
JDK环境配置
Hadoop需要JDK环境安装并配置:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html官网下载Linux的版本如jdk-8u231-linux-x64.tar.gz。
新建Java文件夹并解压JDK:tar -zxvf jdk-8u231-linux-x64.tar.gz
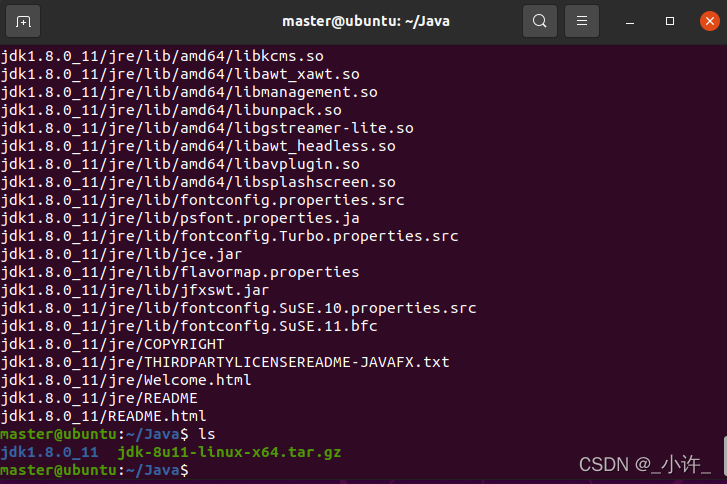
配置环境变量:
cd /etc
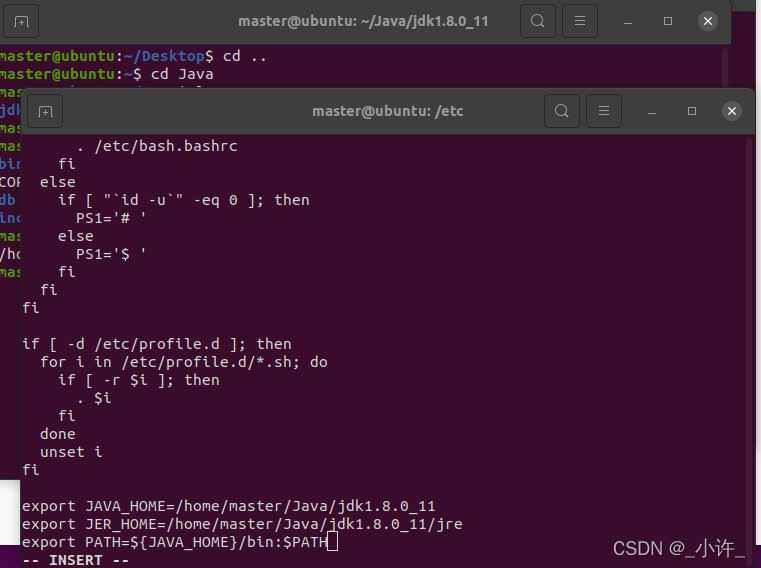
sudo vi profile
在文件末尾增加以下内容(具体路径依据环境而定):
export JAVA_HOME=/Java/jdk1.8.0_11
export JRE_HOME=/Java/jdk1.8.0_11/jre
export PATH=${JAVA_HOME}/bin:$PATH
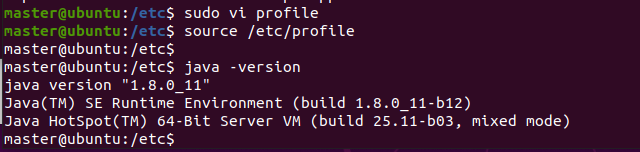
保存退出,在终端界面使用命令: source /etc/profile使配置文件生效。输入java -version查看是否配置成功
也可以选择安装
openjdk:
#安装命令
