
文章目录
一、前言
每次遇到 sql 优化,查看执行计划,其中的字段是什么含义总是会忘,所以有了这篇文章方便查阅。
二、如何查看执行计划
第一种方法,在 SELECT 语句前面加上 EXPLAIN 关键字
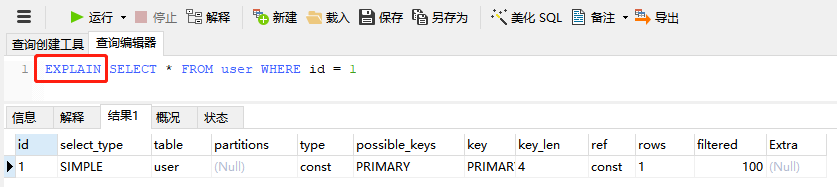

第三种方法,如果用 Navicat 数据库工具的话,点击上面的解释按钮
三、执行计划各字段解释
先贴上 Mysql 官方文档中关于执行计划字段解释的地址:
官网:MySQL 8.0 Reference Manual / Optimization / Understanding the Query Execution Plan / EXPLAIN Output Format
中文网:MySQL 8.0 参考手册 / 第8章优化 / 8.8 了解查询执行计划 / 8.8.2 EXPLAIN 输出格式
| 字段 | 说明 |
|---|---|
| id | 操作的唯一标识符 |
| select_type | 操作的类型 |
| table | 涉及的表名 |
| partitions | 操作涉及的分区 |
| type | 表示使用的连接类型或扫描类型 |
| possible_keys | 可能使用的索引列表 |
| key | 实际选择使用的索引 |
| key_len | 索引键的长度 |
| ref | 连接条件所使用的列或常量 |
| rows | 估计的扫描行数 |
| filtered | 从结果中过滤返回行的百分比 |
| Extra | 额外的信息 |
下面就结合一些实际例子看下 select_type、type、Extra
准备脚本如下:
-- 创建用户表
CREATE TABLE user (
id int(11) NOT NULL AUTO_INCREMENT ,
name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL ,
age int(11) NULL DEFAULT NULL ,
dept_id int(11) NULL DEFAULT NULL ,
remark text CHARACTER SET utf8 COLLATE utf8_general_ci NULL ,
PRIMARY KEY (id),
INDEX index_name_age (name, age) USING BTREE ,
INDEX index_dept_id (dept_id) USING BTREE ,
