
目录
5、创建对应实体类并利用MyBatis-Plus快速构建CRUD
1、 创建db_device_1数据库。并在数据库中创建两张物理表:
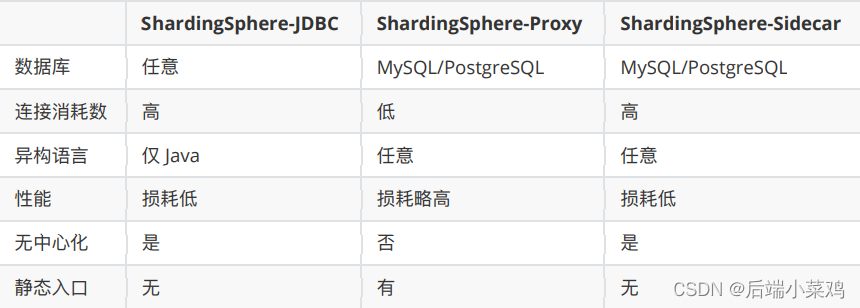
一.ShardingSphere介绍
Apache ShardingSphere 是⼀套开源的分布式数据库解决⽅案组成的⽣态圈,它由 JDBC、 Proxy 和 Sidecar(规划中)这 3 款既能够独⽴部署,⼜⽀持混合部署配合使⽤的产品组成。 它们均提供标准化的数据⽔平扩展、分布式事务和分布式治理等功能,可适⽤于如 Java 同 构、异构语⾔、云原⽣等各种多样化的应⽤场景。
Apache ShardingSphere 旨在充分合理地在分布式的场景下利⽤关系型数据库的计算和存储 能⼒,⽽并⾮实现⼀个全新的关系型数据库。 关系型数据库当今依然占有巨⼤市场份额,是 企业核⼼系统的基⽯,未来也难于撼动,我们更加注重在原有基础上提供增量,⽽⾮颠覆。
二.快速开始(分表)
1、创建数据库
创建名为db_device_0的数据库。
2、创建物理表
逻辑上tb_device表示的是描述设备信息的表,为了体现分表的概念,把tb_device表分成了两 张。于是tb_device就是逻辑表,⽽tb_device_0和tb_device_1就是该逻辑表的物理表。
CREATE TABLE `tb_device_0` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb3;
CREATE TABLE `tb_device_1` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb33、创建SpringBoot项目并引入依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>4、为application.properties添加配置
# 配置真实数据源
spring.shardingsphere.datasource.names=ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/db_device_0?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds1.username=db_device_0
spring.shardingsphere.datasource.ds1.password=db_device_0
# 配置物理表
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds1.tb_device_$->{0..1}
# 配置分表策略:根据device_id作为分⽚的依据(分⽚键、分片算法)
# 将device_id作为分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.sharding-column=device_id
# 用device_id % 2 来作为分片算法 奇数会存入 tb_device_1 偶数会存入 tb_device_0
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.algorithm-expression=tb_device_$->{device_id%2}
# 开启SQL显示
spring.shardingsphere.props.sql.show = true
5、创建对应实体类并利用MyBatis-Plus快速构建CRUD
package com.my.sharding.shperejdbc.demo.entity;
import lombok.Data;
@Data
public class TbDevice {
private Long deviceId;
private Integer deviceType;
}
6、主启动类配置
package com.my.sharding.shperejdbc.demo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
// 配置mybatis扫描的mapper!
@MapperScan("com.my.shardingshpere.jdbc.demo.mapper")
@SpringBootApplication
public class MyShardingShpereJdbcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(MyShardingShpereJdbcDemoApplication.class, args);
}
}7、编写测试
@SpringBootTest
class MyShardingShpereJdbcDemoApplicationTests {
@Autowired
DeviceMapper deviceMapper;
@Test
void testInitData(){
for (int i = 0; i < 10; i++) {
TbDevice tbDevice = new TbDevice();
tbDevice.setDeviceId((long) i);
tbDevice.setDeviceType(i);
deviceMapper.insert(tbDevice);
}
}
}运行并查看数据库:
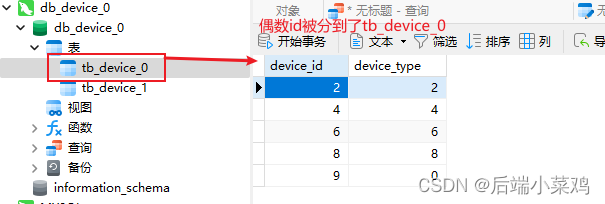
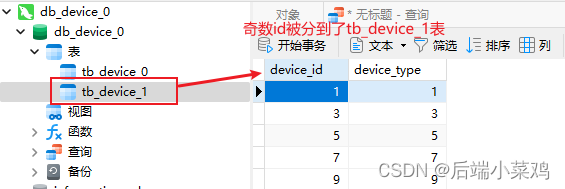
发现,根据分⽚策略,这10条数据中id是奇数的数据将会被插⼊到tb_device_1表中,id是奇 数的数据将会被插⼊到tb_device_0表中。
三.尝试分库分表
1、 创建db_device_1数据库。并在数据库中创建两张物理表:
CREATE TABLE `tb_device_0` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb3;
CREATE TABLE `tb_device_1` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb32、调整数据源配置
提供两个数据源,将之前创建的两个MySQL数据库作为数据源,并创建分库策略
