
文章目录
- 一、流
- 二、常用方法
-
- 1、filter(element -> boolean表达式)
- 2、distinct()
- 3、sorted() / sorted((T, T) -> int)
- 4、limit(long n)
- 5、skip(long n)
- 6、`map(T -> R)`
- 7、`faltMap(T -> Stream)`
- 8、anyMatch(T -> boolean表达式)
- 9、allMatch(T -> boolean)和noneMatch(T -> boolean)
- 10、count()
- 11、reduce((T, T) -> T) / reduce(T, (T, T) -> T)
- 12、forEach()
- 13、Stream.iterate
- 三、收集方法collect()详解
- 四、并行流parallelStream
一、流
Java 8 API添加了一个新的抽象称为流Stream,将要处理的元素集合看作一种流, 流在管道中传输,能够对每个元素进行一系列并行或串行的流水线操作
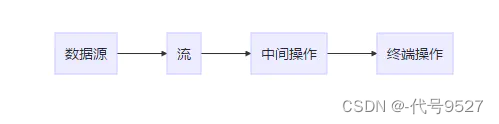

- 数据源可以是集合,数组,I/O channel, 产生器generato…
- 数据源如:List<T> 的集合转换为 Stream<T> 类型的流,然后进行中间操作如过滤、排序、遍历、类型转换
- 终端可以选择将 Stream 流转换回一个新类型的集合中,如果中间对每个元素操作后,你的目的已达到,最后转不转回都行
- 很多中间操作的方法返回类型就是Stream,因此可以直接连起来,如操作List<Person> list

- 流的操作不会改变原集合,除非用原集合接,即list = list.stream().xxx…
stream()− 为集合创建串行流- parallelStream() − 为集合创建并行流
二、常用方法
数据源:
List<String> stringList = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
public class Person{
String name;
Integer age;
}
List<Person> list = new ArrayList<>();
list.add(new Person("Jack",23));
list.add(new Person("Jack",23));
list.add(new Person("Tom",30));
1、filter(element -> boolean表达式)
作用:
- 过滤元素,符合Boolean表达式的留下来
示例:
//过滤,只要空字符串
NewList<String> list = stringList.stream()
.filter(param -> param.isEmpty())
.collect(Collectors.toList());
2、distinct()
作用:
- 去除重复元素
- 这个方法是
通过类的 equals 方法来判断两个元素是否相等的
示例:
list = list.stream()
.distinct().collect(Collectors.toList());
这里不重写Person类的equals方法,两个数据不会被处理
3、sorted() / sorted((T, T) -> int)
作用:
- 对流中的元素进行排序
- 若流中元素的类实现了Comparable接口,即有自己的排序规则,此时可直接sorted()
- 否则,用
sorted((T,T) -> int)说明排序规则
示例:
根据年龄大小来比较:
list = list.stream()
.sorted((p1, p2) -> p1.getAge() - p2.getAge())
.collect(Collectors.toList());
以上可优化为:
list = list.stream()
.sorted(Comparator.comparingInt(Person::getAge))
.collect(Collectors.toList());
4、limit(long n)
作用:
- 返回前n个元素
示例:
list = list.stream()
.limit(1)
.collect(Collectors.toList());
5、skip(long n)
作用:
- 去除前n个元素
- limit(m).skip(n),先返回前m个元素,再从这m个元素中去除n个
- skip(n).limit(m),先去除n个元素,再返回剩余的前m个
示例:
list = list.stream()
.limit(2)
.skip(1)
.collect(Collectors.toList());
//即先拿前两个,再去掉这两个中的第一个
6、map(T -> R)
作用:
- 将流中的每一个元素映射为R
示例:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list = list.stream().map(i -> i + 2).collect(Collectors.toList());
list.forEach(System.out::println);
//输出3、4、5
除了处理基本数据类型,也可修改对象,但最后记得return element;
list = list.stream()
.map(p -> {p.setAge(p.getAge() + 1);
p.setName(p.getName().equals("Tom")? "TomCat" : "Cat");
return p;})
.collect(Collectors.toList());
//对每个对象的属性进行定制操作
也可映射抽出对象的一部分属性,收集到一个新类型的集合中:
List<String> newlist = list.stream()
.map(Person::getName)
.collect(Collectors.toList());
List<Integer> newlist = list.stream()
.map(p -> p.getAge())
.collect(Collectors.toList());
map方法接受一个lambda表达式,这个表达式是一个函数,输入类型是集合元素的类型, 输出类型是任意类型 , 即你可以选择将元素映射为任意类型, 并对映射后的值做下一步处理.