sudo apt-get install openjdk-8-jre openjdk-8-jdk
#卸载命令
sudo apt-get remove openjdk-8-jdk
sudo apt-get remove openjdk-8-jre-headless
下载并配置Hadoop
新建Hadoop文件夹,解压文件tar -zxvf hadoop-2.10.1.tar.gz
hadoop需要ssh免密登陆等功能,因此先安装ssh。
sudo apt-get install ssh
解压后修改hadoop-env.sh配置文件 修改
修改JAVA_HOME为本机的JDK路径。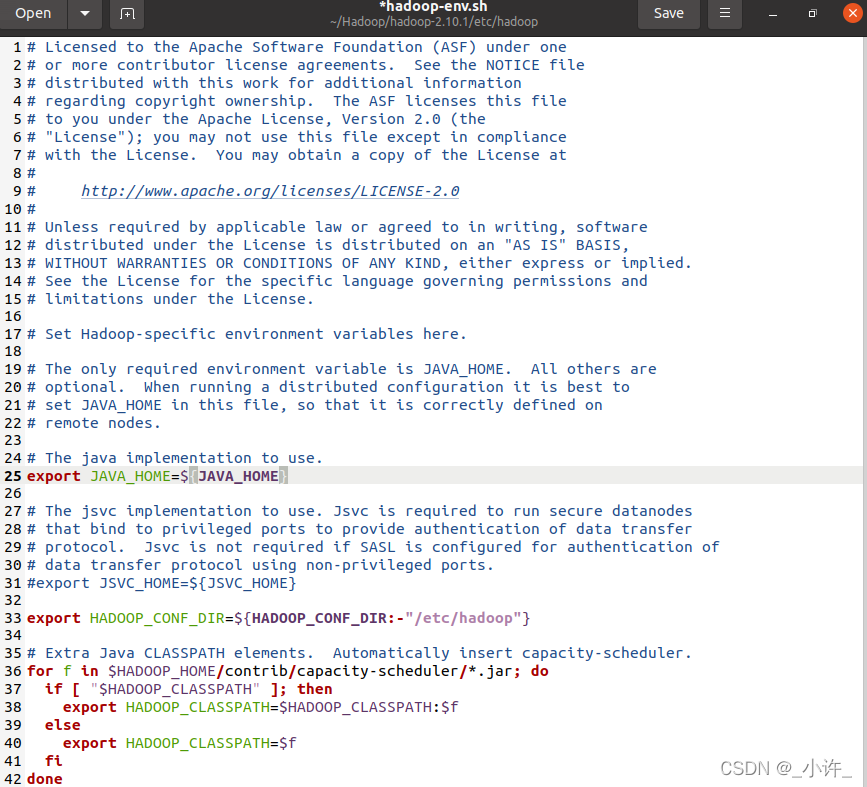
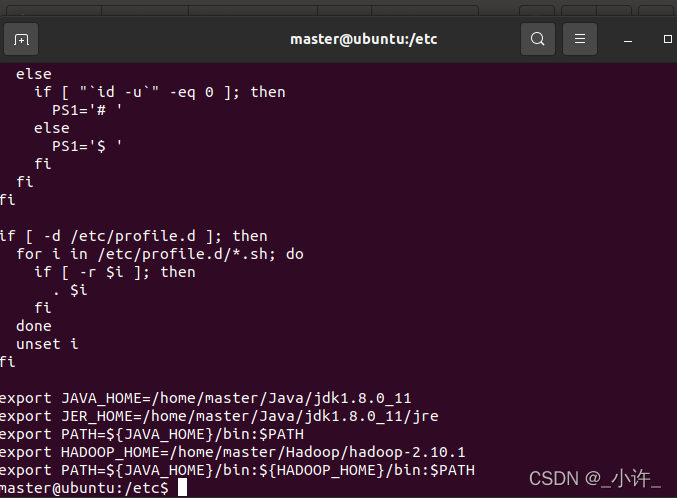
配置Hadoop的环境变量:在/etc/profile追加Hadoop的环境变量。
修改core-site.xml配置文件
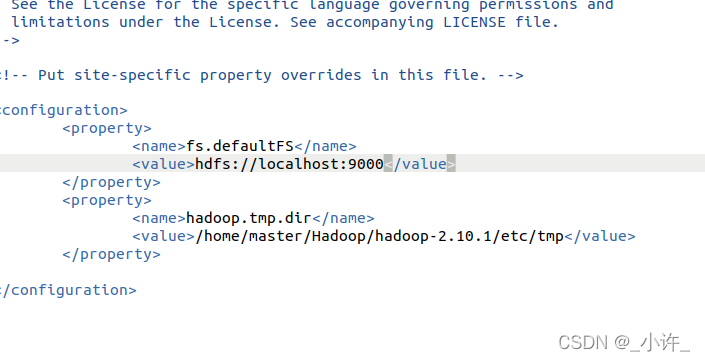
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/master/Hadoop/hadoop-2.10.1/etc/tmp</value>
</property>
</configuration>