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/db_device_0?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds0.username=db_device_0
spring.shardingsphere.datasource.ds0.password=db_device_0
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/db_device_1?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds1.username=db_device_1
spring.shardingsphere.datasource.ds1.password=db_device_1
# 配置物理表
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds$->{0..1}.tb_device_$->{0..1}
# 配置分库策略
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
# ⾏表达式分⽚策略 使⽤Groovy的表达式
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{device_id%2}
# 配置分表策略:根据device_id作为分⽚的依据(分⽚键、分片算法)
# 将device_id作为分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
# ⾏表达式分⽚策略 使⽤Groovy的表达式
# 用device_id % 2 来作为分片算法 奇数会存入 tb_device_1 偶数会存入 tb_device_0
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.algorithm-expression=tb_device_$->{device_id%2}
# 开启SQL显示
spring.shardingsphere.props.sql.show = true
相⽐之前的配置,这次加⼊了两个数据库的分⽚策略,根据device_id的奇偶特性决定存⼊哪 个数据库中。同时,使⽤groovy脚本确定了数据库和表之间的关系。
ds$->{0..1}.tb_device_$->{0..1}相当于:
ds0.tb_device_0
ds0.tb_device_1
ds1.tb_device_0
ds1.tb_device_13、运行测试类
结果:发现device_id的奇数数据会存⼊ ds1.tb_device_1 表中,偶数数据会 存⼊ ds0.tb_device_0 表中。
四.在分库分表下做查询
1、根据device_id查询
/**
* 根据device_id查询
*/
@Test
void testQueryByDeviceId(){
QueryWrapper<TbDevice> wrapper = new QueryWrapper<>();
wrapper.eq("device_id",1);
List<TbDevice> list = deviceMapper.selectList(wrapper);
list.stream().forEach(e->{
System.out.println(e);
});
}结果:TbDevice(deviceId=1, deviceType=1)
且查询的库为tb_device_1
2、根据device_id范围查询
/**
* 根据 device_id 范围查询
*/
@Test
void testDeviceByRange(){
QueryWrapper<TbDevice> wrapper = new QueryWrapper<>();
wrapper.between("device_id",1,10);
List<TbDevice> devices = deviceMapper.selectList(wrapper);
devices.stream().forEach(e->{
System.out.println(e);
});
}结果:
Error querying database. Cause: java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue(columnName=device_id, tableName=tb_device, valueRange=[1‥10])原因:inline的分⽚策略没有办法⽀持范围查询。
四.分库分表核⼼知识点
1.核⼼概念
在了解分⽚策略之前,先来了解以下⼏个重点概念:逻辑表、真实表、数据节点、绑定表、 ⼴播表。
- 逻辑表
⽔平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分 为10张表,分别是 t_order_0 到 t_order_9 ,他们的逻辑表名为 t_order 。
- 真实表
在分⽚的数据库中真实存在的物理表。即上个示例中的 t_order_0 到 t_order_9 。
- 数据节点
数据分⽚的最⼩单元。由数据源名称和数据表组成,例: ds_0.t_order_0 。
- 绑定表
指分⽚规则⼀致的主表和⼦表。例如: t_order 表和 t_order_item 表,均按照 order_id 分 ⽚,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联 查询效率将⼤⼤提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);在不配置绑定表关系时,假设分⽚键 order_id 将数值10路由⾄第0⽚,将数值11路由⾄第1 ⽚,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);其中 t_order 在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路 由计算将会只使⽤主表的策略,那么 t_order_item 表的分⽚计算将会使⽤ t_order 的条件。 故绑定表之间的分区键要完全相同。
2.分片及分片策略
1)分片键
