
7 文件操作、单元测试、goroutine【Go语言教程】
1 文件操作
1.1 介绍


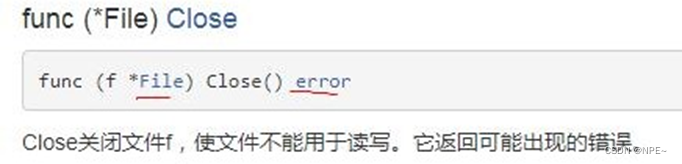
- os.File 封装所有文件相关操作,File 是一个结构体
常用方法:
- 打开文件
- 关闭文件

package main
import (
"fmt"
"os"
)
func main(){
//打开文件
//file又叫做:file对象、file指针、file文件句柄
file, err := os.Open("D:/系统默认/桌面/code.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//输出file,看看file到底是什么,最后结果可以看处file就是一个指针*File
//file=&{0xc000004a00}
fmt.Printf("file=%v", file)
//关闭文件
err = file.Close()
if err != nil {
fmt.Println("close file err=", err)
}
}
1.2 应用实例
①读文件
常用方法:
①bufio.NewReader(), reader.ReadString【带缓冲】
②io/ioutil【一次性读取,适用于小文件】
- 读取文件的内容并显示在终端(带缓冲区的方式),使用 os.Open, file.Close, bufio.NewReader(), reader.ReadString 函数和方法.
package main
import (
"fmt"
"os"
"bufio"
"io"
)
//定义缓冲区常量
const (
defaultBufSize = 4096 //默认缓冲区为4096
)
func main(){
//打开文件
file, err := os.Open("D:/系统默认/桌面/code.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//当函数退出时,要及时的关闭file句柄,否则会又内存泄漏问题
defer file.Close()
//创建一个*Reader(带缓冲的)
reader := bufio.NewReader(file)
//循环读取文件内容
for {
str, err := reader.ReadString('\n') //读取到一个换行就结束
if err == io.EOF { //io.EOF表示文件的末尾
break
}
//输出读取到的内容
fmt.Println(str)
}
fmt.Println("文件读取结束....")
}
- 读取文件的内容并显示在终端(使用 ioutil 一次将整个文件读入到内存中),这种方式适用于文件不大的情况。相关方法和函数(ioutil.ReadFile)
package main
import (
"fmt"
"io/ioutil"
)
func main(){
//使用ioutil.ReadFile一次性将文件读取到位
file := "D:/系统默认/桌面/code.txt"
content, err := ioutil.ReadFile(file) // content: []byte
if err != nil {
fmt.Printf("read file err=%v", err)
}
//把读取到的文件内容显示到终端
fmt.Printf("%v", string(content))//[]byte
//我们没有显示的Open文件,因此也不需要显示的Close文件
//因为,文件的Open何Close都被封装到了ioutils.ReadFile的函数内部
}
效果:
②写文件
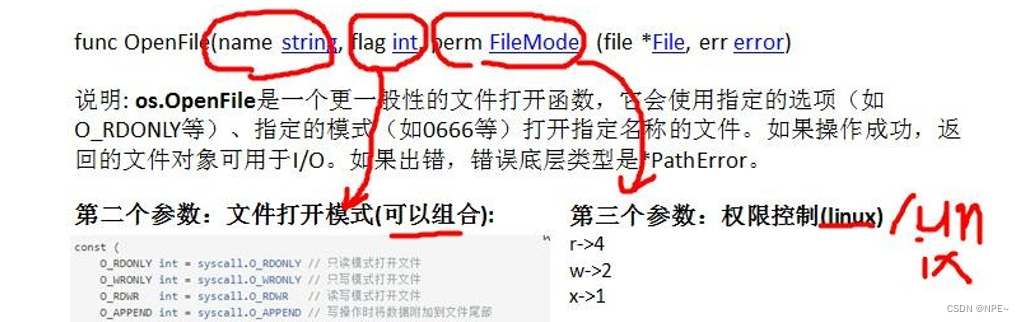
1. 创建一个新文件,写入内容[os.O_CREATE]
- file, err :=
os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666)//只写、创作- writer:= bufio.NewWriter(file)
package main
import (
"fmt"
"os"
"bufio"
)
func main(){
//创建一个新文件,写入内容 5句 "hello Go"
//1. 打开文件 D:/系统默认/桌面/demo1.txt
filePath := "D:/系统默认/桌面/demo1.txt"
//os.O_WRONLY | os.O_CREATE, 文件模式 0666 权限操作
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//及时关闭file句柄
defer file.Close()
//准备写入5句 "hello, Go"
str := "hello, Go\n"
//写入时,使用带缓存的 *Writer
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
//因为writer是带缓存,因此在调用WriterString方法时,其实内容是先写入到缓存的,
//所以需要调用Flush方法,将缓冲的数据真正写入到文件中,否则文件中会没有数据
writer.Flush()
}
