
Hive的下载与安装

下载完成后需要将文件上传到服务器或虚拟机上,当然如果多wget命令比较熟悉也可以直接下载源码文件。
上传后并解压缩:

接下来配置hive的环境变量,全局使用hive:vi /etc/profile
export HADOOP_HOME=/root/hadoop/hadoop-2.10.1
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export HIVE_HOME=/root/hadoop/hive/apache-hive-2.1.0-bin
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH:$HOME/bin
上面包含了jdk,hadoop的环境变量,详情请看Ubuntu20.04下搭建Hadoop伪分布式集群
hive核心部分是:
export HIVE_HOME=/root/hadoop/hive/apache-hive-2.1.0-bin
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH:$HOME/bin
输入hive查看环境变量是否配置成功:
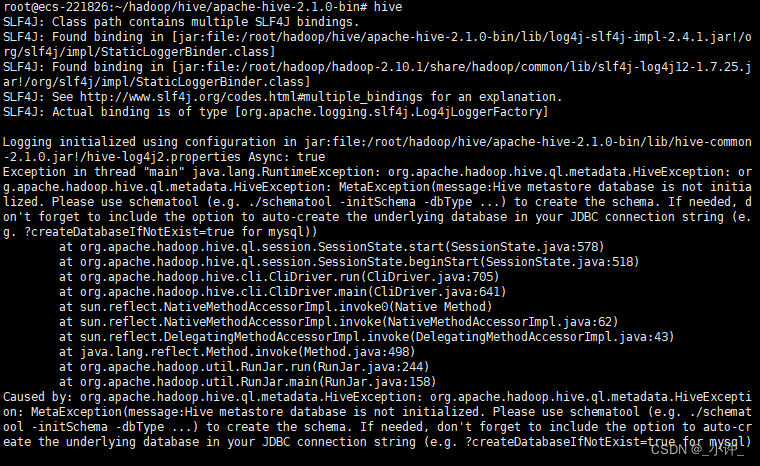
出现了MetaException(message:Hive metastore database is not initialized. Please use schematool 错误,至少说明环境变量配置成功。
这是由于没有初始化数据库,生成元数据。需要执行以下指令(在hive的bin目录下执行)
./schematool -initSchema -dbType mysql
不是现在执行而是配置好mysql数据库后执行,见下。
Hive的配置
hive-env.sh文件配置
在hive的conf目录找到hive-env.sh.template复制一份改名为hive-env.sh
cp hive-env.sh.template hive-env.sh
配置改名后的文件:
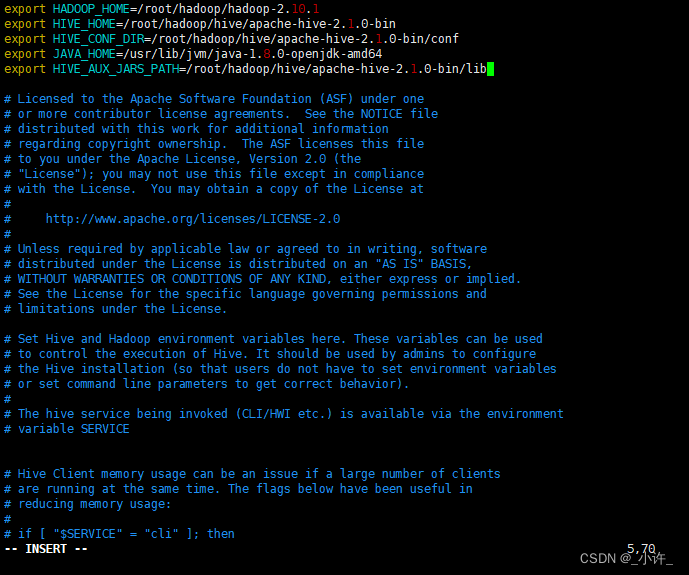
export HADOOP_HOME=/root/hadoop/hadoop-2.10.1
export HIVE_HOME=/root/hadoop/hive/apache-hive-2.1.0-bin
export HIVE_CONF_DIR=/root/hadoop/hive/apache-hive-2.1.0-bin/conf
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export HIVE_AUX_JARS_PATH=/root/hadoop/hive/apache-hive-2.1.0-bin/lib
hive-site.xml文件配置
在conf目录找到hive-default.xml.template 复制一份并改名为hive-site.xml
cp hive-default.xml.template hive-site.xml
# 由于源文件的内容过多,也可以直接新建改文件
该文件的配置非常多,在顶部加入以下内容即可:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://139.9.209.93:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Xwh190823</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://ecs-221826:9010/hive/warehouse</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/root/hadoop/hive/apache-hive-2.1.0-bin/exec</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/root/hadoop/hive/apache-hive-2.1.0-bin/downloadedsource</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/root/hadoop/hive/apache-hive-2.1.0-bin/logs</value>
</property>
</configuration>
hive-log4j2.properties文件配置
cp hive-log4j2.properties.template hive-log4j2.properties
修改改配置到log目录,没有就新建:

