
一、字符集
- 编码与解码
- 计算机中储存的信息都是用
二进制数表示的 - 而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果
- 按照某种规则,将字符存储到计算机中,称为
编码 - 反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为
解码
- 计算机中储存的信息都是用
- 字符编码(Character Encoding)
- 就是一套自然语言的
字符与二进制数之间的对应规则
- 就是一套自然语言的
- 字符集
- 也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等
二、ASCII码
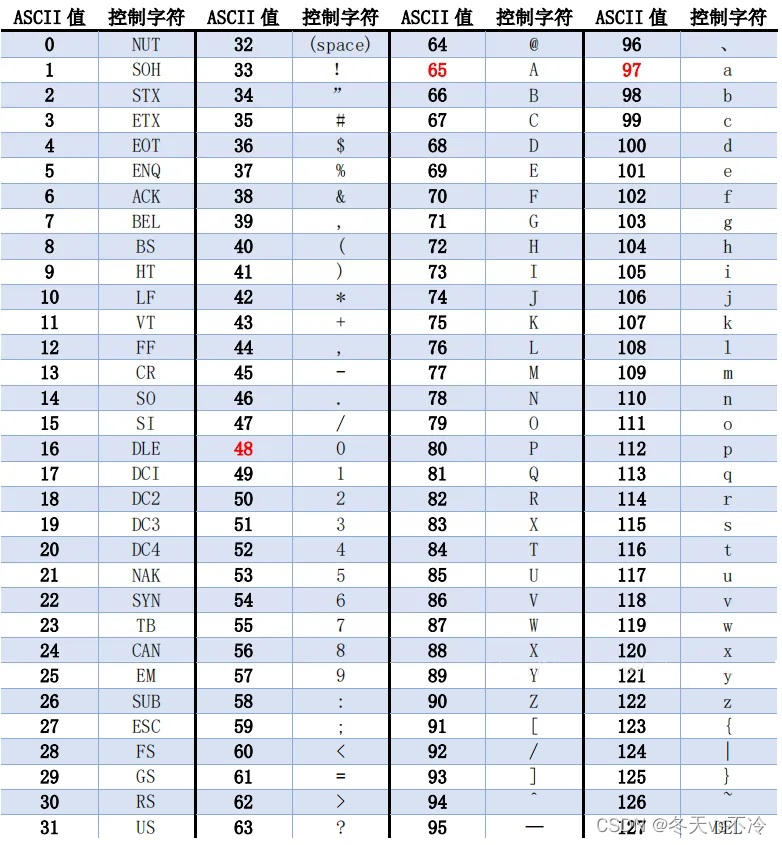
- ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码):上个世纪60年代,美国制定了一套字符编码,对
英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码 - ASCII码用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)
- 基本的ASCII字符集,使用7位(bits)表示一个字符(最前面的1位统一规定为0),共
128个字符。比如:空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001) - 缺点:不能表示所有字符
三、ISO-8859-1字符集
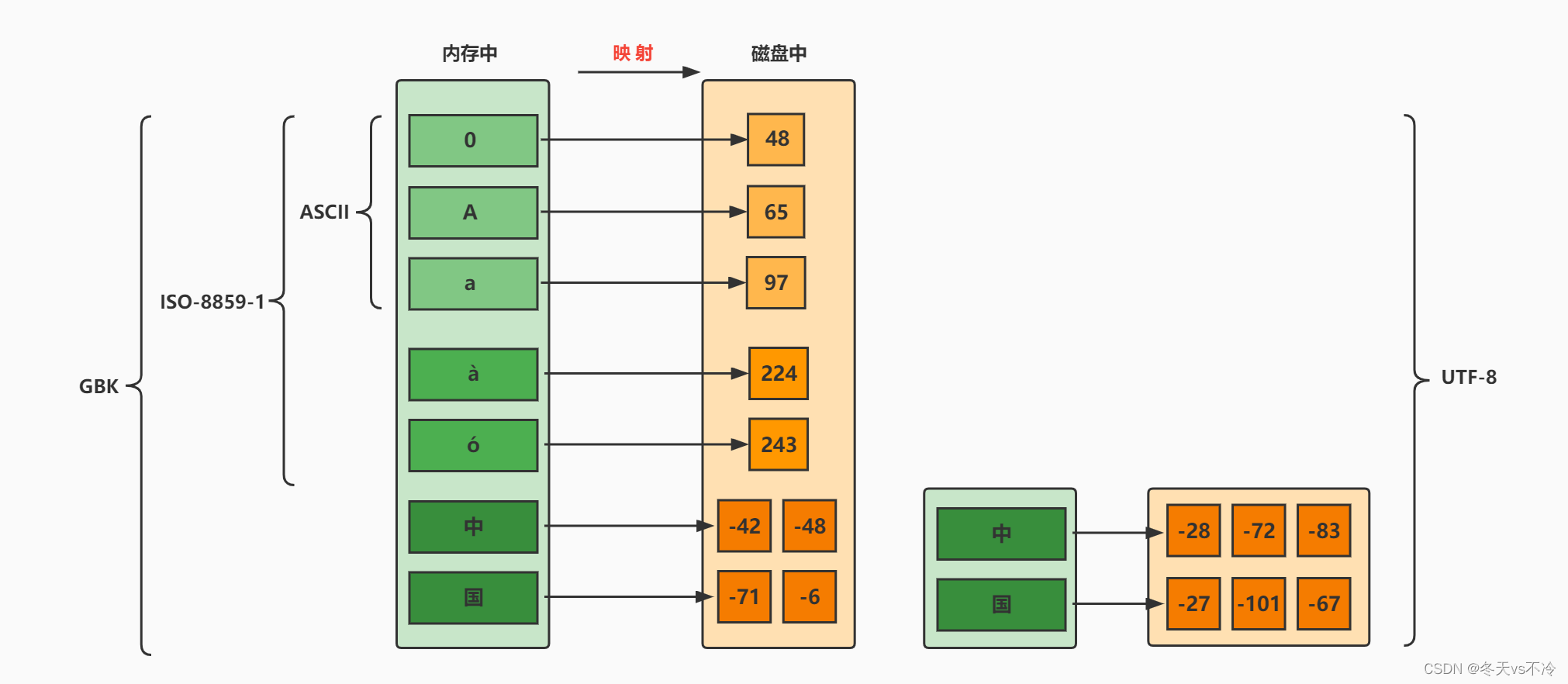
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰语、德语、意大利语、葡萄牙语等
- ISO-8859-1使用
单字节编码,兼容ASCII编码
四、GBxxx字符集
- GB就是国标的意思,是为了
显示中文而设计的一套字符集 - GB2312:简体中文码表
- 一个小于127的字符的意义与原来相同,即向下兼容ASCII码
- 但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含
7000多个简体汉字 - 此外数学符号、罗马希腊的字母、日文的假名们都编进去了
- 这就是常说的”全角”字符,而原来在127号以下的那些符号就叫”半角”字符了
- GBK:最常用的中文码表
- 是在GB2312标准基础上的扩展规范,使用了
双字节编码方案,共收录了21003个汉字 - 完全兼容GB2312标准,同时支持
繁体汉字以及日韩汉字等
- 是在GB2312标准基础上的扩展规范,使用了
- GB18030:最新的中文码表
- 收录汉字
70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成 - 支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等
- 收录汉字
五、Unicode码
- Unicode编码为表达
