
一、进程内存空间
1.1 逻辑地址和物理地址
通过一个反编译的C语言文件查看逻辑地址
-
完整的C语言代码
#sample.c int sum(int x,int y) { return x+y; } int main() { sum(2,3); return 0; } -
使用gcc进行编译和汇编但不链接成可执行文件,得到目标二进制代码文件
#生成二进制文件 sample.o gcc -g -c sample.c -
使用objdump对sample.o进行反编译查看其汇编代码
#反汇编指令 objdump -d sample.o sample.o: 文件格式 elf64-x86-64 Disassembly of section .text: 0000000000000000 <sum>: 0: 55 push %rbp 1: 48 89 e5 mov %rsp,%rbp 4: 89 7d fc mov %edi,-0x4(%rbp) 7: 89 75 f8 mov %esi,-0x8(%rbp) a: 8b 55 fc mov -0x4(%rbp),%edx d: 8b 45 f8 mov -0x8(%rbp),%eax 10: 01 d0 add %edx,%eax 12: 5d pop %rbp 13: c3 retq 0000000000000014 <main>: 14: 55 push %rbp 15: 48 89 e5 mov %rsp,%rbp 18: be 03 00 00 00 mov $0x3,%esi 1d: bf 02 00 00 00 mov $0x2,%edi 22: e8 00 00 00 00 callq 27 <main+0x13> 27: b8 00 00 00 00 mov $0x0,%eax 2c: 5d pop %rbp 2d: c3 retq如上面的汇编代码所示,每条指令“:”前面的数字就是程序指令对应的逻辑地址,也称为虚拟地址。逻辑地址使用16进制表示,所有程序的逻辑地址都是从0开始的,后面跟着的数字是机器指令。
以sum函数对应的汇编代码进行分析:
0: 55 push %rbp 1: 48 89 e5 mov %rsp,%rbp 4: 89 7d fc mov %edi,-0x4(%rbp) 7: 89 75 f8 mov %esi,-0x8(%rbp) a: 8b 55 fc mov -0x4(%rbp),%edx d: 8b 45 f8 mov -0x8(%rbp),%eax 10: 01 d0 add %edx,%eax 12: 5d pop %rbp 13: c3 retq0x55指令对应一个字节,所以第二条指令的逻辑地址等于第一条指令逻辑地址+1=1,第二条指令0x48 89 e5对应3个字节,所以第三条指令的逻辑地址等于4,依次类推。
物理地址是内存单元看到的地址,是指令和数据真实存在的内存地址,而逻辑地址是面向程序而言的。CPU在执行指令的时候,会先将逻辑地址经过一个MMU(Memory Management Unti)的硬件设备转换成物理地址,然后从物理地址取出指令执行
1.2 进程的内存映像
以32位的机器为例,地址总线为32位,可寻址的最大内存空间是2^32Bytes,即4GB。每个运行的程序可以获得一个4GB的逻辑地址空间,这个地址空间被分为两部分:内核空间和用户空间,其中用户空间分配0x00000000到0xC0000000共3G的地址,而内核空间分配了0xC0000000到oxFFFFFFFF高位的1GB地址。
而用户进程的逻辑地址内容就是进程内存映像,一共包含四个部分的内容:
- text代码段:只读,存放代码的指令,上面反汇编后的文件中section .text表示的就是代码段
- data数据段:存放全局或静态变量
- heap堆:运行时(Run time)分配的内存(如用malloc函数申请内存)
- stack栈:存放局部变量和函数返回地址
下面通过代码查看各个部分在内存中的情况:
数据段
#dataSegment.c
int global_var = 5;
int main(int argc, char const *argv[])
{
static int static_var = 8;
return 0;
}
lizhi@Dog-li:~/test/c/memory$ gcc -g -c dataSegment.c
lizhi@Dog-li:~/test/c/memory$ objdump -s -d dataSegment.o
#部分代码如下
dataSegment.o: 文件格式 elf64-x86-64
Contents of section .text:
0000 554889e5 897dfc48 8975f0b8 00000000 UH...}.H.u......
0010 5dc3 ].
Contents of section .data:
0000 05000000 08000000
......