it -> Integer.toString(it)
7、faltMap(T -> Stream)
当处理的是一个List<Person>,此时使用map方法,拿到的元素是一个个Person对象。当处理的是一个List<List<Person>>,此时使用map,拿到的是一个个list集合,此时想对每一个Person对象操作,就得用faltMap,flat,平铺的意思 .
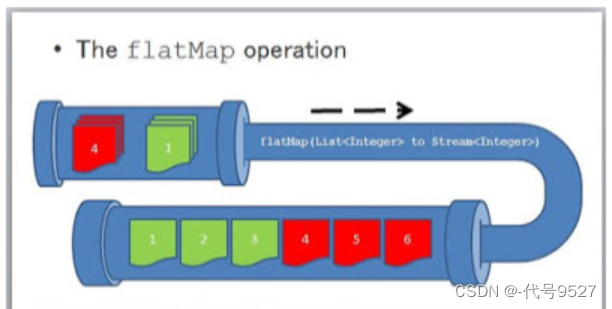
这个图很清晰的说明了flatMap的使用场景—流中的元素自身也是一个流(集合 . 数组)
常用写法:
xx.stream().flatMap(t -> t.stream()).xxx- 等价于
xx.stream().flatMap(Collection::stream).xx
举例:
List<Person> list1 = new ArrayList<>();
List<Person> list2 = new ArrayList<>();
list1.add(new Person("A",23));
list1.add(new Person("B",23));
list2.add(new Person("C",23));
list2.add(new Person("D",23));
List<List<Person>> listPlus = new ArrayList<>();
listPlus.add(list1);
listPlus.add(list2);
List<String> nameList = listPlus.stream()
.flatMap(t -> t.stream()) //此时流中元素为Person对象
.map(t -> t.getName())
.distinct()
.collect(Collectors.toList());
//A B C D
8、anyMatch(T -> boolean表达式)
作用:
- 流中是否有元素满足这个Boolean表达式
举例:
是否存在一个 person 对象的 age 等于 20:
boolean b = list.stream().anyMatch(person -> person.getAge() == 20);
9、allMatch(T -> boolean)和noneMatch(T -> boolean)
作用:
- allMatch(T -> boolean)即流中所有元素是否都满足Boolean条件
- noneMatch(T -> boolean)即是否流中没有一个元素满足Boolean表达式
10、count()
作用:
- 返回流中元素的个数,返回Long型
11、reduce((T, T) -> T) / reduce(T, (T, T) -> T)
作用:
- 组合流中的元素,进行求数学运算值
- 价格使用BigDecimal防止精度损失
计算年龄总和:
int sum = list.stream().map(Person::getAge).reduce(0, (a, b) -> a + b);
与之相同:
int sum = list.stream().map(Person::getAge).reduce(0, Integer::sum);
BigDecimal计算,将所有商品的价格累加
BigDecimal totalPrice = goodList.stream().map(GoodsCode::getPrice()).reduce(BigDecimal.ZERO, BigDecimal::add);