FULLTEXT INDEX index_remark (remark)
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
AUTO_INCREMENT=38
ROW_FORMAT=DYNAMIC
;
-- 初始化用户数据
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('1', '张三', '20', '1', 'abc');
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('2', '李四', '18', '1', 'bcd');
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('3', '王五', '22', '1', 'cde');
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('4', '赵六', '23', '2', 'def');
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('5', '孙七', '25', '2', 'efg');
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('6', '周八', '16', '2', 'fgh');
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('7', '吴九', '19', '3', 'ghi');
INSERT INTO user (id, name, age, dept_id, remark) VALUES ('8', '郑十', '13', '3', 'hij');
-- 创建部门表
CREATE TABLE dept (
id int(11) NOT NULL ,
name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL ,
PRIMARY KEY (id),
INDEX index_name (name) USING BTREE
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
ROW_FORMAT=DYNAMIC
;
-- 初始化部门数据
INSERT INTO dept (id, name) VALUES ('1', '人事部');
INSERT INTO dept (id, name) VALUES ('2', '财务部');
INSERT INTO dept (id, name) VALUES ('3', '技术部');
四、select_type
| select_type | 说明 |
|---|---|
| SIMPLE | 简单查询 |
| PRIMARY | 主查询(外部查询) |
| SUBQUERY | 子查询 |
| DEPENDENT SUBQUERY | 依赖子查询 |
| UNCACHEABLE SUBQUERY | 不可缓存子查询 |
| UNION | 合并查询 |
| UNION RESULT | 合并查询结果 |
| DEPENDENT UNION | 依赖合并查询 |
| UNCACHEABLE UNION | 不可缓存合并查询 |
| DERIVED | 派生表 |
| MATERIALIZED | 物化 |
下面针对各种情况举例,不用纠结sql本身的业务含义
4.1、SIMPLE(简单查询)
不包含UNION或者子查询
4.1.1、简单的单表查询
EXPLAIN SELECT * FROM user;

4.1.2、多表连接查询
EXPLAIN SELECT
a.*, b.*
FROM
USER a
INNER JOIN dept b ON b.id = a.dept_id;
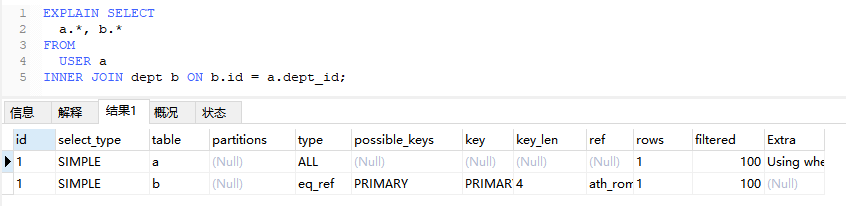
4.2、PRIMARY(主查询)
包含复杂子查询的外层查询,或者UNION语句中的第一个查询
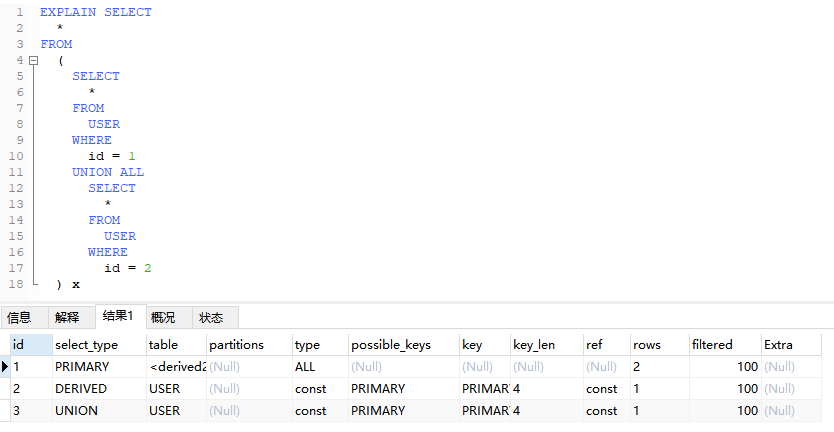
4.2.1、包含复杂子查询的外层查询
EXPLAIN SELECT
*
FROM
(
SELECT
*
FROM
USER
WHERE
id = 1
UNION ALL
SELECT
*
FROM
USER
WHERE
id = 2
) x;
4.2.2、UNION语句中的第一个查询
EXPLAIN SELECT
*
FROM
USER
WHERE
id = 1
UNION ALL
SELECT
*
FROM
USER
WHERE
id = 2;
4.3、SUBQUERY(子查询)、DEPENDENT SUBQUERY(依赖子查询)、UNCACHEABLE SUBQUERY(不可缓存子查询)