2. 覆盖原来的内容写[os.O_TRUNC]
打开一个存在的文件中,将原来的内容覆盖成新的内容 10 句 “你好,Go”
- file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_TRUNC, 0666)
- os.O_WRONLY | os.O_TRUNC
package main
import (
"fmt"
"os"
"bufio"
)
func main(){
//打开一个存在的文件,将原来的内容覆盖为"hello jackson"
//1. 打开一个已经存在的文件"D:\系统默认\桌面\demo1.txt"
filePath := "d:/系统默认/桌面/demo1.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_TRUNC, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//及时关闭file句柄
defer file.Close()
str := "hello jackson\n"
//写入时使用带缓存的 *Writer
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
writer.WriteString(str)
}
//将缓存中的数据flush到硬盘
writer.Flush()
}
3. 追加写[os.O_APPEND]
打开一个存在的文件,在原来的内容追加内容
- file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_APPEND, 0666)
package main
import (
"fmt"
"os"
"bufio"
)
func main(){
//打开一个存在的文件,追加写入"you are good!!!"
filePath := "d:/系统默认/桌面/demo1.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
defer file.Close()
str := "you are good!!!\n"
writer := bufio.NewWriter(file);
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
writer.Flush()
}
4. 读出文件内容并追加[os.O_RDWR | os.O_APPEND]
打开一个存在的文件,将原来的内容读出显示在终端,并且追加 5 句”you are good!!!”
- file, err := os.OpenFile(filePath, os.O_RDWR | os.O_APPEND, 0666)
- reader := bufio.NewReader(file)
- str, err := reader.ReadString(‘\n’)
package main
import (
"fmt"
"os"
"bufio"
"io"
)
func main(){
//打开一个存在的文件,追加写入"you are good!!!"
filePath := "d:/系统默认/桌面/demo1.txt"
//READ、WRITE、APPEND
file, err := os.OpenFile(filePath, os.O_RDWR | os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
defer file.Close()
//先读取原来的内容,并显示在终端
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF { //如果读取到文件的末尾
break
}
//显示到终端
fmt.Print(str)
}
//追加写入数据"you are good!!!"
str := "you are good!!!"
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
writer.Flush()
}
5. 将A文件内容写入到B文件
编程一个程序,将一个文件的内容,写入到另外一个文件。注:这两个文件已经存在了.
- 说明:使用 ioutil.ReadFile / ioutil.WriteFile 完成写文件(覆盖写)的任务.
package main
import (
"fmt"
_ "os"
_ "bufio"
_ "io"
"io/ioutil"
)
func main(){
//将demo.txt文件的内容导入到demo1.txt
//1. 先将demo.txt内容读取到内存
//2. 将读取到的内容写入到demo1.txt
filePath1 := "d:/系统默认/桌面/demo.txt"
filePath2 := "d:/系统默认/桌面/demo1.txt"
data, err := ioutil.ReadFile(filePath1)
if err != nil {
fmt.Printf("read file err=%v\n", err)
return
}
//从demo.txt文件中读取到的data数据写入到demo1.txt