⽤于分⽚的数据库字段,是将数据库(表)⽔平拆分的关键字段。例:将订单表中的订单主键的 尾数取模分⽚,则订单主键为分⽚字段。 SQL中如果⽆分⽚字段,将执⾏全路由,性能较 差。 除了对单分⽚字段的⽀持,ShardingSphere也⽀持根据多个字段进⾏分⽚。
2)分⽚算法
通过分⽚算法将数据分⽚,⽀持通过 = 、 >= 、 、 < 、 BETWEEN 和 IN 分⽚。分⽚算法 需要应⽤⽅开发者⾃⾏实现,可实现的灵活度⾮常⾼。 ⽬前提供4种分⽚算法。由于分⽚算法和业务实现紧密相关,因此并未提供内置分⽚算法,⽽ 是通过分⽚策略将各种场景提炼出来,提供更⾼层级的抽象,并提供接⼝让应⽤开发者⾃⾏ 实现分⽚算法
- 精确分⽚算法
对应PreciseShardingAlgorithm,⽤于处理使⽤单⼀键作为分⽚键的=与IN进⾏分⽚的场景。 需要配合StandardShardingStrategy使⽤。
- 范围分⽚算法
对应RangeShardingAlgorithm,⽤于处理使⽤单⼀键作为分⽚键的BETWEEN AND、>、=、<=进⾏分⽚的场景。需要配合StandardShardingStrategy使⽤。
- 复合分⽚算法
对应ComplexKeysShardingAlgorithm,⽤于处理使⽤多键作为分⽚键进⾏分⽚的场景,包 含多个分⽚键的逻辑较复杂,需要应⽤开发者⾃⾏处理其中的复杂度。需要配合 ComplexShardingStrategy使⽤。
- Hint分⽚算法
对应HintShardingAlgorithm,⽤于处理使⽤Hint⾏分⽚的场景。需要配HintShardingStrategy使⽤。
3)分片策略
包含分⽚键和分⽚算法,由于分⽚算法的独⽴性,将其独⽴抽离。真正可⽤于分⽚操作的是 分⽚键 + 分⽚算法,也就是分⽚策略。⽬前提供5种分⽚策略。
-
标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, >, =, , =, <=分⽚,如果不配置 RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
- 复合分片策略
对应ComplexShardingStrategy。复合分⽚策略。提供对SQL语句中的=, >, =, <=, IN和 BETWEEN AND的分⽚操作⽀持。ComplexShardingStrategy⽀持多分⽚键,由于多分⽚键 之间的关系复杂,因此并未进⾏过多的封装,⽽是直接将分⽚键值组合以及分⽚操作符透传 ⾄分⽚算法,完全由应⽤开发者实现,提供最⼤的灵活度。
- ⾏表达式分片策略
对应InlineShardingStrategy。使⽤Groovy的表达式,提供对SQL语句中的=和IN的分⽚操作 ⽀持,只⽀持单分⽚键。对于简单的分⽚算法,可以通过简单的配置使⽤,从⽽避免繁琐的 Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,⽽分成8张表,表名 称为 t_user_0 到 t_user_7 。
- Hint分片策略
对应HintShardingStrategy。通过Hint指定分⽚值⽽⾮从SQL中提取分⽚值的⽅式进⾏分⽚的 策略。
- 不分片策略
对应NoneShardingStrategy。不分⽚的策略。
3.分⽚策略的实现
1)Standard标准分⽚策略的精准分片
在Standard标准分⽚策略可以分别配置在分库和分表中。配置时需要指明分⽚键,精确分⽚ 或范围分⽚。
- 配置分库的精确分片
# 配置分库策略 为 标准分片策略的精准分片
#standard
spring.shardingsphere.sharding.default-databaswe-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBasePreciseAlgorithm
需要提供⼀个实现精确分⽚算法的实现类,其中精确分⽚的逻辑可以与inline中的⾏表达式⽤ 意相同。
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyDataBasePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
*
* 数据库标准分片策略
* @param collection 数据源集合
* @param preciseShardingValue 分片条件
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
// 获取逻辑表明 tb_device
String logicTableName = preciseShardingValue.getLogicTableName();
// 获取分片键
String columnName = preciseShardingValue.getColumnName();
// 获取分片键的具体值
Long value = preciseShardingValue.getValue();
//根据分⽚策略:ds$->{device_id % 2} 做精确分⽚
String shardingKey = "ds"+(value%2);
if(!collection.contains(shardingKey)){
throw new UnsupportedOperationException("数据源:"+shardingKey+"不存在!");
}
return shardingKey;
}
}- 配置分表的精确分⽚
# 配置分表策略 为 标准分片策略的精准分片
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTablePreciseAlgorithm
同时,需要提供分表的精确分⽚算法的实现类。
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyTablePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
String logicTableName = preciseShardingValue.getLogicTableName(); // 获取逻辑表名
Long value = preciseShardingValue.getValue(); // 获取具体分片键值
String shardingKey = logicTableName+"_"+(value % 2);