注意一定要设置hadoop.tem.dir不然下次启动会找不到namenode
修改hdfs-site.xml配置文件
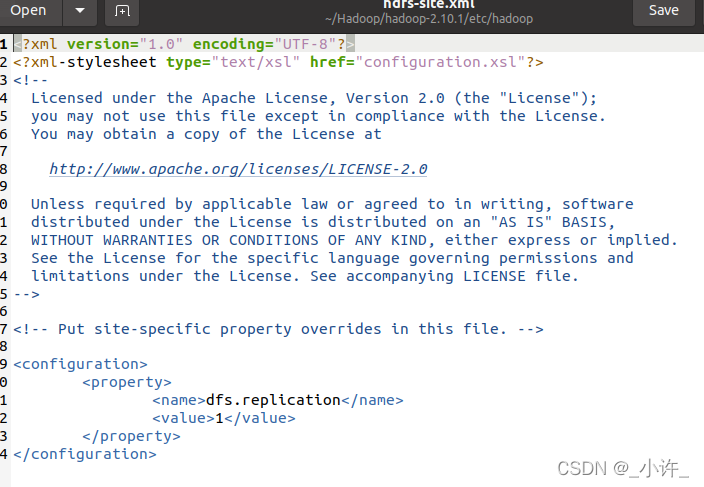
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
设置免密登陆
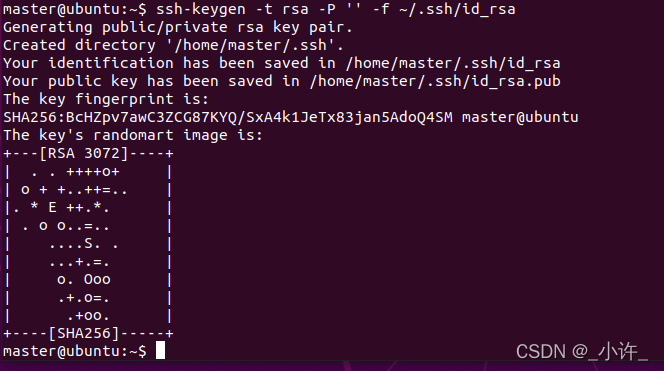
输入ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa出现下面内容:
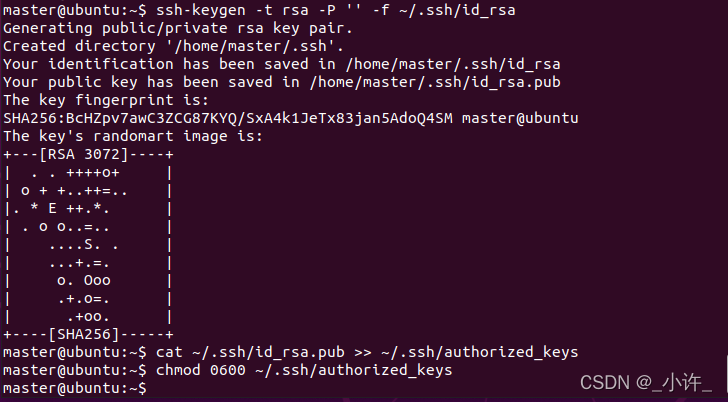
再输入cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
接着输入chmod 0600 ~/.ssh/authorized_keys
检验免密登录是否成功:
使用命令:ssh localhost输入yes,出现下面情况就说明ok了。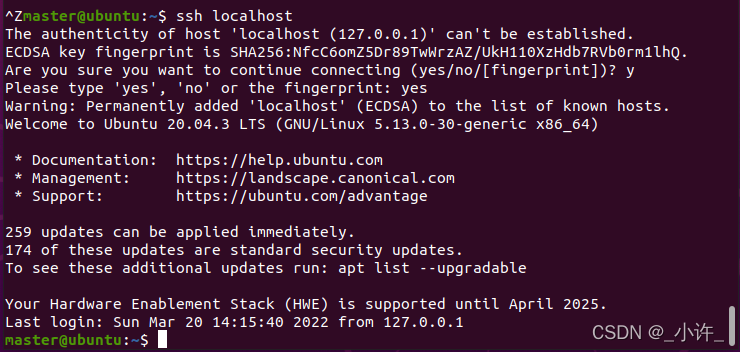
验证Hadoop安装
格式化文件系统,只能格式化一次。hdfs namenode -format
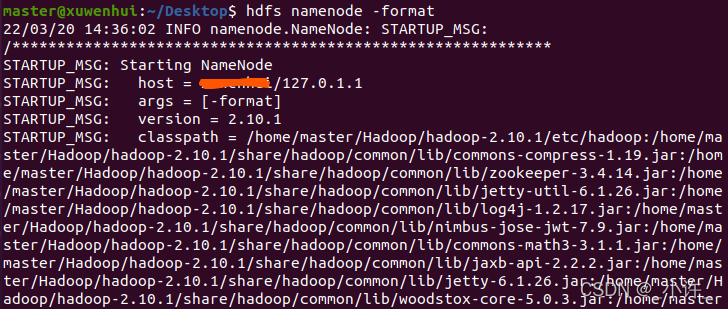
