
分库分表的背景:
传统的将数据集中存储⾄单⼀数据节点的解决⽅案,在性能、可⽤性和运维成本这三⽅⾯已经难于满⾜互联⽹的海量数据场景。
随着业务数据量的增加,原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。
当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等,
此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
分库分表之垂直拆分
专库专用。一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面。如下图:
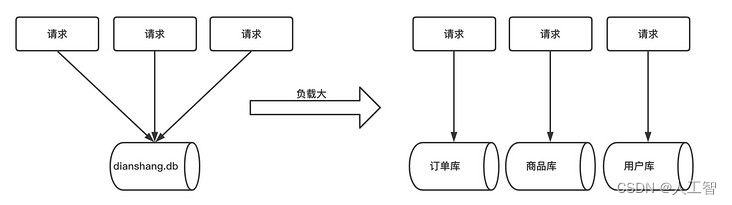
优点:
1、拆分后业务清晰,拆分规则明确。
2、系统之间整合或扩展容易。
3、数据维护简单。
缺点:
1、部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度。
2、受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3、事务处理复杂。
分库分表之水平切分
垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式。如下图:
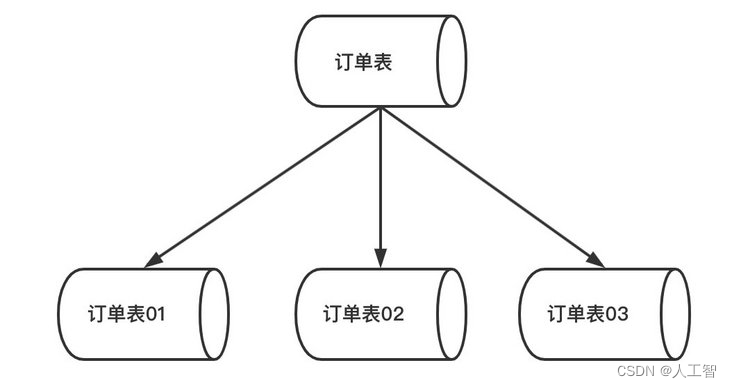
优点:
不存在单库大数据,高并发的性能瓶颈。
对应用透明,应用端改造较少。
按照合理拆分规则拆分,join 操作基本避免跨库。
提高了系统的稳定性跟负载能力。
缺点:
拆分规则难以抽象。
分片事务一致性难以解决。
数据多次扩展难度跟维护量极大。
跨库 join 性能较差。
1、容量瓶颈
从性能⽅⾯来说,由于关系型数据库⼤多采⽤ B+ 树类型的索引,
数据量超过一定大小,B+Tree 索引的高度就会增加,而每增加一层高度,整个索引扫描就会多一次 IO 。
在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;
MySQL单表可以存储10亿级数据,只是这时候性能比较差,业界公认MySQL单表容量在1KW以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
2、吞吐量瓶颈:
同时,⾼并发访问请求也使得集中式数据库成为系统的最⼤瓶颈。
在传统的关系型数据库⽆法满⾜互联⽹场景需要的情况下,将数据存储⾄原⽣⽀持分布式的 NoSQL 的尝试越来越多。
但 NoSQL 并不能包治百病,而关系型数据库的地位却依然不可撼动。
分表能够⽤于有效的数据量超过可承受阈值而产⽣的查询瓶颈, 解决MySQL 单表性能问题
分库能够⽤于有效的分散对数据库单点的访问量;
3、分库分表的问题
分库导致的事务问题
不过,由于目前采用柔性事务居多,实际上,分库的事务性能也是很高的
分库分表方案选择
互联网行业处理海量数据的通用方法:分库分表。 分库分表中间件全部可以归结为两大类型:
- CLIENT模式;
- PROXY模式;
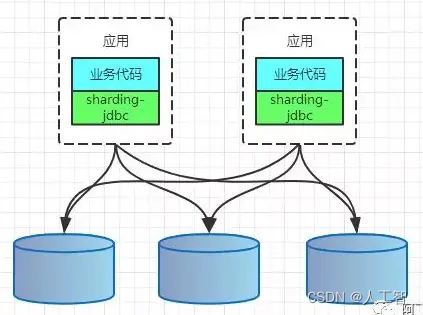
CLIENT模式代表有阿里的TDDL,开源社区的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已经支持了proxy模式)。架构如下:

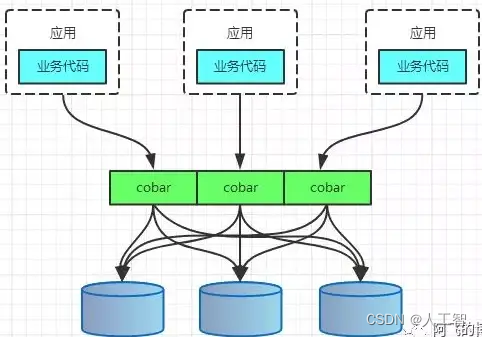
PROXY模式代表有阿里的cobar,民间组织的MyCAT。架构如下:
无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
3.分库分表思路(MYSQL)
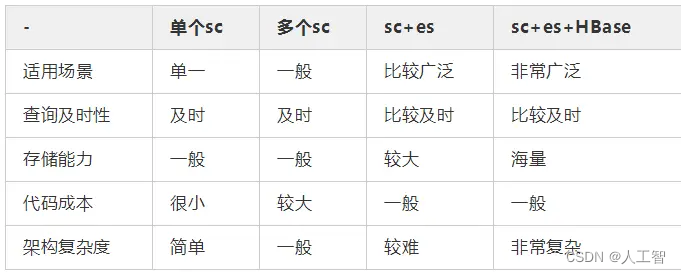
1、单个sharding column分库分表 ;
2、多个sharding column分库分表;
3、sharding column分库分表 + ES检索;
4.分库分表落地(MYSQL)
(1)选择合适的sharding column
分库分表第一步也是最重要的一步,即sharding column的选取,sharding column选择的好坏将直接决定整个分库分表方案最终是否成功。sharding column的选取跟业务强相关。
选择方法:分析你的API流量,将流量比较大的API对应的SQL提取出来,将这些SQL共同的条件作为sharding column。
选择示例:例如一般的OLTP系统都是对用户提供服务,这些API对应的SQL都有条件用户ID,那么,用户ID就是非常好的sharding column。
(2)冗余全量表和冗余关系表选择(订单表)
例如将一张订单表t_order拆分成三张表t_order、t_user_order、t_merchant_order。分别使用三个独立的sharding column,即order_id(订单号),user_id(用户ID),merchant_code(商家ID)。

冗余全量表:每个sharding列对应的表的数据都是全量的
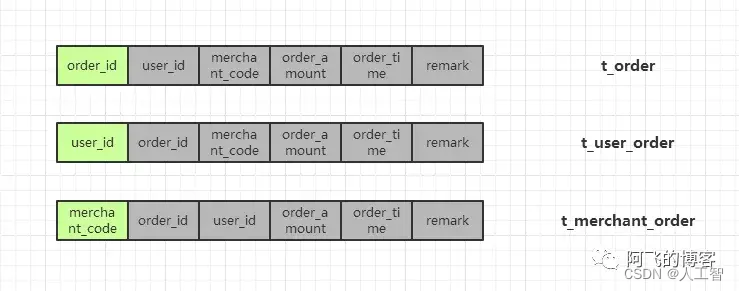
冗余关系表:只有一个sharding column的分库分表的数据是全量的,其他分库分表只是与这个sharding column的关系表。实际使用中可能会冗余更多常用字段,如用户名称、商户名称等。
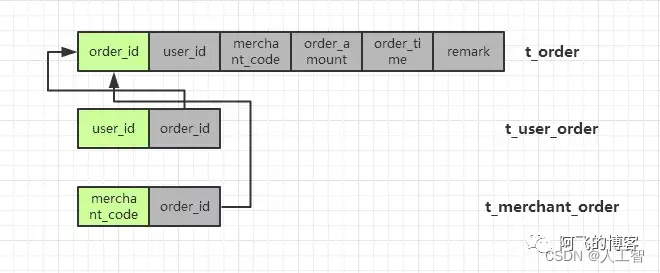
冗余全量表 VS 冗余关系表
- 速度对比:冗余全量表速度更快,冗余关系表需要二次查询,即使有引入缓存,还是多一次网络开销;
- 存储成本:冗余全量表需要几倍于冗余关系表的存储成本;
- 维护代价:冗余全量表维护代价更大,涉及到数据变更时,多张表都要进行修改。
总结:选择冗余全量表还是索引关系表,这是一种架构上的trade off(权衡),两者的优缺点明显,阿里的订单表是冗余全量表。
(3)单个sharding column分库分表示例(账户表)

一般账户相关API使用account_no为sharding column
