
目录
实现复制操作-FileReadr和FileWriter配合使用
使用RandomAccessFile实现文件内容的插入操作:
File类的使用
- java.io.File类:文件和文件目录路径的抽象表示形式,与平台无关。
- File能 新建,删除,重命名文件和目录,但File不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
- 想要在java程序中表示一个真实存在的文件或目录,那必须有一个File对象,但是java程序中的一个File对象,可能没有一个真实存在的文件或目录。
- File对象可以作为参数传递给流的构造器。
File类的构造器

//在构造时,new出来的依然是在内存层面
路径分隔符问题
- 路径中的每级目录之间用一个路径分隔符隔开 。
- 路径分隔符和系统有关:
—》windows和DOS系统默认使用 “ \ ” 来表示。(反斜杠)
—》UNIX和URL使用 “ / ” 来表示。(正斜杠) - Java程序支持跨平台运行,因此路径分隔符要慎用。
- 为了解决这个隐患,File类提供了一个常量:
public static final String separator 。根据操作系统,动态的提供分隔符。
分隔符常量的使用举例:
//一般写法
File file1 = new File("d:\\document\\Test.txt");
//使用分隔符常量
File file2 = new File("d:" + File.separator + "document" + File.separator + "Test.txt");
File类的常用方法


文件的创建和删除
创建硬盘中的文件或者文件目录或删除磁盘中的文件或文件目录

File类只可完成对于文件的一些简单操作,需要对文件进行读写操作,需要使用到IO流的操作。File对象常常作为参数传入到流的构造器中,指明读取或写入的“终点”。
IO流的原理及流的分类
JavaIO原理
- I/O是Input/Output的缩写,I/O技术是非常实用的技术,用于处理设备之间的数据传输。如读/写文件,网络通讯。
- Java程序中,对于数据的输入/输出操作以”流(stream)”的方式进行。
- java io包下提供了各种”流”类”类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据。
流的分类

IO流体系
深色底色为常用

流的一般操作步骤
- File类的实例化 —>new file()
- 流的实例化 —>new FileReader(file)
- 流操作 —>writer() ,read()
- 流资源的关闭 —>stream.close()
关于文件的相对路径
@Test
public void test1() {
//在此单元测试中,相对路径为当前模块下
}
public static void main(String[] args) {
//在main方法中,相对路径为当前工程下
}字符流Reader -Write
流读取文件的操作(输入)reader
- read()的理解:返回读入的一个字符,如果读取到文件末尾,则返回-1.
- 异常的处理:为了保证流资源一定可以执行关闭操作,需要使用try-catch-finally。
流-FileReader的使用举例1
读取文件hello.txt
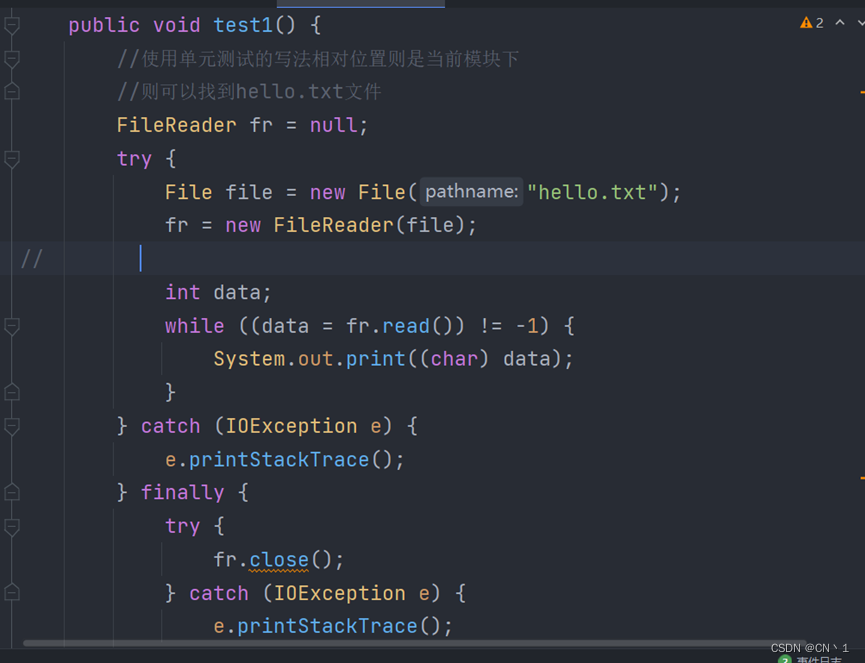
流-FileReader的使用举例2
读取文件hello.txt —-//使用read()另一构造器
将arr传入read()中 —>read(arr)
:使得read()每一次获取arr.length个字符。
//此代码采取throws的方式处理异常

