
文章目录

1、sorted_set类型
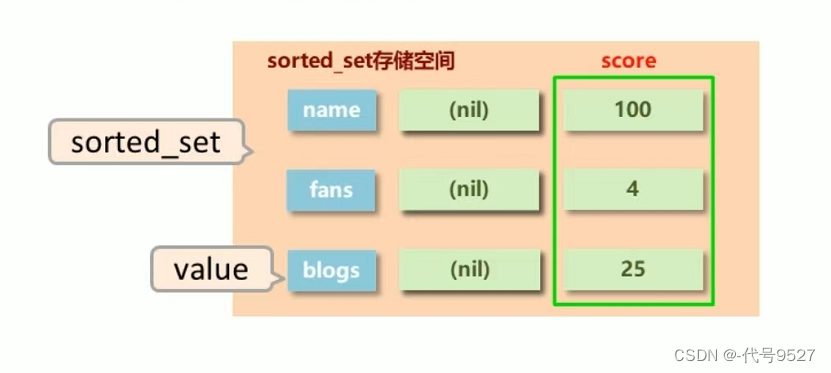
数据排序有利于数据的有效展示,故在set的存储结构上添加可排序字段score,就构成了sorted_set
2、sorted_set类型数据的基本操作
- 添加数据
zadd key score1 member1 [score2 member2]- 获取全部数据
zrange key start stop [withscores] //升序
zrevrange key start stop [withscores] //反转(降序)- 删除数据
zrem key memeber [member …]- 按条件获取数据
zrangebyscore key min max [withscores] [limit] //limit即控制显示几行,用于分页
zrevrangebyscore key max min [withscores] [limit]- 条件删除数据
zremrangebyrank key start stop //按索引删除
zremrangebyscore key min max //按值的范围区间删除- 获取集合数据的总量
zcard key
zcount key min max- 集合交并操作
zinterstore destination numkeys key [key ……] //numkeys为要合并的集合数量
zunionstore destination numkeys key [key ……]
记忆Tip:
- min与max用于限定搜索查询的条件,作用于值
- start与stop用于限定查询范围,作用于索引,表示开始和结束索引
- offset与count用于限定查询范围,作用于查询结果,表示开始位置和数据总量
举例:
127.0.0.1:6379> zadd scores 100 ls 60 ww 47 zl
(integer) 3
127.0.0.1:6379> zrange scores 0 -1
1) "zl"
2) "ww"
3) "ls"
127.0.0.1:6379> zrange scores 0 -1 withscores
1) "zl"
2) "47"
3) "ww"
4) "60"
5) "ls"
6) "100" //升序,带score值
127.0.0.1:6379> zrangebyscore scores 40 100 withscores limit 0 2
1) "zl"
2) "47"
3) "ww"
4) "60" //显示两行,最后是2,但注意前面写的是0,limit 0 2
127.0.0.1:6379> zremrangebyrank scores 0 1 //索引0 1,删除两行
(integer) 2
127.0.0.1:6379> zrange scores 0 -1 withscores
1) "ls"
2) "100"
集合交并的举例:
127.0.0.1:6379> zadd s1 50 aa 60 bb 70 cc
(integer) 3
127.0.0.1:6379> zadd s2 60 aa 40 bb 90 dd
(integer) 3
127.0.0.1:6379> zadd s3 70 aa 20 bb 100 dd
(integer) 3
127.0.0.1:6379> zinterstore ss 3 s1 s2 s3
(integer) 2
127.0.0.1:6379> zrange ss 0 -1 withscores
1) "bb"
2) "120"
3) "aa"
4) "180" //注意这里是把共同member的score加起来了
//也可不加,取最值,help zinterstore可看参数
127.0.0.1:6379> zinterstore sss 3 s1 s2 s3 aggregate max
(integer) 2
127.0.0.1:6379> zrange sss 0 -1 withscores
1) "bb"
2) "60"
3) "aa"
4) "70"
3、sorted_set 类型数据的扩展操作
- 获取数据对应的索引(排名)
zrank key member
zrevrank key member- score值获取与修改
zscore key member
zincrby key increment member
举例:
127.0.0.1:6379> zadd movies 1000 A 2000 B 10000 C