示例:
12、forEach()
普通for循环或者增强for循环,break跳出整个循环,continue跳出本次循环。stream()的forEach则不同:
- 处理集合时不能使用break和continue中止循环
- 可以使用
关键字return跳出本次循环,并执行下一次遍历 - 不能跳出整个流的forEach循环
//打印各个元素
list.stream().forEach(System.out::println);
也可对每个元素进行想要的操作:
list.stream().forEach(element -> {
java语句1;
java语句2;
}
);
13、Stream.iterate
作用:
指定一个常量seed,生成从seed到常量f(由UnaryOperator返回的值得到)的流。
Stream.iterate(0, n -> n + 1).limit(5).forEach(a -> {
System.out.println(a);
});
以上:根据起始值seed(0),每次生成一个指定递增值(n+1)的数,limit(5)用于截断流的长度,即只获取前5个元素。
输出:
0
1
2
3
4
三、收集方法collect()详解
作用:
- 收集流中元素的方法,传参是一个收集器接口, 常用写法:
.collect(Collectors.toList())收集到list集合.collect(Collectors.toMap(x,x,x))收集到map集合.collect(Collectors.groupingBy(xx))分组.collect(Collectors.counting())统计集合总数.collect(joining())连接字符串
1、.collect(Collectors.toMap(x,x,x))
Map<String,Person> newMap = lst.stream()
.collect(Collectors.toMap(p -> p.getName(), p -> p, (p1,p2) -> p1));
各个参数的意义:
- 第一个参数
p -> p.getName()即使用name做为Map集合的key - p -> p.getName()可以写成
Person::getName - 第二个参数
p -> p即将原来的对象做为map的value值,当然也可以Person::getAge继续用属性做value - 第三个参数
(p1,p2) -> p1即若p1、p2的key相同,则取p1的value
2、.collect(Collectors.groupingBy(xx))
作用: 将处理后的元素进行分组,得到一个Map集合
/数据准备
@Data
@AllArgsConstructor
public class Books {
private Integer id;
private Integer num;
private String name;
private Double price;
private String category;
}
Books book1 = new Books(1,100,"Java入门",60.0,"互联网类") ;
Books book2 = new Books(2,200,"Linux私房菜",100.0,"互联网类") ;