- SUBQUERY(子查询):子查询是指嵌套在主查询中的查询语句。当 Mysql 优化器将子查询作为单独的查询执行,并将结果作为主查询的条件之一时,
select_type会被标记为 SUBQUERY 。这种情况下,子查询会在主查询之前执行,并将结果传递给主查询使用。 - DEPENDENT SUBQUERY(依赖子查询):当一个子查询需要根据外部查询的结果来确定查询条件或提供必要的数据时,它就被称为依赖子查询。依赖子查询会在外部查询的每一行上执行,并根据外部查询的结果进行计算。
- UNCACHEABLE SUBQUERY(不可缓存子查询):优化器可以根据查询中的各种条件和索引信息来对查询进行优化,以获得更好的性能。然而,某些类型的子查询由于其特殊的性质,无法被优化器缓存。
4.3.1、SUBQUERY(子查询)
如果是SUBQUERY(子查询)需要满足以下条件:
- 子查询不能转化为半连接,关于半连接可参考:8.2.2.1 使用半连接转换优化 IN 和 EXISTS 子查询谓词
- 子查询是不相关子查询
这里补充下不相关子查询和相关子查询的含义
不相关子查询:子查询与主查询之间没有依赖关系,独立于主查询执行,只执行一次,然后将结果用于主查询的条件或者计算
相关子查询:子查询与主查询之间存在依赖关系,子查询的结果依赖于主查询的每一行数据
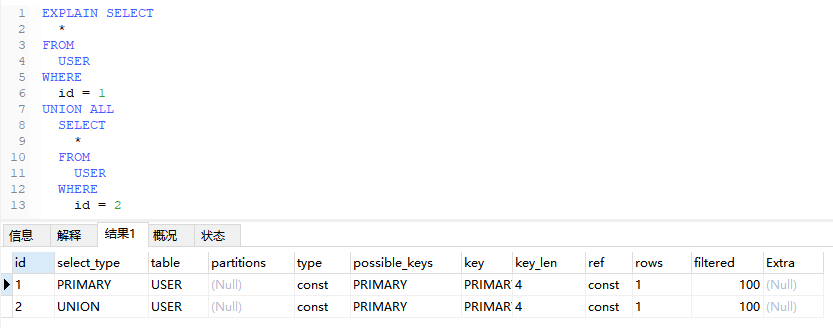
EXPLAIN SELECT
*
FROM
USER
WHERE
age > (SELECT avg(age) FROM USER);
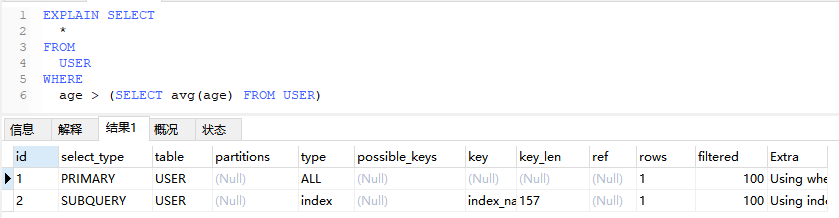
4.3.2、DEPENDENT SUBQUERY(依赖子查询)
如果是DEPENDENT SUBQUERY(依赖子查询)需要满足以下条件:
- 子查询不能转化为半连接
- 子查询是相关子查询
只要把上面例子里的 > 改成 IN,子查询就会变成相关子查询
EXPLAIN SELECT
*
FROM
USER
WHERE
age IN (SELECT avg(age) FROM USER);
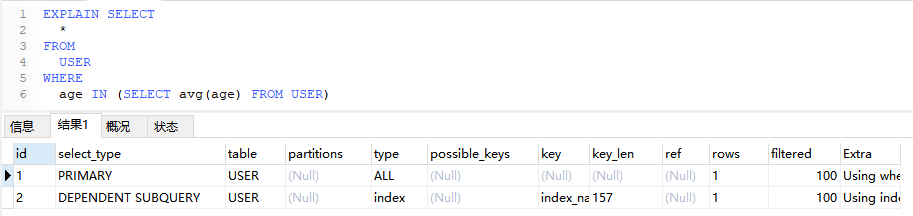
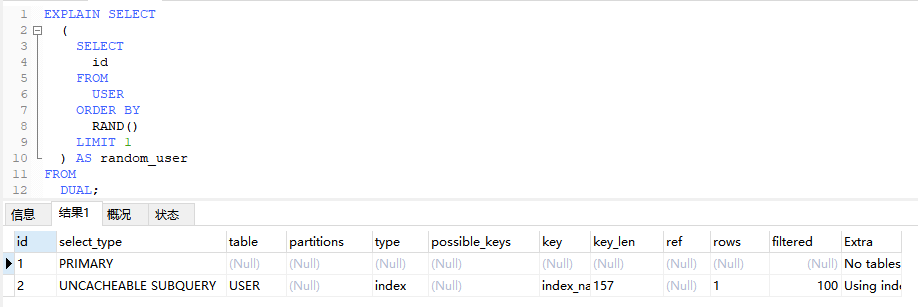
4.3.3、UNCACHEABLE SUBQUERY(不可缓存子查询)
当子查询中使用了不支持查询缓存的函数,会导致该子查询被标记为不可缓存
EXPLAIN SELECT
