
简单介绍:
缓存机制的存在,是为了当我们在执行重复的SQL代码的时候,不需要重新向数据库进行访问,而是将之前查询的结果存放在内存当中,从而减少我们重复的获取数据库连接进行查询时候消耗的资源,是一种加快查询速度,优化查询方式的一种方法。
在MyBatis中,缓存机制有两种,一种是默认的一级缓存,另一种是需要我们手动进行配置的二级缓存。一级缓存是SqlSession级别的缓存,当我们在使用同一个SqlSession多次执行相同的SQL查询语句之后,在第一次查询的时候,会将查询结果缓存到内存中。此后,如果程序不进行增删改查的操作,那么当之后多次执行相同的查询语句的时候,都只会从内存中获取数据,并不会连接到数据库。
使用方法:
由于MyBatis默认情况下就是采用的一级缓存,所以我们不需要做任何关于缓存的相关配置。为了方便我们观察SQL语句的执行过程,我们需要条件一个log4j的依赖,并且添加相关的配置文件,这个组件会帮我们把日志打印到控制台,方便我们观察我们SQL语句的执行过程。
pom依赖:
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>log4j的配置文件,这是一个properties文件:此处需要注意,log4j的配置文件的命名必须写作:log4j.properties,这是log4j的使用规范之一
log4j.rootLogger=DEBUG,console
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
代码实现:
在写好配置文件之后,我们就可以进行代码的测试了,我们只需要写一个简单的从用户表查询数据即可:
映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 接口式开发有两个规范: -->
<!--1.接口中方法的名称必须与SQL语句的唯一标识,也就是id的值保持一致,resultType就是接口中返回值的类型,parameterType就是接口中方法的参数的类型-->
<!-- 2.mapper标签的namespace属性必须是接口的全路径,否则在运行的时候会无法找到接口对象的SQL映射文件 -->
<mapper namespace="mappers.select">
<!-- 根据id查询单条数据-->
<select id="selectOne" resultType="User" parameterType="int">
select * from user where id = #{id};
</select>
<!-- 查询所有的数据-->
<select id="selectAll" resultType="User">
select * from user;
</select>
<!-- 增加一个数据-->
<insert id="insertInto" parameterType="User">
insert into user values (#{id} , #{name} , #{sex} , null , null);
</insert>
<!-- 删除一个数据-->
<delete id="deleteFromUser" parameterType="int">
delete from user where id = #{id};
</delete>
</mapper>测试类:
package mappers;
