

1、字典表的意义
假设有一个职员表:
| 姓名 | 性别 | 证件类型 | 学历 | 国籍 |
|---|---|---|---|---|
| 甲 | 男 | 身份证 | 本科 | 中国 |
| 乙 | 女 | 身份证 | 本科 | 中国 |
| … | … | … | … | … |
这个表有一亿条数据,现在用户要求证件类型要从”身份证”改为”居民身份证”,这样一下更新所有数据,能完成,但维护困难,由此,考虑这么实现:
| 代号 | 身份证类型 |
|---|---|
| 001 | 身份证 |
| 002 | 暂住证 |
加了这样一个身份证类型表后,职员表变为:
| 姓名 | 性别 | 证件类型 | 学历 | 国籍 |
|---|---|---|---|---|
| 甲 | 男 | 001 | 本科 | 中国 |
| 乙 | 女 | 001 | 本科 | 中国 |
| … | … | … | … | … |
此时把”身份证”改为”居民身份证”,只需改身份证类型表的一行数据的一个字段。但此时有新的问题了,国籍、学历也是可以枚举完的字段,那再加个学历类型表?显然不行,如果这种字段有十几个,那以后查询就要进行几十个表的联结(join)操作。先看实现:
系统代码表
| 标识 | 分类 |
内容 |
|---|---|---|
