
事故回顾
20220805
17:39 部分用户反映系统卡顿,页面发送请求后页面不响应数据
17:40 手动进入服务器发现busienss-216 服务内存吃满,且连续fullgc,但内存不能够释放
17:50 手动从consul剔除服务,由business-215 完全接管请求
curl --request PUT http://ip:8600/v1/agent/service/deregister/service:seataServer-ip:7008
17:51 开始排查216
故障分析
1、进入docker容器发现jvm频繁full gc,查看目前堆中大对象
jmap -histo:live 1
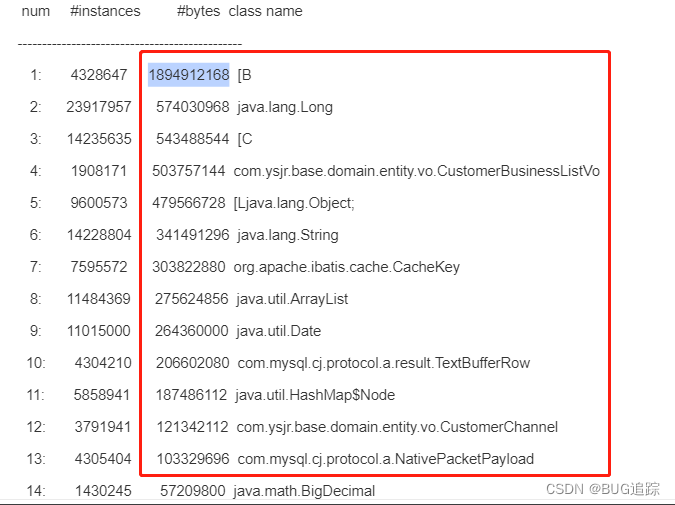
发现堆内存在大对象多,且业务对象近1G,其他对象近5G
初步估计内存泄漏。
2、启动arthas进入控制仪表盘发现部分线程阻塞。查看线程栈信息
thread 786
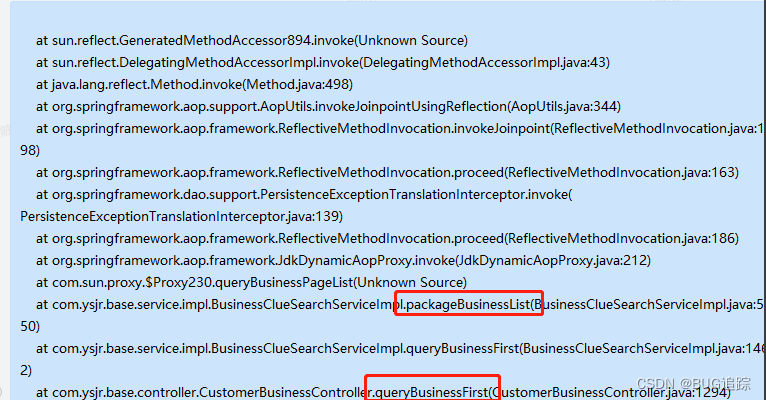
发现内存泄漏代码案发现场 packageBusinessList 方法内部应该有缺陷代码
3、结合系统日志,发现有一个sql 大小达到101M远远大于mysql配置的包大小64M
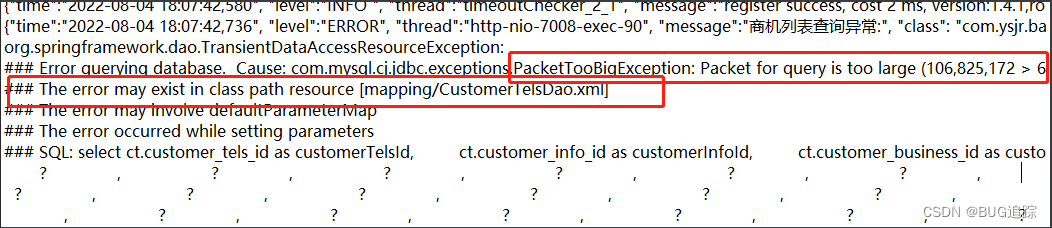
此时应该可以确定是由于传入了大量参数导致内存吃满,再次验证是代码问题。
4、继续查看日志信息,往上搜索线程 http-nio-7008-exec-90 当前线程查看参数来源
ps -ef | grep -A 150 ‘http-nio-7008-exec-90’ logs/info.2022-08-04-96.log
发现异常sql语句
{“time”:“2022-08-04 17:28:07,277”, “level”:”INFO “, “thread”:“http-nio-7008-exec-90”, “message”:”Logic SQL:
SELECT tcb.customer_business_id,
tcb.customer_info_id,
tccbc.channel_grade,
tccbc.customer_channel_id,
tcbbt.description AS business_description,
tcf.create_time AS follow_time,
tcfbt.description AS follow_description,
