
机器学习概论
1. 什么是机器学习?
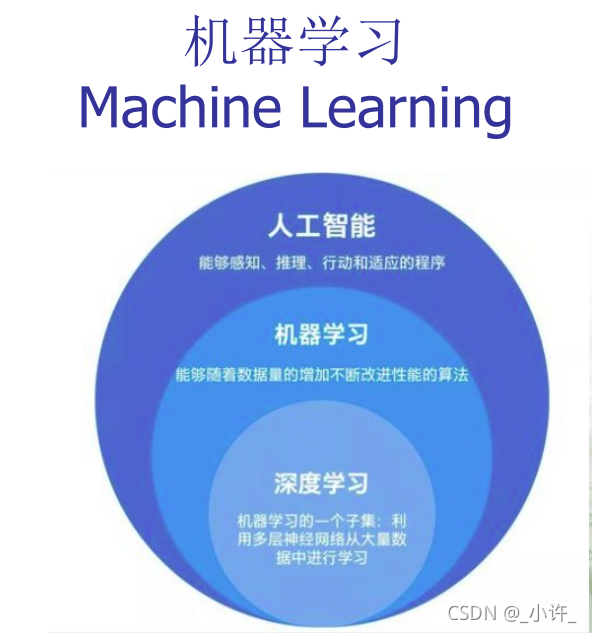
机器学习是计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能,以达到不需要外部明显的指示,而可以自己通过数据(数据驱动)来学习、建模,并且利用建好的模型和新的输入来进行预测的学科。
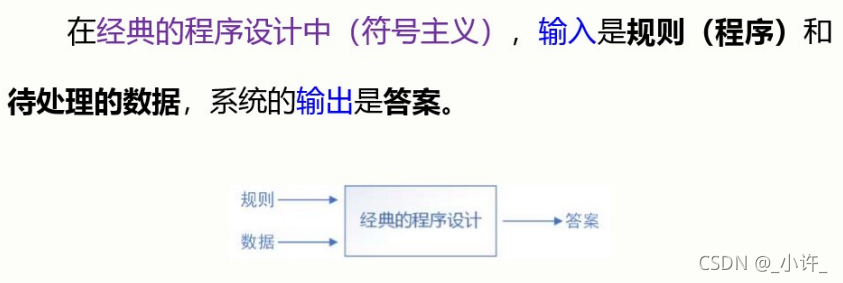
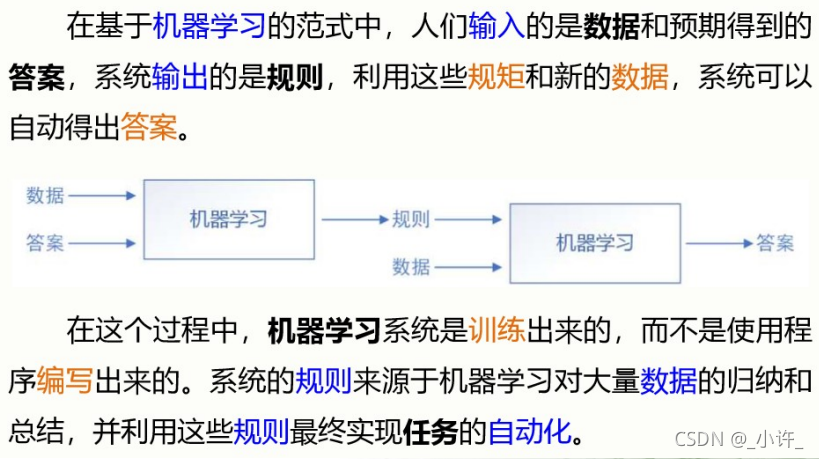
程序设计与机器学习
2. 机器学习分类
机器学习可分为有监督学习,无监督学习和半监督学习。有监督学习是有训练集和测试集的,通过训练集拟合函数即分类器,用测试集来测试数据;无监督学习是只有数据集,通过数据集的特点将特征相似的聚类;半监督学习即使两者的结合。
3. 机器学习三要素
输入数据
预期输出实例
衡量算法效果的方法
4. 分类,聚类,回归,降维
机器学习可分为四大块,即分类,回归,聚类,降维。前两者使有监督学习,后两者使无监督学习。
分类:通过向模型输入各种训练集,产生函数即分类器,对未分类的测试集用分类器进行分类。主要算法有,K-邻近算法,决策树算法,贝叶斯算法和支持向量机算法。
回归:通过向模型输入训练集,得到一条回归线,反应自变量和因变量的关系,主要实现算法有,线性回归,逻辑回归。
聚类:对数据集分析,根据数据集的特点将特征相似的数据聚合到一起,形成不同的类别。
降维:利用正交变换对一系列可能的变量进行线性变换,将数据映射到维度更低的空间便于分析和计算。
5. Python 语言的优势
Python作为实现机器学习算法的编程语言:
(1) Python的语法清晰;
(2) 易于操作纯文本文件;
(3) 使用广泛,存在大量的开发文档。
python提供大量的库方便进行计算
(1)科学函数库SciPy和NumPy使用底层语言(C和Fortran)编写,提高了相关应用程序
的计算性能。
(2)绘图工具Matplotlib协同工作。Matplotlib可以绘制2D、3D图形,也可以处理科学研究中经常使用到的图形.
(3)Pandas 数据分析工具,是Python中进行数据分析的库,它具有以下功能:生成类似Excel表格式的数据表,并对数据进行修改操作;从不同的数据源中获取数据,例如:SQL Server, Excel表格, CSV文件, Oracle等;
(4)Scikit learn 也简称sklearn,是机器学习领域当中最知名的python模块之一。sklearn包含了很多机器学习的方式。以后的学习主要就是用到机器学习库sklearn。
sklearn库简介
- Classification 分类
- Regression 回归
- Clustering 非监督分类
- Dimensionality reduction 数据降维
- Model Selection 模型选择
- Preprocessing 数据与处理
- datasets 数据集库
使用sklearn可以很方便地让我们实现一个机器学习算法。一个复杂度算法的实现,使用sklearn可能只需要调用几行API即可.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/156339.html