| 111 | Country | 中国 |
| 112 | Country | 美国 |
| …… | …… | …… |
| 001 | ID | 身份证 |
| 002 | ID | 暂住证 |
即加一个类型字段,以区分是具体哪个字段的。
2、若依的字典表结构
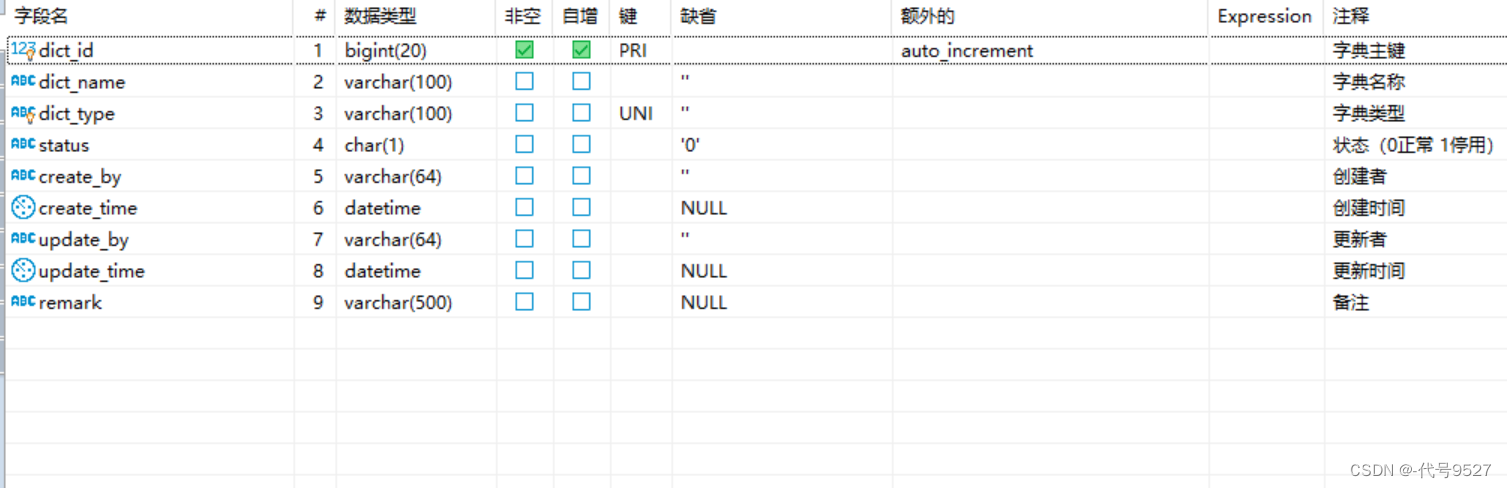
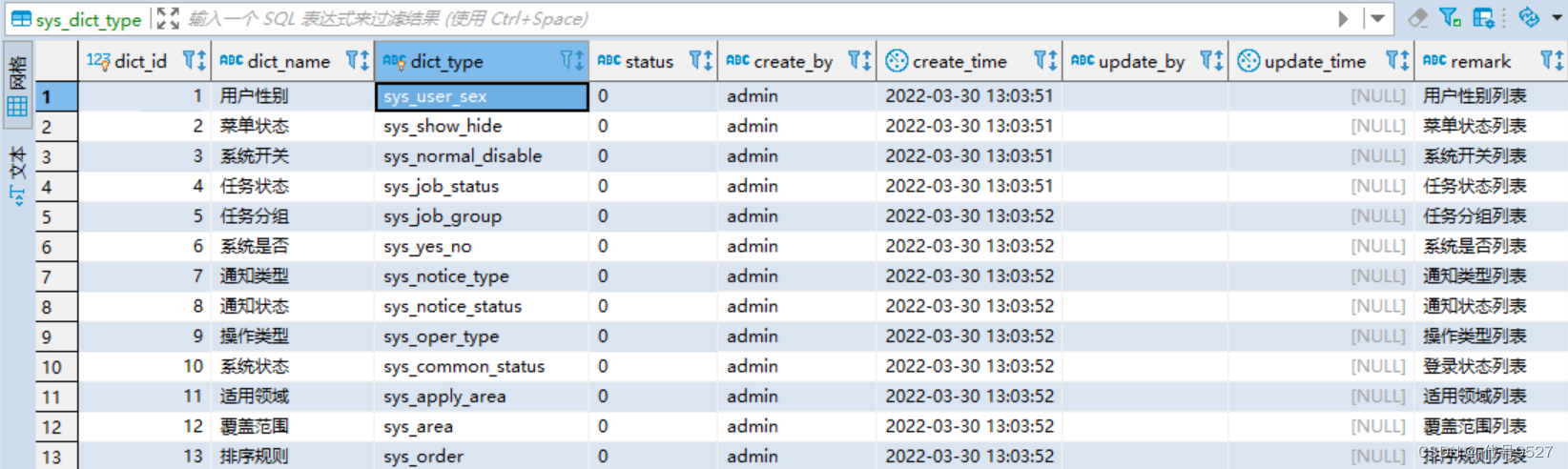
基于以上一个简单的背景,来看若依框架提供的字典表结构:ruoyi有两张字典相关表,一个字典类型表sys_dict_type,一个字典数据表sys_dict_data,将字典定义和数据分开。先看字典类型表:
再看字典数据表:
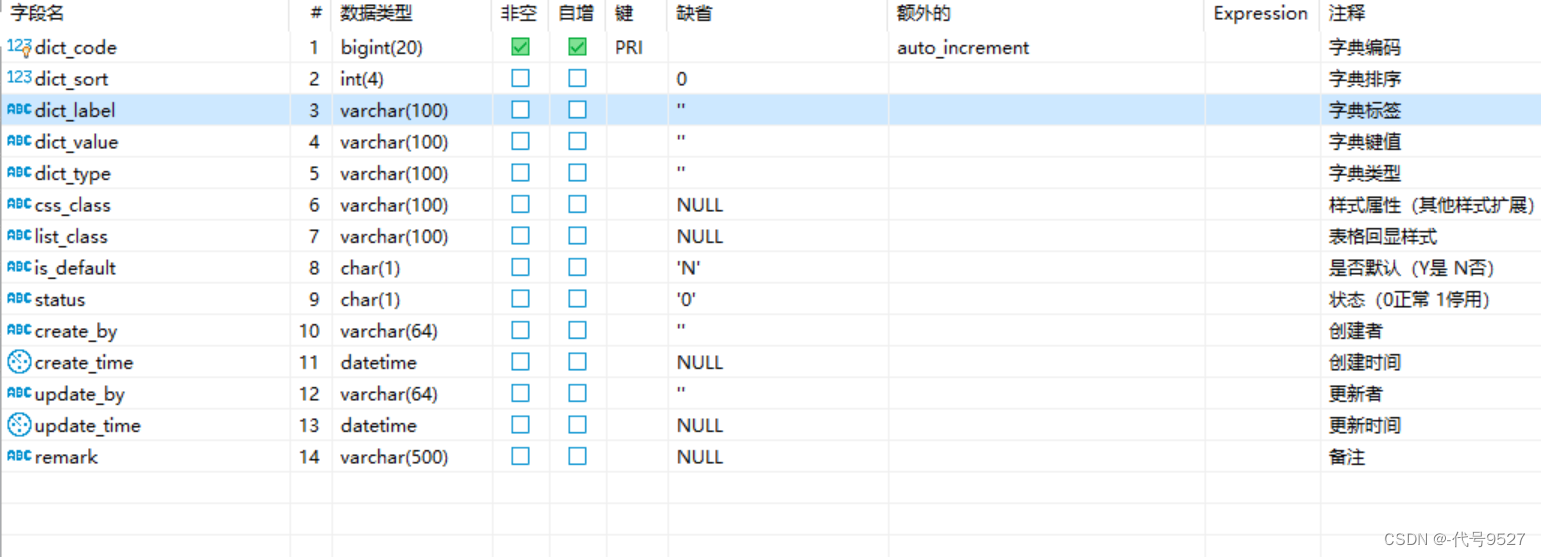
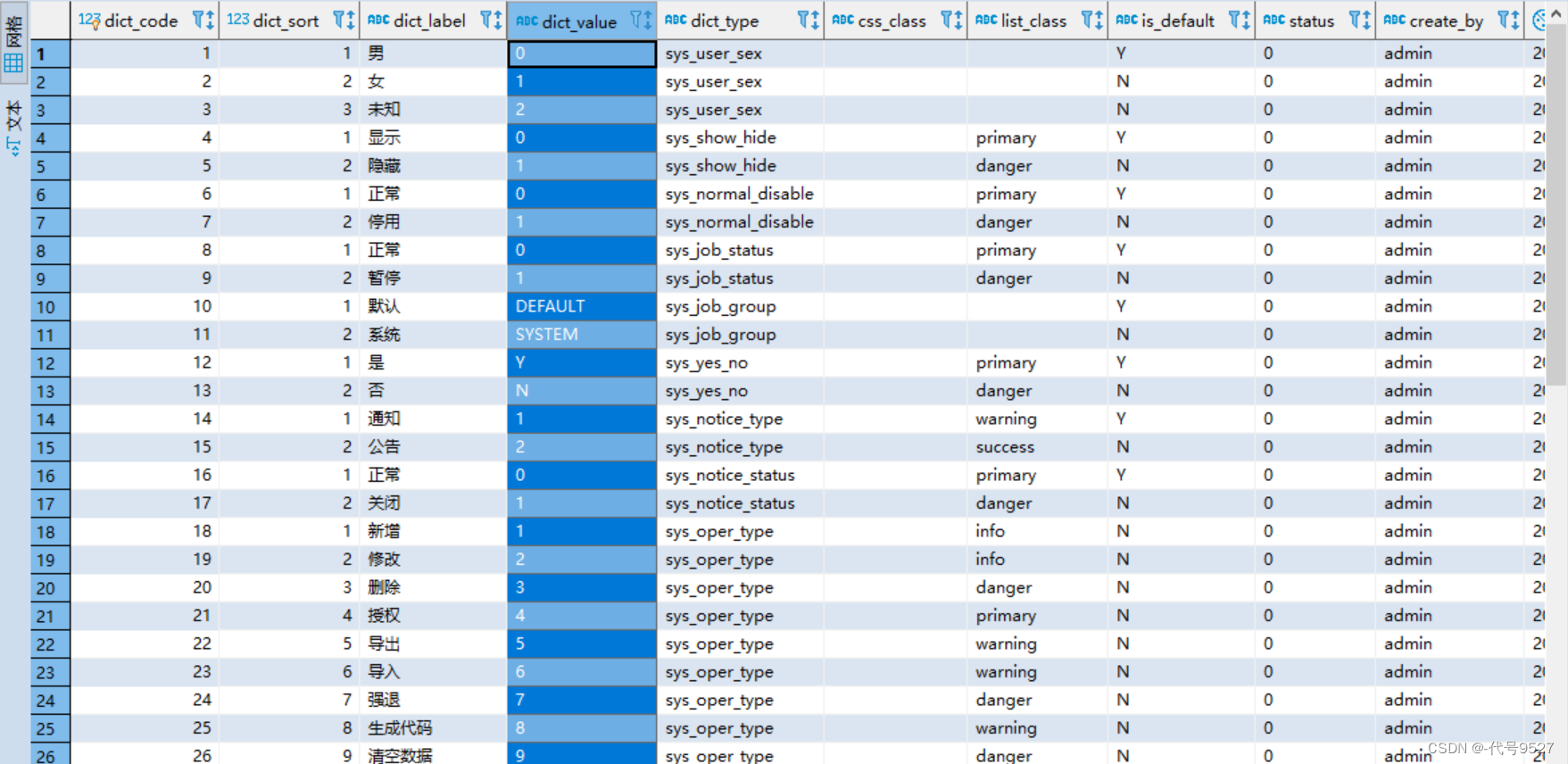
- 两张表通过字典类型字段dict_type关联
- 字典数据表中有
顺序字段dict_sort,可调整枚举对应显示顺序 - 字典数据表有键和值字段,页面显示值dict_label,数据库中存代号dict_value
- 两张表都有status字段控制整条数据是否可用
字典数据表支持层级也是一个要考虑的点,如下面这个需求:
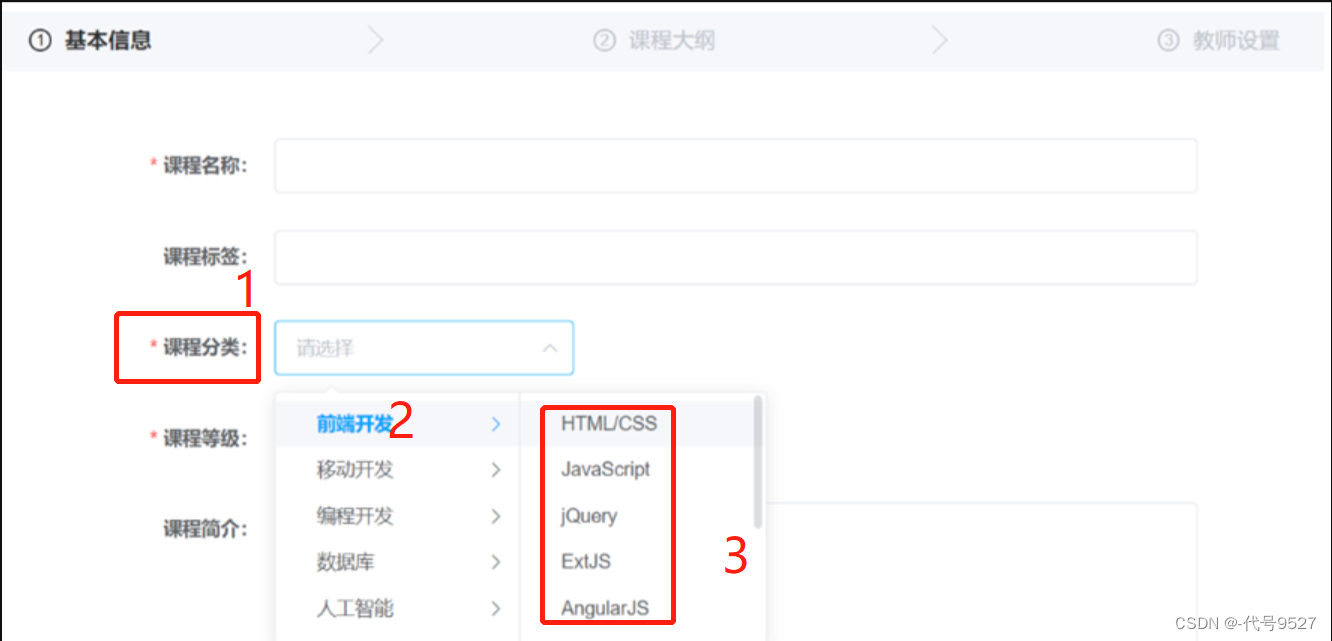
此时,可以增加一个parent_id可以在数据表中递归查询所有的层级数据:
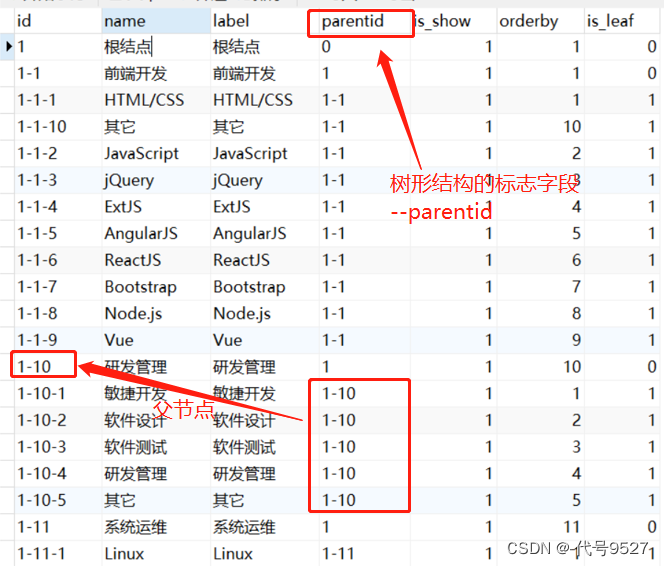
这个需求的实现,参考:https://blog.csdn.net/llg___/article/details/129683540
3、ruoyi枚举类
字典中定义好数据了,再写一个对应于dict_type的枚举类,枚举类中定义值,方便后面代码中调用枚举值做业务处理。以ruoyi的审核状态字典为例:

枚举类定义:
import brave.internal.Nullable;
import java.util.HashMap;
import java.util.Map;
public enum AuditStatusEnum {
BEFORE("before","待提交"),
WAIT("wait", "待审核"),
NO("no", "审核未通过"),
PASS("pass","审核通过");
String code;
String name;
AuditStatusEnum(String code, String name) {
this.code = code;
this.name = name;
}
private static final Map<String, AuditStatusEnum> mappings = new HashMap<>(5);
static {
for (AuditStatusEnum statusEnum : values()) {
mappings.put(statusEnum.code, statusEnum);
}
}
public String getCode(){
return code;
}
public String getName(){
return name;
}
@Nullable
public static AuditStatusEnum resolve(@Nullable String code) {
return (code != null ? mappings.get(code) : null);
}
}
- values()方法作用是获取枚举成员的所有值,返回一个数组
- 写静态代码块,以枚举值的code为键,以枚举值本身为值创建Map集合
- 最后的静态方法resolve()则是根据枚举值的code查询枚举值
- 这里是利用了Java类加载的时机之一:访问类的静态方法,执行静态代码块,初始化Map方便后面查询,妙!
