
要开始单独负责需求了,捋一捋表设计的思路。

一、MySQL中的数据类型
字符串类型
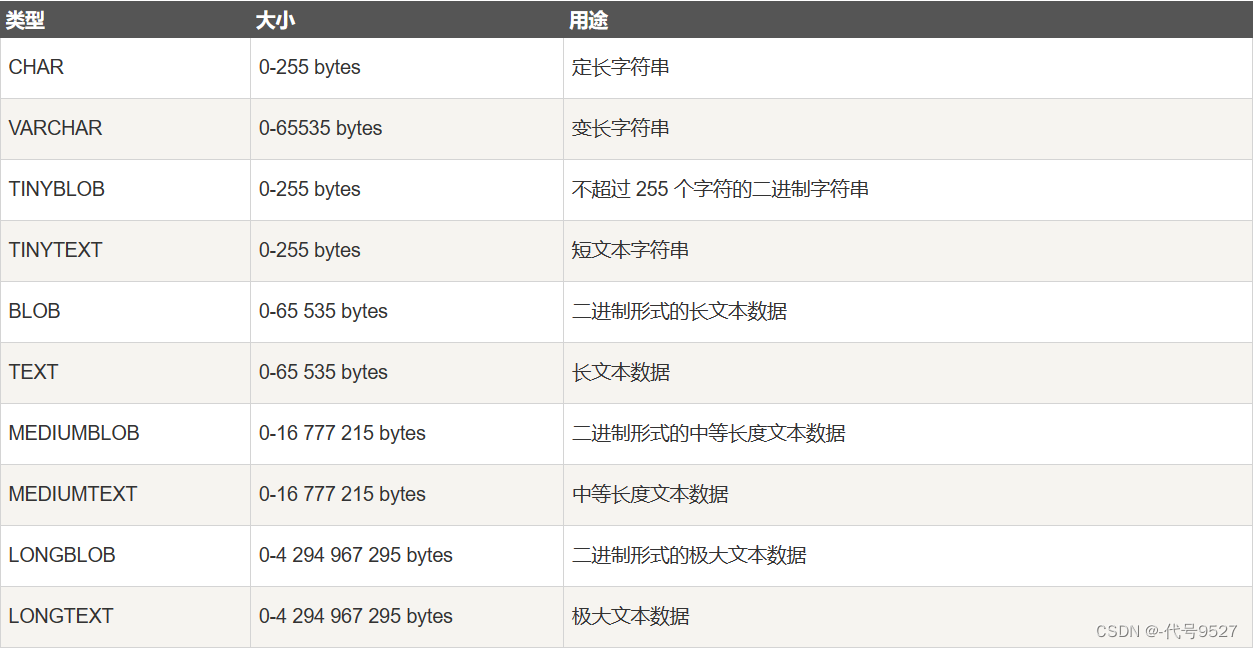
- varchar:即variable char ,可边长度的字符串,会根据实际数据的长度动态分配空间,以节省空间,如varchar(10)存jack,则只给4字节
- char:定长字符串,最大255
字符。不论实际数据长度都以定长空间存储,使用不当容易浪费空间 - char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数。
一个汉字字符存储要两字节,一个英文字符存储一个字节 - varchar要动态分配空间,故效率低于char。如果存性别等定长的,用char好,存人名、则varchar
日期和时间类型
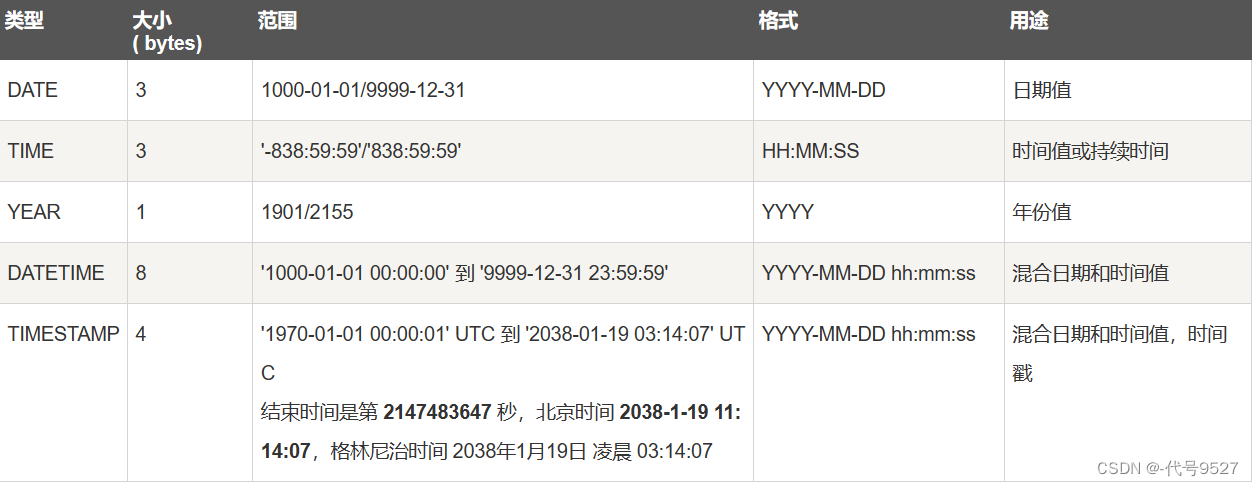
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR
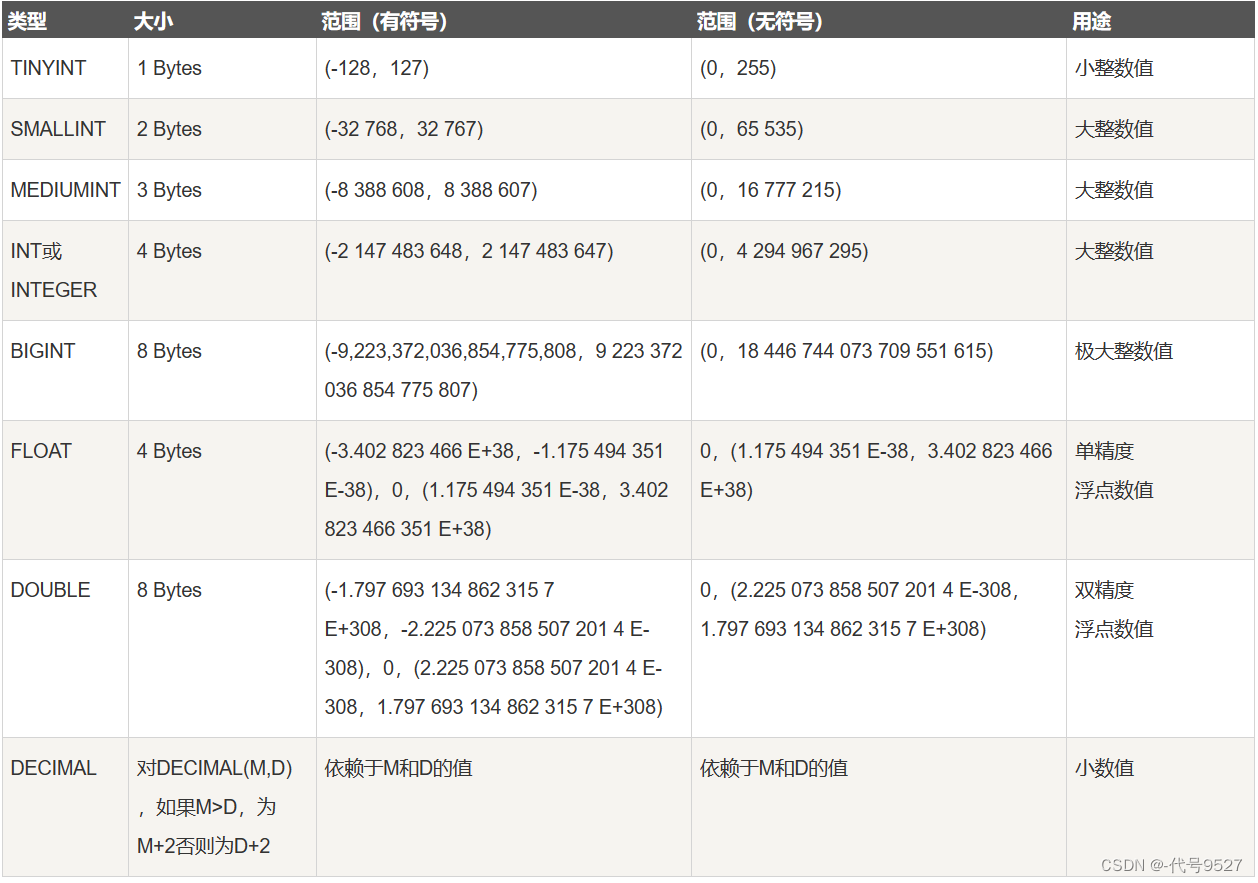
数值类型
二、一对一的关系设计
一张表A中的一条记录只能对应另一张表B中的一条记录,另一张表B中的一条记录也只能对应一张表A中的一条记录。如:学生表和学生卡表
设计思路:
- 把两个实体存在一张表中
- 分两张表且共享主键
学生表student
id name
1001 张三
1002 张四
学生卡表card
id name
1001 card1
1002 card2
此时查询张三信息:
