessHistory mediaProcessHistory = new MediaProcessHistory();
BeanUtils.copyProperties(mediaProcess, mediaProcessHistory);
mediaProcessHistoryMapper.insert(mediaProcessHistory);
//删除mediaProcess
mediaProcessMapper.deleteById(mediaProcess.getId());
}
@Override
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count) {
List<MediaProcess> mediaProcesses = mediaProcessMapper.selectListByShardIndex(shardTotal, shardIndex, count);
return mediaProcesses;
}
}
5.4 视频处理
视频采用并发处理,每个视频使用一个线程去处理,每次处理的视频数量不要超过cpu核心数。
所有视频处理完成结束本次执行,为防止代码异常出现无限期等待则添加超时设置,到达超时时间还没有处理完成仍结束任务。
@Slf4j
@Component
public class VideoTask {
@Autowired
MediaFileService mediaFileService;
@Autowired
MediaFileProcessService mediaFileProcessService;
@Value("${videoprocess.ffmpegpath}")
String ffmpegpath;
@XxlJob("videoJobHandler")
public void videoJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
List<MediaProcess> mediaProcessList = null;
int size = 0;
try {
//取出cpu核心数作为一次处理数据的条数
int processors = Runtime.getRuntime().availableProcessors();
//一次处理视频数量不要超过cpu核心数
mediaProcessList = mediaFileProcessService.getMediaProcessList(shardIndex, shardTotal, processors);
size = mediaProcessList.size();
log.debug("取出待处理视频任务{}条", size);
if (size < 0) {
return;
}
} catch (Exception e) {
e.printStackTrace();
return;
}
//启动size个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(size);
//计数器
CountDownLatch countDownLatch = new CountDownLatch(size);
//将处理任务加入线程池
mediaProcessList.forEach(mediaProcess -> {
threadPool.execute(() -> {
try {
//任务id
Long taskId = mediaProcess.getId();
//抢占任务
boolean b = mediaFileProcessService.startTask(taskId);
if (!b) {
return;
}
log.debug("开始执行任务:{}", mediaProcess);
//下边是处理逻辑
//桶
String bucket = mediaProcess.getBucket();
//存储路径
String filePath = mediaProcess.getFilePath();
//原始视频的md5值
String fileId = mediaProcess.getFileId();
//原始文件名称
String filename = mediaProcess.getFilename();
//将要处理的文件下载到服务器上
File originalFile = mediaFileService.downloadFileFromMinIO(mediaProcess.getBucket(), mediaProcess.getFilePath());
if (originalFile == null) {
log.debug("下载待处理文件失败,originalFile:{}", mediaProcess.getBucket().concat(mediaProcess.getFilePath()));
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "下载待处理文件失败");
return;
}
//处理结束的视频文件
File mp4File = null;
try {
mp4File = File.createTempFile("mp4", ".mp4");
} catch (IOException e) {
log.error("创建mp4临时文件失败");
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "创建mp4临时文件失败");
return;
}
//视频处理结果
String result = "";
try {
//开始处理视频
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpegpath, originalFile.getAbsolutePath(), mp4File.getName(), mp4File.getAbsolutePath());
//开始视频转换,成功将返回success
result = videoUtil.generateMp4();
} catch (Exception e) {
e.printStackTrace();
log.error("处理视频文件:{},出错:{}", mediaProcess.getFilePath(), e.getMessage());
}
if (!result.equals("success")) {
//记录错误信息
log.error("处理视频失败,视频地址:{},错误信息:{}", bucket + filePath, result);
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, result);
return;
}
//将mp4上传至minio
//mp4在minio的存储路径
String objectName = getFilePath(fileId, ".mp4");
//访问url
String url = "/" + bucket + "/" + objectName;
try {
mediaFileService.addMediaFilesToMinIO(mp4File.getAbsolutePath(), "video/mp4", bucket, objectName);
//将url存储至数据,并更新状态为成功,并将待处理视频记录删除存入历史
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "2", fileId, url, null);
} catch (Exception e) {
log.error("上传视频失败或入库失败,视频地址:{},错误信息:{}", bucket + objectName, e.getMessage());
//最终还是失败了
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "处理后视频上传或入库失败");
}
}finally {
countDownLatch.countDown();
}
});
});
//等待,给一个充裕的超时时间,防止无限等待,到达超时时间还没有处理完成则结束任务
countDownLatch.await(30, TimeUnit.MINUTES);
}
private String getFilePath(String fileMd5,String fileExt){
return fileMd5.substring(0,1) + "/" + fileMd5.substring(1,2) + "/" + fileMd5 + "/" +fileMd5 +fileExt;
}
}
写实现类,逻辑复杂时先用注释写出你每一步要干啥,再用代码翻译。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146058.html