将mysql连接的工具包上传到hive的lib目录下:


解决hive和hadoop的log4j版本冲突问题,直接删除hive的jar工具包即可,删除有impl的那个。
配置mysql数据库
#进入数据库
mysql -u root -p
# 创建数据库
create database hive;
# 配置权限
grant all on hive.* to root@’master’ identified by ‘hivepwd’; -- 此处的单引号需要修改
# 若上面的失败,就执行下面两行
create user 'root'@'ecs-221826' identified by 'Xwh190823';
grant all on hive.* to 'root'@'139.9.209.93' WITH GRANT OPTION;
# 使配置生效
flush privileges;
退出mysql
exit
上面的grant all on hive.* to root@’master’ identified by ‘hivepwd’是会报错的,因为新版的的mysql版本已经将创建账户和赋予权限的方式分开了解决方案:
使用 grant 权限列表 on 数据库 to ‘用户名’@’访问主机’ identified by ‘密码’时会出现”……near ‘identified by ‘密码” at line 1”错误
初始化hive的元数据库
在第一次使用hive之前,需要使用如下命令初始化hive的元数据库,该命令只能执行一次(在hive的bin目录下)
schematool -dbType mysql -initSchema
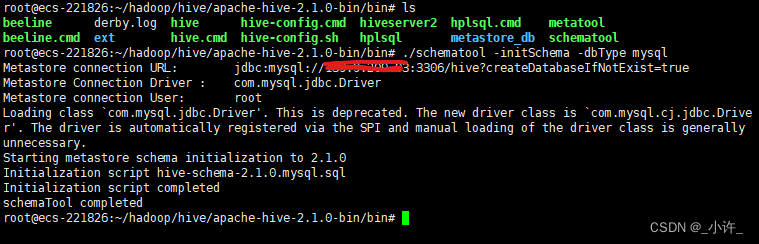
出现下面这个提示需要回到hive-site.xml 配置文件将数据库驱动改为com.mysql.cj.jdbc.Driver,这是数据8版本的驱动。

这是在此初始化hive数据库会出现org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!的错误。
这时需要删除之前穿件的hive数据后重新创建,即可如下执行成功:

schematool -dbType mysql -initSchema该命令只能执行一次,多次执行就会包上面的错误,需要删除hive数据库重新配置。
Hive的使用
在hive的配置文件中已经配置了hadoop的节点信息

使用命令hive启动hive,注意,Hive启动时会直接访问HDFS,Hive的一些操作会继续MapReduce实现,所以需要保证HDFS和yarn都处于正常的启动状态。
# 进入数据库
hive

