
使用HttpClient可以创建浏览器对象,然后对页面数据进行抓取,另外再使用Jsoup库解析Html页面。因为Jsoup和JQuery一样有选择器获取元素的方式,所以抓取页面数据变得非常方便。
例如这个链接:https://search.jd.com/Search?keyword=%E5%B0%8F%E7%B1%B3&page=1&s=201&click=0
研究发现,京东商城关键字搜索商品的页面Url的page参数为奇数(1、3、5、7、9…),估计应该是前面30个商品数据实际为第一页,后面Ajax加载的30个商品数据实际为第二页,这个第一页和第二页的数据合起来就是page的1页的数据。
另外,京东商品的数据中,有2个字段很神奇,分别为spu和sku,spu代表商品集合id,sku代表商品最小品类单元id,也就是说一个spu至少有一个或多个sku。每个sku代表一个商品。
例如这个链接:https://item.jd.com/100004994481.html
现在就以爬取京东某个关键词下面的商品列表,一页有60个商品,不过只能爬取30个,还有30个是通过Ajax加载的,而且需要页面滚动到第30个数据之后才执行的Ajax请求,所以目前这异步加载的30个商品数据就爬不了了。如果想要抓取完整的60条数据,可以使用Selenium库,它是以滚动页面方式分析和抓取网页数据,可以抓取Js动态生成数据。
使用Fiddler抓包工具,有几个小发现,如下所示。
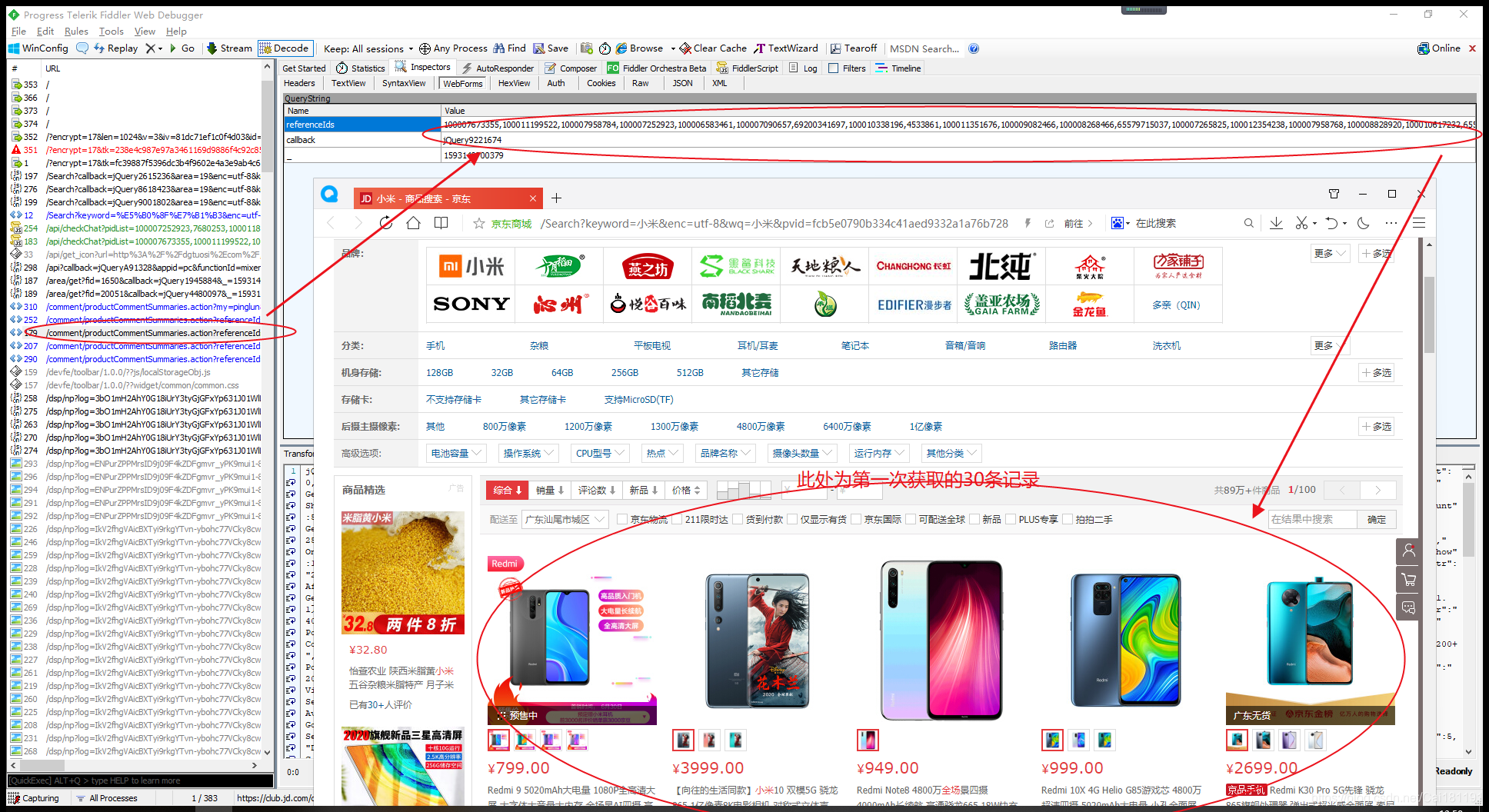
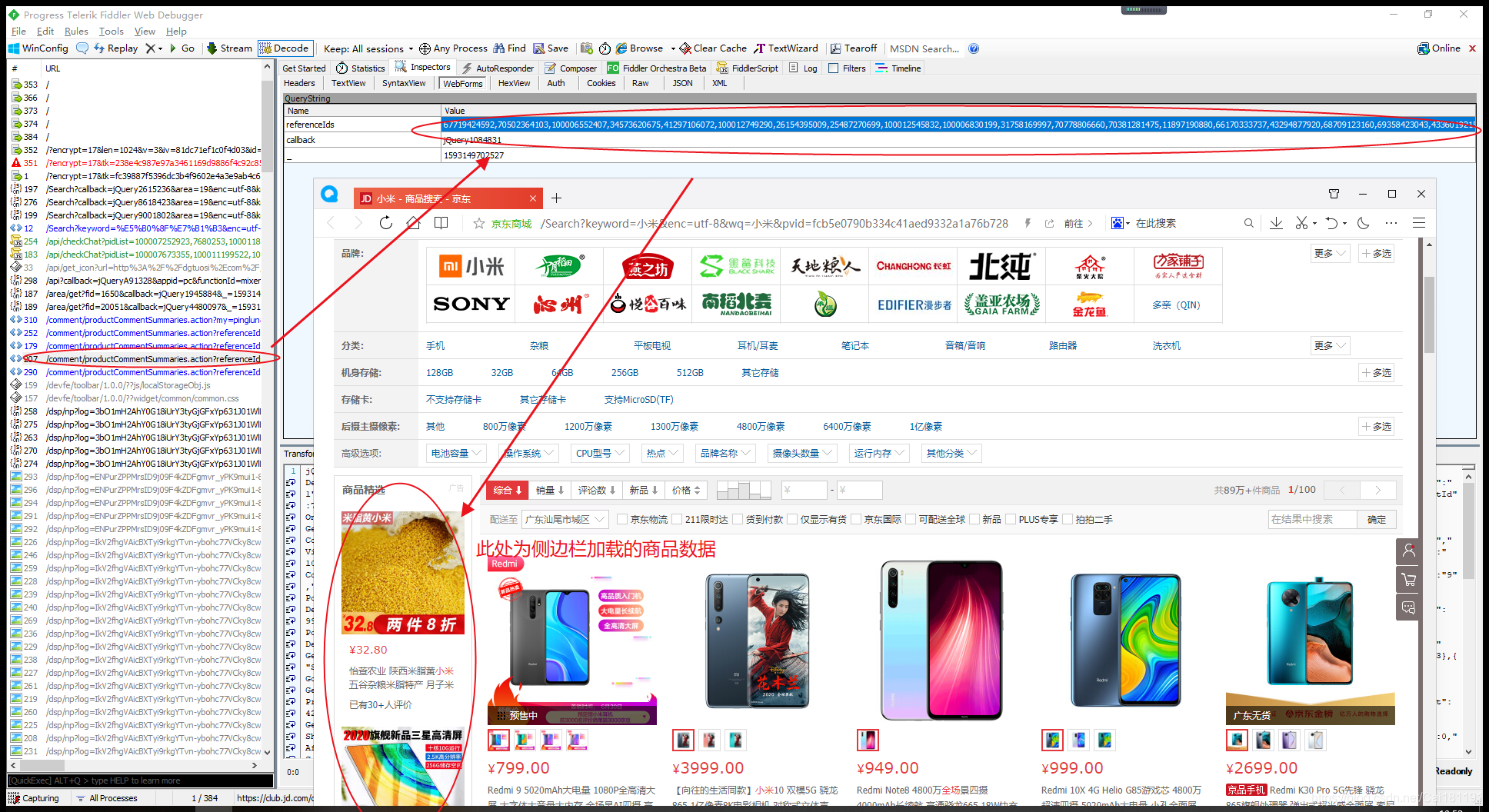
