
一、Kafka简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式消息中间件,它可以处理消费者在网站中的所有动作流数据。
二、Kafka业务架构
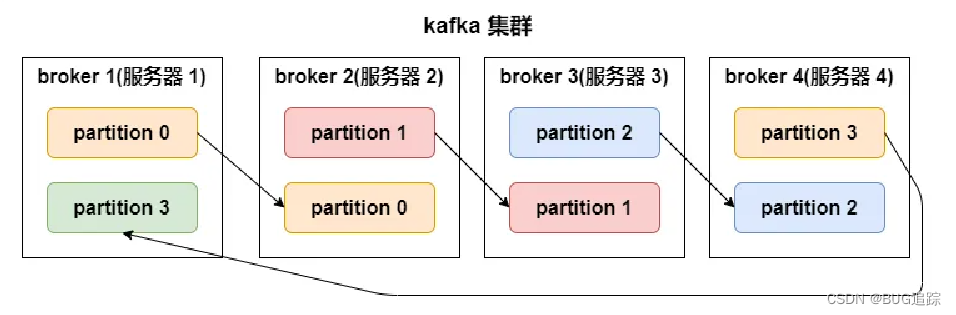
1、Kafka集群
Kafka集群就是有多个kafka实例组成的分布式阵列,生产者producer发送消息到kafka的topic主题,consumer消费者也从topic拉取数据进行消费。集群的所有管理都交由zookeeper进行管理,当某一broker实例宕机,zookeeper会自动进行处理让集群恢复。
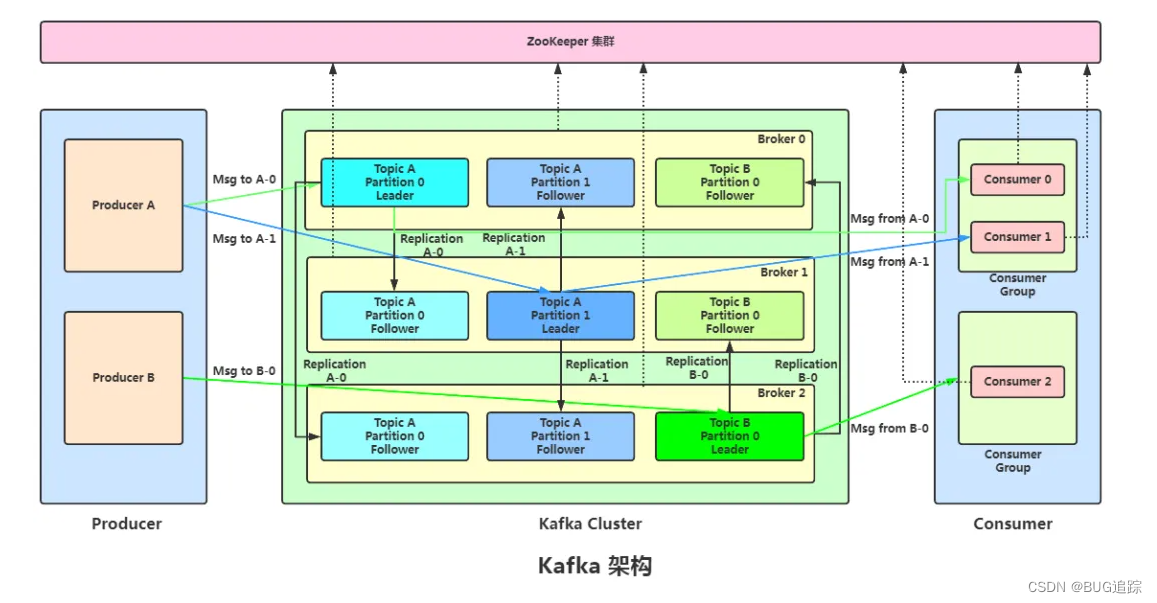
2、Kafka broker实例与分区
一个broker就是一个kafka实例,一个broker中可以有多个partition分区,每个分区保存部分数据,所有分区数据总和就是完整的数据,不同的分区可以部署在不同的broker上来实现分布式高可用。一个partition分区分为主分区和副本分区,主分区主要负责数据处理,副本分区则是提供数据冗余,副本分区的数据同步方式是从主分区拉取数据。当主分区出现问题时候,副本分区可以重新选举主分区从而恢复集群。
三、消息丢失处理场景及处理方案
1、丢失场景
1.1 producer生产者丢失消息
生产者发送消息后由于网络等原因并没有到kafka实例的场景
处理方案:
producer 端设置ack
request.required.acks
0:producer不等待broker的ack,broker一接收到还没有写入磁盘就已经返回,可靠性最低;
1:producer等待broker的ack,partition的leader刷盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据,可靠性中;
-1:producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack,可靠性高,但延迟时间长
1.2 broker kafka消息中间件自身丢失消息
消息已经发送到kafka,由于kafka异常情况或者宕机导致消息丢失
处理方案:
1.2.1 给 topic 设置 replication.factor 参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本;
1.22 在 Kafka 服务端设置 min.insync.replicas 参数:这个值必须大于 1,要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower ,可被选举为leader;
1.2.3 在 producer 端设置 acks=-1:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了;
1.2.4 在 producer 端设置 retries=MAX(无限次重试):这个是要求一旦写入失败,就无限重试。
1.3 consumer 消费者丢失消息
消费者业务异常或者网络异常,kafka自动offset导致正常偏移,使得消息未消费丢失
处理方案:
关闭自动提交offset
enable.auto.commit = true,不管执行结果如何,消费者会自动提交offset;
enable.auto.commit = false,需要用户需要手动提交offset,可以根据执行结果具体处理offset。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154672.html