流写入文件的操作(输出)writer

输出操作说明:
操作时,指定文件不存在,不会报错,因为输出操作
当检测到文件不存在时,会自动生成文件
writer()其中构造器(是否覆盖文件):
writer(filename)或writer(filename,false) 对文件内容覆盖操作
writer(filename,true) 对文件及进行追加操作
实现复制操作-FileReadr和FileWriter配合使用
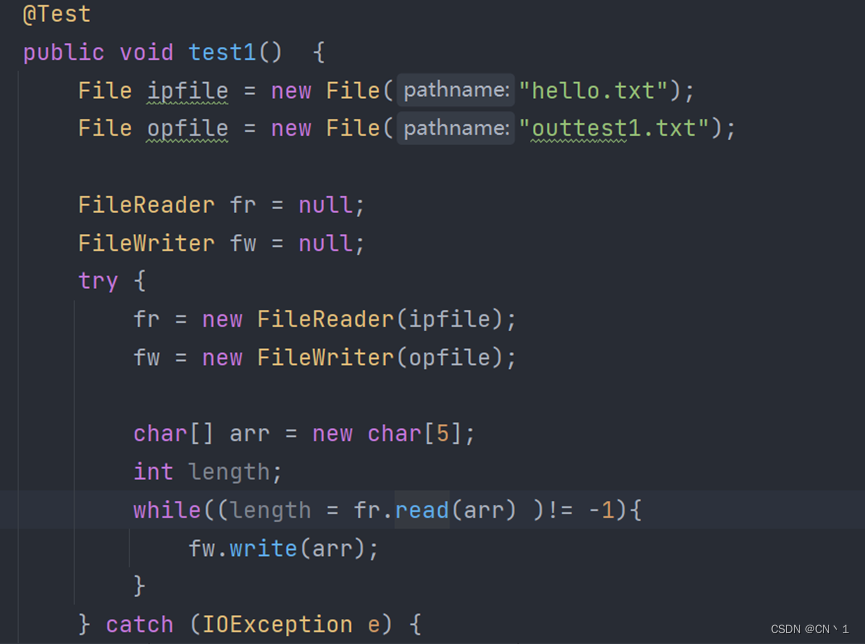
字节流 InputStream,OutputStream
使用字节流对非文本文件的复制操作:
(FileInputStream-FileOutputStream)
补充说明:字符流无法处理图片文件等。
- 对于文本文件,使用字符流处理。
- 对于非文本文件,使用字节流处理。
- 如果仅是进行复制操作,不在内存层面转化输出(控制台输出)字节流,字节流可以处理文本文件,如果在内存层面输出,会出现乱码情况。