任意语言的任意字符而设计,也称为统一码、标准万国码- Unicode 将世界上所有的文字用
2个字节统一进行编码 - 为每个字符设定唯一的二进制编码
- 以满足跨语言、跨平台进行文本处理的要求
- Unicode 将世界上所有的文字用
- Unicode 的缺点:这里有三个问题:
- 第一,英文字母只用一个字节表示就够了,如果用更多的字节存储是
极大的浪费 - 第二,如何才能
区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢? - 第三,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,
不够表示所有字符
- 第一,英文字母只用一个字节表示就够了,如果用更多的字节存储是
- Unicode在很长一段时间内无法推广,直到互联网的出现
- 为解决Unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现
- 具体来说,有三种编码方案,UTF-8、UTF-16和UTF-32
六、UTF-8
- Unicode是字符集,UTF-8、UTF-16、UTF-32是三种
将数字转换到程序数据的编码方案- 顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位
- 其中,UTF-8 是在互联网上
使用最广的一种 Unicode 的实现方式
- 互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码
- 所以开发Web应用,也要使用UTF-8编码。UTF-8 是一种
变长的编码方式 - 可以使用 1-4 个字节表示一个符号它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码
- 拉丁文等字符,需要二个字节编码
- 大部分常用字(含中文),使用三个字节编码
- 其他极少使用的Unicode辅助字符,使用四字节编码
举例:
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
————————————————————|—–—–—–—–—–—–—–—–—–—–—–—–—–—–
0000 0000-0000 007F | 0xxxxxxx(兼容原来的ASCII)
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- 0开头代表一个字节就是一个字符
- 110开头代表两个字节组成一个字符
- 1110开头代表三个字节组成一个字符
- 11110开头代表四个字节组成一个字符

总结
- 一个字符(char)占用2个字节。在内存中使用的字符集称为Unicode字符集
注意: 在中文操作系统上,ANSI(美国国家标准学会、AMERICAN NATIONAL STANDARDS INSTITUTE: ANSI)编码即为GBK;在英文操作系统上,ANSI编码即为ISO-8859-1
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/148571.html