tcbl.loan_money,
tcbl.loan_type,
tci.add_blacklist,
tbpp.create_time as poolCreateTime
FROM t_customer_business tcb
LEFT JOIN t_customer_business_loan tcbl
ON tcbl.customer_business_id = tcb.customer_business_id
LEFT JOIN t_customer_business_big_text tcbbt
ON tcbbt.customer_business_id = tcb.customer_business_id
LEFT JOIN t_customer_follow tcf ON tcf.customer_follow_id = tcb.customer_follow_id
LEFT JOIN t_customer_follow_big_text tcfbt
ON tcfbt.customer_follow_id = tcb.customer_follow_id
LEFT JOIN t_customer_clue_business_channel tccbc
ON tccbc.customer_business_id = tcb.customer_business_id
LEFT JOIN t_customer_info tci ON tci.customer_id=tcb.customer_info_id
left join t_business_public_pool tbpp on tbpp.customer_business_id = tcb.customer_business_id
WHERE tcb.belong_company_id = ?
order by conversion_time
desc
发现并没有传入商机id进行过滤,由于本系统业务商机数量级有几百万,如果不传入商机id查询将会将全库数据查询出,将会导致系统内存直接吃满。
5、为什么会没有传入商机ID,这个业务是必须要求有商机才能查询的。
定位异常sql产生代码:

以及前步骤代码:
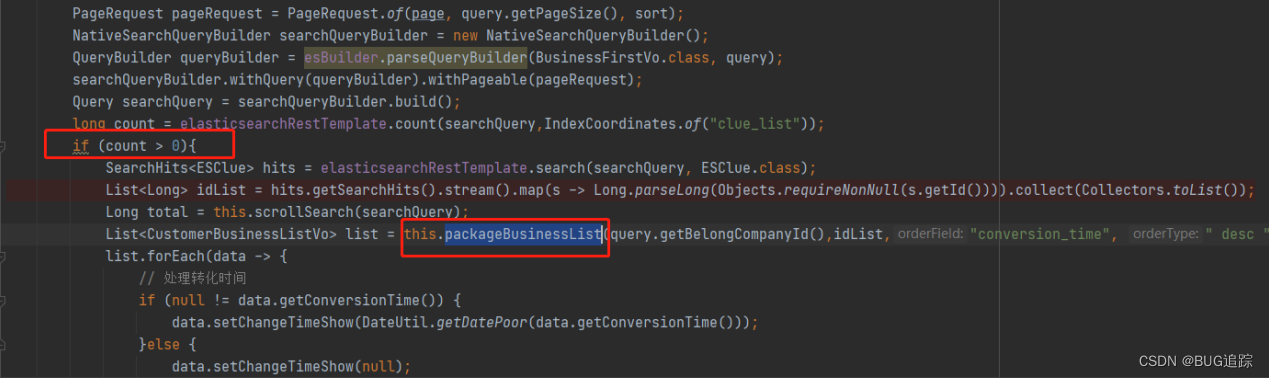
发现数据来源于ES,如果ES查询出来有数量,则再次查询数据并拿出业务主键进行后续逻辑处理。如果二次查询没有数据响应,你们将会导致后续查询占用大量内存。
那么,ES为什么第一次查询有数据,第二次查询没有数据呢?