缓冲流 (处理流)
BufferedInputStream-BufferedOutputStream
缓冲流说明
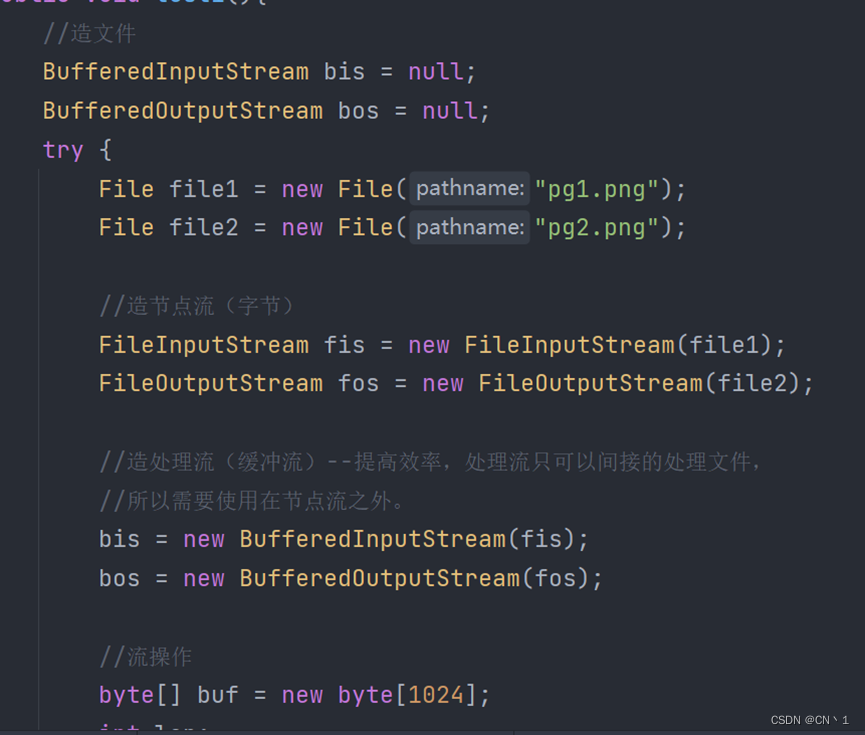
使用缓冲流对非文本文件(字节流)进行复制操作
处理流:在节点流之外,提高效率。
Buffered内部提供了缓存区,大小为:8192。读取进来的数据先存放于
缓存区,当缓存区存满后,调用flush()方法,将缓存区内一次性写出(输出)
从而提高了效率。
处理流的使用(作用于节点流之上)
流资源的关闭顺序说明
//关闭顺序:先关闭外层(处理流),后关闭内层(节点流)
//说明:关闭外层流(处理流)后,内层流自动关闭
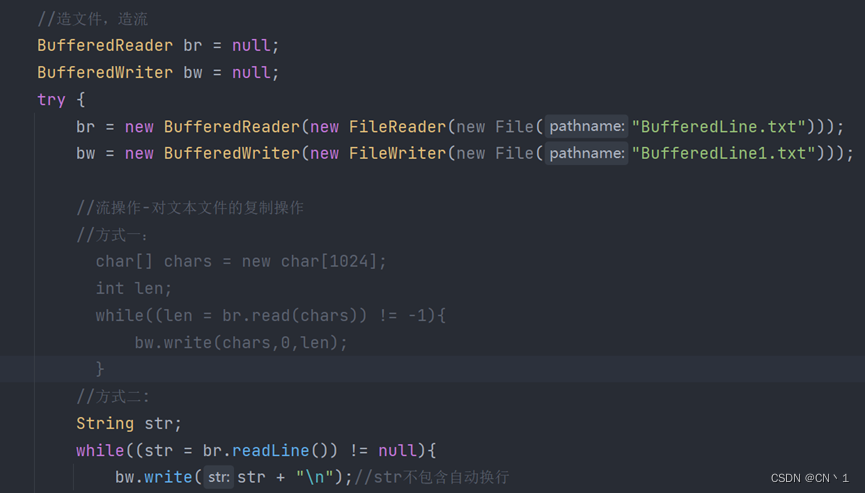
使用缓冲流对文本文件进行复制操作
方式二使用BufferedReader-BufferedWriter 中的readLine()
代码说明:
- 处理流套接着节点流,所以使用了合并的方式书写。
- 新的读取方式,使用readLin(),此方式为:一次读取一行,读取到空行时,返回null,表示到达文件末尾,所以:需要我们手动换行。
练习:图片的加密解密
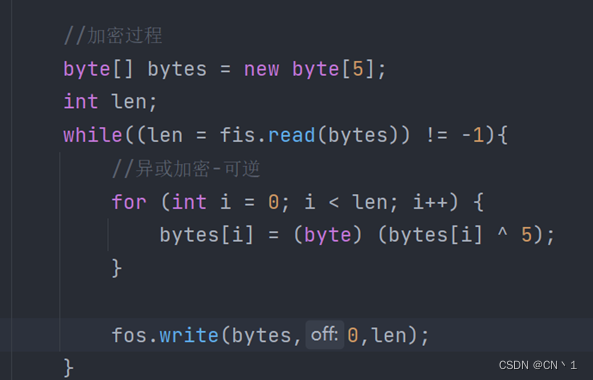
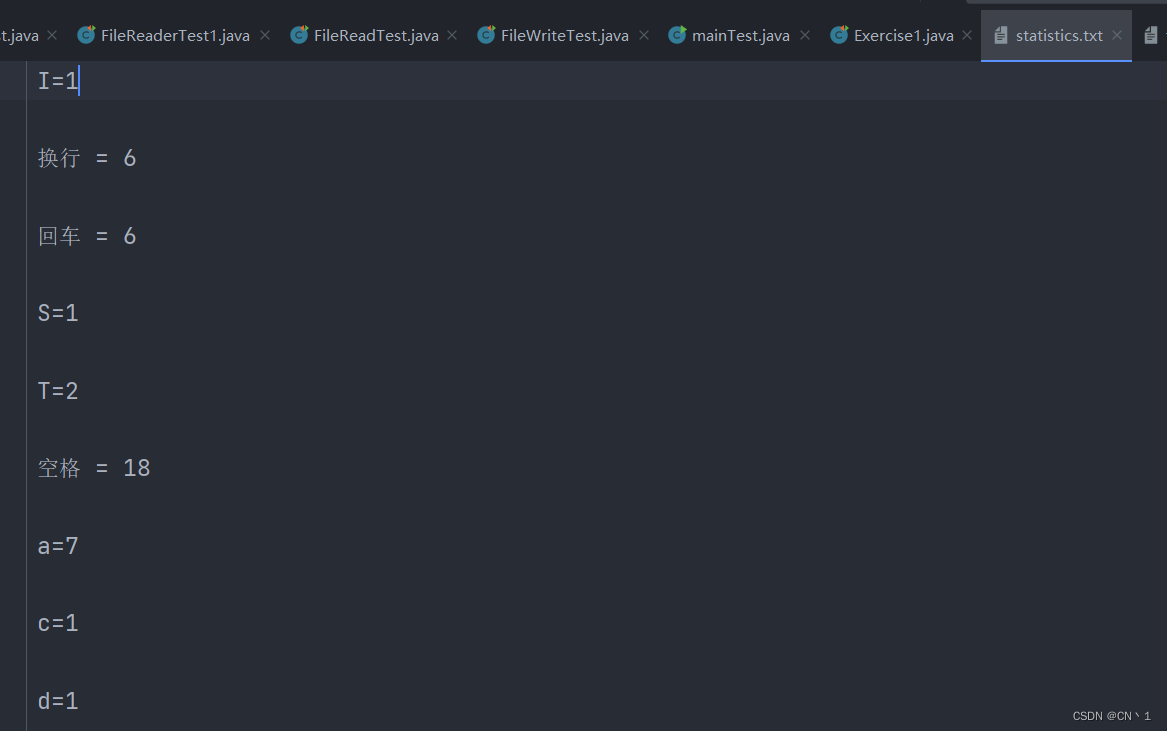
练习:统计文本文件中所有字符各个出现的次数
package bk3;
import org.junit.Test;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 统计文本文件中字符出现的次数
*
*/
public class Exercise1 {
@Test
public void test1(){
Map<Character,Integer> map = new HashMap<>();
FileReader fr = null;
BufferedWriter bw = null;
try {
fr = new FileReader("BufferedLine.txt");
int len = 0;
while((len = fr.read()) != -1){
char chars = (char)len;
//判断字符是否有value值,如为null表明第一次添加。