(integer) 3
127.0.0.1:6379> zrank movies A
(integer) 0 //索引为0.排名为1
127.0.0.1:6379> zscore movies C
"10000"
127.0.0.1:6379> zincrby movies 1 C
"10001"
注***
- score保存的数据存储空间是64位,如果是整数范围是-9007199254740992~9007199254740992
- core保存的数据也可以是一个双精度的double值,基于双精度浮点数的特征,可能会丢失精度
- sorted_set 底层存储还是基于set结构的,因此数据不能重复,如果重复添加相同的数据,score值将被反复覆盖,保留最后一次修改的结果
7.0.0.1:6379> zadd test 11 m
(integer) 1
127.0.0.1:6379> zadd test 22 m //同一个member
(integer) 0
127.0.0.1:6379> zrange test 0 -1 withscores
1) "m"
2) "22"
4、sorted_set类型的应用场景
实现计数器组合排序功能对应的排名
实际场景:
- 票选广东十大杰出青年,各类综艺选秀海选投票
- 各类资源网站TOP10(电影,歌曲,文档,电商,游戏等)
存成sorted_set,使用zrank和zrevrank完成排名。
sorted_set实现时效性任务管理
业务场景:
各种平台的VIP,当VIP体验到期后,如果有效管理此类信息?
实现思路:
将到期处理时间记录为score值,按照排序功能排序,记录下一个要处理的时间,对于到期任务,移除redis中的记录,并更新下一个要处理的任务的时间。为提升性能,可将其分为多个sorted_set存储,如1小时内,1天内,周内,月内,季内,将即将操作的若干个任务纳入到1小时内处理的队列中。
获取当前系统时间:
time
实现指令:
127.0.0.1:6379> time
1) "1660486886" //秒
2) "875524"
127.0.0.1:6379> zadd vip 1660486900 uid:001
(integer) 1
127.0.0.1:6379> zadd vip 1660486999 uid:002
(integer) 1
127.0.0.1:6379> zadd vip 1700000000 uid:9527
(integer) 1
127.0.0.1:6379> zrange vip 0 -1 withscores
1) "uid:001"
2) "1660486900"
3) "uid:002"
4) "1660486999"
5) "uid:9527"
6) "1700000000"
127.0.0.1:6379> zrem vip uid:001
(integer) 1
sorted_set实现带有权重的任务管理
业务场景:
对于形成任务队列或消息队列的待处理消息,对于优先级高的任务要保障其被优先处理,即实现任务的权重管理。
实现思路:
用score记录每个任务的权重值
实现指令:
127.0.0.1:6379> zadd tasks 4 order:id:001
(integer) 1
127.0.0.1:6379> zadd tasks 1 order:id:002
(integer) 1
127.0.0.1:6379> zadd tasks 9 order:id:003
(integer) 1
127.0.0.1:6379> zrevrange tasks 0 -1 withscores
1) "order:id:003"
2) "9"
3) "order:id:001"
4) "4"
5) "order:id:002"
6) "1"
127.0.0.1:6379> zrevrange tasks 0 0 withscores //0 0拿出第一个要优先处理的
1) "order:id:003"
2) "9"
127.0.0.1:6379> zrem tasks order:id:003 //这里有操作原子性的问题,等在事务中优化
(integer) 1
注意:
为了实现按位比对score,整体score长度必须是统一的,不足位补0。第一排序规则首
位不得是0。
至此,五种Redis数据类型完结!
5、Redis数据类型综合练习
例1:Redis用于按次结算的服务控制
业务场景:
对于下图服务,可免费试用,但试用用户每分钟只能最多试用十次,业务次数如何实现控制?