err = ioutil.WriteFile(filePath2, data, 0666)
if err != nil {
fmt.Printf("write file err=%v\n", err)
}
}
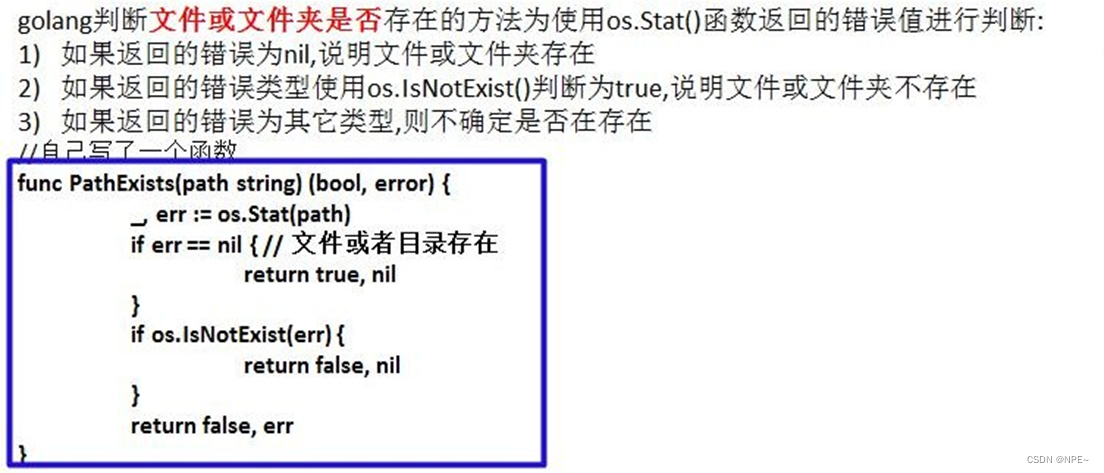
6. 判断文件是否存在
- _, err := os.Stat(path)
- os.IsNotExist(err)
package main
import (
"fmt"
"os"
)
func main(){
//判断文件或目录是否存在
filePath1 := "d:/系统默认/桌面/demo.txt"
flag, err := PathExists(filePath1)
//flag=true, err=<nil>
fmt.Printf("flag=%v, err=%v\n", flag, err)
}
func PathExists(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil { //文件或目录存在
return true, nil
}
//如果文件的Stat返回的err是os.IsNotExist则表明文件不存在
if os.IsNotExist(err){
return false, nil
}
return false, err
}
③拷贝文件、统计字符数、命令行参数
1. 拷贝一张图片
说明:将一张图片/电影/mp3 拷贝到另外一个文件 e:/abc.jpg io 包
- func Copy(dst Writer, src Reader) (written int64, err error)
注意; Copy 函数是 io 包提供的.
package main
import (
"fmt"
"os"
"io"
"bufio"
)
func main(){
//D:\系统默认\桌面
_, err := CopyFile("D:/系统默认/桌面/banner2.png", "D:/系统默认/桌面/banner.png")
if err != nil {
fmt.Printf("CopyFile() fail, err=%v", err)
} else {
fmt.Printf("success...")
}
}
//拷贝文件
func CopyFile(dstFilePath string, srcFilePath string) (written int64, err error){
srcFile, err := os.Open(srcFilePath)
if err != nil {
fmt.Printf("open file err=%v\n", err)
}
defer srcFile.Close()
//通过srcFile获取到Reader
reader := bufio.NewReader(srcFile)
//打开dstFilePath
dstFile, err := os.OpenFile(dstFilePath, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open fil err=%v\n", err)
return
}
//通过dstFile获取到Writer
writer := bufio.NewWriter(dstFile)
defer dstFile.Close()
//调用io包下的工具类
return io.Copy(writer, reader)
}
2. 统计字符数
说明:统计一个文件中含有的英文、数字、空格及其它字符数量
package main
import (
"fmt"
"os"
"io"
"bufio"
)
//定义一个结构体,用于保存统计结果
type CharCount struct {
ChCount int //记录英文个数
NumCount int //数字个数
SpaceCount int //空格个数
OtherCount int //其他字符个数
}
func main(){
//1. 打开一个文件,创建一个Reader
//2. 每读取一行,就去统计该行有多少个英文、数字、空格和其他字符
//3. 然后将结果保存到一个结构体
fileName := "D:/系统默认/桌面/demo.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
defer file.Close()
//定义CharCount实例
var count CharCount
//创建一个reader
reader := bufio.NewReader(file)
//开始循环读取文件的内容
for {
str1, err := reader.ReadString('\n') //一行一行读取
if err == io.EOF { //读到文件末尾就退出
break
}
//为了兼容中文字符,可以将str转成[]rune
str := []rune(str1)
//遍历str,进行统计
for _, v := range str {
switch {
case v >= 'a' && v <= 'z':
fallthrough //穿透,大小写字母都存在ChCount中
case v >= 'A' && v <= 'Z':
count.ChCount++