# 显示数据库
show databases;

hive也是基于sql语言作为DDL,DML的数据库。
hive使用hadoop需要使用yarn的一些功能项,需要新增配置:
<-- Map Reduce运行需要设置的shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<-- 可以为容器分配的物理内存量(MB)。如果设置为-1且yarn.nodemanager.resource.detect-hardware-capabilities为true,则会自动计算(如果是Windows和Linux)。在其他情况下,默认值为8192MB。 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
再次开启hive数据库,创建包并插入数据:
insert into student(1,'tom');
hive (default)> insert into javaAndBigdata.student(id,name) values (3,"java页大数据");
Query ID = root_20220323224810_5192a9f4-95ae-4166-b21e-c8e5f1493c32
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
2022-03-23 22:48:15,074 INFO [d31f649c-88de-4e0c-9dbb-f724e403a684 main] client.AHSProxy: Connecting to Application History server at slave2/192.168.52.11:10200
2022-03-23 22:48:15,183 INFO [d31f649c-88de-4e0c-9dbb-f724e403a684 main] client.AHSProxy: Connecting to Application History server at slave2/192.168.52.11:10200
2022-03-23 22:48:15,252 INFO [d31f649c-88de-4e0c-9dbb-f724e403a684 main] client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Starting Job = job_1648046463761_0002, Tracking URL = http://slave1:8088/proxy/application_1648046463761_0002/
Kill Command = /opt/hadoop-3.2.2/bin/mapred job -kill job_1648046463761_0002
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2022-03-23 22:48:36,569 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1648046463761_0002 with errors
Error during job, obtaining debugging information...
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
https://www.csdn.net/tags/NtDaAg2sMzUyNDgtYmxvZwO0O0OO0O0O.html
插入成功!
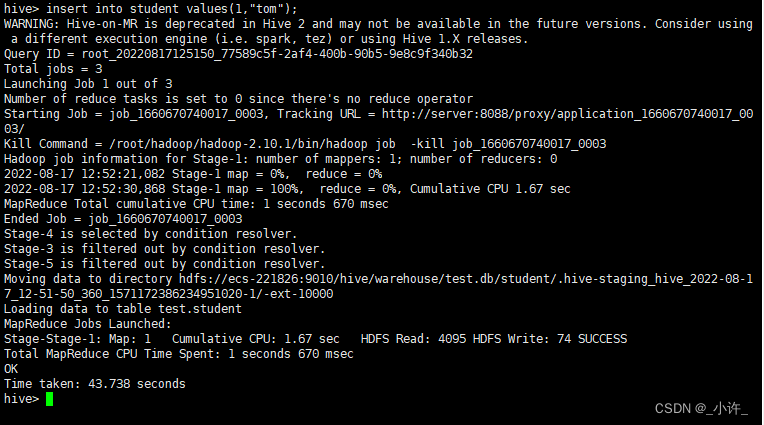
查询语句:

hive配置成功!
Sqoop的下载与安装
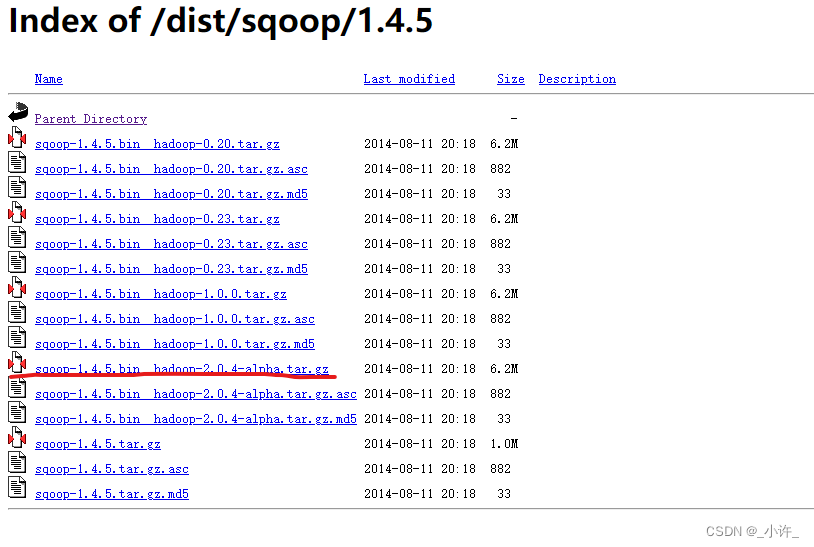

上传到服务器并解压缩:

配置环境把变量:

重启环境变量:
source /etc/profile
查看环境变量是否成功:
sqoop version
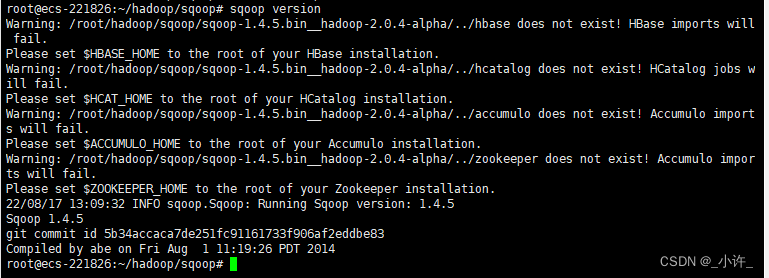
出现上面的情况可以看到sqoop版本号已经出现了,上面的提示信息是缺少连接数据库的包,接下来导入数据库启动包,和之前的hive导包一样,将数据库启动包导入到sqoop的安装目录的lib目录下:


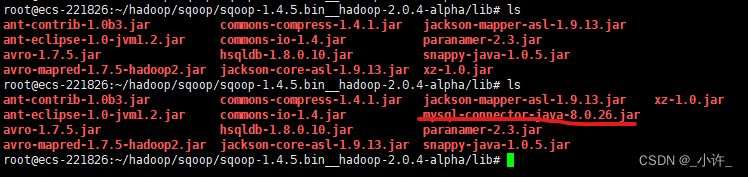
Sqoop的使用
sqoop实现了mysql和hdfs的数据互传。sqoop下载地址
mysql数据导入到hdfs
在Mysql数据库中创建数据库表并插入数据
-- 进入数据库
mysql -u root -p
create database sqoop;
use sqoop;
create table product(
id int not null primary key auto_increment,
name varchar(30),
price double(10,2),
version int
);
insert into product values(null, ‘pro1’, 199, 1);
insert into product values(null, ‘pro2’, 299, 1);
insert into product values(null, ‘pro3’, 399, 1);
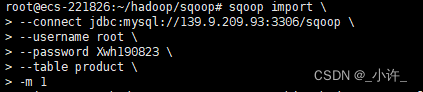
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username root --password Xwh190823 --table product -m 1
参数说明
Import 表示导入数据到HDFS
–connect jdbc:mysql://……表示数据库的连接URL
–username root 数据库用户名
–password root 数据库密码
–table product 数据库表名
-m1 指定用于导入数据的map作业个数SSH
除了上面的写法也可以写在一行用空格隔开:
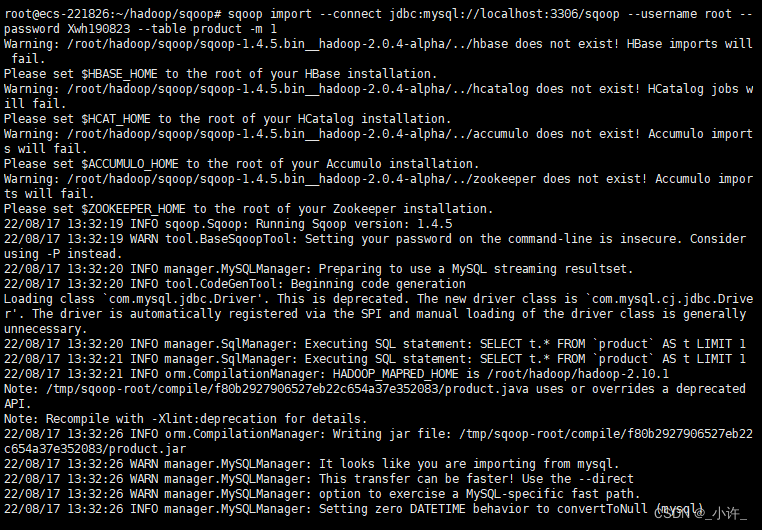
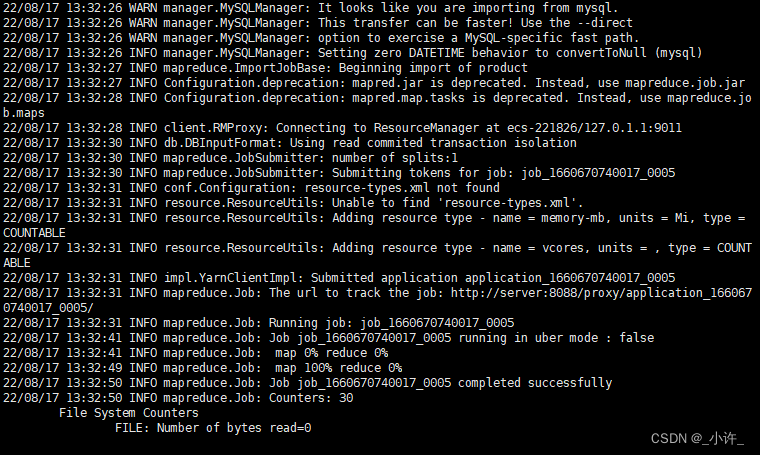
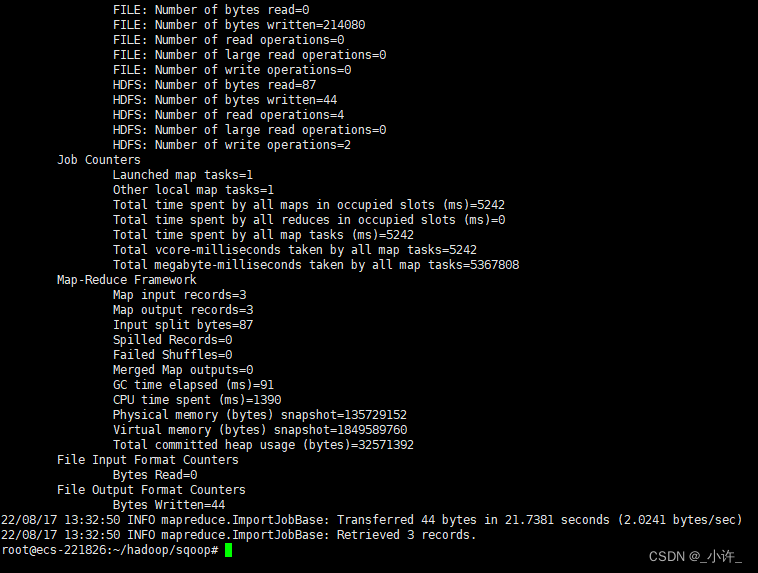
出现如上图所示的即为导入成功!
查看导入结果:
hdfs dfs -ls product