解决方案:
- 设计计数器,记录调用次数,以用户id为key,试用次数为value
- 在调用前获取试用次数,判断是否超过限制次数,若未超,每次试用调用次数+1,若调用失败了,则回退一次,计数-1
- 对计数器设置生命周期,如1秒/分钟,自动清空周期内试用的次数。
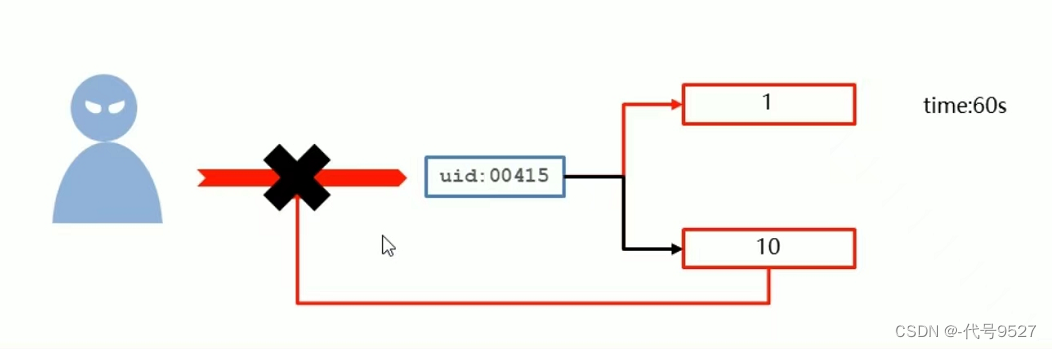

//setex设置数据具有指定的生命周期
127.0.0.1:6379> setex uid:001 60 1 //设置时间为60s
OK
127.0.0.1:6379> get uid:001
"1"
127.0.0.1:6379> incr uid:001 //调用次数加1
(integer) 2
//代码逻辑层判断是否超过10次
一分钟后:
127.0.0.1:6379> get uid:001
(nil)
方案改良:
每次调用前都判断一次试用次数是否超过限制,很繁琐,利用incr操作超过最大值抛异常的特点代替繁琐的每次判断,新方案如下:
- 判断是否为nil,若是,设置为Max次数,若不是则计数+1,业务调用失败,计数-1
- 当incr到最大值,抛异常,视为达到上限
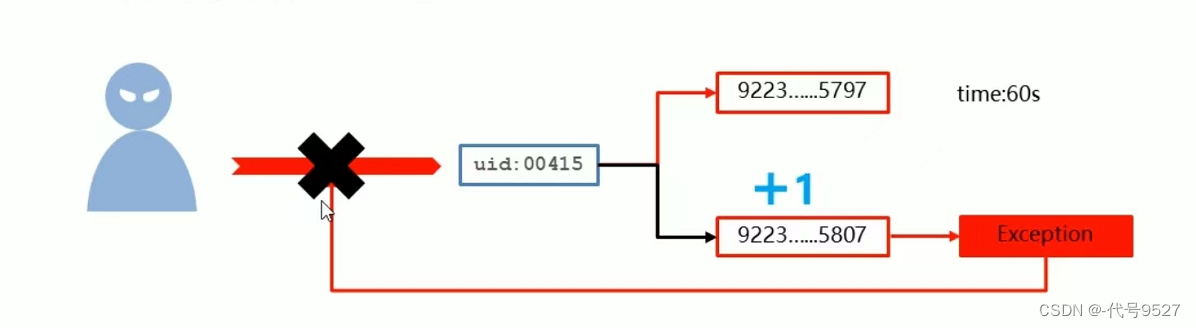
实现指令:
//利用string类型中的上限9223372036854775807
127.0.0.1:6379> setex uid:9527 60 9223372036854775805
OK
127.0.0.1:6379> incr uid:9527
(integer) 9223372036854775806
127.0.0.1:6379> incr uid:9527
(integer) 9223372036854775807
127.0.0.1:6379> incr uid:9527