Books book3 = new Books(3,200,"Docker进阶",70.0,"互联网类") ;
Books book4 = new Books(4,600,"平凡的世界",200.0,"小说类") ;
Books book5 = new Books(5,1000,"白鹿原",190.0,"小说类") ;
List<Books> booksList = Lists.newArrayList(book1,book2,book3,book4,book5);
case1:按照某个属性分组, 即以该属性为Map集合的key,把这个属性相同的对象放在一个List集合中做为value
//按照category分类
Map<String,List<Books>> map = booksList.stream()
.collect(Collectors.groupingBy(Books::getCategory));
//run
{
互联网类=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类), Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)],
小说类=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类), Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)]
}
case2:按照某几个属性拼接分组
Map<String,List<Books>> map = booksList.stream()
.collect(Collectors.groupingBy(t -> t.getCategory() +"_" + t.getName()));
//run
{
互联网类_Linux私房菜=[Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类)],
小说类_平凡的世界=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类)],
互联网类_Docker进阶=[Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)],
互联网类_Java入门=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类)],
小说类_白鹿原=[Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)]
}
case3:按照不同的条件分组
//不同条件下,使用不同的key
Map<String,List<Books>> map = booksList.stream()
.collect(Collectors.groupingBy(t -> {
if(t.getNum() > 500){
return "数量充足";
}else{
return "数量较少";
}
}));
//run
{
数量充足=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类), Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)],
数量较少=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类), Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)]