关于Java类加载的时机,访问这里。
/定义了上面的字典对应的枚举类后,写业务逻辑代码:
if (xxDto.getAuditCode().equals(AuditStatusEnum.NO.getCode())){
return new MyException("审核未通过,不可操作!");
}
4、代码.ruoyi字典查询接口与缓存
定义接口,查询不同类型下的字典的key和value,给前端展示(当然前端也可以用html定义下拉框选项写死几个)
/**
* 根据字典类型查询字典数据信息
*/
@GetMapping(value = "/type/{dictType}")
public AjaxResult dictType(@PathVariable String dictType) {
return AjaxResult.success(dictTypeService.selectDictDataByType(dictType));
}
service层接口:
/**
* 根据字典类型查询字典数据
*
* @param dictType 字典类型
* @return 字典数据集合信息
*/
public List<SysDictData> selectDictDataByType(String dictType);
service接口实现类:这里是先在字典缓存中查,如果有,直接返回,如果缓存中没有,则调mapper层去数据库查,并把结果查询结果写进缓存备用
/**
* 根据字典类型查询字典数据
*
* @param dictType 字典类型
* @return 字典数据集合信息
*/
@Override
public List<SysDictData> selectDictDataByType(String dictType) {
List<SysDictData> dictDatas = DictUtils.getDictCache(dictType);
if (StringUtils.isNotNull(dictDatas)) {
return dictDatas;
}
dictDatas = dictDataMapper.selectDictDataByType(dictType);
if (StringUtils.isNotNull(dictDatas)) {
DictUtils.setDictCache(dictType, dictDatas);
return dictDatas;
}
return null;
}
获取字典缓存的方法定义:
/**
* 获取字典缓存
*
* @param key 参数键
* @return dictDatas 字典数据列表
*/
public static List<SysDictData> getDictCache(String key)
{
Object cacheObj = SpringUtils.getBean(RedisService.class).getCacheObject(getCacheKey(key));
if (StringUtils.isNotNull(cacheObj))
{
List<SysDictData> dictDatas = StringUtils.cast(cacheObj);
return dictDatas;
}
return null;
}
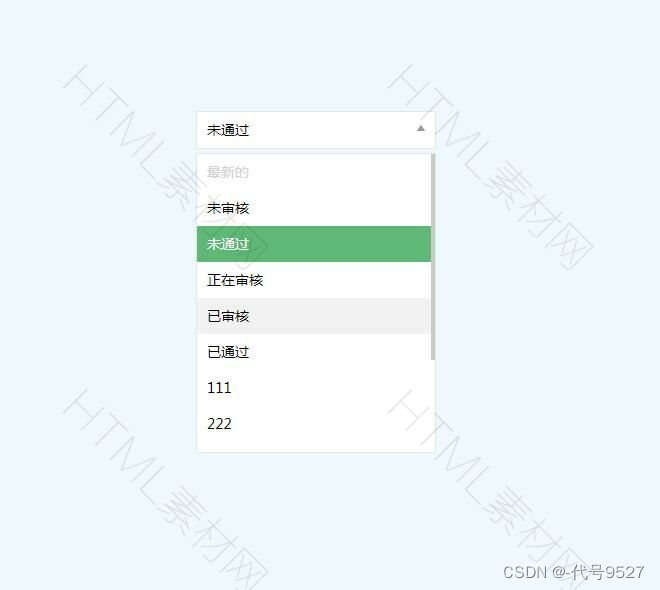
此时,前端调用接口,传入对应的dictType,即可拿到下拉框中的字典字段:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146068.html