SELECT
*
FROM
card c
WHERE
id='1001'
- 分两张表且加唯一外键。(加外键且这个外键要求不重复)
学生表student
id name
1001 张三
1002 张四
学生卡表card
id name stuent_id(设计表时给该字段添加唯一性约束)
111 card1 1001
222 card2 1002
此时查询张三的信息--
SELECT
*
FROM
card c
JOIN
student s
ON
c.student_id=s.id
WHERE
s.name='张三'
注意点:
- 字段较多时,
做好静态表和动态表的分离,静态表即存储着一些固定不变的资源,比如城市/地区名/国家。动态表:一些频繁修改的表,如年龄、体重
二、一对多的关系设计
一对多的关系很常见,如:一个部门对应多个员工、一个班级对应多个学生。E-R图:

设计思路:
- 在“多”关系的表中去维护一个字段,这个字段是“一”关系的主键。如员工与部门,就在员工表中加部门id字段
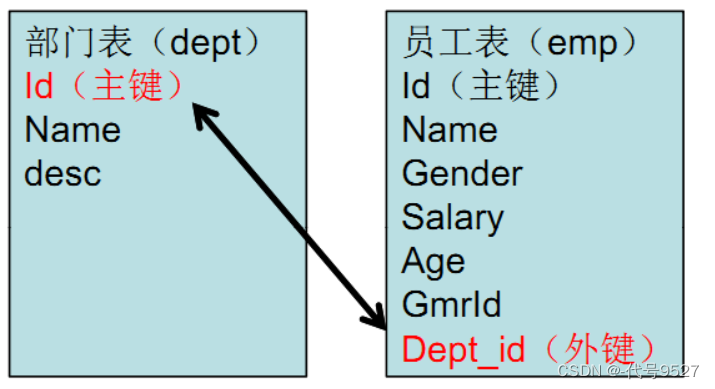

- 维护一个关联字段后,加不加外键约束看你的实际业务需求
注意点:
-
加外键约束,会保证数据业务上的一致性
-
不用外键时数据管理简单,操作方便,性能高(导入导出等操作,在insert, update, delete 数据的时候更快)
-
对于海量数据的场景,insert数百万条记录,当存在外键约束的时候,每次要去扫描此记录是否合格,性能就会大打折扣
三、多对多的关系设计
