
= = = =MyBatis整理= = = =
篇一.MyBatis环境搭建与增删改查
篇二.MyBatis查询与特殊SQL
篇三.自定义映射resultMap和动态SQL
篇四.MyBatis缓存和逆向工程
文章目录
1、自定义映射
若字段名和实体类的属性名不一致,则需要自定义映射。
P1:测试数据准备
员工表:
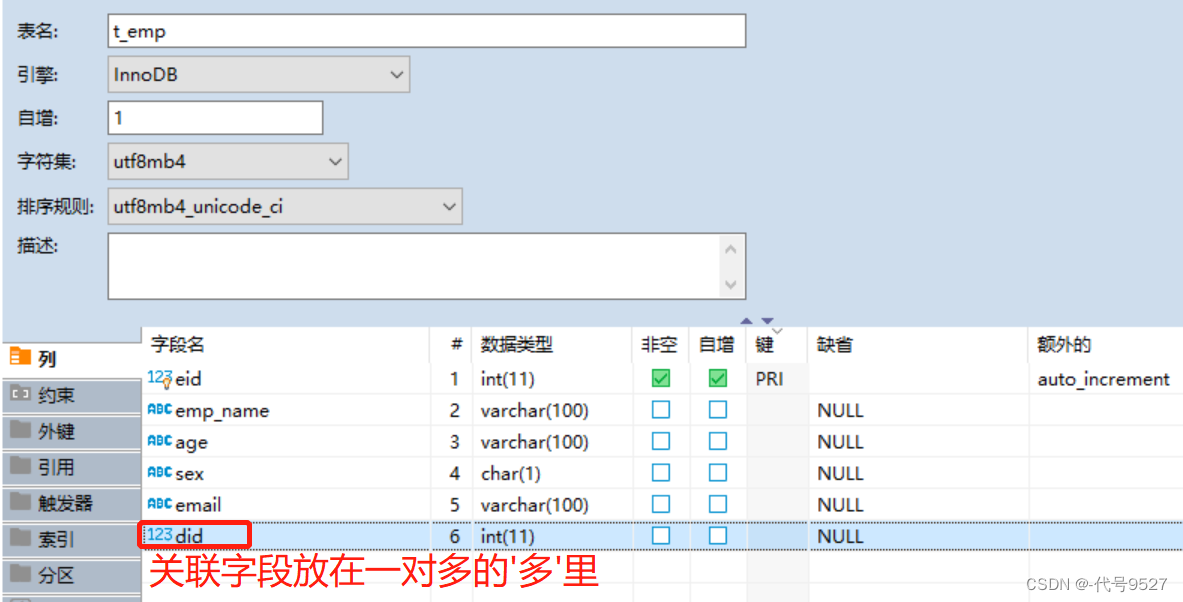
部门表:
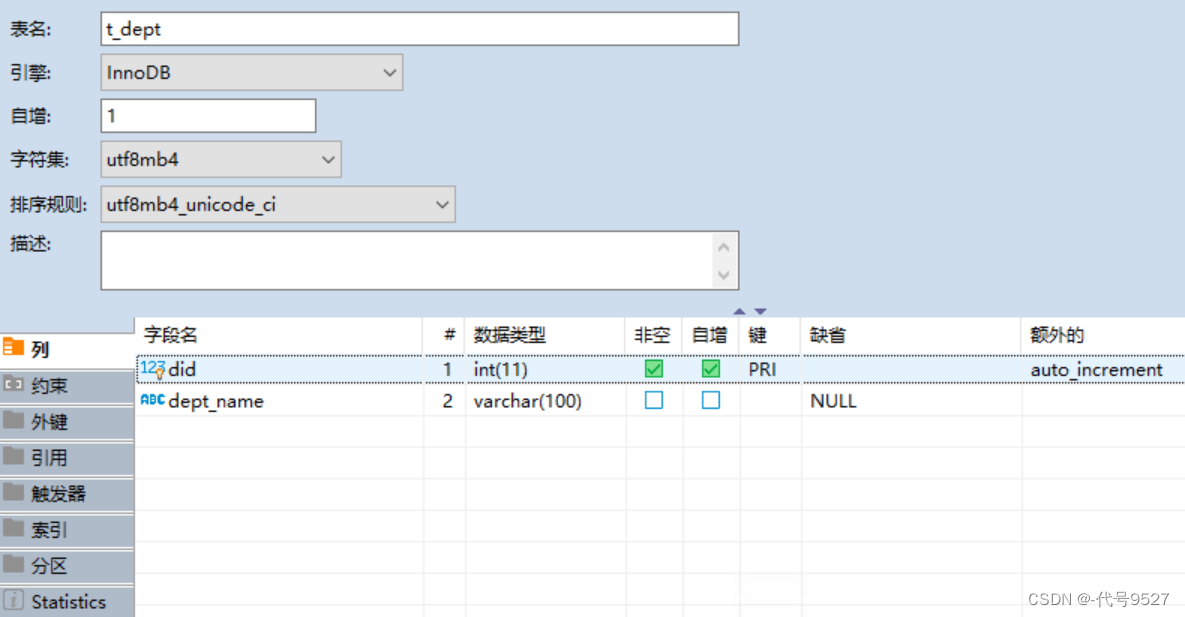
定义对应的实体类:(注意,字段名是下划线命名,属性名是驼峰命名,不再一致了)
定义Mapper接口和映射文件:
P2:字段和属性的映射关系
当字段名和实体类中的属性名不一致,但是字段名符合数据库的规则(使用_),实体类中的属性名符合Java的规则(使用驼峰),此时使用之前的自动映射resultType,则命名不一致的属性值为null,解决思路有三种:
思路一:给字段名起别名,使其和属性名保持一致
<!--List<Emp> getAllEmp();-->
<select id="getAllEmp" resultType="Emp">
select eid,emp_name empName,age,sex,email from t_emp
</select>
思路二:设置全局配置,将下划线_自动映射为驼峰
在核心配置文件mybatis-config.xml中:
<settings>
<!--将表中字段的下划线自动转换为驼峰-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!--注意这种只能转换规范命名,即emp_name映射为empName-->
此时,SQL语句正常写即可。
思路三:使用resultMap,不再使用之前的resultType做自动映射
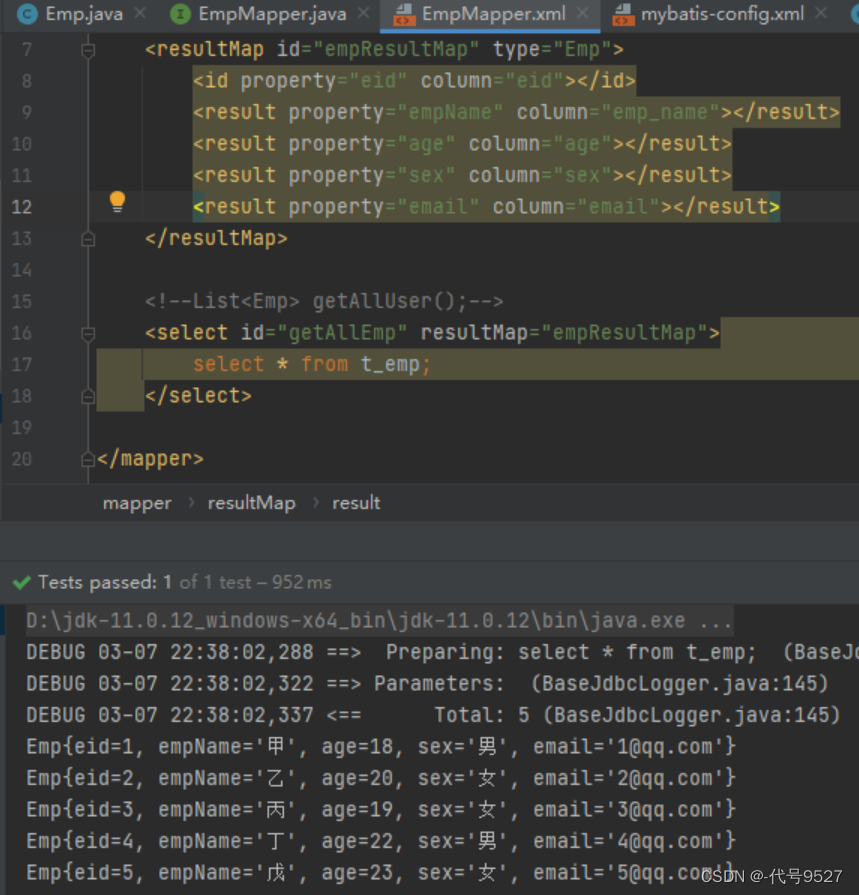
<resultMap id="empResultMap" type="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
</resultMap>
<!--List<Emp> getAllEmp();-->
<select id="getAllEmp" resultMap="empResultMap">
select * from t_emp
</select>
<!--注意别只写不一样的属性,一样的也得写一遍-->
resultMap即设置自定义映射关系:
- 属性:
。 id:我定义的映射的唯一标识,不能重复,给select标签中的resultMap属性用
。 type:查询的数据要映射的实体类的类型 - 子标签:
。 id:设置主键的映射关系
。 result:设置普通字段的映射关系 - 子标签属性:
。 property:设置映射关系中实体类中的属性名
。 column:设置映射关系中表中的字段名
运行结果:
P3:多对一的映射关系
多对一的时候,在’多’的这边设置,设置’一’所对应的对象;在’一’那边,设置’多’的对象集合 。处理多对一的映射关系(如查询企业员工信息及其部门)有三种实现方式:
public class Emp {
private Integer eid;
private String empName;
private Integer age;
private String sex;
private String email;
/**
* 这里设置'一'所对应的对象
*/
private Dept dept;
//...构造器、get、set方法等
}
思路一:使用级联属性赋值
<resultMap id="empAndDeptResultMapOne" type="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<result property="dept.did" column="did"></result>
<result property="dept.deptName" column="dept_name"></result>
</resultMap>
<!--Emp getEmpAndDept(@Param("eid")Integer eid);-->
<select id="getEmpAndDept" resultMap="empAndDeptResultMapOne">
select * from t_emp left join t_dept on t_emp.did = t_dept.did where t_emp.eid = #{eid}
</select>
思路二:通过association处理多对一的映射
- association:处理多对一映射关系
- property:需要处理多对一映射关系的属性名
- javaType:该属性的类型
<resultMap id="empAndDeptResultMapTwo" type="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<association property="dept" javaType="Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
</association>
</resultMap>
<!--Emp getEmpAndDept(@Param("eid")Integer eid);-->
<select id="getEmpAndDept" resultMap="empAndDeptResultMapTwo">
