
Elasticsearch 概述及安装
1. Elasticsearch 是什么
Elastic Stack 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack),能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elastcisarch(ES) 是一个开源的高扩展的分布式全文搜索引擎,它是整个 Elastic Stack 技术栈的核心,可以近乎实时的存储、检索数据。同时还具有良好的扩展性,可以部署到上百台服务器上,处理 PB 级的数据。
2. 全文搜索引擎
事实上,可以将现实世界中的数据分为结构化数据和非结构化数据两大类。其中,结构化数据通常是指有固定格式和有限长度的数据,可以用关系型数据库中的表存储;非结构化数据也称为全文数据,是不定长且无固定格式的数据,包括常见的文档、文本、邮件、图像格式的数据。
对于结构化数据,可以通过 SQL 查询直接从关系型数据库中查找,而对于非结构化数据,关系型数据库搜索不能提供好的支持。
对于传统数据库而言,进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 语句进行优化,效果也不尽如人意。虽然建立了索引可以提高查询效率,但是对于插入和修改操作都会重新构建索引,维护麻烦。
在生产环境中,当使用常规的搜索方式碰到以下的情况,搜索性能会变得非常差:
- 搜索的数据对象是大量的非结构化文本数据
- 文本记录量达到数十万或数百万甚至更多
- 支持大量交互式文本的查询
- 需求非常灵活的全文搜索查询
- 对高度相关的搜索结构有特殊需求,但是没有可用的关系数据库可以满足
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况
为了解决结构化数据搜索和非结构化数据搜索性能的问题,就需要更加专业、健壮、强大的全文搜索引擎。
🎁全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
3. Elasticsearch And Solr
Lucene 是 Apache 软件基金会 Jakarta 项目组的一个子项目,它作为 Elasticsearch 的核心,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。但 Lucene 只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来进行应用。
目前市面上流行的搜索引擎软件,主流的有两款:Elasticsearch 和 Solr, 这两款都是基于 Lucene 搭建的,是可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作 修改、添加、保存、查询等都十分类似。
在使用过程中,一般都会将 Elasticsearch 和 Solr 这两个软件对比,然后进行选型。这两个搜索引擎都是流行的,先进的的开源搜索引擎。它们都是围绕核心底层搜索库 – Lucene 构建的。但它们又是不同的,它们分别有各自的特点:
| 特征 | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| 社区和开发者 | Apache 软件基金和社区支持 | 单一商业实体及其员工 |
| 节点发现 | Apache Zookeeper,在大量项目中成熟并且经过实战测试 | Zen 内置于 Elasticsearch 本身,需要专用的主节点才能进行分裂脑保护 |
| 碎片放置 | 本质上是静态,需要手动工作来迁移分片,从 Solr7 开始-Autoscaling API 允许一些动态操作 | 动态,可以根据群集状态按需移动分片 |
| 高速缓存 | 全局,每个段更改无效 | 每段,更适合动态更改数据 |
| 分析引擎性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据放置 |
| 全文搜索功能 | 基于 Lucene 的语言分析,多建议,拼写检查,丰富的高亮显示支持 | 基于 Lucene 的语言分析,单一建议 API 实现,高亮显示重新计算 |
| DevOps 支持 | 尚未完全,但即将到来 | 非常好的 API |
| 非平面数据处理 | 嵌套文档和父子支持 | 嵌套和对象类型的自然支持允许几乎无限的嵌套和父子支持 |
| 查询 DSL | JSON(有限)、XML(有限)或 URL 参数 | JSON |
| 索引/收集领导控制 | 领导者安置控制和领导者重新平衡甚至可以节点上的负载 | 不可能 |
| 机器学习 | 内置-在流聚合之上,专注于逻辑回归和学习排名贡献模块 | 商业功能,专注于异常和异常值以及时间序列数据 |
4. Elasticsearch Or Solr
Elasticsearch 和 Solr 都是开源搜索引擎,那么我们在使用时该如何选择呢?