case v == ' ' || v == '\t':
count.SpaceCount++
case v >= '0' && v <= '9':
count.NumCount++
default:
count.OtherCount++
}
}
}
//输出统计的结果看看是否正确
fmt.Printf("字符的个数为=%v, 数字的个数为=%v, 空格的个数为=%v, 其他字符的个数为=%v",
count.ChCount, count.NumCount, count.SpaceCount, count.OtherCount)
}
3. 命令行参数解析[flag包]
比如:cmd>main.exe -f c:/aaa.txt -p 200 -u root 这样的形式命令行,go 设计者给我们提供了 flag包,可以方便的解析命令行参数,而且参数顺序可以随意
package main
import (
"fmt"
"flag"
)
func main(){
//定义几个变量,用于接收命令行的参数值
var user string
var pwd string
var host string
var port int
//&user 就是接收用户命令行中输入的 -u 后面的参数值
//"u", 就是 -u 指定参数
//"", 默认值
//"用户名,默认为空" 说明
flag.StringVar(&user, "u", "", "用户名, 默认为空")
flag.StringVar(&pwd, "pwd", "", "密码, 默认为空")
flag.StringVar(&host, "h", "localhost", "主机名, 默认为localhost")
flag.IntVar(&port, "port", 3306, "端口号, 默认为3306")
//这里有一个非常重要的操作, 转换, 必须调用该方法
flag.Parse()
//输出结果
fmt.Printf("user=%v pwd=%v host=%v port=%v", user, pwd, host, port)
}

mysql的命令行也是类似于这种方式
④json的序列化、反序列化
1. 序列化
- json 序列化是指,将有 key-value 结构的数据类型(比如结构体、map、切片)序列化成 json 字符串的操作。
- 这里我们介绍一下结构体、map 和切片的序列化,其它数据类型的序列化类似。
package main
import (
"fmt"
"encoding/json"
)
//定义一个结构体
type Monster struct {
Name string `json:"name"`
Age int `json:"age"`
Birthday string
Sal float64
Skill string
}
func testStruct(){
//演示
monster := Monster{
Name: "牛魔王",
Age : 500,
Birthday : "2011-11-11",
Sal : 8000.0,
Skill : "牛魔拳",
}
//将monster序列化
data, err := json.Marshal(&monster)
if err != nil {
fmt.Printf("序列号错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("结构体:monster序列化后=%v\n", string(data))
}
//将map进行序列化
func testMap(){
var a map[string]interface{}
//使用map之前需要make
a = make(map[string]interface{})
a["name"] = "红孩儿"
a["age"] = 30
a["address"] = "洪崖洞"
//将a这个map进行序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
fmt.Printf("map序列化=%v\n", string(data))
}
//对切片序列化 []map[string]interface{}
func testSlice(){
var slice []map[string]interface{}
var m1 map[string]interface{}
//使用map前make
m1 = make(map[string]interface{})
m1["name"] = "jack"
m1["age"] = "7"
m1["address"] = "北京"
slice = append(slice, m1)
var m2 map[string]interface{}
//使用map前,需要先make
m2 = make(map[string]interface{})
m2["name"] = "tom"
m2["age"] = "20"
m2["address"] = [2]string{"墨西哥", "夏威夷"}
slice = append(slice, m2)
data, err := json.Marshal(slice)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("切片:slice序列化后=%v\n", string(data))