select * from t_emp left join t_dept on t_emp.did = t_dept.did where t_emp.eid = #{eid}
</select>
以上的逻辑是:在association中写要处理多对一关系的属性名dept,再说明该属性的Java类—->知道类型,通过反射拿到该类型的属性did和deptName—->将查询出来的字段赋值给属性—->Dept类的对象有了—->赋值给属性dept
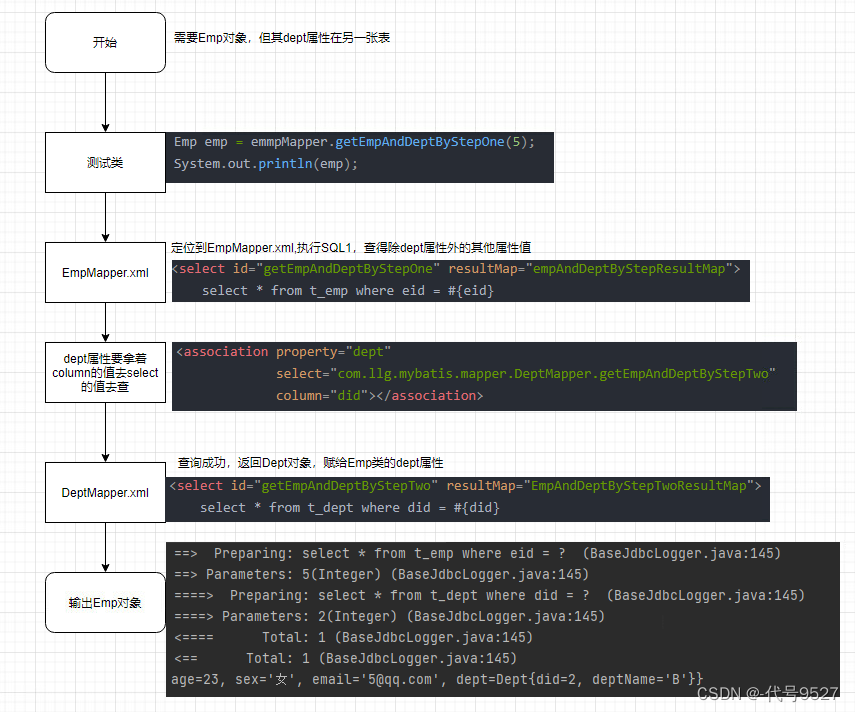
思路三:分步查询处理多对一的映射
先查询员工信息–>拿到部门id–>根据部门id查询部门信息—>将信息赋值给dept属性
引用属性--那个属性的值也是一个对象,丈夫是一个对象:
有姓名属性、年龄属性、妻子属性。妻子属性就是一个引用属性,里面是个对象,有它自己的属性
//EmpMapper里的方法
/**
* 通过分步查询,员工及所对应的部门信息
* 分步查询第一步:查询员工信息
*/
Emp getEmpAndDeptByStepOne(@Param("eid") Integer eid);
- property:即要处理多对一映射关系的属性名
select:即设置分布查询的sql的唯一标识(namespace.SQLId或mapper接口的全类名.方法名)column:设置分布查询的条件,要根据员工表的did去查询部门信息,即第二个SQL要根据什么去查
<resultMap id="empAndDeptByStepResultMap" type="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<association property="dept"
select="com.llg.mybatis.mapper.DeptMapper.getEmpAndDeptByStepTwo"
column="did"></association>
</resultMap>
<!--Emp getEmpAndDeptByStepOne(@Param("eid") Integer eid);-->
<select id="getEmpAndDeptByStepOne" resultMap="empAndDeptByStepResultMap">
select * from t_emp where eid = #{eid}
</select>
第二步:
//DeptMapper里的方法
/**
* 通过分步查询,员工及所对应的部门信息
* 分步查询第二步:通过did查询员工对应的部门信息
* 这里的查询结果要给Emp的dept属性赋值,所以返回类型Dept
*/
Dept getEmpAndDeptByStepTwo(@Param("did") Integer did);
