
快速排序利用的是分治的思想即“分而治之”。
其中心思想就是:
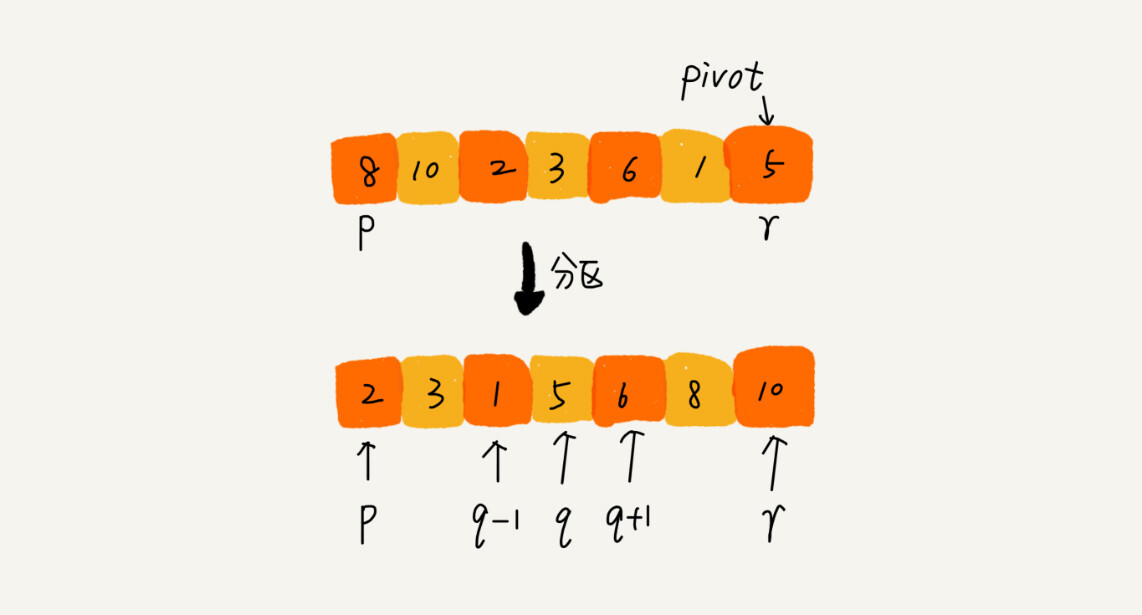
假如要对一个数组进行排序,可以先数组中随机找一个数作为分区点(pivot),从左往右遍历数组,将小于pivot的元素放在pivot的左边,将大于pivot的元素放在pivot的右边,这样数组就被分为了三个部分。
再根据分治、递归的思想用递归排序左边部分(小于pivot的元素) 、右边部分(大于pivot的元素),直到可排序的元素个数为1,就说明所有数据都是有序的了。

java实现以上步骤:
public static void quickSort(int[] arr,int start , int end){
if(start >= end) return;
int partition = partition(arr,start,end); // 获取分区点
quickSort( arr , start , partition-1); // 递归排序左边部分
quickSort( arr , partition + 1 , end); // 递归排序右边部分
}
如何获取分区点并对数组进行分区?