}
//对基本数据类型序列化【意义不大】
func testFloat64(){
var num1 float64 = 2345.67
data, err := json.Marshal(num1)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
fmt.Printf("基本数据类型:num1 序列化后=%v\n", string(data))
}
func main(){
testStruct()
testMap()
testSlice()
testFloat64()
}

2. 反序列化
json 反序列化是指,将 json 字符串反序列化成对应的数据类型(比如结构体、map、切片)的操作
package main
import (
"fmt"
"encoding/json"
)
//定义一个结构体
type Monster struct {
Name string `json:"name"`
Age int `json:"age"`
Birthday string
Sal float64
Skill string
}
//反序列化结构体
func UnmarshalStruct(){
//说明 str 在项目开发中,是通过网络传输获取到.. 或者是读取文件获取到
str := "{\"Name\":\"牛魔王\",\"Age\":500,\"Birthday\":\"2011-11-11\",\"Sal\":8000,\"Skill\":\"牛魔拳\"}"
var monster Monster
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Printf("unmarshal err=%v", err)
}
fmt.Printf("结构体反序列化后 monster=%v monster.Name=%v\n", monster, monster.Name)
}
//反序列化map
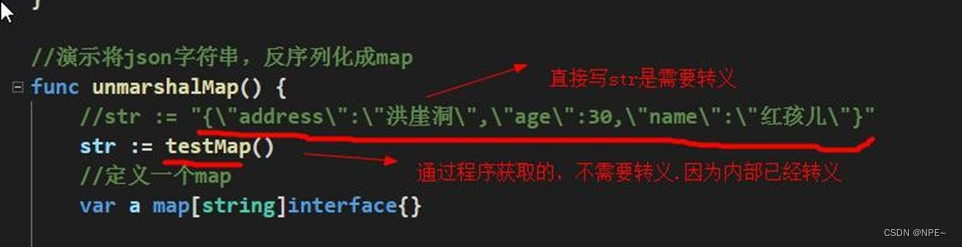
func UnmarshalMap(){
str := "{\"address\":\"洪崖洞\",\"age\":30,\"name\":\"红孩儿\"}"
var a map[string]interface{}
//注意:反序列化map,不需要make,因为make操作被封装到Unmarshal函数
err := json.Unmarshal([]byte(str), &a)
if err != nil {
fmt.Printf("unmarshal err=%v", err)
}
fmt.Printf("map反序列化后 a=%v\n", a)
}
//反序列化切片
func UnmarshalSlice(){
str := "[{\"address\":\"北京\",\"age\":\"7\",\"name\":\"jack\"}," +
"{\"address\":[\"墨西哥\",\"夏威夷\"],\"age\":\"20\",\"name\":\"tom\"}]"
var slice []map[string]interface{}
//反序列化不需要make,因为make操作被封装在了Unmarshal函数
err := json.Unmarshal([]byte(str), &slice)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("切片反序列化后 slice=%v\n", slice)
}
func main(){
UnmarshalStruct()
UnmarshalMap()
UnmarshalSlice()
}

说明:
2 单元测试
2.1 概念
Go 语言中自带有一个轻量级的测试框架 testing 和自带的 go test 命令来实现单元测试和性能测试,testing 框架和其他语言中的测试框架类似,可以基于这个框架写针对相应函数的测试用例,也可以基于该框架写相应的压力测试用例。
- go test
- testing 测试框架
go test [运行错误时才有日志]
go test -v [不论运行正确还是错误,都输出日志]
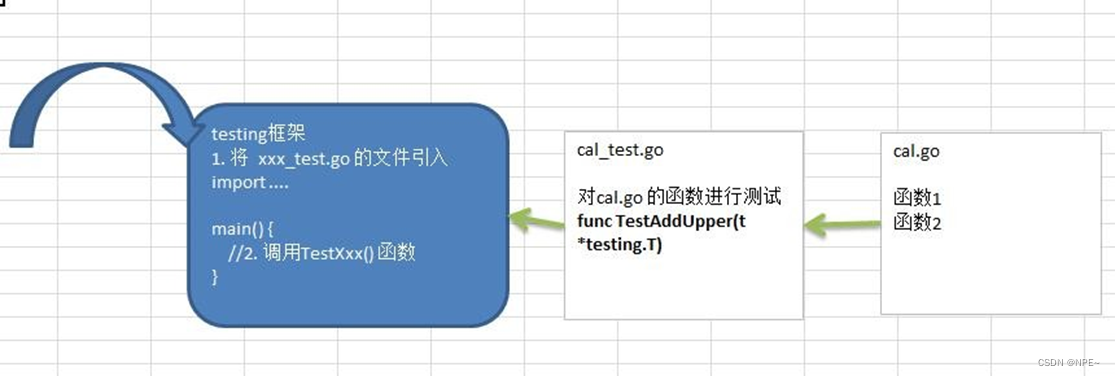
- 测试用例文件名必须以 _test.go 结尾。 比如 cal_test.go , cal 不是固定的。
- 测试用例函数必须以 Test 开头,一般来说就是 Test+被测试的函数名,比如 TestAddUpper
- TestAddUpper(t *tesing.T) 的形参类型必须是 *testing.T 【看一下手册】
- 一个测试用例文件中,可以有多个测试用例函数,比如 TestAddUpper、TestSub
- 运行测试用例指令
(1) cmd>go test [如果运行正确,无日志,错误时,会输出日志]
(2) cmd>go test -v [运行正确或是错误,都输出日志]- 当出现错误时,可以使用 t.Fatalf 来格式化输出错误信息,并退出程序
- t.Logf 方法可以输出相应的日志
- 测试用例函数,并没有放在 main 函数中,也执行了,这就是测试用例的方便之处[原理图].