<!--此处的resultMap仅是处理字段和属性的映射关系,不想写就开启setting后使用resultType-->
<resultMap id="EmpAndDeptByStepTwoResultMap" type="Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
</resultMap>
<!--Dept getEmpAndDeptByStepTwo(@Param("did") Integer did);-->
<select id="getEmpAndDeptByStepTwo" resultMap="EmpAndDeptByStepTwoResultMap">
select * from t_dept where did = #{did}
</select>
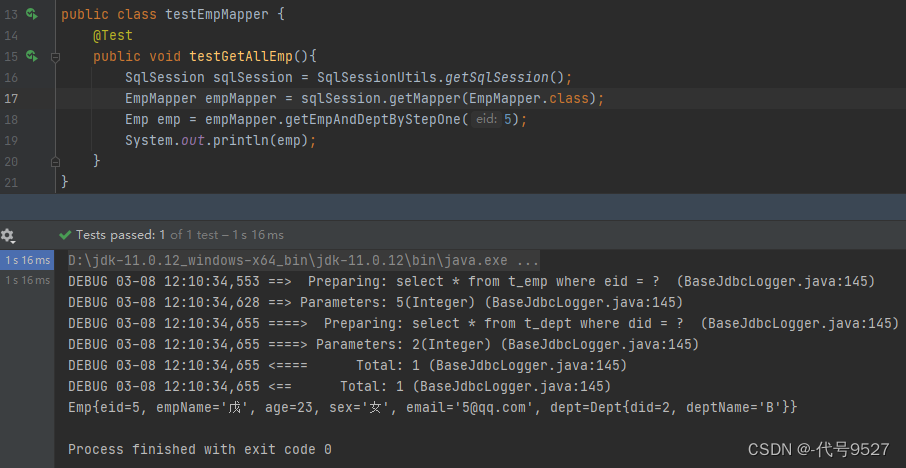
测试类:
@Test
public void testGetEmpAndDeptByStep() {
SqlSession sqlSession = SqlSessionUtils.getSqlSession();
EmpMapper empMapper = sqlSession.getMapper(EmpMapper.class);
Emp emp = emmpMapper.getEmpAndDeptByStepOne(5);
System.out.println(emp);
}
运行结果:
梳理下逻辑:
分步查询的好处–延迟加载
分步查询,实现一个功能分了两步,但这两步各自也是一个单独的功能。这就分步查询的好处—实现延迟加载
在核心配置文件中配置全局信息(setting标签):
- lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载
- aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。 否则,每个属性会按需加载
<settings>
<!--开启延迟加载-->
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
此时:我只获取员工名称,可以发现第二句SQL并未执行,这就是按需加载,获取的数据是什么,就只会执行相应的sql
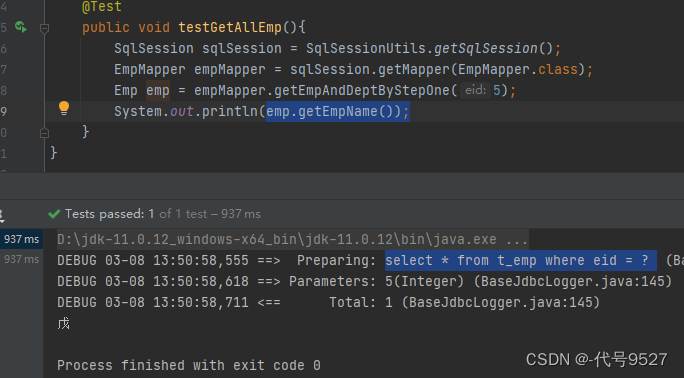
而当获取部门信息的时候,两句就都会执行。为了清晰看到效果,先关掉延迟加载,可以看到是两句SQL都执行完了,再拿数据:
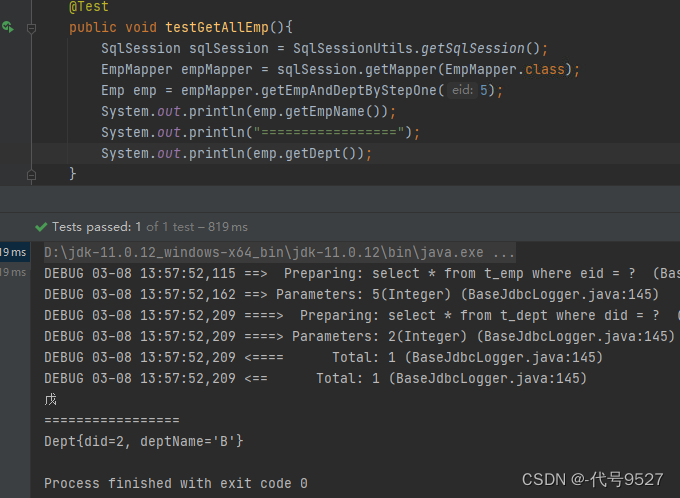
再开启延迟加载,可以看到是先执行了一句SQL,拿到了员工姓名,后面需要部门信息的时候,又执行了第二句SQL,这就是按需加载!!!