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 89 7d fc mov %edi,-0x4(%rbp)
7: 48 89 75 f0 mov %rsi,-0x10(%rbp)
b: b8 00 00 00 00 mov $0x0,%eax
10: 5d pop %rbp
11: c3 retq
如上所示,通过objdump -s将详细的内存信息都打印出来,Contents of section .text下展示的是代码段的指令对应的机器码,与Disassembly of section .text是一致的;而Contents of section .data展示的是数据段存放的值,代码中global_var和static_var分别对应5和8存放在数据段里面
堆栈段
堆栈数据只有在程序运行时才能在内存中看到,所以下面代码让程序处于休眠状态
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global_var = 5;
int main(int argc, char const *argv[])
{
static int static_var = 8;
int local_var = 10;
int* p = (int*)malloc(100);
printf("the global_var address is %1x\n", &global_var);
printf("the static_var address is %1x\n", &static_var);
printf("the local_var address is %1x\n", &local_var);
printf("the address with the p points to %1x\n", p);
free(p);
sleep(1000);
return 0;
}
#执行程序
lizhi@Dog-li:~/test/c/memory$ ./heapStack
the global_var address is 55bdc4b4a010
the static_var address is 55bdc4b4a014
the local_var address is 7ffd5a55169c
the address with the p points to 55bdc60be260
#查找进程对应的
lizhi@Dog-li:~$ ps -e |grep 'heapStack'
7322 pts/0 00:00:00 heapStack
#通过下面命令可以看到进程的相关段的大小限制以及进程的其他信息
lizhi@Dog-li:~$ cat /proc/6781/status
......
VmData: 176 kB
VmStk: 132 kB
VmExe: 4 kB
VmLib: 2108 kB
VmPTE: 52 kB
VmSwap: 0 kB
......
#通过下面命令可以看到当前正在运行进程的映射信息(程序各部分的地址段)
lizhi@Dog-li:~$ cat /proc/6781/maps
| 地址范围(from_to) | 权限| offset |设备ID| iNode|
55bdc4949000-55bdc494a000 r-xp 00000000 08:01 548264 /home/lizhi/test/c/memory/heapStack
55bdc4b49000-55bdc4b4a000 r--p 00000000 08:01 548264 /home/lizhi/test/c/memory/heapStack
55bdc4b4a000-55bdc4b4b000 rw-p 00001000 08:01 548264 /home/lizhi/test/c/memory/heapStack
55bdc60be000-55bdc60df000 rw-p 00000000 00:00 0 [heap]
7fee880d7000-7fee882be000 r-xp 00000000 08:01 923849 /lib/x86_64-linux-gnu/libc-2.27.so
7fee882be000-7fee884be000 ---p 001e7000 08:01 923849 /lib/x86_64-linux-gnu/libc-2.27.so
7fee884be000-7fee884c2000 r--p 001e7000 08:01 923849 /lib/x86_64-linux-gnu/libc-2.27.so
7fee884c2000-7fee884c4000 rw-p 001eb000 08:01 923849 /lib/x86_64-linux-gnu/libc-2.27.so
7fee884c4000-7fee884c8000 rw-p 00000000 00:00 0
7fee884c8000-7fee884ef000 r-xp 00000000 08:01 923821 /lib/x86_64-linux-gnu/ld-2.27.so
7fee886d9000-7fee886db000 rw-p 00000000 00:00 0
7fee886ef000-7fee886f0000 r--p 00027000 08:01 923821 /lib/x86_64-linux-gnu/ld-2.27.so
7fee886f0000-7fee886f1000 rw-p 00028000 08:01 923821 /lib/x86_64-linux-gnu/ld-2.27.so
7fee886f1000-7fee886f2000 rw-p 00000000 00:00 0
7ffd5a532000-7ffd5a553000 rw-p 00000000 00:00 0 [stack]
7ffd5a5d5000-7ffd5a5d8000 r--p 00000000 00:00 0 [vvar]
7ffd5a5d8000-7ffd5a5d9000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
上面的堆栈信息,显示了程序各个部分的Address(逻辑地址空间),Permissions,Offset,Device,iNode,PathName
- Address:程序映射占用的起始地址和结束地址
- Permission:readable,writable,executable,private,shared
- Offset:基于逻辑内存开始地址的在文件中的偏移量,并不是每个逻辑地址都是从文件映射,所以有的偏移量为0
- iNode:相关文件的编号
Offset和iNode在文件系统中会详细介绍
上面的堆栈信息中,第一行的权限是可读可执行,所以为代码段(text segmen);第三行的权限为可读可写,故为数据段(data segment),结合我们执行程序打印的各个变量和指针的内存地址,可以看到全局变量和静态变量的地址对应在数据段的地址范围,而局部变量的地址对应于栈的地址范围,指针的地址对应于堆的地址范围。
二、内存管理
2.1 内存介绍(Main Memory)
内存一般称之为主存,而磁盘等外部存储器称之为辅存,它们的硬件构造是完全不同的
-
Main Memory is certral to operation of a modern computer system
-
Memory contains of a large array of bytes,each with its own address.