if (map.get(chars) == null){
map.put(chars,1);
}else{
map.put(chars,map.get(chars) + 1);
}
}
bw = new BufferedWriter(new FileWriter("statistics.txt"));
Set<Map.Entry<Character, Integer>> entries = map.entrySet();
for (Map.Entry<Character, Integer> entry :entries){
//统计符号出现的个数
switch(entry.getKey()){
case ' ':
bw.write("空格 = " + entry.getValue());
break;
case '\n':
bw.write("换行 = " + entry.getValue());
break;
case '\r':
bw.write("回车 = " + entry.getValue());
break;
default:
//统计字符
bw.write(entry.getKey() + "=" + entry.getValue());
break;
}
//换行
bw.newLine();
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (bw != null){
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fr != null){
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
输出结果:
处理流之二:转换流
- 转换流:属于字符流
InputStreamReader :将一个字节的输入流转换为一个字符的输入流。
OutputStreamWriter:将一个字符的输出流转换为一个字节的输出流。
2.作用:提供字节流于字符流的转换
标准输入输出流
System.in :标准输入流,默认从键盘输入
System.out : 标准输出流,默认从控制台输出
System类的setInt(InputStream is)/setOut(OutputStream)设置流向
练习:使用标准流将输入数据转化为大写输出(e/exit退出)
报错为未处理异常