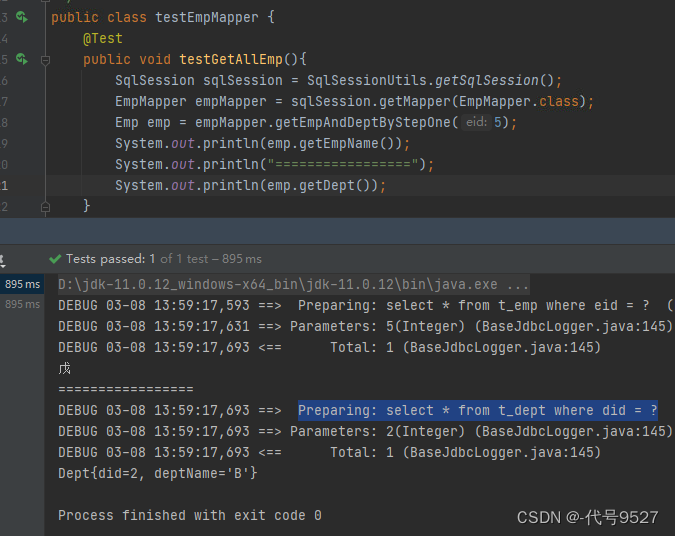
更改了全局设置,是否延迟加载则是对所有SQL的。当开启了全局的延迟加载(注意fetchType的前提是开启全局),要想单独控制某一个,可通过association和collection中的fetchType属性设置当前的分步查询是否使用延迟加载:
- fetchType=“lazy(延迟加载)”
- fetchType=“eager(立即加载)”
P4:一对多的映射关系
多对一的时候,在’多’的这边设置,设置’一’所对应的对象;在’一’那边,设置’多’的对象集合 。
public class Dept {
private Integer did;
private String deptName;
//'多'的类型的集合
private List<Emp> emps;
//...构造器、get、set方法等
}
思路一:使用collection
- collection:处理一对多的映射关系
- ofType:表示该属性所对应的集合中存储的数据的类型
public interface DeptMapper{
/**
* 查询部门即其下的所有员工信息
*/
Dept getDeptAndEmp(@Param("did") Integer did);
}
<resultMap id="DeptAndEmpResultMap" type="Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
<collection property="emps" ofType="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
</collection>
</resultMap>
<!--Dept getDeptAndEmp(@Param("did") Integer did);-->
<select id="getDeptAndEmp" resultMap="DeptAndEmpResultMap">
select * from t_dept left join t_emp on t_dept.did = t_emp.did where t_dept.did = #{did}
</select>
思路二:分步查询
第一步:
public interface DeptMapper{
/**
* 通过分步查询,查询部门及对应的所有员工信息
* 分步查询第一步:查询部门信息
*/
Dept getDeptAndEmpByStepOne(@Param("did") Integer did);
}
<resultMap id="DeptAndEmpByStepOneResultMap" type="Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
<collection property="emps"
select="com.llg.mybatis.mapper.EmpMapper.getDeptAndEmpByStepTwo"
column="did"></collection>
</resultMap>
<!--Dept getDeptAndEmpByStepOne(@Param("did") Integer did);-->
<select id="getDeptAndEmpByStepOne" resultMap="DeptAndEmpByStepOneResultMap">
select * from t_dept where did = #{did}
</select>
第二步:
public interface EmpMapper{
/**
* 通过分步查询,查询部门及对应的所有员工信息
* 分步查询第二步:根据部门id查询部门中的所有员工
*/
List<Emp> getDeptAndEmpByStepTwo(@Param("did") Integer did);
}
<!--List<Emp> getDeptAndEmpByStepTwo(@Param("did") Integer did);-->
<select id="getDeptAndEmpByStepTwo" resultType="Emp">
select * from t_emp where did = #{did}
</select>
结果:
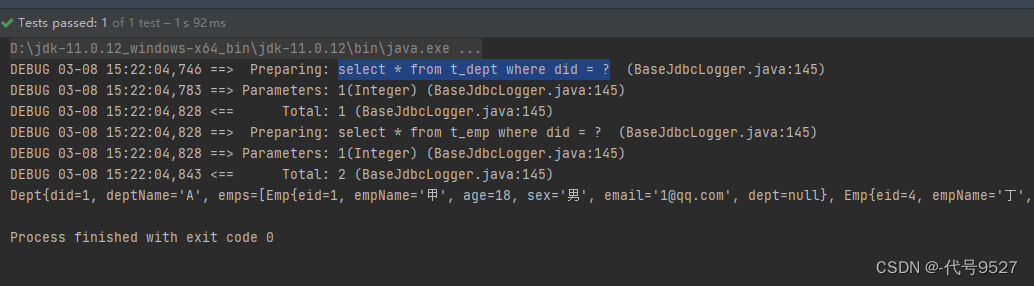
当然,分布查询在这儿也可以得到验证:
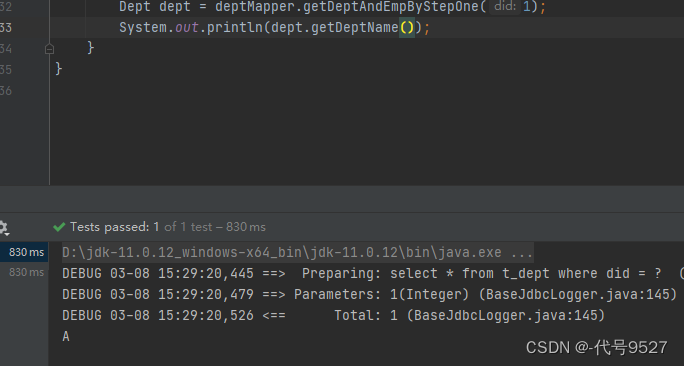