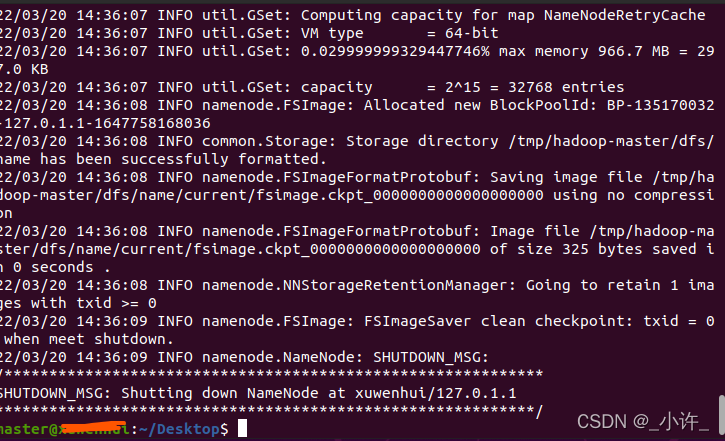
启动hadoop进程start-dfs.sh或start-all.sh结果却出现:

出错的原因是脚本命令实在hadoop文件夹下的sbin目录而不是bin目录
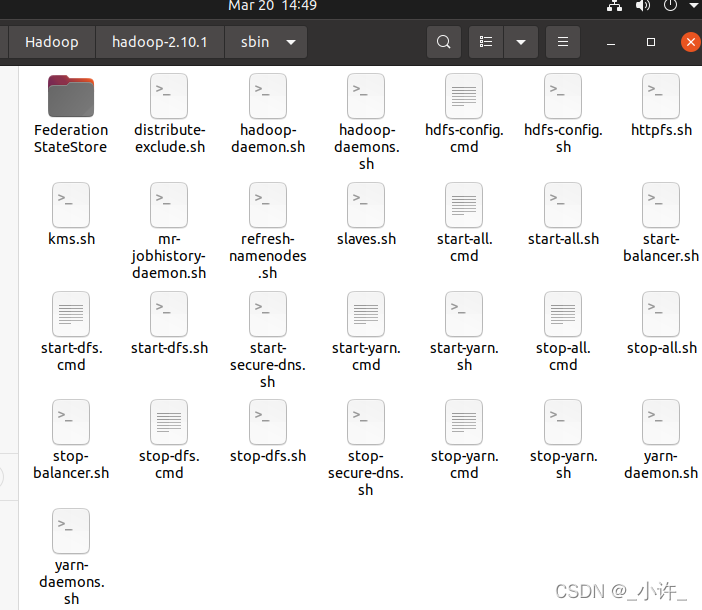
修改/etc/profile的最后一个PATH的${HADOOP_HOME}/sbin将bin改为sbin即可。
修改后成功启动hadoop集群:

输入jps查看hadoop进程:
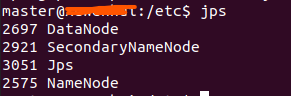
注意要在namenode上启动集群
通过web访问hadoop
主机输入:[ip:50070]访问NameNode
主机输入:[ip:50090]访问DataNode
常见命令:
stop-all.sh和stop-dfs.sh停止所有进程。
start-all.sh和start-dfs.sh启动所有进程。
jps查看所有进程。
上面的hadoop环境搭建式伪分布式的,一台虚拟机既做主节点又作从节点。搭建完整集群参考Linux公社。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/156299.html