- Google 搜索趋势结果表明,与 Solr 相比,Elasticsearch 具有很大的吸引力,但这并不意味着 Apache Solr 已经死亡。虽然有些人可能不这么认为,但 Solr 仍然是最受欢迎的搜索引擎之一,拥有强大的社区和开源支持。
- 与 Solr 相比,Elasticsearch 易于安装且非常轻巧。此外,你可以在几分钟内安装并运行Elasticsearch. 但是,如果 Elasticsearch 管理不当,这种易于部署和使用可能会成为一个问题。基于 JSON 的配置很简单,但如果要为文件中的每个配置指定注释,那么它不适合您。总的来说,如果你的应用使用的是 JSON,那么 Elasticsearch 是一个更好的选择。
- Solr 拥有更大、更成熟的用户,开发者和贡献者社区。ES 虽拥有的规模较小但活跃的用户社区以及不断增长的贡献者社区。Solr 贡献者和提交者来自许多不同的组织,而 Elasticsearch 提交者来自单个公司。
- Solr 更成熟,但 ES 增长迅速,更稳定。
- Solr 是一个非常有据可查的产品,具有清晰的示例和 API 用例场景。 Elasticsearch 的 文档组织良好,但它缺乏好的示例和清晰的配置说明。
那么,到底是 Solr 还是 Elasticsearch?
- 由于易于使用,Elasticsearch 在新开发者中更受欢迎。一个下载和一个命令就可以启动一切。
- 如果除了搜索文本之外还需要它来处理分析查询,Elasticsearch 是更好的选择。
- 如果需要分布式索引,则需要选择 Elasticsearch. 对于需要良好可伸缩性和以及性能分布式环境,Elasticsearch 是更好的选择。
- Elasticsearch 在开源日志管理用例中占据主导地位,许多组织在 Elasticsearch 中索引它们的日志以使其可搜索。
- 如果你喜欢监控和指标,那么请使用 Elasticsearch,因为相对于 Solr,Elasticsearch 暴露了更多的关键指标。
5. Elasticsearch 应用案例
- GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码。
- 维基百科:启动以 Elasticsearch 为基础的核心搜索架构。
- SoundCloud:SoundCloud 使用 Elasticsearch 为 1.8 亿用户提供即时而精准的音乐搜索服务。
- 百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大 100 台机器,200 个 ES 节点,每天导入 30TB+ 数据。
- 新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