2、动态SQL
Mybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串时的痛点问题
2.1 IF标签
public interface DynamicSQLMapper{
/**
* 多条件查询
*/
List<Emp> getEmpByCondition(Emp emp);
}
- if标签可通过
test属性对表达式进行判断,若表达式的结果为true,则标签中的内容会拼接到SQL中,反之标签中的内容不会拼接。 - 在where后面添加一个
恒成立条件1=1,这个条件不会影响查询结果,而又可以很好的拼接后面的SQL:当empName传过来为空,select * from t_emp where and age = ? and sex = ? and email = ?,此时where与and连用,SQL语法错误
<!--List<Emp> getEmpByCondition(Emp emp);-->
<select id="getEmpByCondition" resultType="Emp">
select * from t_emp where 1=1
<if test="empName != null and empName !=''">
and emp_name = #{empName}
</if>
<if test="age != null and age !=''">
and age = #{age}
</if>
<if test="sex != null and sex !=''">
and sex = #{sex}
</if>
<if test="email != null and email !=''">
and email = #{email}
</if>
</select>
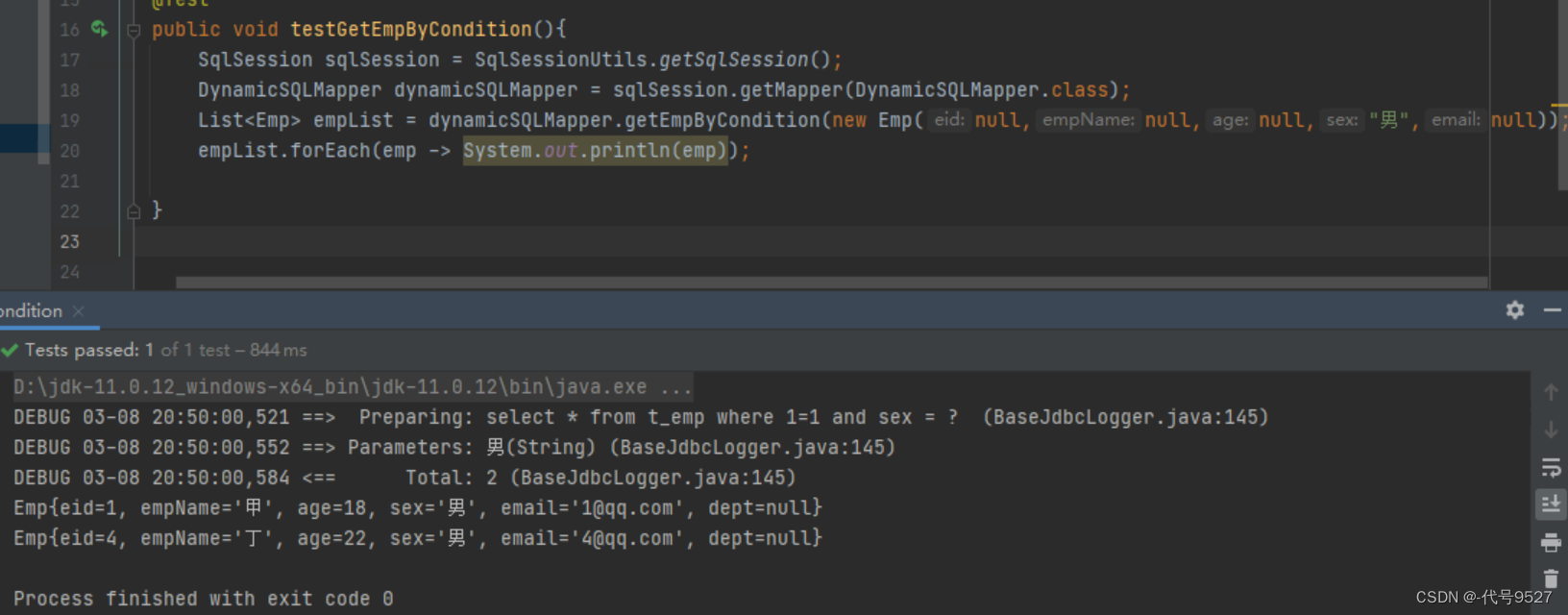
测试:
2.2 where标签
当where标签中有内容时,会自动生成where关键字,并将内容前多余的and或者or去掉,而当where标签中没内容时,where关键字也就不再生成。
<!--List<Emp> getEmpByCondition(Emp emp);-->
<select id="getEmpByCondition" resultType="Emp">
select * from t_emp
<where>
<if test="empName != null and empName !=''">
emp_name = #{empName}
</if>
<if test="age != null and age !=''">
and age = #{age}
</if>
<if test="sex != null and sex !=''">
and sex = #{sex}
</if>
<if test="email != null and email !=''">
and email = #{email}
</if>
</where>
</select>
where标签和if标签一般配合使用:
- 若where标签中的if条件都不满足,则where标签没有任何功能,即不会添加where关键字
- 若where标签中的if条件满足,则where标签会自动添加where关键字,并将条件最前方多余的and/or去掉
<!--这种用法是错误的,只能去掉条件前面的and/or,条件后面的不行-->
<if test="empName != null and empName !=''">
emp_name = #{empName} and
</if>
<if test="age != null and age !=''">
age = #{age}
</if>
当empName有值,age为空,则SQL为:
select * from d_emp where emp_name="llg" and
//此处where标签去不掉and了
2.3 trim标签
trim用于去掉或添加标签中的内容,当标签中有内容的时候:
- prefix:在trim标签中的内容的前面添加某些指定内容
- suffix:在trim标签中的内容的后面添加某些指定内容
- prefixOverrides:在trim标签中的内容的前面去掉某些指定内容
- suffixOverrides:在trim标签中的内容的后面去掉某些指定内容
当标签中没有内容的时候,trim标签也没有任何效果
<!--List<Emp> getEmpByCondition(Emp emp);-->
<select id="getEmpByCondition" resultType="Emp">