(
SELECT
id
FROM
USER
ORDER BY
RAND()
LIMIT 1
) AS random_user
FROM
DUAL;
4.4、UNION(合并查询)、UNION RESULT(合并查询结果)、DEPENDENT UNION(依赖合并查询)、UNCACHEABLE UNION(不可缓存合并查询)
- UNION(合并查询):在 UNION 语句中,第二个及之后的 select 会标记成 UNION。
- UNION RESULT(合并查询结果):当执行 UNION 操作时,MySQL 可能会生成一个 UNION RESULT 来存储合并后的结果集,以供后续处理使用,这个结果集就会标记为 UNION RESULT。
- DEPENDENT UNION(依赖合并查询):依赖于外部查询的 UNION 操作,UNION 的结果取决于外部查询的结果,无法独立地进行计算,通常表现为子查询中,第二个及之后的 select。
- UNCACHEABLE UNION(不可缓存合并查询):和 UNCACHEABLE SUBQUERY(不可缓存子查询)类似,表示一个无法通过查询缓存来进行优化的 UNION 操作。
4.4.1、UNION(合并查询)、UNION RESULT(合并查询结果)
EXPLAIN SELECT
*
FROM
USER
WHERE
id = 1
UNION
SELECT
*
FROM
USER
WHERE
id = 2;
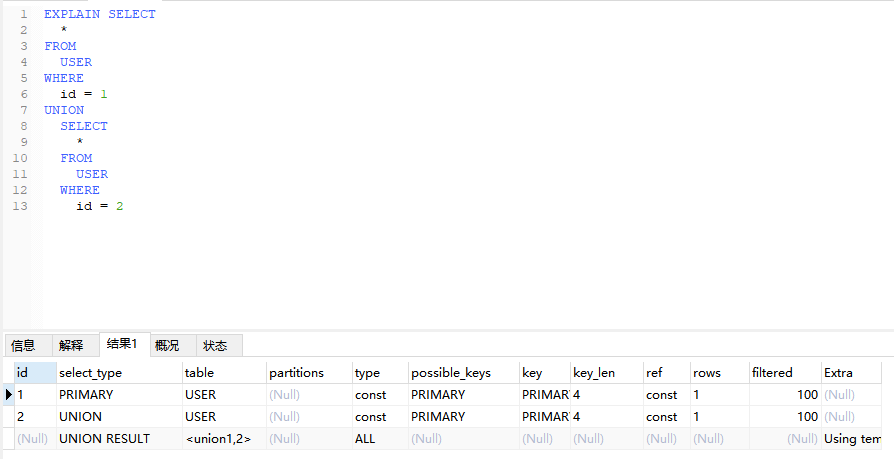
4.4.2、DEPENDENT UNION(依赖合并查询)
当UNION作为子查询时,第二个或者后面的查询语句
EXPLAIN SELECT
*
FROM
USER
WHERE
id IN (
SELECT
id
FROM
USER
WHERE
NAME = '张三'
UNION ALL
SELECT
id
FROM
USER
WHERE
NAME = '李四'
);
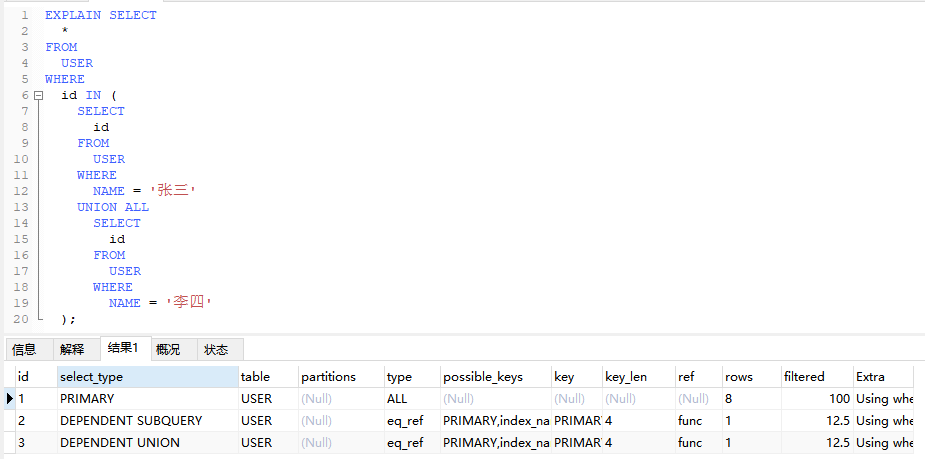
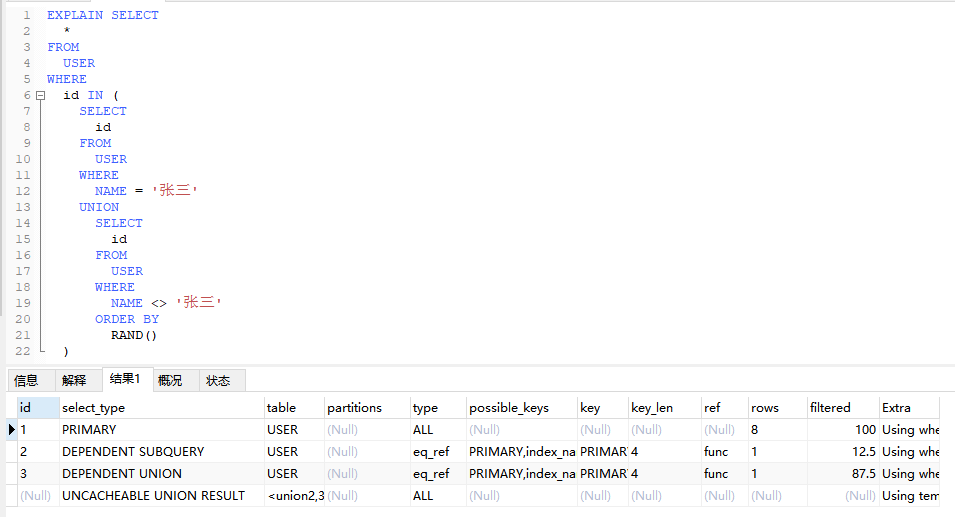
4.4.3、UNCACHEABLE UNION(不可缓存合并查询)
EXPLAIN SELECT
*
FROM
USER
WHERE
id IN (
SELECT
id
FROM
USER
WHERE
NAME = '张三'
UNION
SELECT
id
FROM
USER