- PASS 表示测试用例运行成功,FAIL 表示测试用例运行失败
- 测试单个文件,一定要带上被测试的原文件
go test -v cal_test.go cal.go- 测试单个方法
go test -v -test.run TestAddUpper
快速入门:
xxx_test.go文件应该与被测试的函数在同一个包下
比如:都在monster包下,在进行单元测试的时候如果用到了其他go文件中的函数、结构体、变量等,需要在go test命令后面再加上这个函数。
执行类似下面命令便可以了
go test -v .\monster_test.go .\monster.go
package test
import (
"testing"
)
func TestSub(t *testing.T){
res := Sub(20, 10)
if res != 10 {
t.Fatalf("sub(20, 10) error, 期望值为%v, 实际值为%v", 10, res)
}
t.Logf("test sub success...")
}
//定义一个Sub函数
func Sub(a int, b int) int {
return a - b
}
2. 2 实战

- monster/monster.go:
package monster
import (
"fmt"
"encoding/json"
"io/ioutil"
)
type Monster struct {
Name string
Age int
Skill string
}
//序列化保存到文件中
func (this *Monster) Store() bool {
//1. 序列化
data, err := json.Marshal(this)
if err != nil {
fmt.Println("marshal err=", err)
return false
}
//2. 保存到文件
filePath := "d:/系统默认/桌面/demo.ser"
err = ioutil.WriteFile(filePath, data, 0666)
if err != nil {
fmt.Println("write file err=", err)
return false
}
return true
}
//反序列化
func (this *Monster) ReStore() bool {
//1. 从序列化文件中读取字符串
filePath := "d:/系统默认/桌面/demo.ser"
data, err := ioutil.ReadFile(filePath)
if err != nil {
fmt.Println("ReadFile err=", err)
return false
}
//2. 使用读取到的data: byte[]进行反序列化
err = json.Unmarshal(data, this)
if err != nil {
fmt.Println("Unmarshal err=", err)
return false
}
return true
}
- monster/monster_test.go
package monster
import (
"testing"
)
//测试Store方法
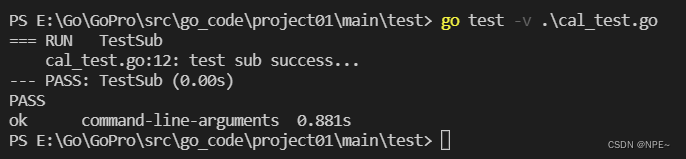
func TestStore(t *testing.T){
monster := &Monster{
Name : "红孩儿",
Age: 10,
Skill: "吐火",
}
flag := monster.Store()
if !flag {
t.Fatalf("monster.Store()错误,希望为=%v 实际为%v", true, flag)
}
t.Logf("monster.Store() 测试成功!!!")
}
func TestReStore(t *testing.T){
var monster = &Monster{}
flag := monster.ReStore()
if !flag {
t.Fatalf("monster.ReStore()错误, 希望为=%v 实际为=%v", true, flag)
}
//进一步判断
if monster.Name != "红孩儿" {
t.Fatalf("monster.ReStore()错误, 希望为=%v 实际为=%v", "红孩儿", monster.Name)
}
t.Logf("monster.ReStore() 测试成功!!!")