select * from t_emp
<trim prefix="where" suffixOverrides="and|or">
<if test="empName != null and empName !=''">
emp_name = #{empName} and
</if>
<if test="age != null and age !=''">
age = #{age} and
</if>
<if test="sex != null and sex !=''">
sex = #{sex} or
</if>
<if test="email != null and email !=''">
email = #{email}
</if>
</trim>
</select>
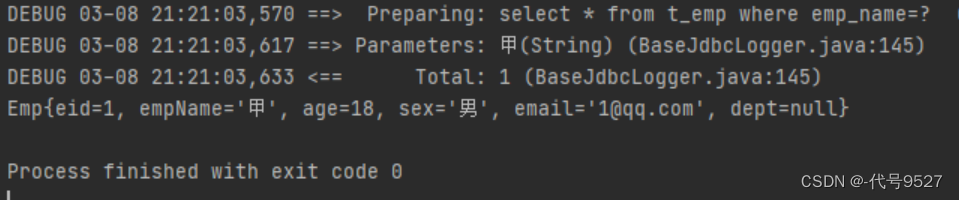
测试类:
//测试类
@Test
public void getEmpByCondition() {
SqlSession sqlSession = SqlSessionUtils.getSqlSession();
DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);
List<Emp> emps= mapper.getEmpByCondition(new Emp(null, "甲", null, null, null, null));
System.out.println(emps);
}
2.4 choose、when、otherwise标签
choose…when…otherwise相当于if…else if…else
- when即if或者else if,至少要有一个,when后面的test条件成立,则拼接
- otherwise相当于else,最多只能有一个
<select id="getEmpByChoose" resultType="Emp">
select * from t_emp
<where>
<choose>
<when test="empName != null and empName != ''">
emp_name = #{empName}
</when>
<when test="age != null and age != ''">
age = #{age}
</when>
<when test="sex != null and sex != ''">
sex = #{sex}
</when>
<when test="email != null and email != ''">
email = #{email}
</when>
<otherwise>
did = 1
</otherwise>
</choose>
</where>
</select>
<!--注意这里不用加and或者or了,没意义,if分支中一个就结束了-->
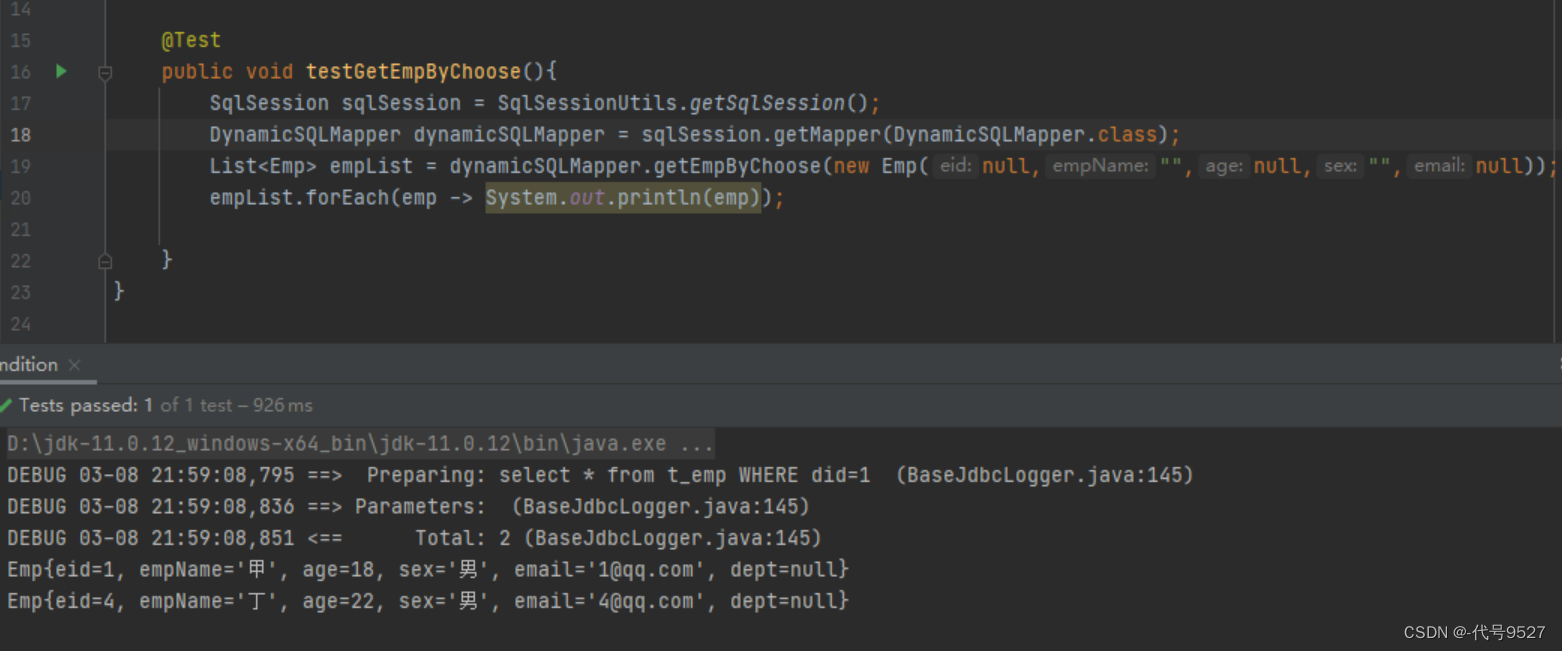
测试程序:
@Test
public void getEmpByChoose() {
SqlSession sqlSession = SqlSessionUtils.getSqlSession();
DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);
List<Emp> emps = mapper.getEmpByChoose(new Emp(null, "", null, "", "", null));
System.out.println(emps);
}
结果:
2.5 foreach标签
foreeach标签的属性有:
- collection:设置要循环的数组或集合
- item:表示集合或数组中的每一个数据
- separator:设置循环体之间的分隔符,分隔符前后默认有一个空格,如,
- open:设置foreach标签中的内容的开始符
- close:设置foreach标签中的内容的结束符
通过数组实现批量删除
public interface DynamicSQLMapper{
/**
* 通过数组实现批量删除
*/
int deleteMoreByArray(List<Integer> eids);
}
只论SQL,批量删除的实现可以通过以下两种写法:
delete from t_emp where eid in (6,7,8);
delte from t_emp where eid=6 or eid=7 or eid=8;
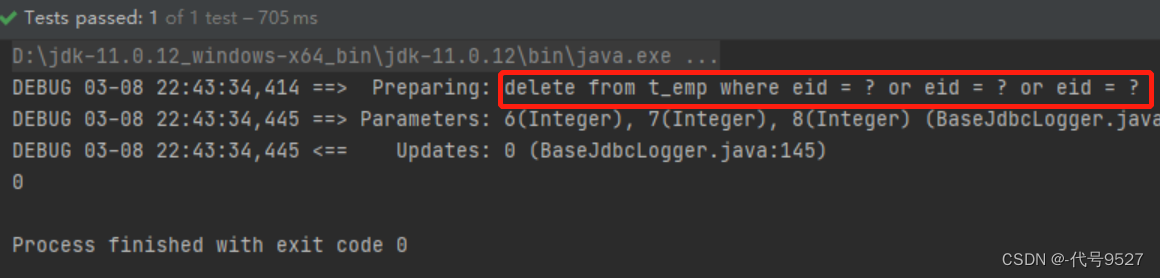