多对多的关系如:大学生与课程,一个大学生有多门课程,每个课程下有多个大学生,此时在哪个表中添加外键字段都不行,E-R图:

设计思路:
- 建立关系表
- 两个实体表和关系表之间,分别就成了一对多的关系
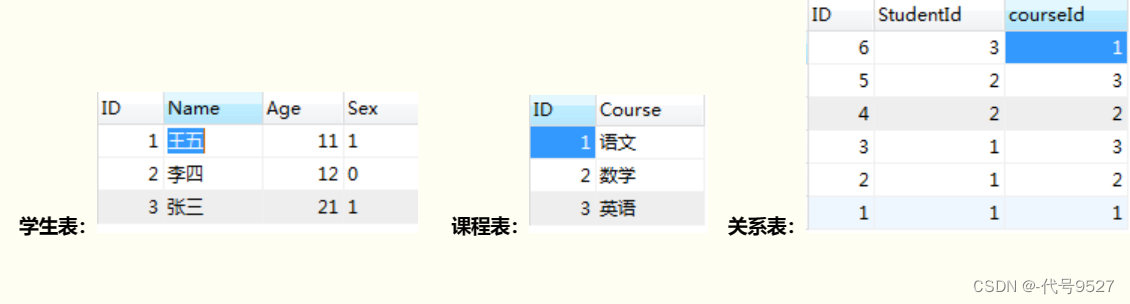
注意点:
- 添加数据时,先添加父表记录(student,course),再添加子表(student_course_relation)记录
- 删除数据时,先删除子表记录(student_course_relation),再删除父表记录(student,course)
- 查询时,内连接查询(等值连接、非等值连接、自连接)还是外连接查询(左外连接、右外连接)看业务选
/查询所有姓张的学生的id、name和所选课程的name:
SELECT
s.id, s.name, c.name
FROM
student s
JOIN
student_course_relation scr
ON
scr.student_id=s.id
JOIN
course c
ON
scr.course_id=c.id
WHERE
s.name LIKE '张%'
四、经验总结
-
一对多,两张表,多的表加外键. -
多对多,三张表,关系表加外键. -
命名规范,表名以t_或者tbl_开头,增加可读性,字段采用下划线命名,避免用保留字,如select、desc
-
主键索引名为pk_字段名,唯一索引名为uk_字段名,普通索引名为idx_字段名
-
数据类型选择时,金额类不能选择float、double,选decimal,防止精度丢失
-