后缀为00000结尾的是数据使用命令cat 查看:
hdfs dfs -cat product/part-m-00000

hdfs数据导入到mysql
在MySQL数据库中创建接收数据的表(要和hdfs模拟导出的字段一致):
use sqoop;
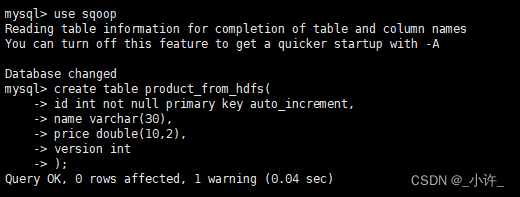
create table product_from_hdfs(
id int not null primary key auto_increment,
name varchar(30),
price double(10,2),
version int
);
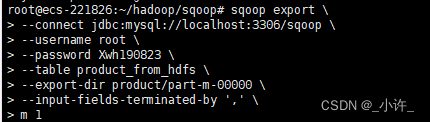
使用sqoop命令将HDFS中的数据导出到MySQL中:
最后一行是
-m 1写错了
参数说明
export 表示从HDFS导出数据
–connect jdbc:mysql://……表示数据库的连接URL
–username root 数据库用户名
–password root 数据库密码
–table product_from_hdfs 数据库表名
–export-dir /user/root/……指定导出的文件