}
case4:实现多级分组, 即由双参数版本的Collectors.groupingBy,对由第一个参数分类后的结果, 再进行分类,此时结果类型Map<String,Map<String,List<Books>>>
//接case3,想先按照类别分组,再给每个组按照数量再分一次
Map<String,Map<String,List<Books>>> map = booksList.stream()
.collect(Collectors.groupingBy(t -> t.getCategory(), Collectors.groupingBy( t -> {
if(t.getNum() > 100){
return "数量充足";
}else{
return "数量较少";
}
})));
//run
{
互联网类={数量充足=[Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)], 数量较少=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类)]},
小说类={数量充足=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类), Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)]}
}
case5:分组后,统计每个分组中元素的个数, Map集合的value类型为long型
Map<String,Long> map = booksList.stream()
.collect(Collectors.groupingBy(Books::getCategory,Collectors.counting()));
//run
{互联网类=3, 小说类=2}
case6:分组后,统计每个分组中元素的某属性的总和
Map<String,Integer> map = booksList.stream()
.collect(Collectors.groupingBy(Books::getCategory,Collectors.summingInt(Books::getNum)));
//run
{互联网类=500, 小说类=1600}
case7:加比较器取某属性最值
Map<String,Books> map3 = booksList.stream()
.collect(Collectors.groupingBy(Books::getCategory, Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Books::getNum)), Optional::get)));
//run
{互联网类=Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), 小说类=Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)}
case8:联合其他收集器
Map<String, Set<String>> map2 = booksList.stream()
.collect(Collectors.groupingBy(Books::getCategory,Collectors.mapping(t->t.getName(),Collectors.toSet())));