if(!collection.contains(shardingKey)){
throw new UnsupportedOperationException("数据表:"+shardingKey+"不存在!");
}
return shardingKey;
}
}测试之前根据id精准查询的测试用例,与之前效果相同,根据id查询到某个库中的某张表中
2)Standard标准分⽚策略的范围分⽚
- 配置分库的范围分⽚
spring.shardingsphere.sharding.default-databaswe-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBasePreciseAlgorithm
spring.shardingsphere.sharding.default-database-strategy.standard.range-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBaseRangeAlgorithm
提供范围查询算法的实现类。
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
public class MyDataBaseRangeAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* 直接返回所有的数据源
* 由于范围查询,需要在两个库的两张表中查。
* @param collection 具体的数据源集合
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
}
- 配置分表的范围分⽚
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTablePreciseAlgorithm
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.range-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTableRangeAlgorithm
提供范围查询算法的实现类:
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
public class MyTableRangeAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
}此时,再运⾏范围查询的测试⽤例,发现成功了。
3) Complex分⽚策略
@Test
void queryDeviceByRangeAndDeviceType(){
QueryWrapper<TbDevice> queryWrapper = new QueryWrapper<>();
queryWrapper.between("device_id",1,10);
queryWrapper.eq("device_type", 5);
List<TbDevice> deviceList =
deviceMapper.selectList(queryWrapper);
System.out.println(deviceList);
}以上测试代码出现的问题:
在对device_id进⾏范围查询的同时,需要根据device_type做精确查找,发现此时也需要查两 个库的三张表,但是奇数的device_type只会在奇数库的奇数表中,此时冗余了多次不必要的 查询。
为了解决冗余的多次查找,可以使⽤complex的分⽚策略。
- complex的分⽚策略
⽀持多个字段的分⽚策略。
# 配置分库策略 complex 传入多个分片键
spring.shardingsphere.sharding.default-database-strategy.complex.sharding-columns=device_id,device_type
spring.shardingsphere.sharding.default-database-strategy.complex.algorithm-class-name=com.sharding.algorithm.database.MyDataBaseComplexAlgorithm
# 配置分表策略 complex 传入多个分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.complex.sharding-columns=device_id,device_type
spring.shardingsphere.sharding.tables.tb_device.table-strategy.complex.algorithm-class-name=com.sharding.algorithm.table.MyTableComplexAlgorithm
- 配置分库的算法实现类
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class MyDataBaseComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
/**
*
* @param collection
* @param complexKeysShardingValue
* @return 这一次要查找的数据节点集合
*/
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
Collection<Integer> deviceTypeValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("device_type");
Collection<String> databases = new ArrayList<>();
for (Integer deviceTypeValue : deviceTypeValues) {
String databaseName = "ds"+(deviceTypeValue % 2);
databases.add(databaseName);
}
return databases;
}
}- 配置分表的算法实现类
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class MyTableComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