- 阿里:使用 Elasticsearch 构建日志采集和分析体系。
6. 安装 Elasticsearch
Elasticsearch 官方地址: https://www.elastic.co/cn/,截止到博客撰写之日,Elasticsearch 的最新版本为 8.2.0,但是这里我选择 7.8.0 版本。
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0

Elasticsearch 分为 Linux 和 Windows 版本,这里的安装演示以 Windows 版本为例,点击 WINDOWS sha 进行下载,由于 Elasticsearch 服务器在国外,在国内下载速度非常慢,博主已经将下载好的压缩包上传到 CSDN,大家可以根据需要点击链接进行下载。

Windwos 版本的 Elasticsearch 安装非常简单,解压即安装完毕,解压后的 Elasticsearch 的目录结构如下所示
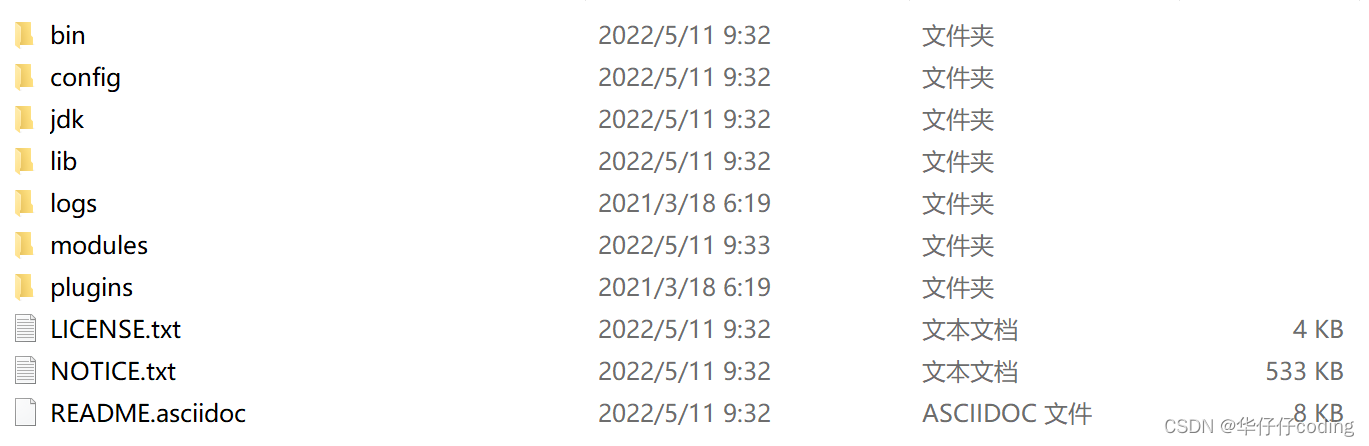
上图中的各个目录的含义如下所示
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置 JDK 目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务


其中,Elasticsearch 集群间组件的通信端口为 9300,而 9200 为浏览器访问的 HTTP 协议 RESTFUL 端口。
在启动过程中有如下事项需要注意:
- Elasticsearch 是使用 Java 开发的,且 7.8 版本的 ES 需要 JDK 1.8 及以上版本,默认安装包带有 JDK 环境,但是如果系统配置了 JAVA_HOME,那么使用系统默认的 JDK。
- 如果遇到双击启动窗口闪退的情况,可以尝试通过路径追踪错误,如果是 “空间不足”,需要修改 config/jvmoptions 配置文件,修改内容如下所示
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms1g # 堆空间初始大小
-Xmx1g # 堆空间最大大小
启动完成之后,便可以进行测试了,打开浏览器,输入访问地址 http://localhost:9200/,测试结果截图如下所示
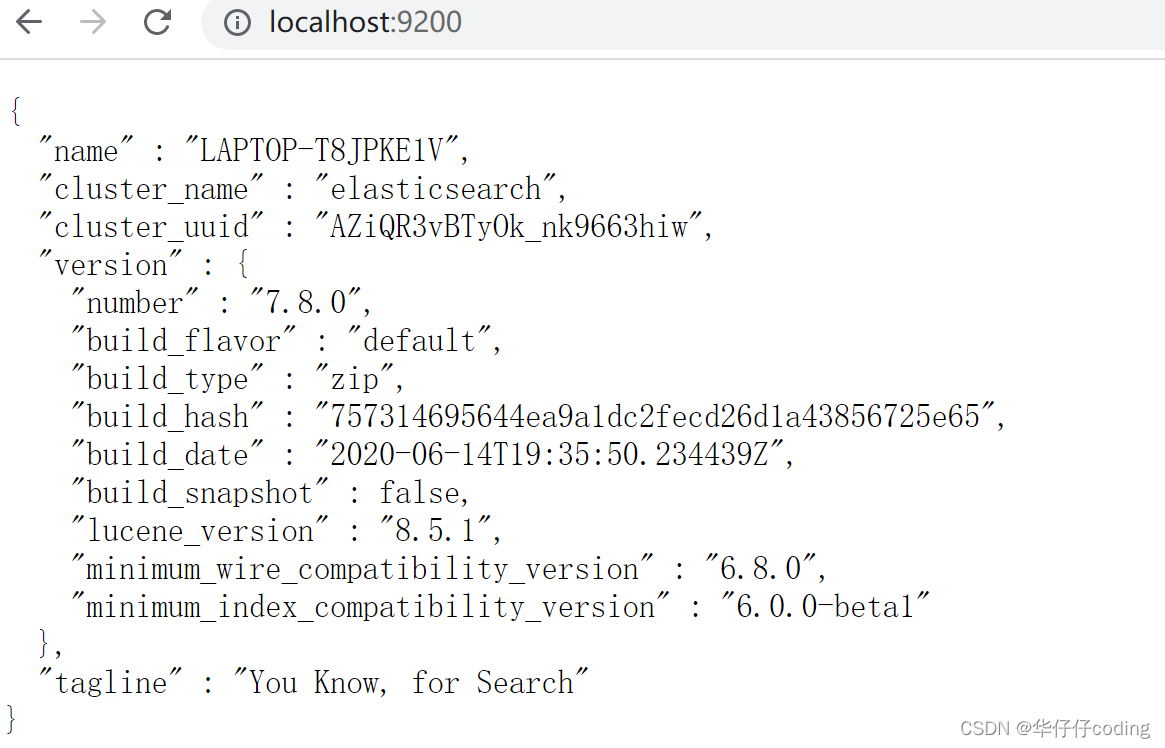
出现以上截图中的测试结果表明启动 Elasticsearch 成功!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/157027.html