WHERE
NAME <> '张三'
ORDER BY
RAND()
);
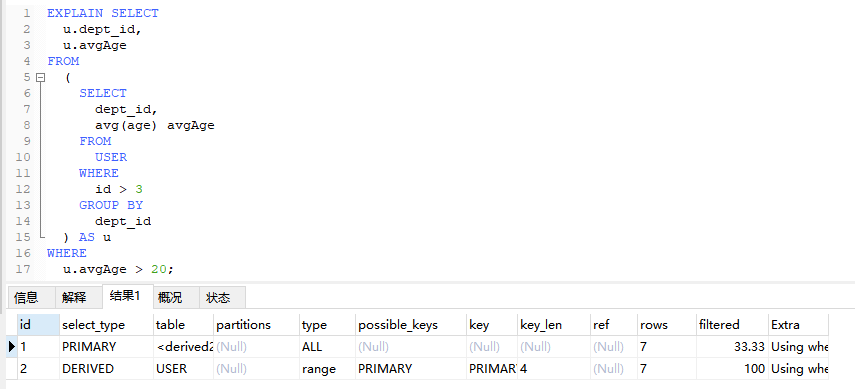
4.5、DERIVED(派生表)
在查询中使用子查询生成的临时表
EXPLAIN SELECT
u.dept_id,
u.avgAge
FROM
(
SELECT
dept_id,
avg(age) avgAge
FROM
USER
WHERE
id > 3
GROUP BY
dept_id
) AS u
WHERE
u.avgAge > 20;
4.6、MATERIALIZED(物化)
当查询包含子查询或派生表,并且优化器认为将其结果保存到临时表中会更有效率时,就会使用物化表。使用物化表可以避免在每次引用子查询或派生表时都需要重新计算结果集,从而提高查询性能。特别是当子查询或派生表的结果集较大或计算复杂时。
五、type
| type | 说明 |
|---|---|
| system | 该表只有一行(相当于系统表),system是const类型的特例 |
| const | 键或唯一索引的等值查询,最多只返回一行数据 |
| eq_ref | 当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型 |
| ref | 如果仅使用了索引的最左边前缀,或者索引不是PRIMARY KEY或UNIQUE |
| fulltext | 全文索引 |
| ref_or_null | 和ref类似,但是会额外搜索哪些行包含了NULL |
| index_merge | 使用索引合并优化 |
| unique_subquery | 和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引 |
| index_subquery | 和unique_subquery类似,只是子查询使用的是非唯一索引 |
| range | 仅检索给定范围内的行,使用索引来选择行,可以在使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, 或 IN()等操作符。 |
| index | 与ALL类似,只是扫描了索引树 |
| ALL | 全表扫描 |
性能从优到劣依次为:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
5.1、system
该表只有一行(相当于系统表),system是const类型的特例