(error) ERR increment or decrement would overflow
例2:Redis 应用于基于时间顺序的数据操作
业务场景:
使用微信的过程中,当微信接收消息后,会默认将最近接收的消息置顶,信息的排序会不停的交替。
场景分析:
假设100是自己的手机,200、300、400是给我发消息的手机,其中400、500手机用户是置顶好友。300发消息后,其不是置顶好友,存于list普通
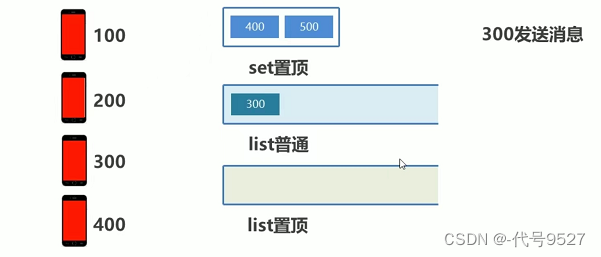
400发消息:
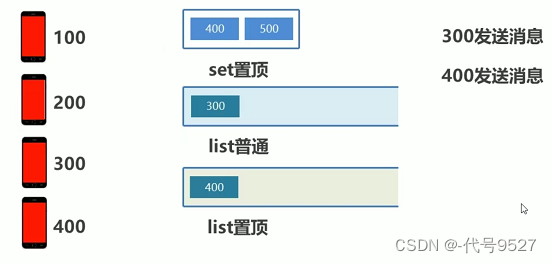
200发消息:
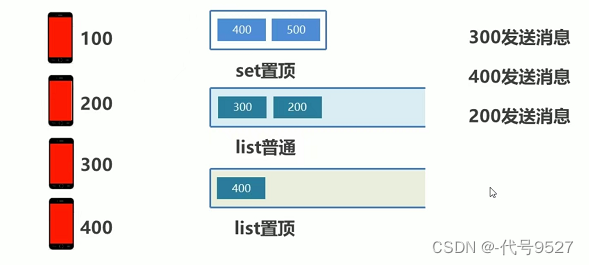
200再发消息(第二次发了),则先把已存入list的200删了,再存入一个200,这里由于200本就在最末尾,这么做的目的和效果不明显,继续往下:

300再发消息,把原300覆盖,再加入新发的300
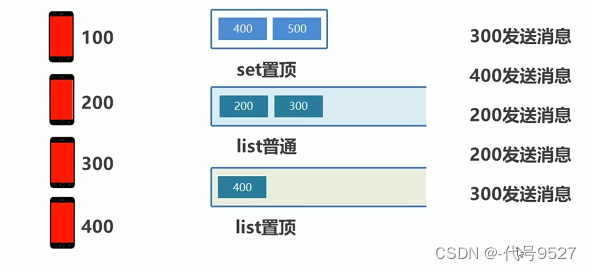
这样,往出来取信息展现给用户的时候,除去置顶list,就是300先出来,这也符合微信特点:新发的消息在最前面!!!
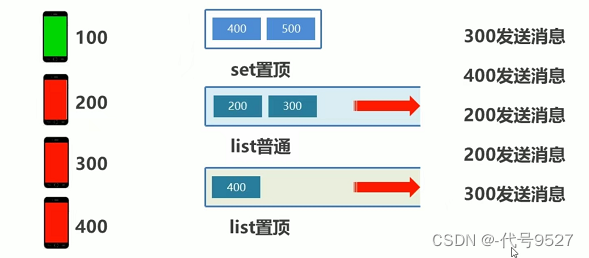
实现思路:
- 依赖list类型的数据具有顺序的特征,将置顶会话和普通会话分别存入两个list管理
- 多个相同id发出的消息反复入栈会出现问题,在入栈之前无论是否具有当前id对应的消息,先删除对应id(lrem、lpush)
- 用户查看完成后,清空list
6、Redis所有数据类型的应用场景整理

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146171.html

