
文章目录
前言
随着当代应用系统要求的QPS/TPS日益增加,很多的业务编程都需要用到多线程并发编程才能满足实际的性能要求。在前面的博文中,我们讲解了很多的JUC并发编程工具类,能够在高并发环境下保证多线程数据的安全性;也提到了Thread Pool线程池可以减少频繁创建、销毁线程在尽可能多的压榨资源的同时提升系统运行效率。那么,现在有没有一种方式在有限的线程下能够尽快尽最大限度完成任务呢?答案就是今天的线程并行主角——ForkJoin 并行处理框架。
何为ForkJoin
ForkJoin 是 JUC并发包下的一个并行处理框架。大家都知道并发就多个线程争抢CPU资源,不一定每个线程可以同时执行,只是拥有同时执行的权利,具体执行需要看CPU资源。但并行则是多个线程同时运行,比如有5个CPU核心,那么同时会有5个线程并行运行。所以 ForkJoin 框架是为多线程提供并行处理的一种架构,我们可以运用ForkJoin 框架下的工具类实现任务的‘分而治之’。
JDK ForkJoin运用
说到ForkJoin并行处理框架,我们就不得不提到JDK1.8中的Parallel Stream并行流。Parallel Stream并行流底层也是采用ForkJoin框架中的ForkJoinPool 并行线程池进行处理的。
案例:
/**
* parallelStreamTest
* @author senfel
* @date 2023/3/23 9:43
* @return void
*/
@Test
public void parallelStreamTest(){
List<Integer> list = new ArrayList<>(Arrays.asList(13, 2, 5, 9, 1, 6, 0, 45, 11));
list.parallelStream().forEach(i->{
System.err.println(i);
System.err.println(Thread.currentThread().getName());
});
}
执行结果:
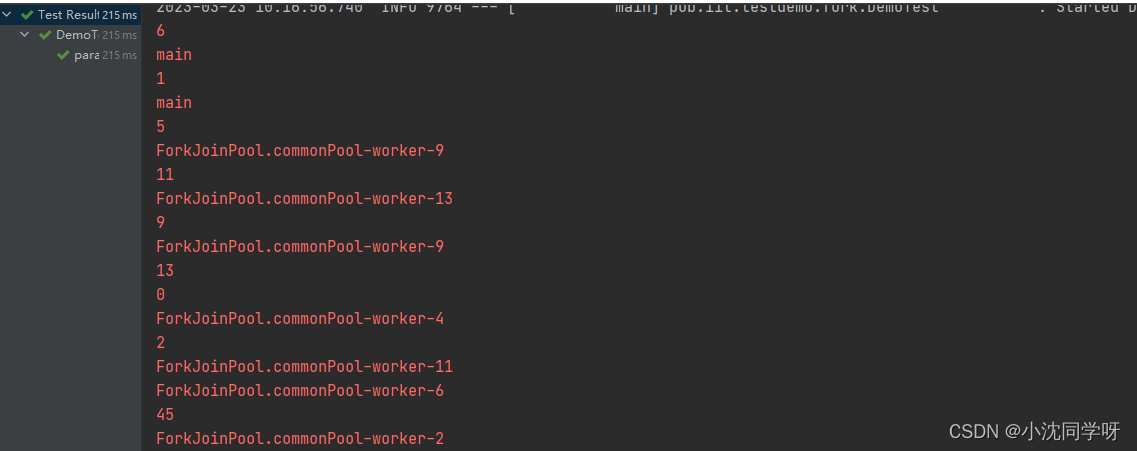
如图所示并行流内部是由主线程和ForkJoinPool线程一起执行的,大大缩短执行时间。
我们先来源码赏析:
//返回一个并行流
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
如源码所示传入默认true并行标识。
继续进入执行源码:
@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
static final class ForEachTask<S, T> extends CountedCompleter<Void>
abstract class CountedCompleter<T> extends ForkJoinTask<T>
如上源码所示parallelStream 内部执行还是用的 ForkJoinTask。因为ForkJoinPool中少量工作
线程能够运行大量的ForkJoinTask。
ForkJoin原理
ForkJoin框架是JDK1.7引入新特性,内部实现了ExecutorService接口,它使用了一个无限队列还缓存任务,在使用过程中传入线程数量,如果不传入默认CPU核心数量作为线程数量。
ForkJoin主要包含ForkJoinPool 并行线程池、ForkJoinTask并行任务、ForkJoinWorkerThread并行工作线程等工具类组成。ForkJoin框架通过这三个主要类实现任务的‘分而治之’。
ForkJoin框架就好比我们的快速排序算法。快速排序其原理是将一个数组拆分为左右两个数组进行排序,左右两个数据内部再次拆分为左右两个数组内部进行排序,依次类推将一个大数组分为多个小数组进排序。同样的道理,ForkJoinTask的Fork()就是将一个大任务重复拆分为很多个子任务,join()方法则是将子任务执行结果汇聚给主任务。
ForkJoin源码解析
ForkJoin主要包含ForkJoinPool 并行线程池、ForkJoinTask并行任务、ForkJoinWorkerThread并行工作线程等工具类组成。
ForkJoinPool源码解析
ForkJoinPool并行线程池,内部实现了ExecutorService接口。
进入JUC ForkJoinPool查看源码
/**
* Creates a {@code ForkJoinPool} with parallelism equal to {@link
* java.lang.Runtime#availableProcessors}, using the {@linkplain
* #defaultForkJoinWorkerThreadFactory default thread factory},
* no UncaughtExceptionHandler, and non-async LIFO processing mode.