打印流

将输出指定到文件夹

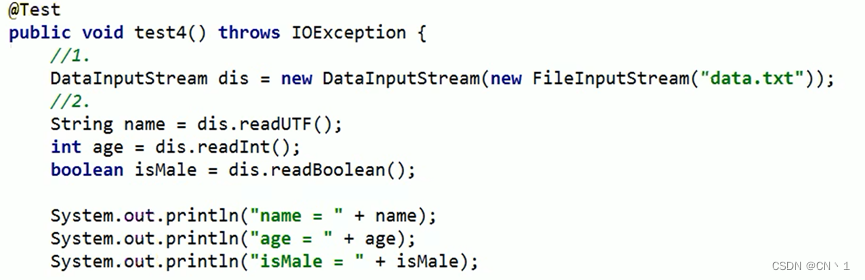
数据流


将内存中的字符串,基本数据类型输出到文件中

将已保存在文件中的String,基本数据类型读入内存
(读取顺序需要按照当初写入顺序一致)
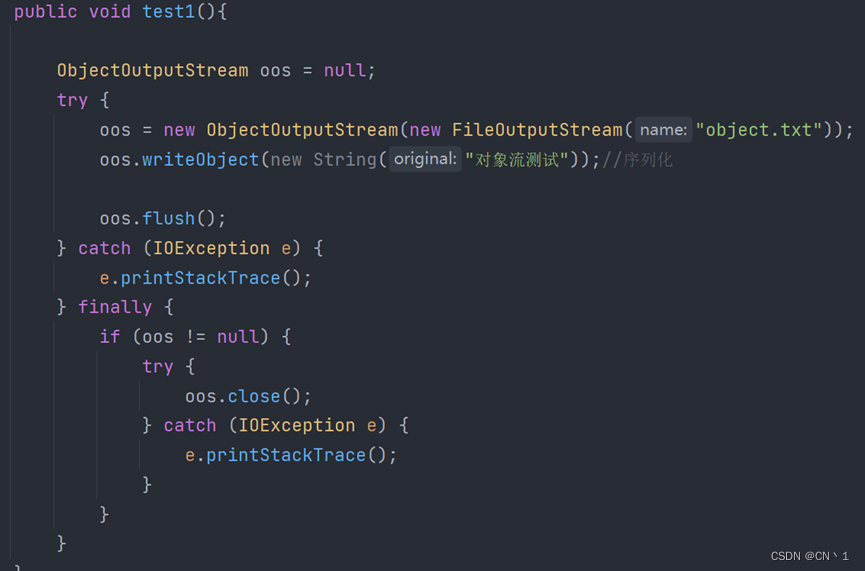
对象流