String logicTableName = complexKeysShardingValue.getLogicTableName();
Collection<Integer> deviceTypeValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("device_type");
Collection<String> tables = new ArrayList<>();
for (Integer deviceTypeValue : deviceTypeValues) {
tables.add(logicTableName+"_"+(deviceTypeValue%2));
}
return tables;
}
}测试:

只查询了一次数据库
4) Hint强制路由策略
hint可以不根据sql语句特性,强制路由到某个库的某个表中。
# 配置分库策略 ## ⾏表达式分⽚策略 使⽤Groovy的表达式
# inline
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{device_id%2}
配置hint算法的实现类
import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.Arrays;
import java.util.Collection;
public class MyTableHintAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
String logicTableName = hintShardingValue.getLogicTableName();
String tableName = logicTableName + "_" +hintShardingValue.getValues().toArray()[0];
if(!collection.contains(tableName)){
throw new UnsupportedOperationException("数据表:"+tableName + "不存在");
}
return Arrays.asList(tableName);
}
}测试用例:
@Test
void testHint(){
HintManager hintManager = HintManager.getInstance();
hintManager.addTableShardingValue("tb_device",0); // 强制指定只查询tb_device_0表
List<TbDevice> devices = deviceMapper.selectList(null);
devices.stream().forEach(System.out::println);
}结果:

4.绑定表
先来模拟笛卡尔积的出现。
- 给两个库创建 tb_device_info_0,tb_device_info_1表:
CREATE TABLE `tb_device_info_0` (
`id` bigint NOT NULL,
`device_id` bigint DEFAULT NULL,
`device_intro` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- 配置 tb_device 和 tb_device_info 表的分⽚策略。
#tb_device表的分⽚策略
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds$->
{0..1}.tb_device_$->{0..1}
spring.shardingsphere.sharding.tables.tb_device.tablestrategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.tablestrategy.inline.algorithm-expression=tb_device_$->{device_id%2}
#tb_device_info表的分⽚策略
spring.shardingsphere.sharding.tables.tb_device_info.actual-datanodes=ds$->{0..1}.tb_device_info_$->{0..1}
spring.shardingsphere.sharding.tables.tb_device_info.tablestrategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device_info.tablestrategy.inline.algorithm-expression=tb_device_info_$->{device_id%2}两张表的分⽚键都是device_id。
- 编写测试⽤例,插⼊数据
@Test
void testInsertDeviceInfo(){
for (int i = 0; i < 10; i++) {
TbDevice tbDevice = new TbDevice();
tbDevice.setDeviceId((long) i);
tbDevice.setDeviceType(i);
deviceMapper.insert(tbDevice);
TbDeviceInfo tbDeviceInfo = new TbDeviceInfo();
tbDeviceInfo.setDeviceId((long) i);
tbDeviceInfo.setDeviceIntro(""+i);
deviceInfoMapper.insert(tbDeviceInfo);
}
}- join查询出现笛卡尔积
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.lc.entity.TbDeviceInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface DeviceInfoMapper extends BaseMapper<TbDeviceInfo> {