//run
{互联网类=[Linux私房菜, Docker进阶, Java入门], 小说类=[平凡的世界, 白鹿原]}
3 、.collect(joining())
作用:
- 拼接收集到的元素
- 传参为拼接时的连接符
String s = list.stream().map(Person::getName)
.collect(joining());
结果:jackmiketom
String s = list.stream().map(Person::getName)
.collect(joining(","));
结果:jack,mike,tom
四、并行流parallelStream
stream是串行的流式计算, parallelStream是并行的流式计算.
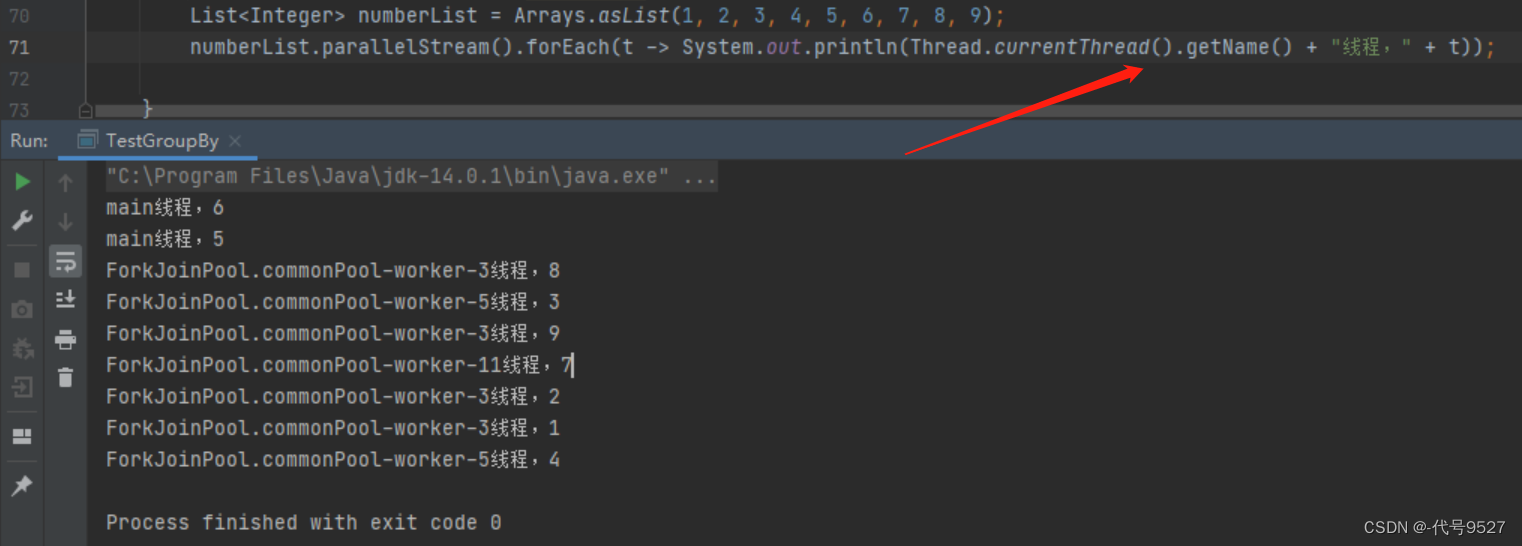
使用并行流遍历打印一个集合元素,并输出当前线程,可以看到线程抬头是ForkJoinPool.且遍历输出的元素是无序的
1、ForkJoin框架
- ForkJoin框架是java7中提供的并行执行框架
- 它的策略是分而治之。即将一个
大任务拆分为若干互不依赖的子任务,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务
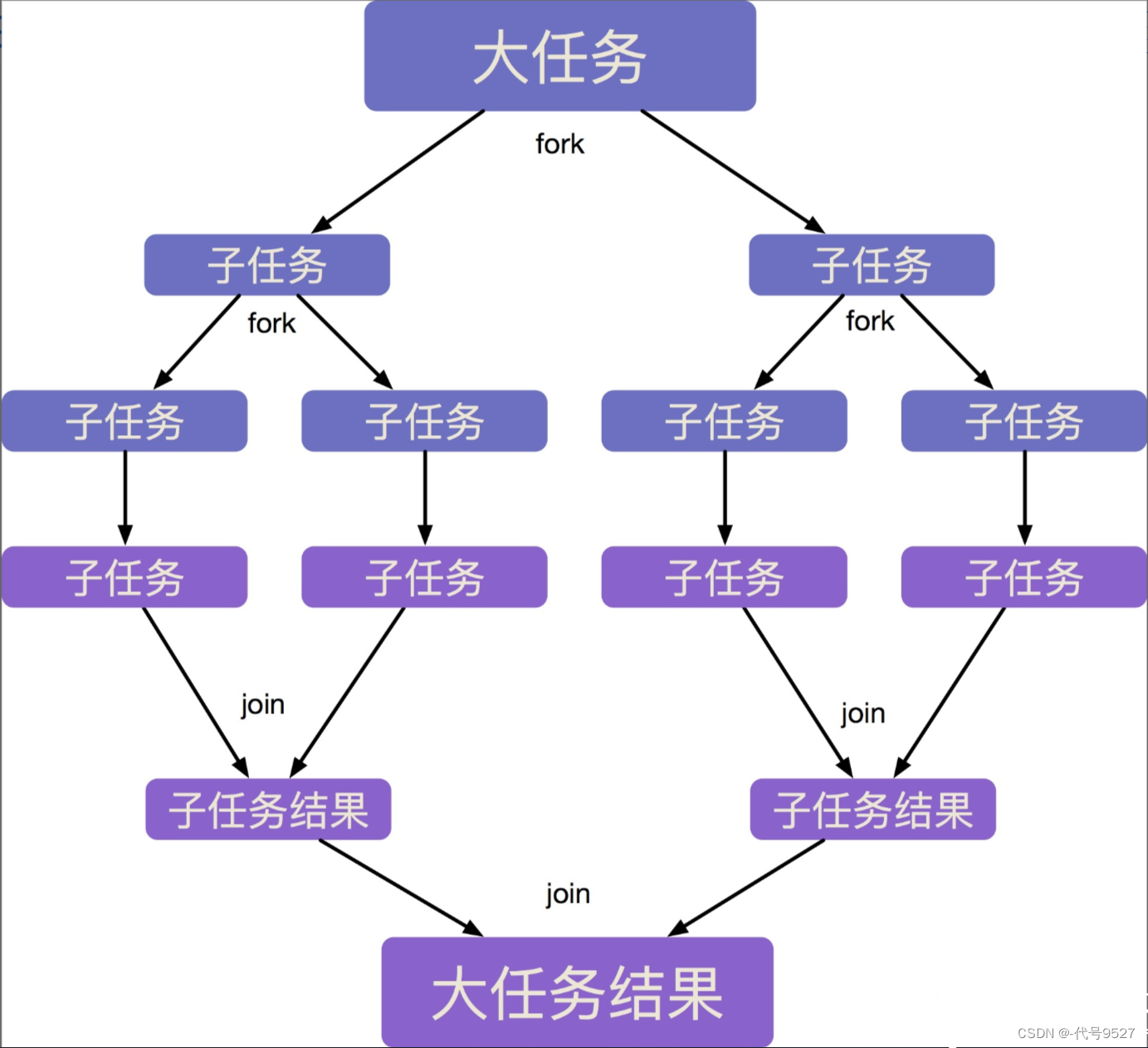
- 为了最大限度地提高并行处理能力,采用了
工作窃取算法来运行任务,也就是说当某个线程处理完自己工作队列中的任务后,尝试当其他线程的工作队列中窃取一个任务来执行,直到所有任务处理完毕。(类比自己的任务做完了, 帮同事分一点任务,以求最早完成总任务) - 为了减少线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行

2、parallelStream
- 调用ParallelStream() 和 Stream() 方法, 返回的都是一个流, 对forEach
- 并行流的创建可以
xx.parallelStream()或者xx.stream().parallel() - 并行流内部使用了默认的ForkJoinPool
- parallelStream默认的并发线程数比CPU处理器的数量少1个(最优的策略是每个CPU处理器分配一个线程,然而主线程也算一个线程)
// 获取当前机器CPU处理器的数量
System.out.println(Runtime.getRuntime().availableProcessors());// 输出 6
// parallelStream默认的并发线程数
System.out.println(ForkJoinPool.getCommonPoolParallelism());// 输出 5
// 设置全局并行流并发线程数
//这是全局配置,会影响所有的并行流
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "3");
-
parallelStream是线程不安全的
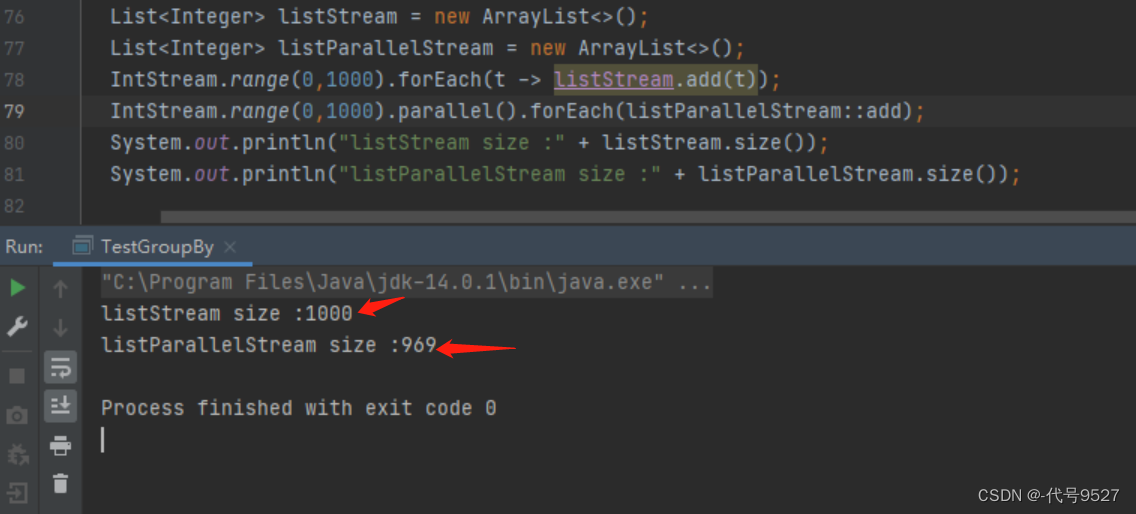
-
并发并不一定就能提高性能, CPU资源不足, 存在频繁的线程切换反而会降低性能
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146070.html