对象的序列化
- 对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传入到另一个网络节点,当其它程序获取了这种二进制流,就可以恢复成原来的Java对象。
- 序列化的好处在于可将任何实现了Serializable接口的对象转化为字节数据,使其在保存和传输时可被还原。
- 序列化是RMI(Remote Method Invoke —远程方法调用)过程的参数和返回值都必须实现的机制,而RMI是JavaEE的基础。因此序列化机制是JavaEE平台的基础。
- 如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一。否则会报异常。
—>Serializable
—>Externalizable
序列化的过程
将内存中的Java对象保存到磁盘或通过网络传输。(使用ObjectOutputStream实现)
对象流:保存内存中的对象到磁盘中,或读取硬盘中的数据到内存中。
* (通过序列化和反序列化的方式)如下:
序列化操作
反序列化操作
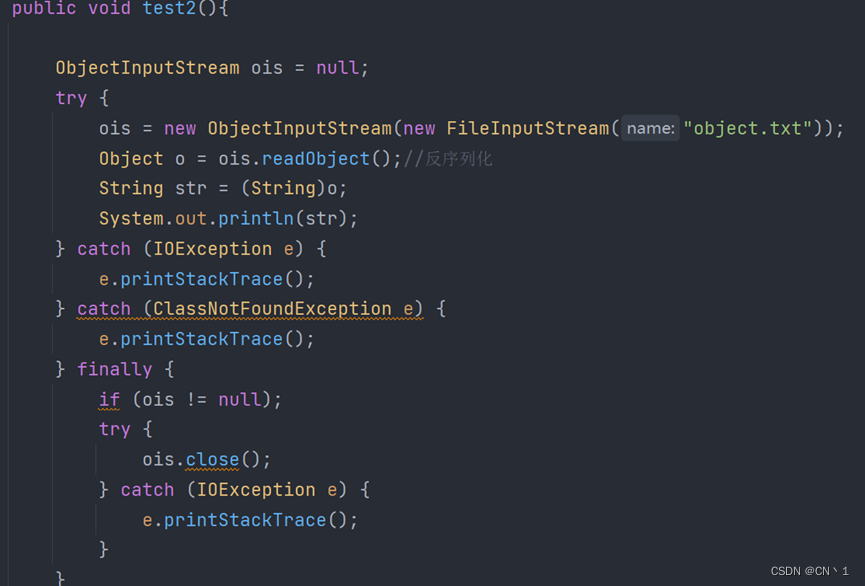
如何设置类为可序列化的?
- 需要实现接口:Serializable
- 当前类提供一个全局常量:serialVersionUID
(public static final long serialVersionUID = xxxxxL)x为任意数字
- 类中的所有属性也应该是可序列化的。(基本数据类型是可序列化的)
- static ,transient修饰的成员变量不可序列化,否则输出为默认值。
transient:不可序列化的。
Serializable接口说明
- 凡是实现Serialiable接口的类都有一个表示序列化版本表示的静态变量:
—>private static final long serialVersionUID;
—>serialVersionUID用来表明类的不同版本间的兼容性你。简而言之,其目的是以序列化对象进行版本控制,有关个版本反序列化时是否兼容。
—>如果类没有显示定义这个静态常量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的实例变量做了修改,serialVersionUID可能发生变化。所以建议显式声明。 - 简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
随机存储文件流(RandomAccessFile类)
特点:即可是输入又可以是输出流
构造器
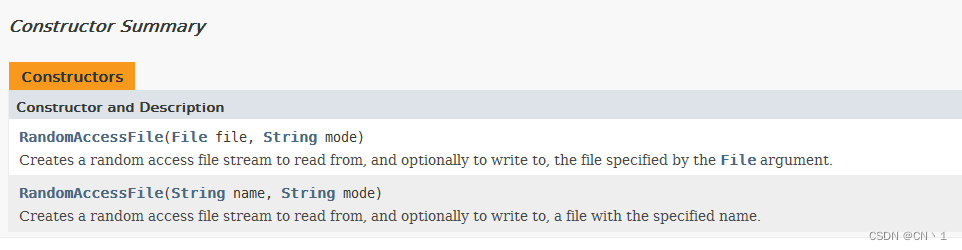
- 创建RandomAccessFile类实例需要指定一个mode参数,该参数指定RandomAccessFile的访问模式:
—> r :只读的方式打开
—> rw : 打开以便读取和写入
—>rwd : 打开以便读取和写入;同步文件内容的更新
—>rws : 打开以便读取和写入; 同步文件内容和元数据的更新 - 如果模式为只读r。则不会创建文件,而是会去读取一个已经存在的文件,如果读取的文件不存在则会出现异常。如果模式为rw读写,文件不存在会去创建文件,文件存在则不创建。
使用RandomAccessFile实现文件内容的插入操作:

JAVA NIO 概述
Java NIO (New IO ,Non-Blocking IO)是从Java1.4版本开始引入的一套新的IO API,可以替代标准的Java IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO将以更加高效的方式进行文件的读写操作。
JavaAPI中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
NIO.2
随着JDK7的发布,Java对NIO进行了极大的扩展,增强了对文件处理 和文件系统性能的支持,以至于我们称他们为NIO.2.因为NIO提供的一些功能,NIO已经成为文件处理中越来越重要的一部分
Path、Paths、File核心API


Path的常用方法

Files类的常用方法

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154587.html

