
文章目录
2. 编写代码,实现对iris数据集的KNN算法分类及预测
要求:
(1)数据集划分为测试集占20%;
(2)n_neighbors=5;
(3)评价模型的准确率;
(4)使用模型预测未知种类的鸢尾花。
(待预测数据:X1=[[1.5 , 3 , 5.8 , 2.2], [6.2 , 2.9 , 4.3 , 1.3]])
iris数据集有150组,每组4个数据。
第一步:引入所需库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
第二步:划分测试集占20%
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0)
test_size为0-1的数代表占百分之几
random_state为零随机数确定,每次结果都相同
第三步:n_neighbors=5
KNeighborsClassifier(n_neighbors=5)
第四步:评价模型的准确率
KNN.fit(x_train, y_train)
# 训练集准确率
train_score = KNN.score(x_train, y_train)
# 测试集准确率
test_score = KNN.score(x_test, y_test)
第五步:使用模型预测未知种类的鸢尾花
#待预测数据:X1=[[1.5 , 3 , 5.8 , 2.2], [6.2 , 2.9 , 4.3 , 1.3]]
X1 = np.array([[1.5, 3, 5.8, 2.2], [6.2, 2.9, 4.3, 1.3]])
# 进行预测
prediction = KNN.predict(X1)
# 种类名称
k = iris.get("target_names")[prediction]
完整代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
if __name__ == '__main__':
iris = load_iris()
data = iris.get("data")
target = iris.get("target")
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0)
KNN = KNeighborsClassifier(n_neighbors=5)
KNN.fit(x_train, y_train)
train_score = KNN.score(x_train, y_train)
test_score = KNN.score(x_test, y_test)
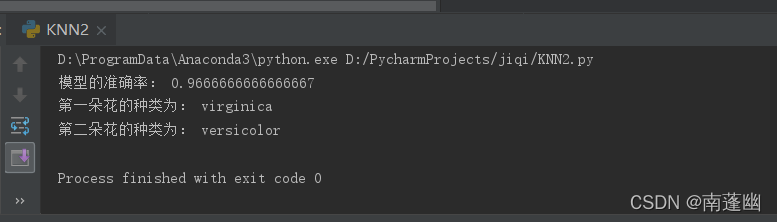
print("模型的准确率:", test_score)
X1 = np.array([[1.5, 3, 5.8, 2.2], [6.2, 2.9, 4.3, 1.3]])
prediction = KNN.predict(X1)
k = iris.get("target_names")[prediction]
print("第一朵花的种类为:", k[0])
print("第二朵花的种类为:", k[1])
结果:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/147453.html