}
测结果:
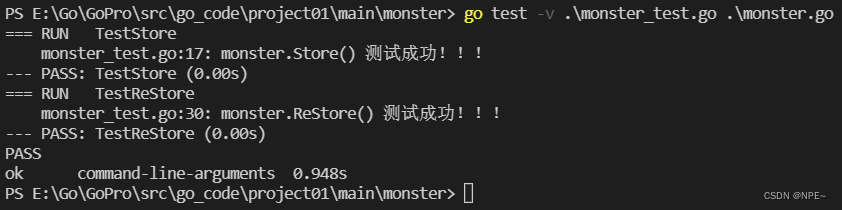
3 goroutine
3.1 goroutine(协程)
①概念及快速入门
1. 概念
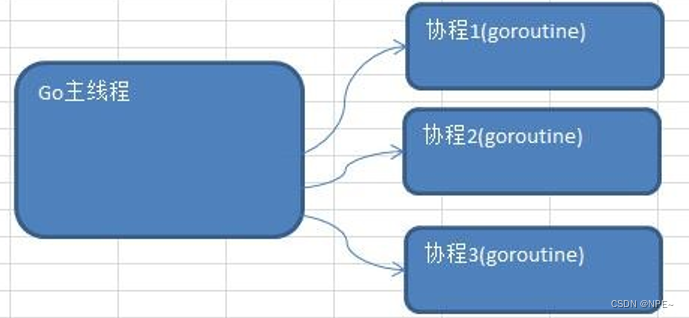
- Go 主线程(有程序员直接称为线程/也可以理解成进程): 一个 Go 线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程[编译器做优化]。
- Go 协程的特点
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
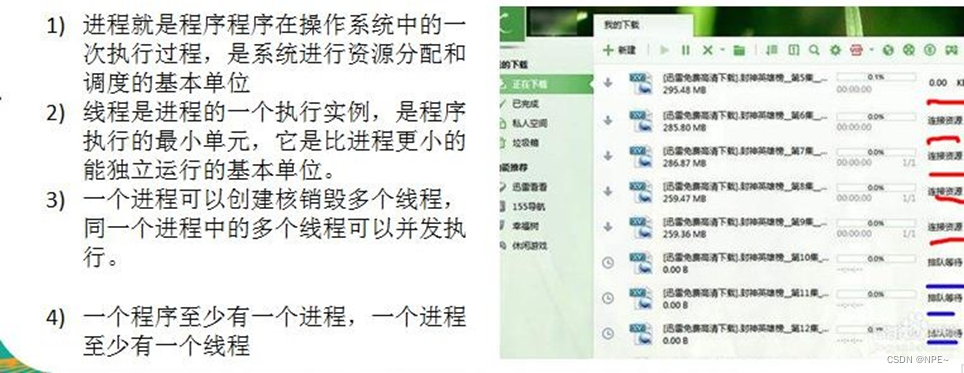
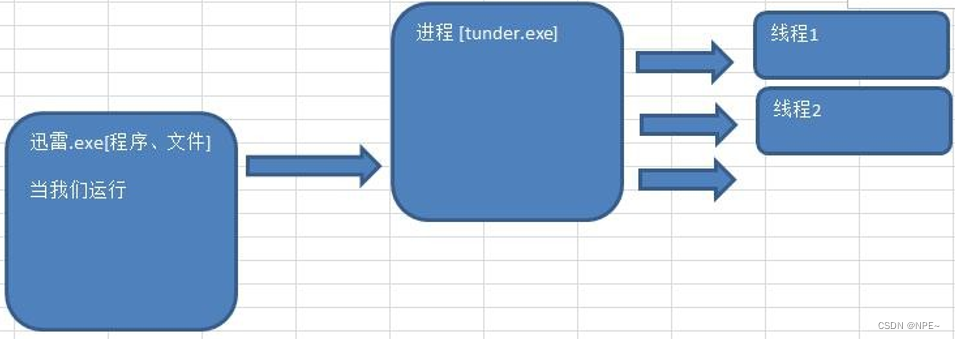
- 进程、线程关系:
- 并发与并行
- 多线程程序在单核上运行,就是并发
- 多线程程序在多核上运行,就是并行
2. 快速入门
请编写一个程序,完成如下功能:
- 在主线程(可以理解成进程)中,开启一个 goroutine, 该协程每隔 1 秒输出 “hello,world”
- 在主线程中也每隔一秒输出”hello,golang”, 输出 10 次后,退出程序
- 要求主线程和 goroutine 同时执行.