内存包含了很多字节序列,每个字节都有一个地址与之对应
-
The CPU fetches(获取) instructions from memory according to the value of the program counter(PC).These instructions may cause addtional loading from and storing to specifi memory address.
PC寄存器:存放下一条要执行的指令的内存地址CPU根据PC寄存器中一条指令的地址从内存中获取指令,这些指令可能造成额外地从指定内存获取和向内存写入的动作
-
A typical instruction-execution cycle,for example,first fetches an instruction from memory.The instruction is then decoded and may cause operands to be fetched from memory.After the instruction has been executed on the operands,result may be stored back in memory.
经典的指令执行周期:首先从内存中获取一条指令,然后对指令进行解码,这个过程可能要再从内存中获取操作数,最后使用操作执行指令,指令运行的结果可能再被写入到内存
2.2 高速缓存(CACHE)
-
高速缓存是一种存取比内存快,但容量比内存小的多的存储器,它可以加快访问物理内存的相对速度
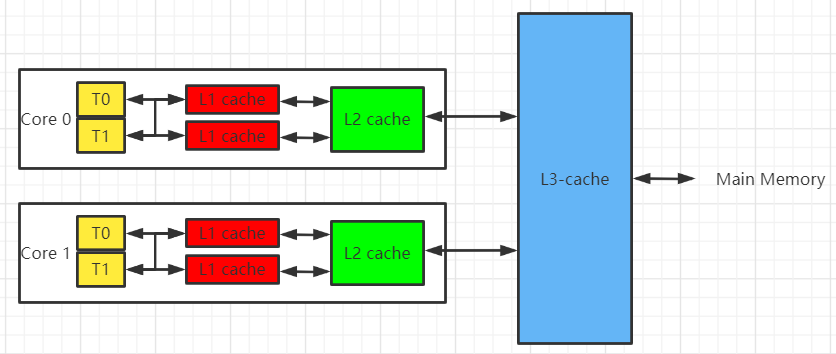

现代操作系统中,一般分为三级缓存,一级和二级缓存一般集成在CPU内部,缓存的级数越高,其容量也就越大,与之对应的存取速度也就越慢
对于多级别的缓存,数据一致性将是一个很重要的问题
2.3 内存数据保护
-
用户进程不可以访问操作系统内存数据,以及用户进程空间不能相互响应
-
通过硬件来实现,操作系统一般不干预CPU对内存的访问
base register:基址寄存器
limit register:限长寄存器
-
上述两个寄存器的值只能被操作系统的特权指令加载(Kernel模式下执行)
-
-
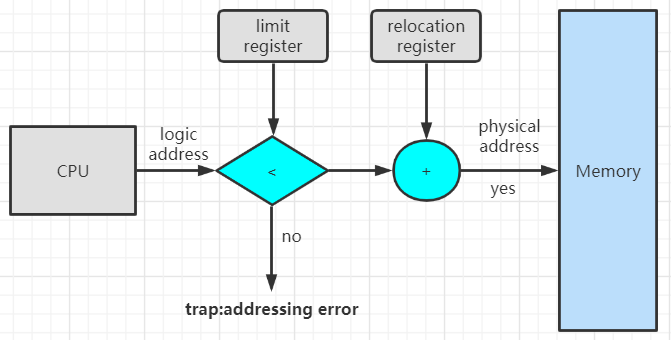
地址保护
策略:与限长寄存器的limit值进行比较
2.4 地址空间与转换
在前面进程内存空间部分,已经介绍过了逻辑地址和物理地址的概念
所有逻辑地址的集合称为逻辑地址空间,这些逻辑地址对应的所有物理地址集合称为物理地址空间
在一个程序中,每条指令的逻辑地址就是与第一条指令之间的相对偏移,所以逻辑地址也成为偏移地址(可以直接理解为偏移量)
每条指令的物理地址=程序起始指令的物理地址(基址)+逻辑地址(偏移量)
基址存放在基址寄存器(base register)
**地址转换:**由逻辑地址转换成物理地址
现代操作系统都是在程序运行时进行地址转换
内存管理单元MMU
-
Memory-Management Unit完成逻辑地址到物理地址运行时的转换工作
MMU基于重定位寄存器(relocation register)或基址寄存器(base register)工作
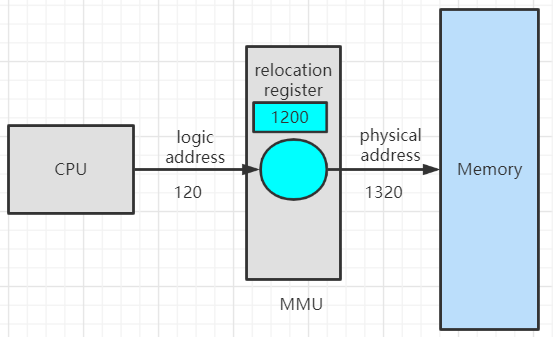
physical address = 1200(base address) + 120(logical address) = 1320
2.5 连续内存分配
In contiguous memory allocation,each process is contained in a single section of memory that is contiguous to the section containing the next process.