主键的设计最好设业务主键,最好是一串无意义且不重复的数字,可采用UUID或者Auto_increment自增
-
数据库不要存储任何资源文件,比如照片/视频/网站等,可以用文件路径/外链用来代替
-
添加以下必需字段,如update_time、create_time

-
发现某个表的记录太多,例如超过一千万条,则要对该表进行水平分割。水平分割的做法是,以该表主键PK的某个值为界线,将该表的记录水平分割为两个表。若发现某个表的字段太多,例如超过八十个,则垂直分割该表,将原来的一个表分解为两个表
-
维护一字段表示该行记录是否可用,可起名为isVaild,预制的含义为0为有效,1为无效,也即逻辑删除
-
关于NULL和NOT NULL,NULL值的存储也需要空间,且可能导致索引失效,不影响业务的话建议
NOT NULL default -
索引建立太多,会降低写的速度,建议单表索引不要超过5个
-
除了MySQL中主键和unique字段自动添加索引,当数据量庞大,手动加索引时挑选字段的思路有:
。 该字段经常出现在where后面,以条件的形式存在,即该字段总被扫描
。该字段不会频繁DML,DML后,索引需要重新排序,而索引维护会降低系统性能 -
数据库三范式,只是一个规范,有时候数据冗余不一定就不好,这叫空间换时间
-
外键有好有坏,不加外键约束,在代码层校验业务逻辑也行
-
加注释comment,特别是枚举类型

-
要提高数据库的运行效率,考虑从三个级别下手:数据库系统级优化、数据库设计级优化、程序实现级优化
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146069.html