@Select("select a.id,a.device_id,b.device_type,a.device_intro from tb_device_info a left join tb_device b on a.device_id = b.device_id")
public List<TbDeviceInfo> queryDeviceInfo();
}
@Test
void testQueryDeviceInfo(){
List<TbDeviceInfo> tbDeviceInfos = deviceInfoMapper.queryDeviceInfo();
tbDeviceInfos.stream().forEach(System.out::println);
}结果:
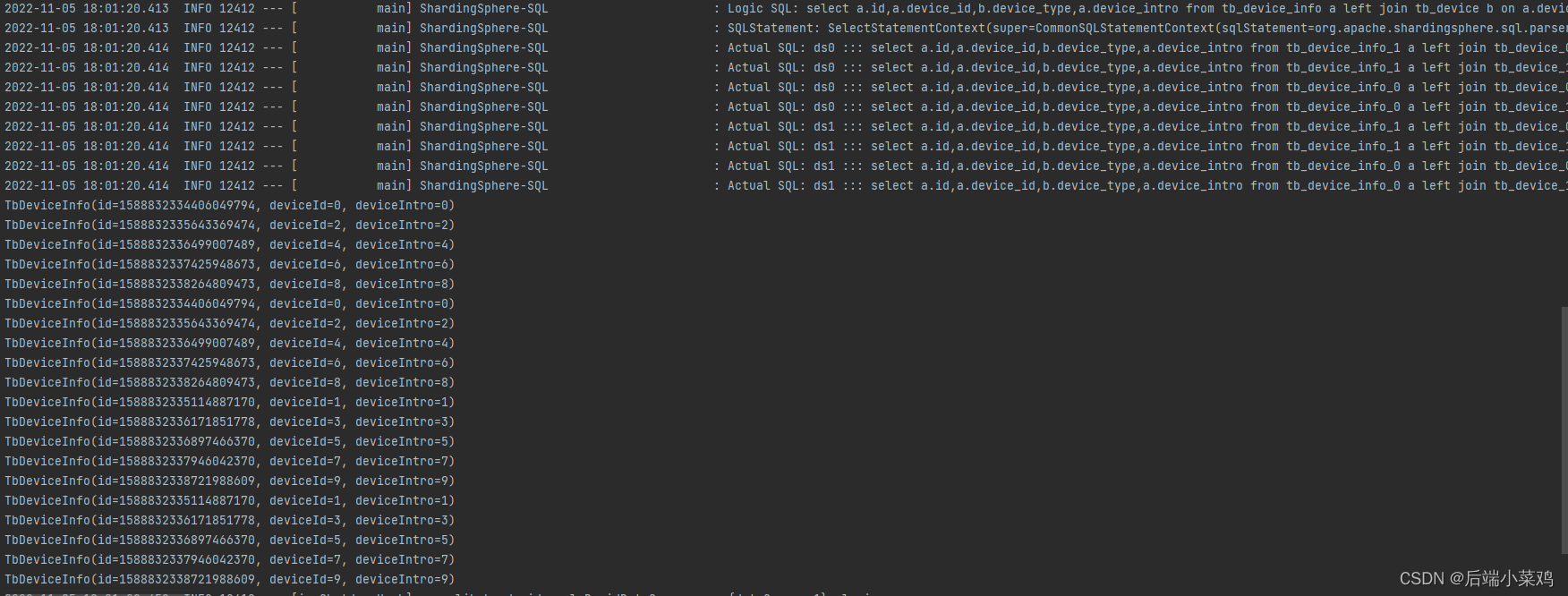
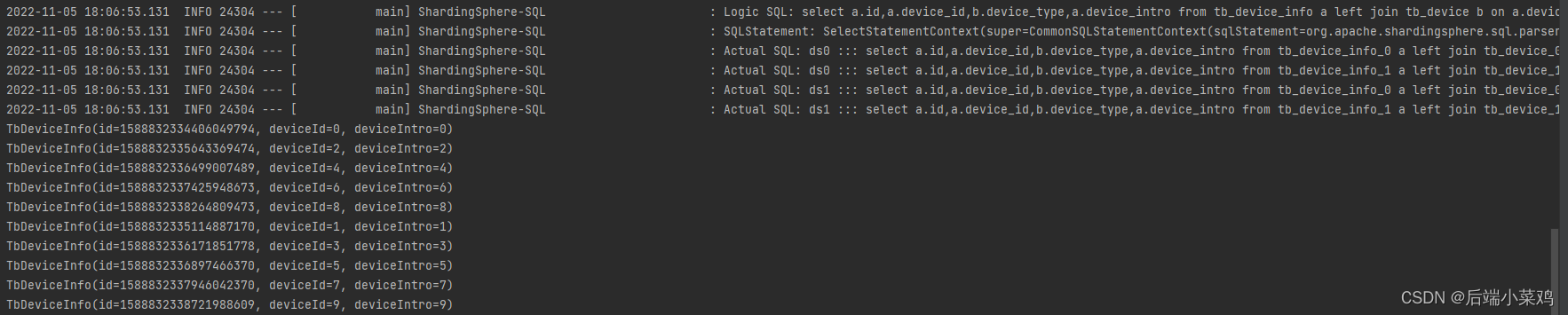
可以看见,产生了笛卡尔积,查出了20条数据
- 配置绑定表
# 配置 绑定表
spring.shardingsphere.sharding.binding-tables[0]=tb_device,tb_device_info再次查询,不再出现笛卡尔积:
5.⼴播表
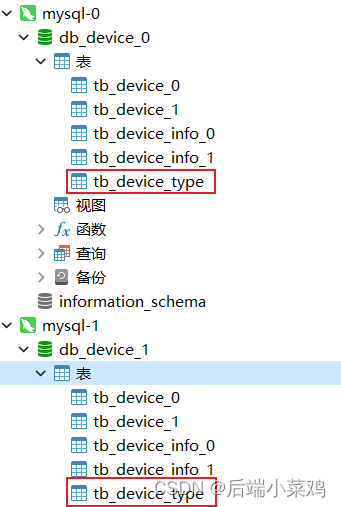
现在有这么⼀个场景,device_type列对应的tb_device_type表中的数据,不应该被分表,两 个库中都应该有全量的该表的数据。
- 在两个数据库中创建 tb_device_type 表
CREATE TABLE `tb_device_type` (
`type_id` int NOT NULL AUTO_INCREMENT,
`type_name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`type_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- 配置⼴播表
#⼴播表配置
spring.shardingsphere.sharding.broadcast-tables=tb_device_type
spring.shardingsphere.sharding.tables.tb_device_type.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.tb_device_type.key-generator.column=type_id- 编写测试⽤例
@Test
void testInsertDeviceType(){
TbDeviceType tbDeviceType = new TbDeviceType();
tbDeviceType.setTypeId(1l);
tbDeviceType.setTypeName("消防器材");
deviceTypeMapper.insert(tbDeviceType);
TbDeviceType tbDeviceType1 = new TbDeviceType();
tbDeviceType1.setTypeId(2l);
tbDeviceType1.setTypeName("健身器材");
deviceTypeMapper.insert(tbDeviceType1);
}结果:
两个库的两张tb_device_type都插入了两条数据
五.实现读写分离
1.搭建主从同步数据库
- 主从同步原理
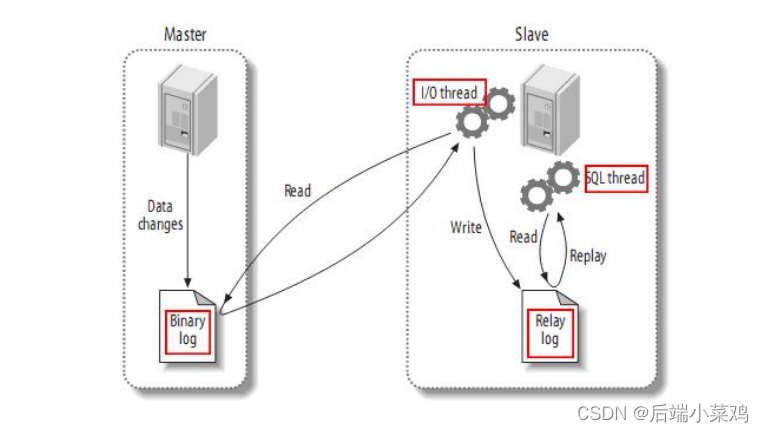
Master将数据写⼊到binlog⽇志中。Slave读取主节点的Binlog数据到本地的relaylog⽇志⽂ 件中。此时,Slave持续不断的与Master同步,且数据存在于relaylog中,⽽并⾮落在数据 库。于是Slave开启⼀条线程,专⻔讲relaylog中的数据写⼊到数据库中。
- 准备Master主库与Slave从库
在 usr/local/docker/mysql 下创建 docker-compose.yml 在其写入:
version: '3.1'
services:
mysql:
restart: "always"
image: mysql:5.7.25
container_name: mysql-test-master
ports:
- 3308:3308
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
command:
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
--max_allowed_packet=128M
--server-id=47
--log_bin=master-bin
--log_bin-index=master-bin.index
--skip-name-resolve
--sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO"
volumes:
- mysql-data:/var/lib/mysql
volumes:
mysql-data:
version: '3.1'
services:
mysql:
restart: "always"
image: mysql:5.7.25
container_name: mysql-test-slave
ports:
- 3309:3309
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
command:
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
--max_allowed_packet=128M
--server-id=48
--relay-log=slave-relay-bin
--relay-log-index=slave-relay-bin.index
--log-bin=mysql-bin
--log-slave-updates=1
--sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO"
volumes:
- mysql-data:/var/lib/mysql1
volumes:
mysql-data:使用 docker-compose up -d 启动
注意其中的配置:
主库:
服务id:server-id=47