有一个比较简单办法就是将数组的最后一个元素作为分区点,申请两个临时数组,将小于该分区点的元素放入一个数组,将大于该分区点的元素放入另一个数组,最后将两个数组拷贝到原数组。但是这个办法比较消耗内存空间,且不是原地排序算法O(1)。故不被采纳。
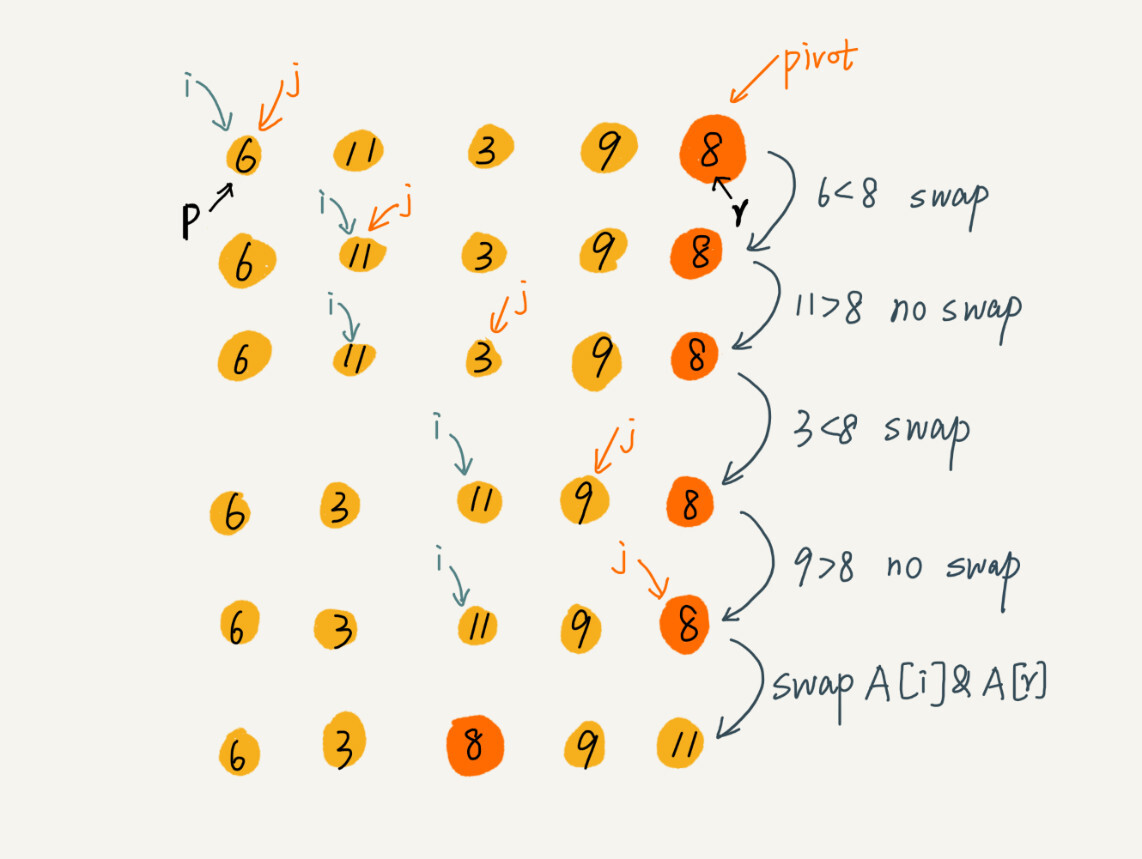
另一个方法就是,将数组arr的最后一个元素 (end) 作为分区点,指针 i 、j 指向数组arr的第一个元素,用 j 从左往右依次遍历,当 arr [ j ]所处下标的值小于分区点,则交换 arr [ j ] 、arr [ i ],当全部遍历完成,再交换 arr [ end ] 、arr[ i ]。
可以理解成 i 的左边是已处理区(并不是说真的有序),i 的右边是未处理区,j 遍历的就是未处理区,在 j 遍历的过程中找到所有比分区点小的数字 插入到 i 的尾部,最后处理完的时候 交换处理区的尾部和分区点 就是为了分隔开处理 已处理和未处理的数据,一直重复这个过程。
完整代码:
public static void quickSort(int[] arr,int start , int end){
if(start >= end) return;
int partition = partition(arr,start,end);
quickSort( arr , start , partition-1);
quickSort( arr , partition + 1 , end);
}
private static int partition(int[] arr, int start, int end) {
int k = arr[end]; // 基准值
int i = start;
for (int j = i; j < end; j++) {
if(arr[j] < k){
swap(arr,i,j);
i++;
}
}
swap(arr,i,end);
return i;
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154440.html