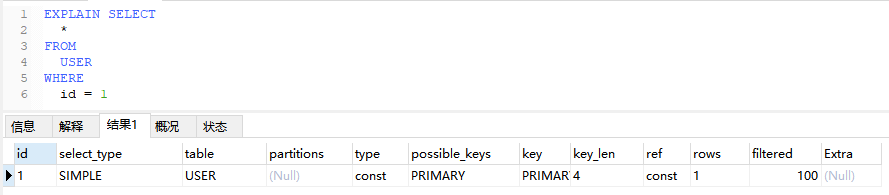
5.2、const
键或唯一索引的等值查询,最多只返回一行数据
EXPLAIN SELECT
*
FROM
USER
WHERE
id = 1;
5.3、eq_ref
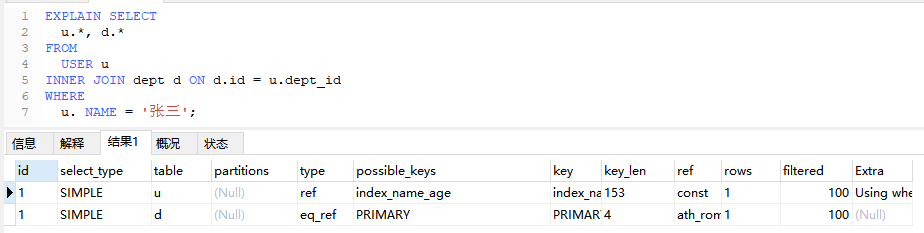
当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型
EXPLAIN SELECT
u.*, d.*
FROM
USER u
INNER JOIN dept d ON d.id = u.dept_id
WHERE
u. NAME = '张三';
5.4、ref
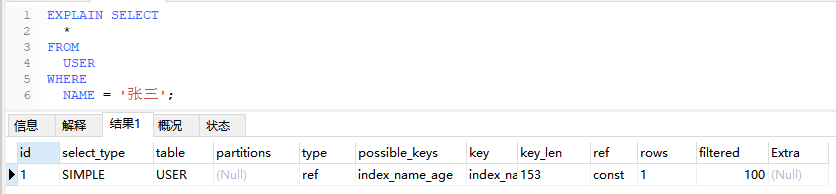
如果仅使用了索引的最左边前缀,或者索引不是PRIMARY KEY或UNIQUE
EXPLAIN SELECT
*
FROM
USER
WHERE
NAME = '张三';
5.5、fulltext
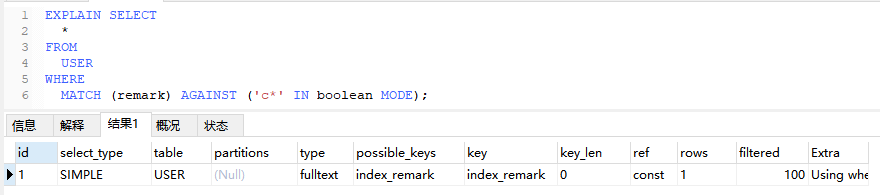
全文索引
EXPLAIN SELECT
*
FROM
USER
WHERE
MATCH (remark) AGAINST ('c*' IN boolean MODE);
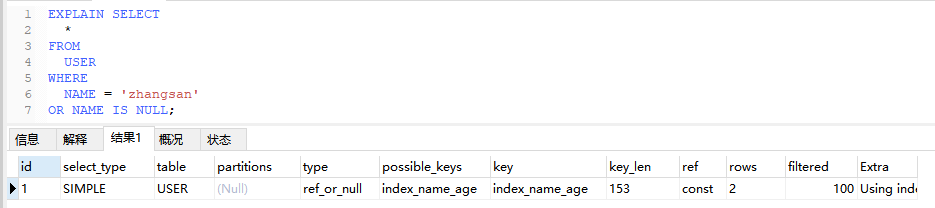
5.6、ref_or_null
和ref类似,但是会额外搜索哪些行包含了NULL
EXPLAIN SELECT
*
FROM
USER
WHERE
NAME = 'zhangsan'
OR NAME IS NULL;
5.7、index_merge
使用索引合并优化
EXPLAIN SELECT
*
FROM
USER
WHERE
id = '1'
OR NAME = '张三';

5.8、unique_subquery
和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引
5.9、index_subquery
和unique_subquery类似,只是子查询使用的是非唯一索引
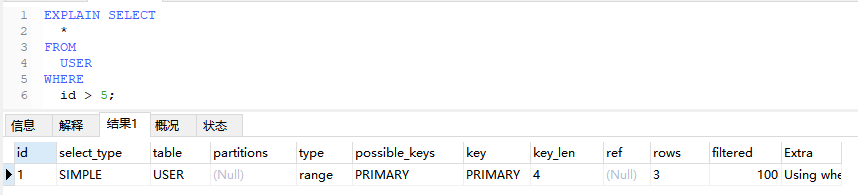
5.10、range
仅检索给定范围内的行,使用索引来选择行,可以在使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, 或 IN()等操作符。