import com.mybatis.User;
import junit.framework.TestCase;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.InputStream;
import java.util.List;
public class selectTest extends TestCase {
SqlSession session = null;
select mapper = null;
public void setUp() throws Exception {
InputStream stream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(stream);
session = build.openSession(true);
mapper = session.getMapper(select.class);
}
public void testSelectOne() {
System.out.println("第一次查询:");
Object o = session.selectOne("mappers.select.selectOne", 1);
User u = (User)o;
System.out.println(u.toString());
System.out.println("第二次查询:");
Object o2 = session.selectOne("mappers.select.selectOne", 1);
User u2 = (User)o1;
System.out.println(u2.toString());
}
}在这个案例中,我们使用SqlSession对同一个SQL语句进行了两次查询, 重点在于我们接下来的运行结果在控制台的输出
运行结果:
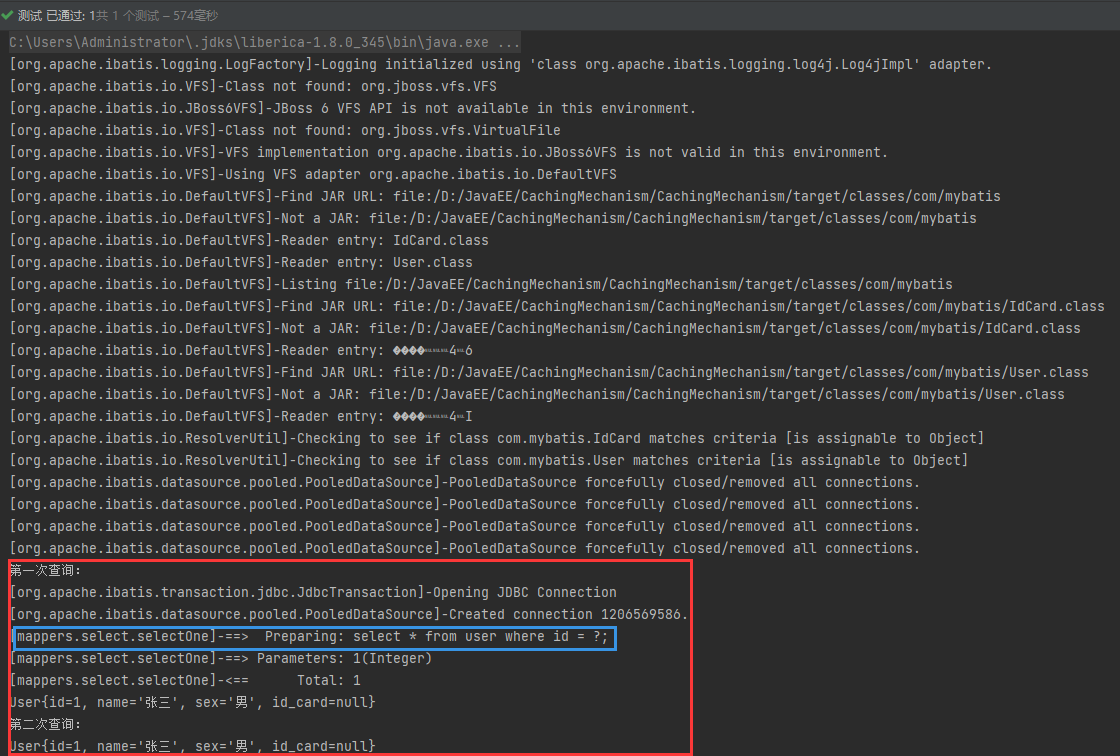
红色框的内容是我们两次查询的执行过程,其中我们可以看到,蓝色框的SQL语句的查询只在第一次查询的时候出现过,第二次查询的时候并没有任何的关系connection或者SQL语句之类的信息出现,说明这是直接从内存中获取到的上一次查询的缓存,这也就体现了我们MyBatis的一级缓存。
或者我们可以查询两条不一样的SQL语句来看一下区别:
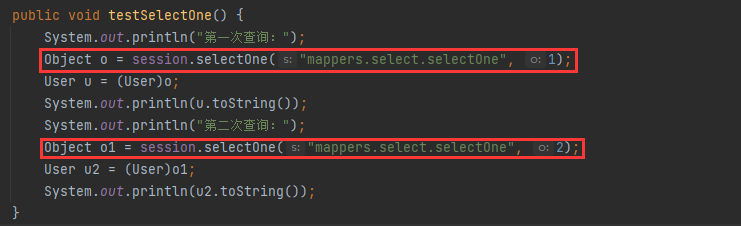
红色框里面的是两条不一样的SQL语句,SQL语句相同表示两条SQL语句必须是一摸一样,包括查询的参数。然后我们再来看控制台输出的信息:
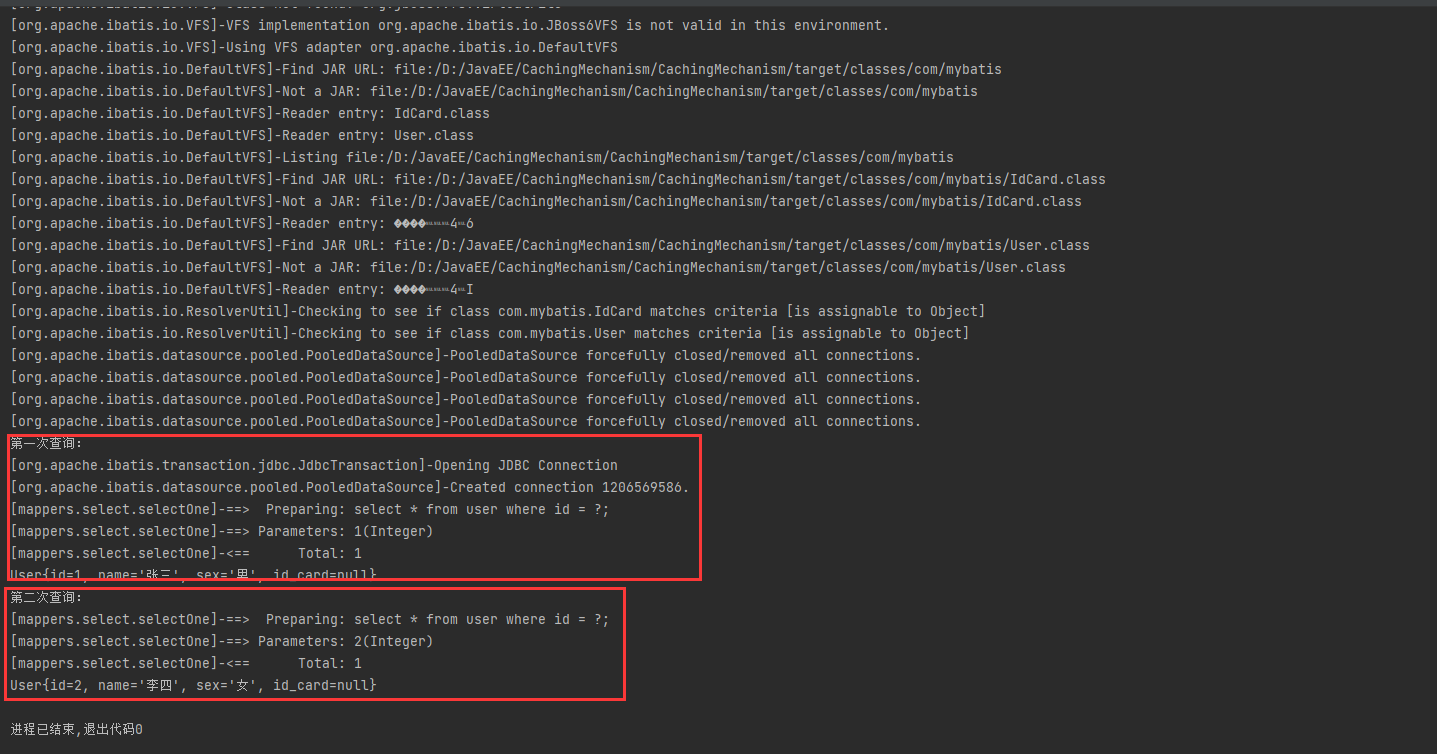 这里就可以很明显的看到,第二次SQL语句的查询依然是传递并执行了SQL语句,与上一个演示的案例的区别就很明显了。
这里就可以很明显的看到,第二次SQL语句的查询依然是传递并执行了SQL语句,与上一个演示的案例的区别就很明显了。
注意点:
MyBatis的一级缓存是默认的,并且一级缓存是针对于SqlSession的缓存,也就是只有当我们使用SqlSession进行查询的时候才能体现出一级缓存的作用,下一章我们会介绍针对于mapper的二级缓存机制。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/153299.html