6、查看ES索引配置
发现当前索引主分片1、副本1
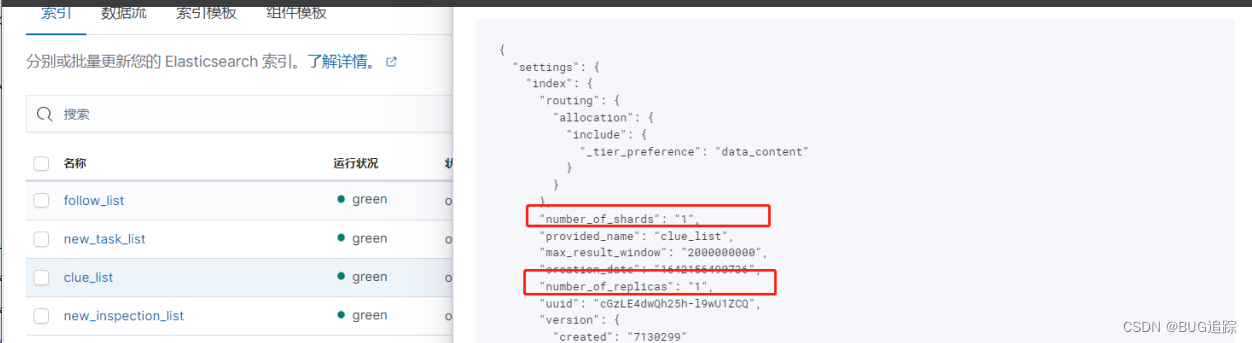
查看索引 refresh参数,发现是默认1s
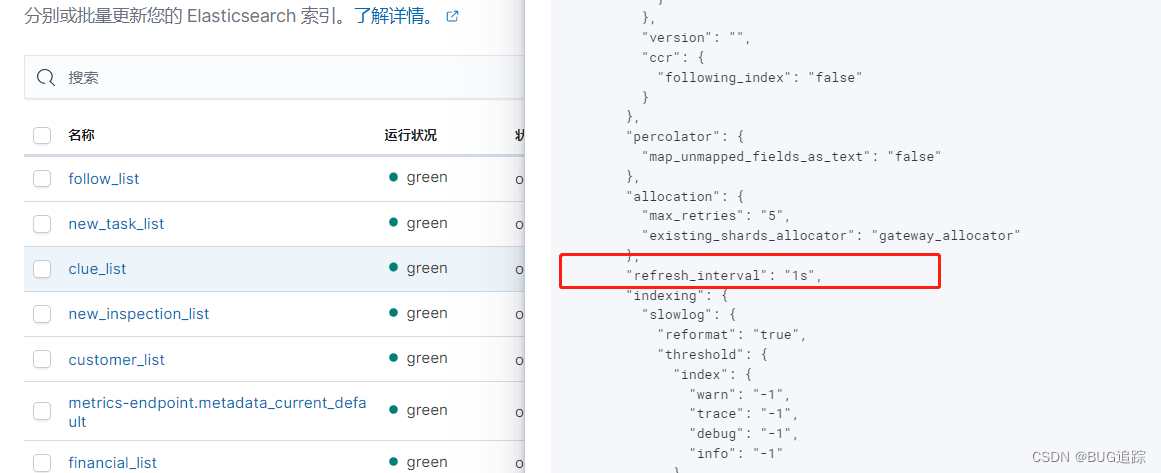
此时有一定的概率是ES 主分片和副本数据不一致造成,因为ES新增一条数据会先放入buffer缓冲区,并写入translog;然后根据配置的刷新时间进行索引刷新。这里我们配置的1s,那么当索引变更1s才会进行refresh到内存,然后默认30min会flush到磁盘。需要注意的是只有refresh到内存的数据才会被查询到,在缓冲区的数据是不能被查询到的。
结合本次事故,如果数据在进入ES后的同时在极短的时间查询数据才能够触发这个雷区。
7、再次确认是否是ES数据不一致造成,是否是有业务数据进入系统的同时,有人员命中这条数据
查看系统日志发现ES查询时间 17:28:05