开启binlog:log_bin=master-bin
binlog索引:log_bin-index=master-bin.index
从库:
服务id:server-id=48
开启中继⽇志:relay-log-index=slave-relay-bin.index
开启中继⽇志:relay-log=slave-relay-bin
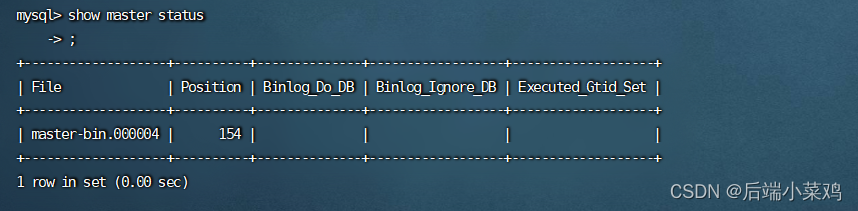
使用bash命令进入master主库容器中,使用 show master status 查看 记录文件名与偏移量
 使用bash命令进入slave从库容器中,并依次执⾏如下命令:
使用bash命令进入slave从库容器中,并依次执⾏如下命令:
#登录从服务
mysql -u root -p;
#设置同步主节点:
CHANGE MASTER TO
MASTER_HOST='主库地址',
MASTER_PORT=3306,
MASTER_USER='root',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='master-bin.000006',
MASTER_LOG_POS=154;
#开启slave
start slave;
⾄此,主从同步集群搭建完成。
在主库中创建 db_device 数据库,并在库中创建表:
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;发现刷新后在从库也同步创建了该表。
2.使⽤sharding-jdbc实现读写分离
- 编写配置⽂件
spring.shardingsphere.datasource.names=s0,m0
#配置主数据源
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/db_device?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
# 配置从数据源
spring.shardingsphere.datasource.s1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.url=jdbc:mysql://localhost:3306/db_device?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.s1.username=root
spring.shardingsphere.datasource.s1.password=123456
# 分配读写规则
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names[0]=s0
# 确定实际表
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds0.tb_user
# 确定主键⽣成策略
spring.shardingsphere.sharding.tables.t_dict.key-generator.column=id
spring.shardingsphere.sharding.tables.t_dict.key-generator.type=SNOWFLAKE
# 开启显示sql语句
spring.shardingsphere.props.sql.show = true- 测试写数据
@Test
void testInsertUser(){
for (int i = 0; i < 10; i++) {
TbUser user = new TbUser();
user.setName(""+i);
userMapper.insert(user);
}
此时,所有的数据只会往主库中写,然后再同步到从库。
- 测试读数据
Test
void testQueryUser(){
List<TbUser> tbUsers = userMapper.selectList(null);
tbUsers.forEach( tbUser -> System.out.println(tbUser));
}此时,所有的数据都读⾃于从库。
六.实现原理-连接模式
ShardingSphere 采⽤⼀套⾃动化的执⾏引擎,负责将路由和改写完成之后的真实 SQL 安全 且⾼效发送到底层数据源执⾏。 它不是简单地将 SQL 通过 JDBC 直接发送⾄数据源执⾏;也 并⾮直接将执⾏请求放⼊线程池去并发执⾏。它更关注平衡数据源连接创建以及内存占⽤所 产⽣的消耗,以及最⼤限度地合理利⽤并发等问题。 执⾏引擎的⽬标是⾃动化的平衡资源控 制与执⾏效率。
6.1.连接模式
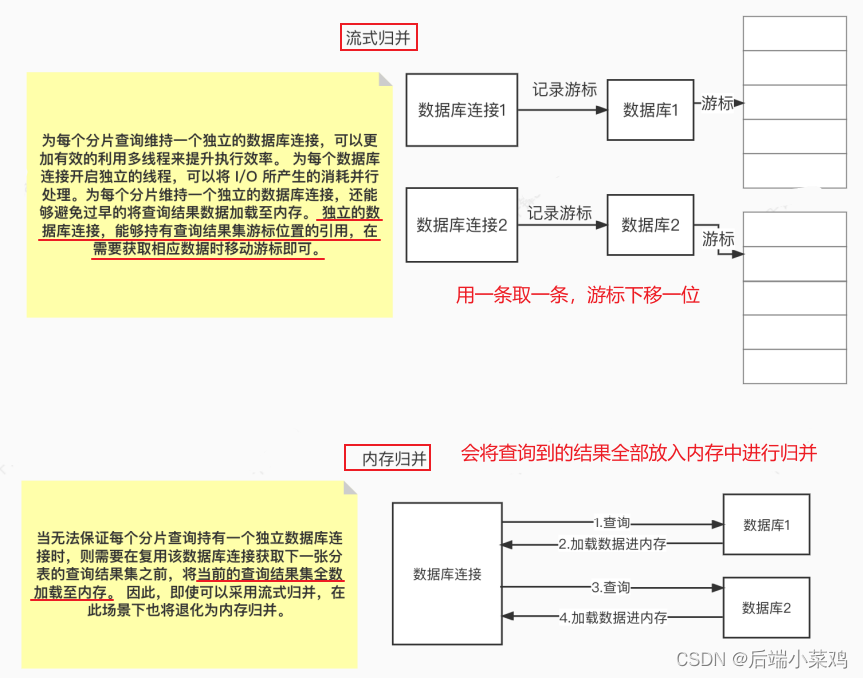
从资源控制的⻆度看,业务⽅访问数据库的连接数量应当有所限制。 它能够有效地防⽌某⼀ 业务操作过多的占⽤资源,从⽽将数据库连接的资源耗尽,以致于影响其他业务的正常访 问。 特别是在⼀个数据库实例中存在较多分表的情况下,⼀条不包含分⽚键的逻辑 SQL 将产 ⽣落在同库不同表的⼤量真实 SQL ,如果每条真实SQL都占⽤⼀个独⽴的连接,那么⼀次查询⽆疑将会占⽤过多的资源。(内存限制模式)
从执⾏效率的⻆度看,为每个分⽚查询维持⼀个独⽴的数据库连接,可以更加有效的利⽤多 线程来提升执⾏效率。 为每个数据库连接开启独⽴的线程,可以将 I/O 所产⽣的消耗并⾏处理。为每个分⽚维持⼀个独⽴的数据库连接,还能够避免过早的将查询结果数据加载⾄内存。 独⽴的数据库连接,能够持有查询结果集游标位置的引⽤,在需要获取相应数据时移动游标即可。(连接限制模式)
以结果集游标下移进⾏结果归并的⽅式,称之为流式归并,它⽆需将结果数据全数加载⾄内 存,可以有效的节省内存资源,进⽽减少垃圾回收的频次。 当⽆法保证每个分⽚查询持有⼀个独⽴数据库连接时,则需要在复⽤该数据库连接获取下⼀张分表的查询结果集之前,将当前的查询结果集全数加载⾄内存。 因此,即使可以采⽤流式归并,在此场景下也将退化为内存归并。
⼀⽅⾯是对数据库连接资源的控制保护,⼀⽅⾯是采⽤更优的归并模式达到对中间件内存资 源的节省,如何处理好两者之间的关系,是 ShardingSphere 执⾏引擎需要解决的问题。 具体来说,如果⼀条 SQL 在经过 ShardingSphere 的分⽚后,需要操作某数据库实例下的 200 张表。 那么,是选择创建 200 个连接并⾏执⾏,还是选择创建⼀个连接串⾏执⾏呢?效率与 资源控制⼜应该如何抉择呢?