*
* @throws SecurityException if a security manager exists and
* the caller is not permitted to modify threads
* because it does not hold {@link
* java.lang.RuntimePermission}{@code ("modifyThread")}
*/
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
/**
* Creates a {@code ForkJoinPool} with the indicated parallelism
* level, the {@linkplain
* #defaultForkJoinWorkerThreadFactory default thread factory},
* no UncaughtExceptionHandler, and non-async LIFO processing mode.
*
* @param parallelism the parallelism level
* @throws IllegalArgumentException if parallelism less than or
* equal to zero, or greater than implementation limit
* @throws SecurityException if a security manager exists and
* the caller is not permitted to modify threads
* because it does not hold {@link
* java.lang.RuntimePermission}{@code ("modifyThread")}
*/
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
如源码所示,ForkJoinPool 可以它使用了一个无限队列还缓存任务,在使用过程中传入线程数量,如果不传入默认CPU核心数量作为线程数量。
继续查看源码submit()方法
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
发现ForkJoinPool的submit()方法,submit()方法主要是提交ForkJoinTask并行任务。
综上所述,ForkJoinPool 是有个并行线程池,由一个无限队列保存ForkJoinTask任务,而且执行线程数量可以传入并默认为CPU核心数。ForkJoinPool 也提供execute()执行方法,execute(task)执行方法来触发ForkJoinTask并行任务的执行。
ForkJoinTask源码解析
ForkJoinTask 是 ForkJoin框架的任务抽象类,内部封装了任务数据和计算并支持并行执行。ForkJoinTask 比线程轻量,可以在少量的ForkJoinWorkerThread运行大量的ForkJoinTask。
先查看源码
public abstract class ForkJoinTask<V> implements Future<V>, Serializable
如源码所示ForkJoinTask是一个抽象类,并实现Future可以响应任务执行结果
继续查看源码
// public methods
/**
* Arranges to asynchronously execute this task in the pool the
* current task is running in, if applicable, or using the {@link
* ForkJoinPool#commonPool()} if not {@link #inForkJoinPool}. While
* it is not necessarily enforced, it is a usage error to fork a
* task more than once unless it has completed and been
* reinitialized. Subsequent modifications to the state of this
* task or any data it operates on are not necessarily
* consistently observable by any thread other than the one
* executing it unless preceded by a call to {@link #join} or
* related methods, or a call to {@link #isDone} returning {@code
* true}.
*
* @return {@code this}, to simplify usage
*/
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
/**
* Returns the result of the computation when it {@link #isDone is
* done}. This method differs from {@link #get()} in that
* abnormal completion results in {@code RuntimeException} or
* {@code Error}, not {@code ExecutionException}, and that
* interrupts of the calling thread do <em>not</em> cause the
* method to abruptly return by throwing {@code
* InterruptedException}.
