
K-邻近算法
K-邻近算法概述
K-邻近算法是几种基本的分类与回归算法,其输入位实例的特征向量,对应于特征空间的点,输出为实例的类别。
算法的三要素为:K值的选择,距离的度量及分类决策。
k-近邻算法(KNN),它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的k个分类标签
在这k个标签中出现次数最多的标签为新数据的标签。简单来说,未标记的样本类别由距离其最近的k个邻居投票来决定。
KNN的工作原理:
- 计算分类样本与其他训练样本的距离;【距离度量】
- 统计距离最近的k个邻居 【k值选择】
- k个邻居中出现次数最多的标签为样本的标签 【分类决策】
距离度量
计算距离有不同的公式,一般使用欧氏距离,还有曼哈顿距离,闵可夫斯基距离,切比雪夫距离,余弦距离等,有兴趣可以自己了解。
欧式距离:
d
=
(
x
1
−
x
2
)
2
+
(
y
1
−
y
2
)
2
d = \sqrt{(x1-x2)^2+(y1-y2)^2}
d=(x1−x2)2+(y1−y2)2
k值选择
k值对结果有重要影响,k值过小,训练的整体模型会变复杂,容易过拟合,k值大会涵盖大多数样本的特征,可能欠拟合。
分类决策
一般情况分类决策由多数表决,即由出现次数多的标签决定。
KNN算法步骤:
- 加载并整理数据;
- 计算待测样本到各训练集数据的距离,并从小到大排序;
- 确定并取出前k个值(即距离最小的k个值);
- 返回k个值中出现次数最多的标签;
- 待测样本即为该类别。
举个简单例子,电影分类问题。已知电影的两个个特征【打斗镜头和接吻镜头】,用knn算法求电影的标签【爱情片或动作片】

计算距离:

按算法步骤完成排序,将k定义为3,则取出[《He’s Not Really into Dudes》,《Beautiful Woman》,《California Man 》],可知出现次数最多的电影的标签为爱情片(三个都是爱情片)则未知电影为爱情片。
算法代码实例
knn处理的数据类型为:数值型和标称型。
//将上面的表格数据处理
/*
电影名称为[1,2,3,4,5,6]对应[《California Man》,《He’s Not Really into Dudes》,《Beautiful Woman 》,《Kevin Longblade 》,《Robo Slayer 3000》,《Amped II》];
同理两个特征[打斗和接吻]对应具体数值
类别[爱情,动作]对应[0,1].
*/
#导入必备包
import numpy as np
import math
#加载数据并整理数据
data=[[1,3,104,0],[2,2,100,0],[3,1,81,0],[4,101,10,1],[5,99,5,1],[6,98,2,1]]
data=np.array(data)
#求[?,18,90,?]
#求距离并排序
x=data[:,1:2]
y=data[:,2:3]
z=[18,90]
for i,j in zip(x,y):
distance=math.sqrt((z[0]-i)**2+(z[1]-j)**2)
test_distance.append(distance)
test_distance=[round(x,2) for x in test_distance]
print(test_distance)
结果:
[20.52, 18.87, 19.24, 115.28, 117.41, 118.93]
example=[]
for i,j in zip(data,target_distance):
x=np.append(i,j)
example.append(x)
example
结果:
[array([ 1. , 3. , 104. , 0. , 20.52]),
array([ 2. , 2. , 100. , 0. , 18.87]),
array([ 3. , 1. , 81. , 0. , 19.24]),
array([ 4. , 101. , 10. , 1. , 115.28]),
array([ 5. , 99. , 5. , 1. , 117.41]),
array([ 6. , 98. , 2. , 1. , 118.93])]
#k取3时,标签全为0,第四位为标签,0为爱情片,故未知电影为爱情片。
python的sklearn库实现knn算法(鸢尾花数据集):
from sklearn.datasets import load_iris #从数据集导入鸢尾花数据集
from sklearn.model_selection import train_test_split #导入训练集和测试集分割函数
from sklearn.neighbors import KNeighborsClassifier #导入knn分类器
#加载数据并整理
iris=load_iris()
#分割数据集为训练集和测试集(.data为特征,.target为标签,test_size为测试集比重)
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.3)
#构造分类器
knn=KNeighborsClassifier(n_neighbors=3) #n_neoghbors即为k
#训练模型
knn.fit(x_train,y_train)
#对测试集预测并对模型评分
score=knn.score(x_test,y_test)
print(score)
结果:
1.0
另外KNeighborsClassifier中提供了很多参数对模型处理:

KNeighborsClassifier对象也提供属性来操作模型:

用构造的模型预测样本
要预测样本首先知道训练集的数据结构,才能进行预测。
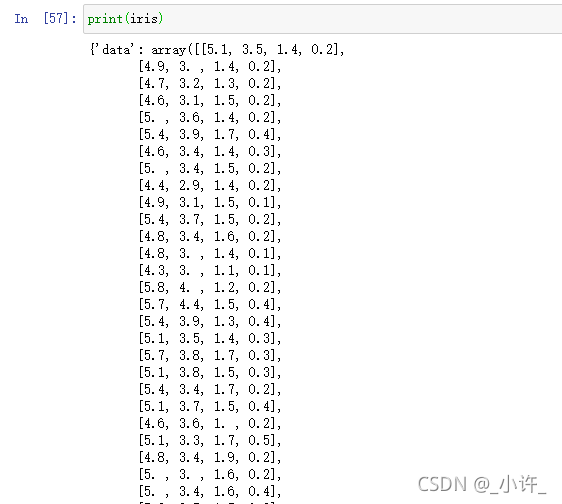

图中的iris的数据集包含了data和target分别表示特征和标签和其他,我们只用的上data和target,具体用法代码已经写出。
// 数据集特征
print(len(iris.data))
结果:
150
print(len(iris.target))
结果:
150
print(iris.data[:5])
结果:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
print(iris.target[5])
结果:
0
#可见特征和标签的长度一致,且对应,前5个的数据标签都为0.
#测试集的数据结构也要为同类型
a_data=[5,3.6,1.4,0.2] a_target=?
#a_data是list而iris.data是numpy下的array,进行数据转换
a_data=np.array(a_data).reshape(1,-1)
knn.predict(a_data)
结果:
array([0])
预测结果为0标签,于是发现a_data其实就是iris训练集的第5个数据,而第5个数据的标签是已知的即0,可见预测还是挺准的。
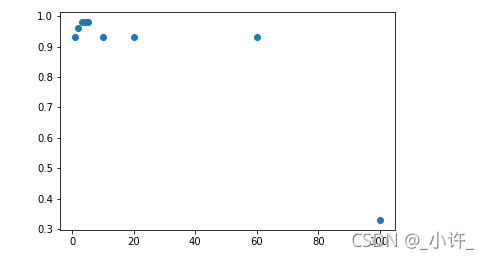
评分随k值的变化趋势
import matplotlib.pyplot as plt
import numpy as np
def function(k):
iris=load_iris()
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.3)
knn=KNeighborsClassifier(n_neighbors=k) #n_neoghbors即为k
knn.fit(x_train,y_train)
score=knn.score(x_test,y_test)
return round(score.tolist(),2)
k=[1,2,3,4,5,10,20,60,100]
score_=[]
score_.append(function(1))
score_.append(function(2))
score_.append(function(3))
score_.append(function(4))
score_.append(function(5))
score_.append(function(10))
score_.append(function(20))
score_.append(function(60))
score_.append(function(100))
#print(score_)
plt.scatter(k,score_)
plt.show()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/156338.html