关于第一种SQL的实现:
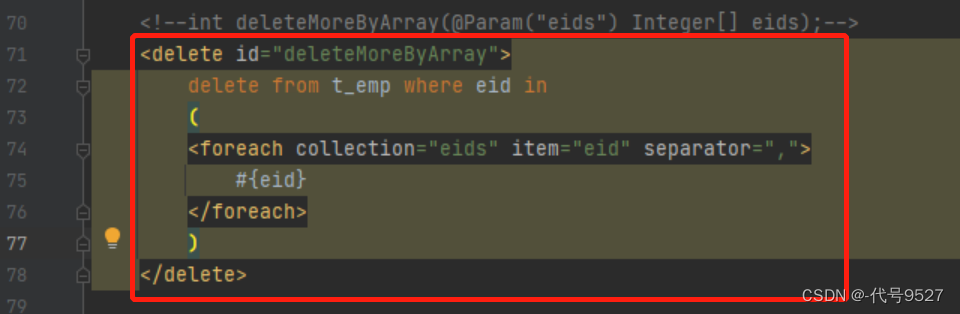
优化一下:
<!--int deleteMoreByArray(Integer[] eids);-->
<delete id="deleteMoreByArray">
delete from t_emp where
<foreach collection="eids" item="eid" separator="or">
eid = #{eid}
</foreach>
</delete>
关于第二种SQL的实现:
<!--int deleteMoreByArray(Integer[] eids);-->
<delete id="deleteMoreByArray">
delete from t_emp where eid in
<foreach collection="eids" item="eid" separator="," open="(" close=")">
#{eid}
</foreach>
</delete>
测试:
@Test
public void deleteMoreByArray() {
SqlSession sqlSession = SqlSessionUtils.getSqlSession();
DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);
int result = mapper.deleteMoreByArray(new Integer[]{6, 7, 8});
System.out.println(result);
}
结果:

通过集合实现批量插入
public interface DynamicSQLMapper{
/**
* 通过集合实现批量添加
*/
int insertMoreByList(List<Emp> emps);
}
只说SQL,写法应该是:
insert into t_emp values
(a1,a2,a3),
(b1,b2,b3),
(v1,v2,v3);
使用foreach动态实现:
<!--int insertMoreByList(@Param("emps") List<Emp> emps);-->
<insert id="insertMoreByList">
insert into t_emp values
<foreach collection="emps" item="emp" separator=",">
(null,#{emp.empName},#{emp.age},#{emp.sex},#{emp.email},null)
</foreach>
</insert>
注意,这里不用open和close,批量插入的原SQL是每条数据中有括号,即每次循环有括号,而不是删除SQL中的开头和结尾有括号。
//测试程序
@Test
public void insertMoreByList() {
SqlSession sqlSession = SqlSessionUtils.getSqlSession();
DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);
Emp emp1 = new Emp(null,"a",1,"男","123@321.com",null);
Emp emp2 = new Emp(null,"b",1,"男","123@321.com",null);
List<Emp> emps = Arrays.asList(emp1, emp2);
int result = mapper.insertMoreByList(emps);
System.out.println(result);
}
结果:

2.6 SQL标签
在映射文件中,声明一段SQL片段,把常用的一段SQL进行记录,在要使用的地方使用include标签进行引入。
- 声明
<sql id="empColumns">eid,emp_name,age,sex,email</sql>
- 引用
<!--List<Emp> getEmpByCondition(Emp emp);-->
<select id="getEmpByCondition" resultType="Emp">
select <include refid="empColumns"></include> from t_emp
</select>
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146082.html