EXPLAIN SELECT
*
FROM
USER
WHERE
id > 5;
5.11、index
与ALL类似,只是扫描了索引树
5.12、ALL
全表扫描
六、Extra
这里列出一些常见的,其他的参考官方文档
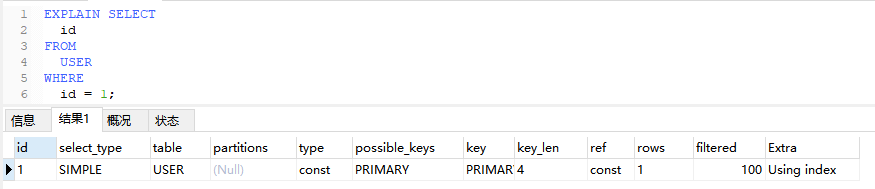
6.1、Using index
查询使用了覆盖索引,查询的所有列都可以从索引中获取,而不需要回表查询数据行。
EXPLAIN SELECT
id
FROM
USER
WHERE
id = 1;
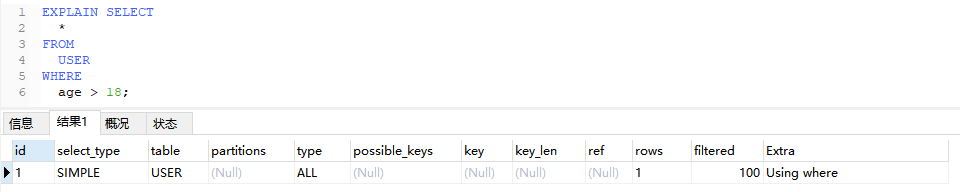
6.2、Using where
在执行查询时会使用WHERE子句对结果进行进一步的筛选,或者全表扫描
EXPLAIN SELECT
*
FROM
USER
WHERE
age > 18;
6.3、Using temporary
为了解析查询,MySQL 需要创建一个临时表来保存结果。
EXPLAIN SELECT
NAME
FROM
USER
WHERE
id = 1
UNION
SELECT
NAME
FROM
USER
WHERE
id = 2;
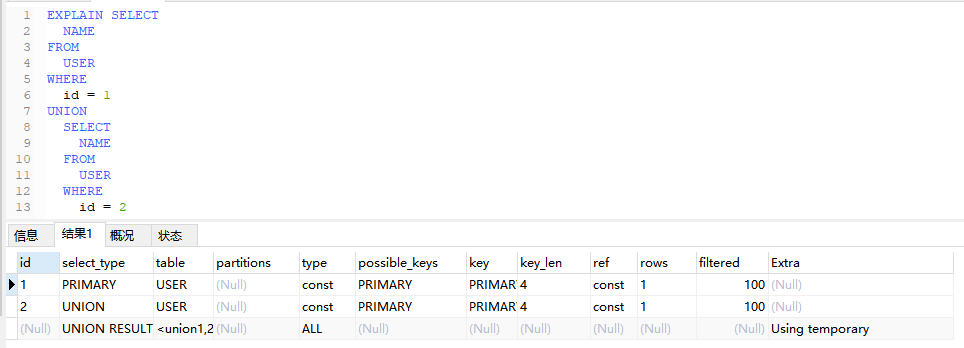
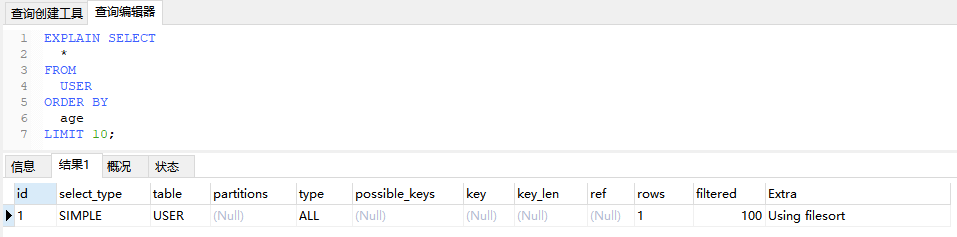
6.4、Using filesort
无法使用索引或其他优化方式直接按照查询语句中的顺序返回结果,而是需要额外的排序操作。会对性能产生一定影响,特别是对大数据量的查询语句。
EXPLAIN SELECT
*
FROM
USER
ORDER BY
age
LIMIT 10;
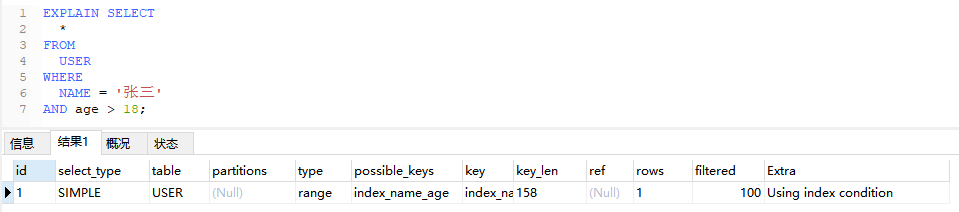
6.5、Using index condition
表示查询使用了索引条件过滤数据,通常表示使用了索引下推,是一个好的优化迹象
索引下推:指 MySQL 将 WHERE 条件中可用于索引的部分推到存储引擎层级进行处理,而不是等到存储引擎返回数据行后再应用 WHERE 条件进行过滤。这样可以减少 IO 操作和数据传输,提高查询性能。
EXPLAIN SELECT
*
FROM
USER
WHERE
NAME = '张三'
AND age > 18;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154468.html