–input-fields-terminated-by ‘,’ 指明导出数据的分隔符
-m1 指定用于导出数据的map作业个数SSH
运行成功之后,到MySQL中查询表product_from_hdfs中的数据
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username root --password Xwh190823 --table product_from_hdfs --export-dir product/part-m-00000 --input-fields-terminated-by ',' -m 1
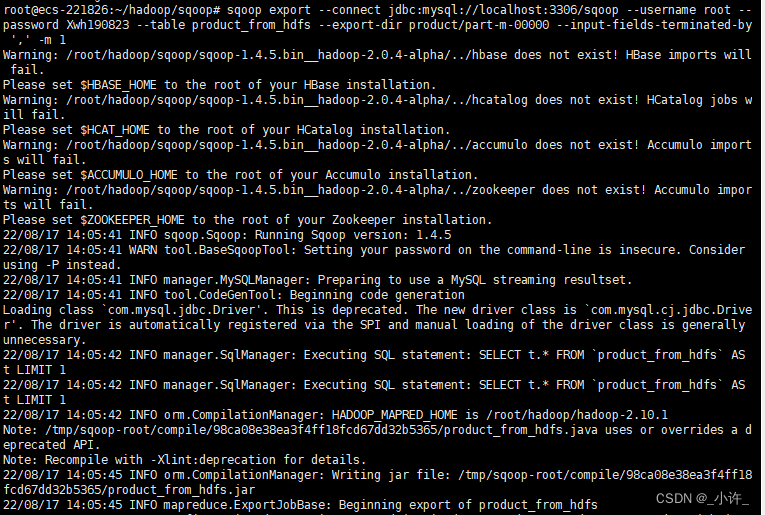
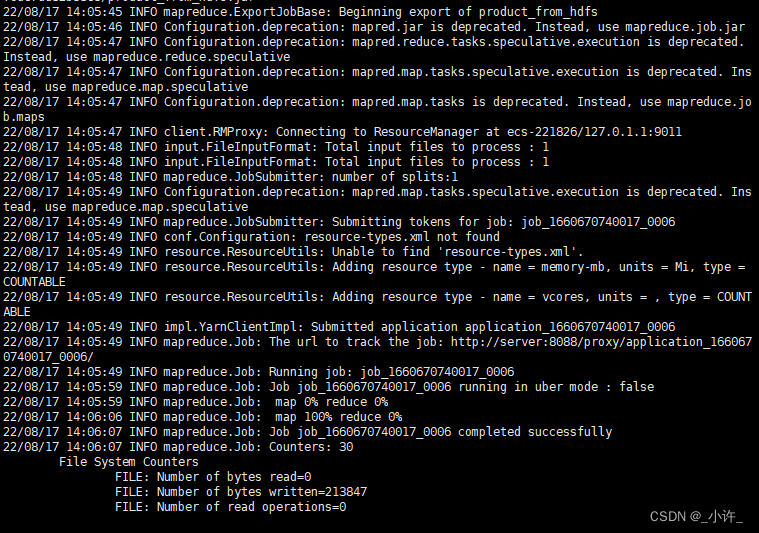
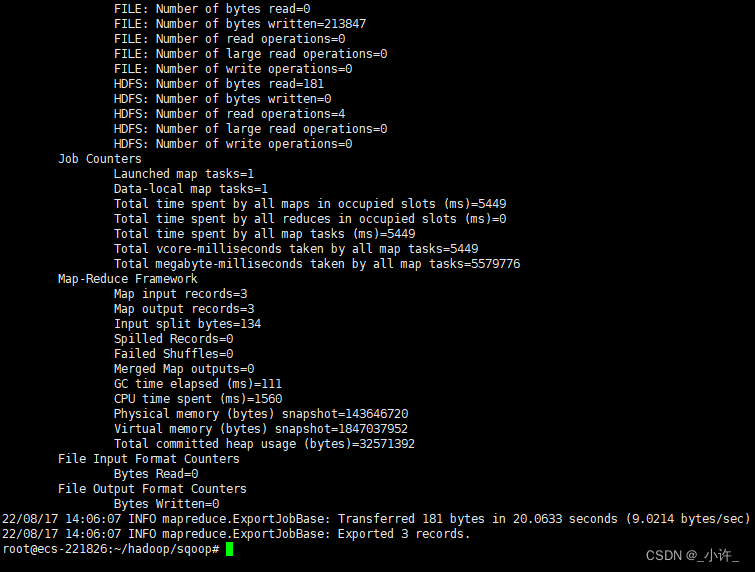
出现如上图所示的内容即为导出成功。
查看建立的数据库是否有数据:
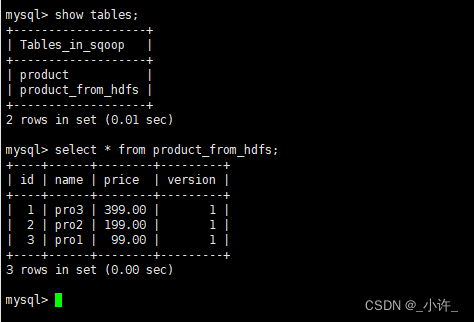
导出成功!
数据转换
csv数据转换为hive的数据表:
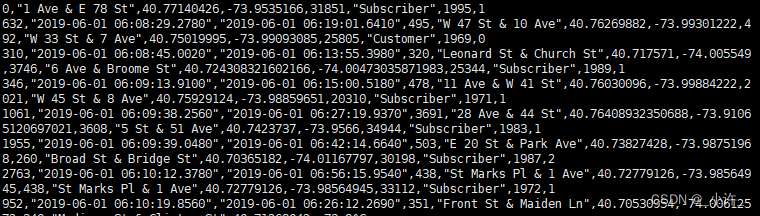

