
KNN算法简述
1、算法概述
KNN算法的核心思想是一个样本空间中k个最相邻的样本中最多的类别是待测数据的类别,并有同样的特征。
2、算法介绍
当待测数据与数据集有相同的属性时,可以用knn算法判断是否为同一类别,具体计算,待测样本到数据集中每个样本的距离。有k决定范围,考虑k个距离样本距离最近的数据,其中多数属于某个类别则样本属于属于该类别。
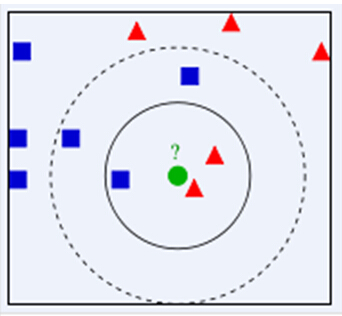
如上面图所示,当k=5时,绿色属于红三角类别,当k=7属于蓝方形类别,说明k值很大程度上决定样本类别。
3、工作原理
1.计算待分类数据与其他物体的距离。
2.统计最近的k个邻居。
3.待测类别则为样本中最多的类别。
4、步骤
1.加载数据集
2.计算待测数据到到个数据的距离
3.将计算的距离从小到大排序
4.确定k值,找最小的k个数据
5.计算k个数据中出现频次最高的类别
6.返回该类别即为待测数据的类别
距离公式

5、代码小试
//训练集样本
movie_data={"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"]
} //字典类型
// 待测样本
test_data={"唐人街探案":[23,3,17,"?"]}
//求训练集到测试集的距离
import math
x=[23,3,27]
test_distance=[]
for key,v in movie_data.items():
d=math.sqrt((x[0]-v[0])**2+(x[1]-v[1])**2+(x[2]-v[2])**2) //欧式距离计算公式
test_distance.append([key,round(d,2),v[3])
print(test_distance)
// 对距离排序
test_distance.sort(key=lamba dis:dis[1])
print(test_distance)
// 通过k值确定样本范围
test1_distance=test_distance[:5]
print(test1_distance)
// 找出样本中出现最多的类别即为待测数据类别
types=[["喜剧片",["动作片"],["爱情片"]]
for i in test1_distance:
for j in types:
if i[2]=j[0]:
j[1]+=1
print(types)
// 输出待测样本类别
types.sort(key=lamba d:d[1] reverse=True)
print(types[0][0])
最后结果应该数输出的喜剧片。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/156351.html