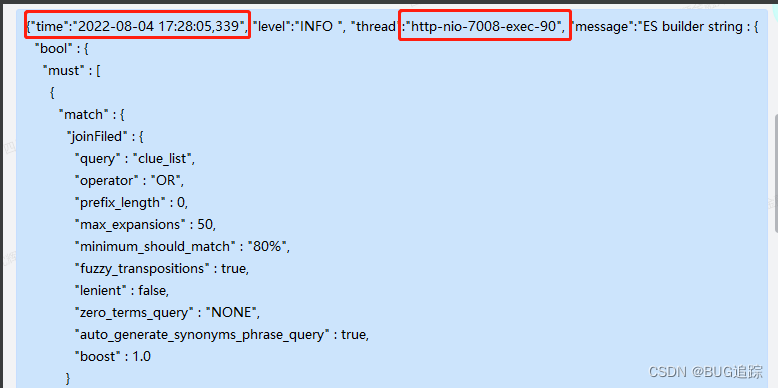
查看数据进入系统时间为 17:27:59
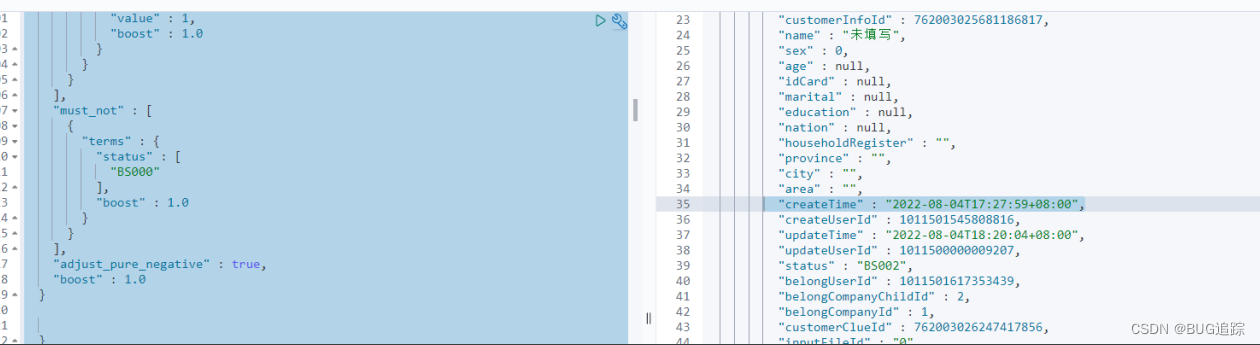
由于我们业务数据写入关系数据库后会用canal监听写入ES,排除业务处理时间、ES refresh时间,以及业务端调用查询业务时间,可以确定是ES主分片与副本数据不一致导致本次事故。
8、改进方案,查询业务数据进行二次验证
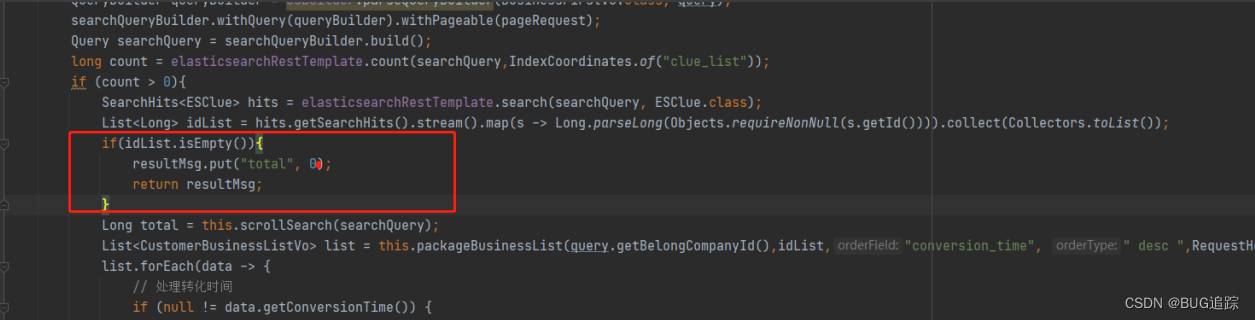
结论:ES 数据进入会先写入buffer缓冲区、translog文件,默认1s后会将数据refresh 文件系统cache,刷入内存后我们才能查询出该数据。实际业务开发中应该二次验证数据,以防止并发时候取不出数据造成意想不到的产线事故。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154701.html