package main
import(
"fmt"
"time"
"strconv"
)
//编写一个函数,每隔1s输出 "hello world"
func test(){
for i := 1; i <= 10; i++ {
fmt.Println("test() hello world "+ strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main(){
go test() //开启了一个goroutine 协程
for i := 1; i <= 10; i++ {
fmt.Println("main() hello, golang " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}

流程图:
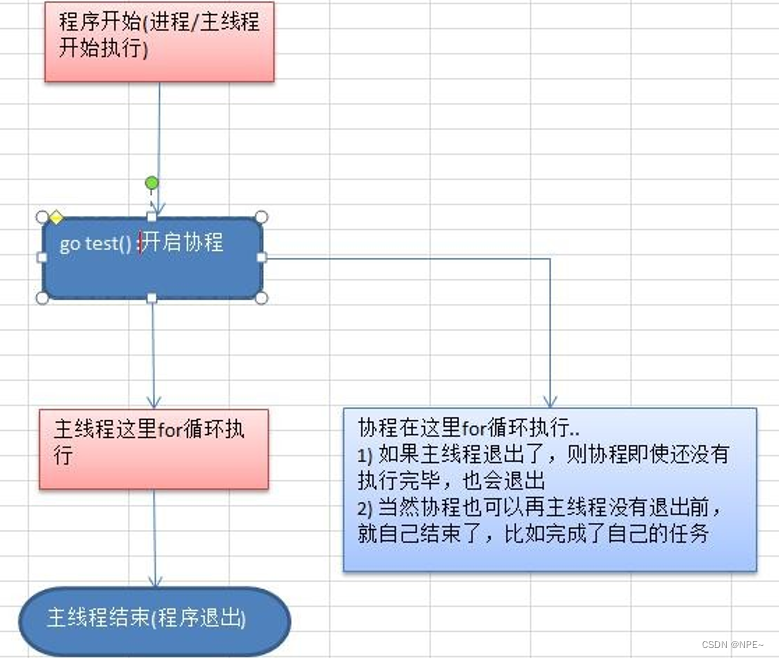
小结:
- 主线程是一个物理线程,直接作用在 cpu 上的。是重量级的,非常耗费 cpu 资源。
- 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。
- Golang 的协程机制是重要的特点,可以轻松的开启上万个协程。其它编程语言的并发机制是一般基于线程的,开启过多的线程,资源耗费大,这里就突显Golang 在并发上的优势了
②gorountine的MPG调度模型
- 概念:
M:操作系统主线程(main)
P:协程执行所需上下文(Process context)
G:协程(goroutine)

- 运行状态
- 状态1:
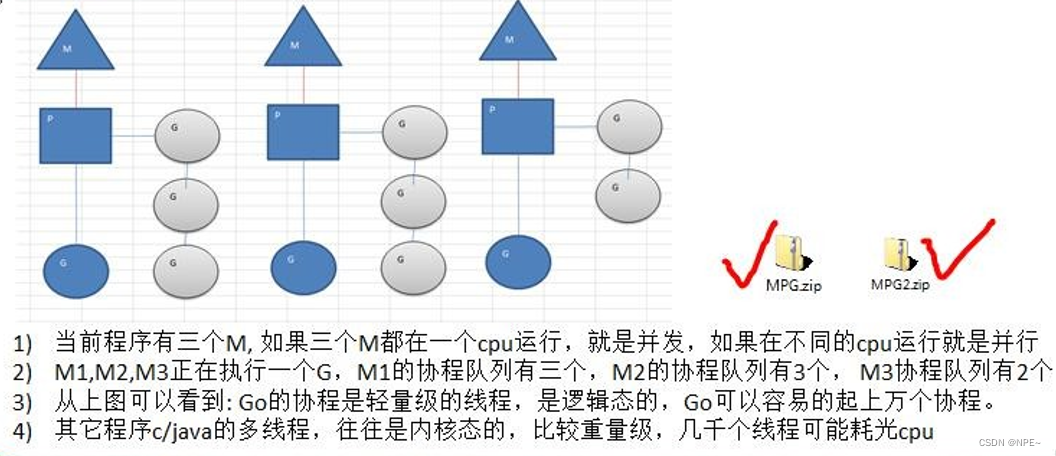
- 状态2:

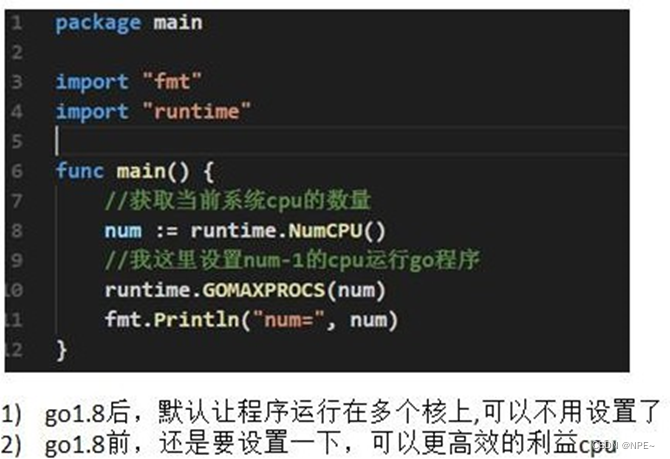
③设置cpu个数
介绍:为了充分了利用多 cpu 的优势,在 Golang 程序中,设置运行的 cpu 数目
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/148508.html