数据处理,包括替换分隔符,去除引号等:

# 对数据文件进行处理
sed -i ‘1d’ /data/201906-citibike-tripdata.csv
# 去掉双引号
sed -i ‘s/”//g’ /data/201906-citibike-tripdata.csv
转化后的数据

上传到hdfs分布式文件系统上

启动hive创建于csv表头对应的数据库
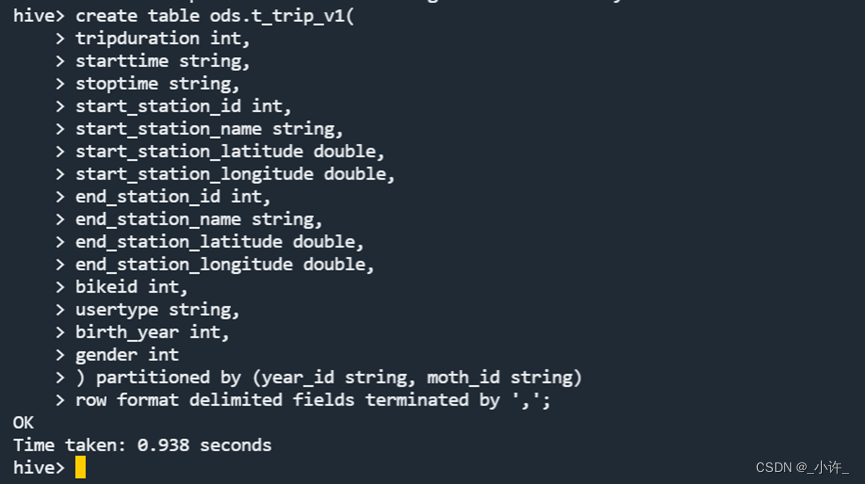
将csv数据导入到数据库表中
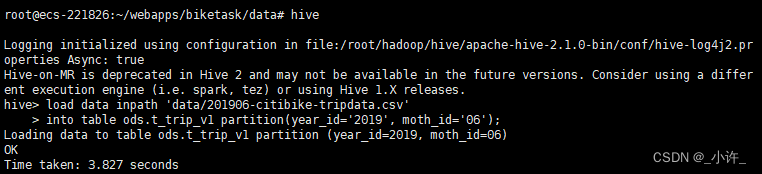
查询数据是否查看成功

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/156239.html