针对上述场景,ShardingSphere 提供了⼀种解决思路。 它提出了连接模式(Connection Mode)的概念,将其划分为内存限制模式(MEMORY_STRICTLY)和连接限制模式 (CONNECTION_STRICTLY)这两种类型。
6.1.1.内存限制模式
使⽤此模式的前提是,ShardingSphere 对⼀次操作所耗费的数据库连接数量不做限制。 如 果实际执⾏的 SQL 需要对某数据库实例中的 200 张表做操作,则对每张表创建⼀个新的数据库连接,并通过多线程的⽅式并发处理,以达成执⾏效率最⼤化。 并且在 SQL 满⾜条件情况 下,优先选择流式归并,以防⽌出现内存溢出或避免频繁垃圾回收情况。
6.1.2.连接限制模式
使⽤此模式的前提是,ShardingSphere 严格控制对⼀次操作所耗费的数据库连接数量。 如 果实际执⾏的 SQL 需要对某数据库实例中的 200 张表做操作,那么只会创建唯⼀的数据库连 接,并对其 200 张表串⾏处理。 如果⼀次操作中的分⽚散落在不同的数据库,仍然采⽤多线程处理对不同库的操作,但每个库的每次操作仍然只创建⼀个唯⼀的数据库连接。 这样即可以防⽌对⼀次请求对数据库连接占⽤过多所带来的问题。该模式始终选择内存归并。
6.2.⾃动化执⾏引擎
ShardingSphere 最初将使⽤何种模式的决定权交由⽤户配置,让开发者依据⾃⼰业务的实际 场景需求选择使⽤内存限制模式或连接限制模式。
为了降低⽤户的使⽤成本以及连接模式动态化这两个问题,ShardingSphere 提炼出⾃动化执 ⾏引擎的思路,在其内部消化了连接模式概念。 ⽤户⽆需了解所谓的内存限制模式和连接限 制模式是什么,⽽是交由执⾏引擎根据当前场景⾃动选择最优的执⾏⽅案。
⾃动化执⾏引擎将连接模式的选择粒度细化⾄每⼀次 SQL 的操作。 针对每次 SQL 请求,⾃ 动化执⾏引擎都将根据其路由结果,进⾏实时的演算和权衡,并⾃主地采⽤恰当的连接模式 执⾏,以达到资源控制和效率的最优平衡。 针对⾃动化的执⾏引擎,⽤户只需配置 maxConnectionSizePerQuery 即可,该参数表示⼀次查询时每个数据库所允许使⽤的最⼤连接数。
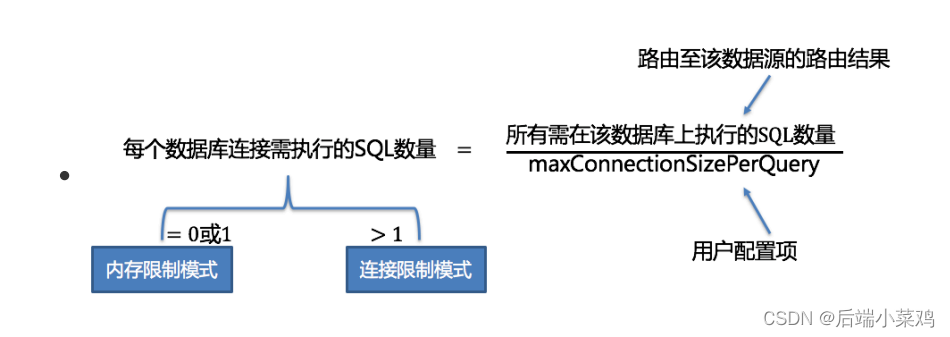
在 maxConnectionSizePerQuery 允许的范围内,当⼀个连接需要执⾏的请求数量⼤于 1 时,意味着当前的数据库连接⽆法持有相应的数据结果集,则必须采⽤内存归并; 反之,当 ⼀个连接需要执⾏的请求数量等于 1 时,意味着当前的数据库连接可以持有相应的数据结果集,则可以采⽤流式归并。 每⼀次的连接模式的选择,是针对每⼀个物理数据库的。也就是说,在同⼀次查询中,如果 路由⾄⼀个以上的数据库,每个数据库的连接模式不⼀定⼀样,它们可能是混合存在的形态。 (当用户设置的maxConnectionSizePerQuery / 所有需在该数据库上执行的SQL数量 等于 0或1 时,则会采用 内存限制模式 如果大于1则会采用 连接限制模式)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154447.html