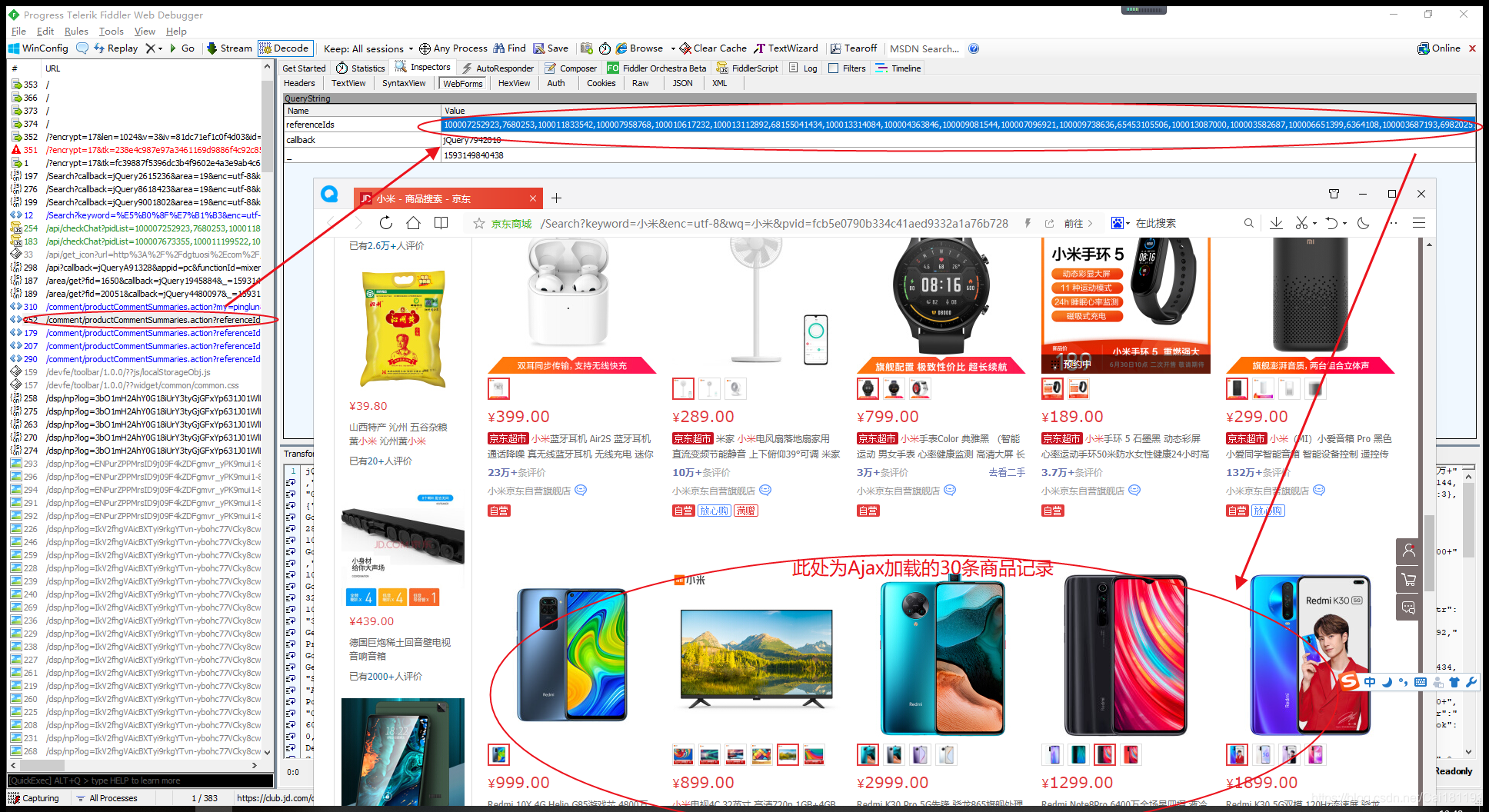


这里奉上一个简单的学习Demo,基于SpringBoot+HttpClient+Jsoup框架,只能获取每页的前30条商品数据,后30条异步加载的商品数据暂时没去实现,仅用于学习。
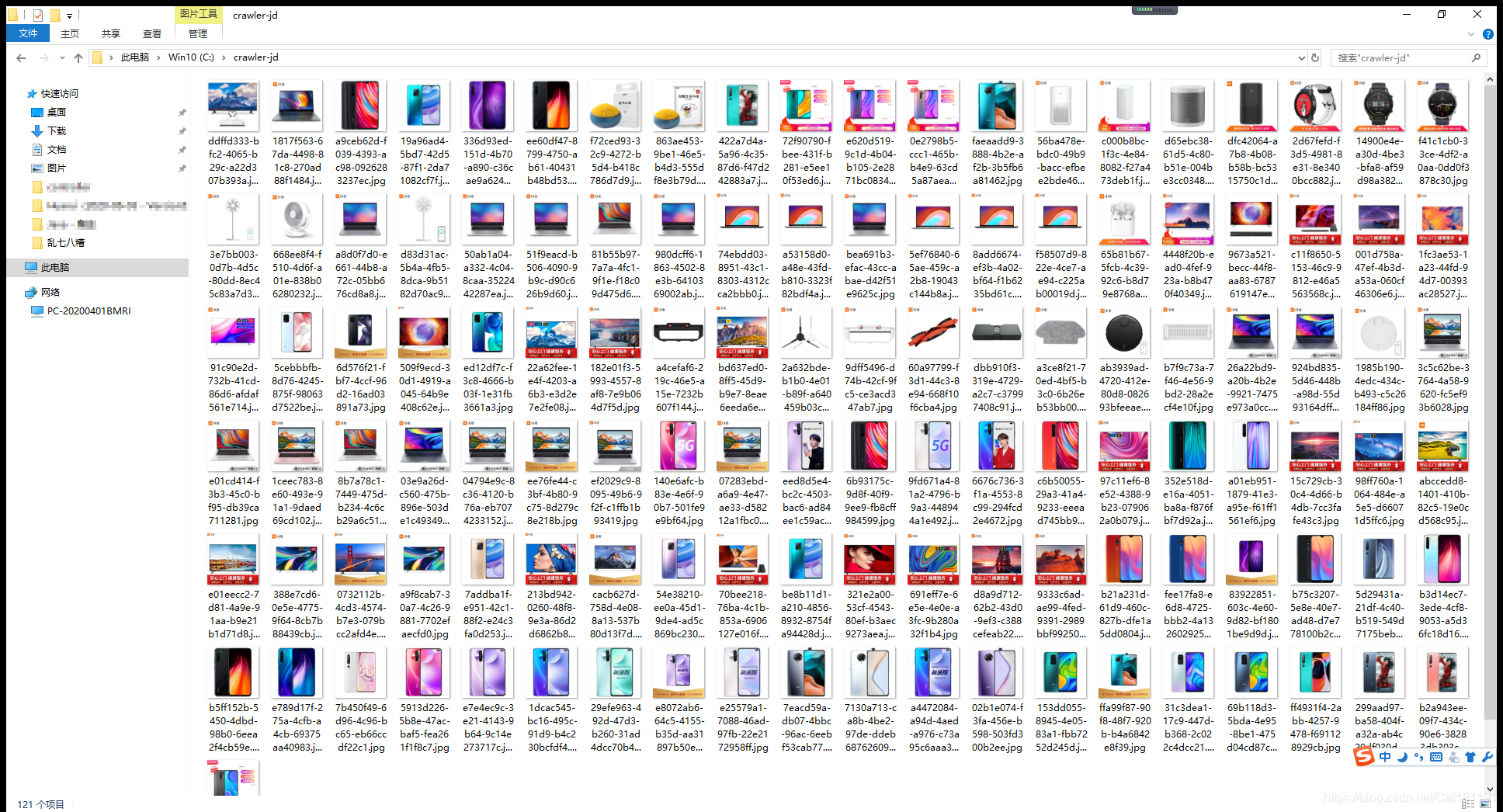
效果如下:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/151189.html