在连续内存分配中,每个进程包含一个单独的内存块且与下一个进程的内存块是连续的。每个进程所占用的内存也是连续的,
固定大小分区(FIXED-SISED PARTTION)
Memory is divided to serval fixed-sised partitions.Each partition may contain exactly one process.
操作系统将内存划分为数个大小不等的分区,每个分区恰好存放一个进程,同时操作系统需要维护一张内存分区表,记录每个分区的编号、基址、分区大小以及是否可用等信息
缺点:灵活性太差,操作系统对于最大分区分配多大内存没有标准,可能导致一个很大的进程因为需要更大的内存而无法使用;造成内部碎片,一个分区大小为10字节分配给了一个大小为6字节的进程,其中剩下的4个字节将无法被使用
内存回收时,是需要将内存分区表中信息改为可用即可
可变分区(VARIABLE-PARTITION)
-
In the variable-parition scheme,the operating system keeps two tables indicating which parts of memory are avariable and which are occupid
在可变分区中,操作系统需要维护两张表,分别指明内存是否可用;两张表都包含了基址、内存大小等信息
-
Initially,all memory is avariable for user processes and is considered one large block of avariable memory,a hold
初始的时候,所有的内存对于用于进程都是可用的,被看成是一大块可用内存,即一个孔
-
Eventually,as you willl see,memory contains a set of holes of various sizes.
最后,内存将会被分成一系列各种大小的孔
一开始内存还没有使用,可以看成一个孔,然后操作系统为每个程序分配满足运行大小的内存块,当一个程序运行完退出之后,之前分配的内存块就变成可用的了,操作系统就会在可用表里面记录该孔的信息(基址、内存大小等),当再有程序需要分配内存时,如果该孔的大小满足,就可以为新程序分配该孔
动态存储分配策略:
-
首次适应
操作系统查找可用内存表时,为程序分配首个满足程序的足够大的孔,效率最高
-
最佳适应
分配最小的可以满足程序的孔,浪费最小
-
最坏适应
分配最大的孔,产生的剩余孔更可能被利用;这种方案的最大问题是每次都使用最大的孔,如果有一个进程需要足够大的孔时,将无法为其分配孔导致无法执行
可变分区的内存回收时,从已用分区表中删除分区信息,同时插入到可用分区表
这两种连续分配方案的地址转换方式是相似: 物理地址=基址+逻辑地址
碎片
Fragmentation:some little piece of memory hardly to be used(很小的内存片,难以利用)
-
internal fragmentation(内部碎片)
相对于固定分区来说,例如一个分区有10K字节大小,分配给了一个只需要5K字节的程序,剩下的5K字节仍然属于该分区,处于分区内部,但不能分配给其他程序使用
-
external fragmentation(外部碎片)
相对可变分区来说,例如一个分区有10K字节大小,分配给一个只需要5K字节的程序后,剩下的5K字节形成了一个新的可用分区记录在表中,当有程序需要时,可以继续分配
对于可变分区产生的碎片,考虑进行压缩然后使用,将很多小的碎片分区合并成一个大的分区,但碎片压缩一定要考虑到对性能的影响
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/153684.html