*
* @return the computed result
*/
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
如源码所示,ForkJoinTask提供fork()方法与Join()方法。fork()方法将主任务分解为子任务加入ForkJoinPool线程池阻塞队列等待执行,Join()方法则是监听ForkJoinTask子任务并在子任务完成后将结果返回给主任务。
ForkJoinWorkerThread源码解析
ForkJoinWorkerThread是ForkJoin框架中的并行工作线程,在一个ForkJoinPool并行线程池下会有定量的ForkJoinWorkerThread并行工作线程,而在一个ForkJoinWorkerThread工作线程下会有多个ForkJoinTask并行任务。
进入ForkJoinWorkerThread查看源码
public class ForkJoinWorkerThread extends Thread
ForkJoinWorkerThread继承Thread 是一个不择不扣的线程。
继续查看源码
public void run() {
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
onStart();
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
onTermination(exception);
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);
}
}
}
}
由ForkJoinWorkerThread线程run()方法可以知道运行线程是从workQueue工作阻塞队列里面取出任务进行执行,当然deregisterWorker()则是善后工作。
ForkJoinTask实现类
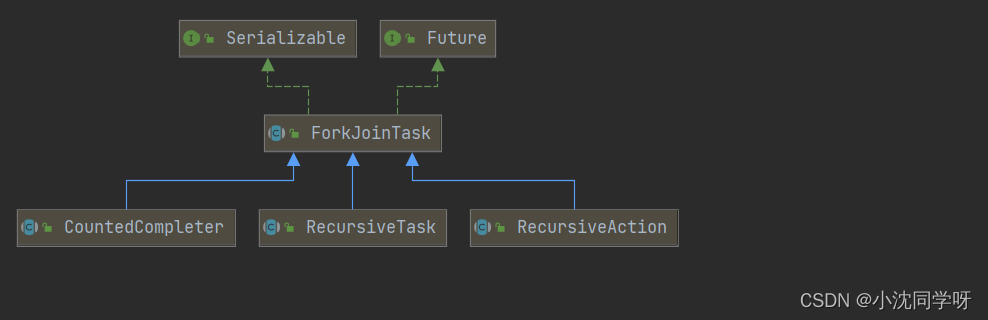
如图所示ForkJoinTask抽象类提供了三种实现类,分别是:
1、RecursiveTask 有返回值的并行任务
2、RecursiveAction 无返回值的并行任务
3、CountedCompleter 带有钩子函数的并行任务,完成任务后可以触发其他任务
ForkJoin实战
案例:
比如我们需要计算1-10000这10000个数相加之和是多少,此时我们就可以采用ForkJoin框架来计算。经分析运算需要返回结果,则选用可以返回任务执行结果的 RecursiveTask来演示。
1、创建MyForkJoinTask继承RecursiveTask
/**
* MyForkJoinTask
* @author senfel
* @version 1.0
* @date 2023/3/23 14:07
*/
public class MyForkJoinTask extends RecursiveTask<Integer> {
/**
* 开始元素
*/
private Integer startElement;
/**
* 结束元素
*/
private Integer endElement;
public MyForkJoinTask(Integer startElement, Integer endElement) {
this.startElement = startElement;
this.endElement = endElement;
}
/**
* compute
* @author senfel
* @date 2023/3/23 14:08
* @return java.lang.Integer
*/
@Override
protected Integer compute() {
int result = 0;
if(startElement > endElement){
int temp = endElement;
endElement = startElement;
startElement = temp;
}
//间隔两个数之内不进行拆分
if(endElement - startElement <= 2){
for(int i = endElement;i >= startElement;i--) {
result += i;
}
}else{
//获取两个数中间值
int middle = (endElement + startElement) / 2;
MyForkJoinTask taskByLeft = new MyForkJoinTask(startElement, middle);
MyForkJoinTask taskByRight = new MyForkJoinTask(middle+1, endElement);
//执行子任务
taskByLeft.fork();
taskByRight.fork();
//等待子任务完成
Integer joinByLeft = taskByLeft.join();
Integer joinByRight = taskByRight.join();
result = joinByLeft+joinByRight;
}
return result;
}
}
2、测试用例直接用当前CPU核心数线程,将并行任务放入并行线程池执行
/**
* forkJoinTest
* @author senfel
* @date 2023/3/23 13:39
* @return void
*/
@Test
public void forkJoinTest() throws Exception{
//可执行线程
int processors = Runtime.getRuntime().availableProcessors();
System.err.println("当前计算机可执行线程数:"+processors);
long startTime = System.currentTimeMillis();
//创建一个并行线程池
ForkJoinPool forkJoinPool = new ForkJoinPool(processors);
//创建并行任务
MyForkJoinTask task = new MyForkJoinTask(1,10000);
//用并行线程池执行任务
ForkJoinTask<Integer> submit = forkJoinPool.submit(task);
//获取执行结果
Integer result = submit.get();
long endTime = System.currentTimeMillis();
System.err.println("1-10000所有数字之和为:"+result+","+processors+"个线程运行计算时间为:"+(endTime-startTime)+"毫秒。");
}
3、运行结果
当前计算机可执行线程数:12
1-10000所有数字之和为:50005000,运行计算时间为:22毫秒。
结论
通过本篇文章我们知道了ForkJoin并行框架一个将任务‘分而治之’的并行架构,我们可以通过ForkJoinTask 实现一个具体的并行任务类,并用fork()\join()方法实现任务的分解和结果合并,再将ForkJoinTask 通过 ForkJoinPool并行线程池进行submit()创建ForkJoinWorkerThread执行。
ForkJoinTask抽象类主要有三种实现类RecursiveTask有返回值的并行任务 、RecursiveAction无返回值的并行任务 与CountedCompleter 带有钩子函数的并行任务。
在实际生产业务开发过程中,遇见可以并行计算的场景可以用ForkJoin框架来提升运算速度。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154645.html