(4)多个sharding column分库分表示例(用户表)
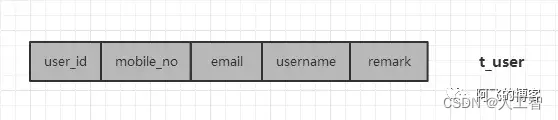
用户可以通过mobile_no,email和username进行登录,一些用户相关API又常使用user_id,所以sharding column选这4个字段。
(5)sharding column分库分表 + ES检索(模糊查询)
一些复杂查询,如果条件中没有sharding column的SQL,尤其是有些运营系统中的模糊条件查询,或者上十个条件筛选。例如淘宝我的所有订单页面,筛选条件有多个,且商品标题可以模糊匹配,这即使是单表都解决不了的问题,更不用谈分库分表了。
sharding column + es的模式,将分库分表所有数据全量冗余到es中,将那些复杂的查询交给es处理。以订单表为例:
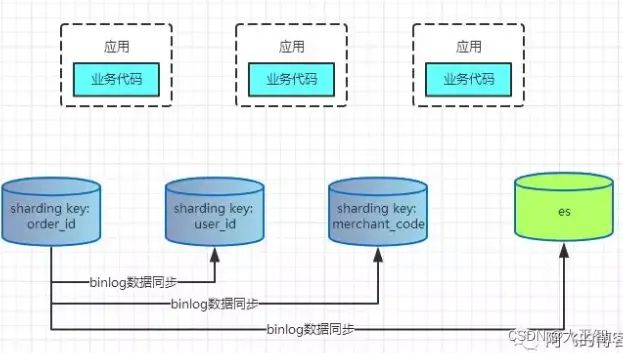
PS:多sharding column不到万不得已的情况下最好不要使用,建议采用单sharding column + es的模式简化架构。
5.全文索引思路(HBase)
- Solr+HBase
- ES+HBase
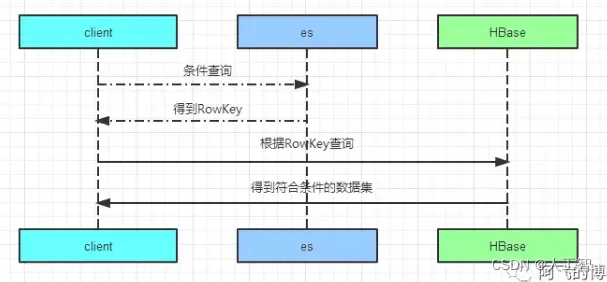
可能参与条件检索的字段索引到ES中,所有字段的全量数据保存到HBase中,这就是经典的ES+HBase组合方案,即索引与数据存储隔离的方案。Hadoop体系下的HBase存储能力我们都知道是海量的,而且根据它的rowkey查询性能那叫一个快如闪电。而es的多条件检索能力非常强大。这个方案把es和HBase的优点发挥的淋漓尽致,同时又规避了它们的缺点,可以说是一个扬长避免的最佳实践。
它们之间的交互大概是这样的:先根据用户输入的条件去es查询获取符合过滤条件的rowkey值,然后用rowkey值去HBase查询,后面这一查询步骤的时间几乎可以忽略,因为这是HBase最擅长的场景,交互图如下所示:
6.总结
对于海量数据,且有一定的并发量的分库分表,绝不是引入某一个分库分表中间件就能解决问题,而是一项系统的工程。需要分析整个表相关的业务,让合适的中间件做它最擅长的事情。例如有sharding column的查询走分库分表,一些模糊查询,或者多个不固定条件筛选则走es,海量存储则交给HBase。
做了这么多事情后,后面还会有很多的工作要做,比如数据同步的一致性问题,还有运行一段时间后,某些表的数据量慢慢达到单表瓶颈,这时候还需要做冷数据迁移。
Sharding-JDBC简介
Sharding-JDBC 是当当网开源的适用于微服务的分布式数据访问基础类库,完整的实现了分库分表,读写分离和分布式主键功能,并初步实现了柔性事务。
从 2016 年开源至今,在经历了整体架构的数次精炼以及稳定性打磨后,如今它已积累了足够的底蕴。
官方的网址如下:
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
- 一套开源的分布式数据库中间件解决方案。
- 有三个产品:JDBC、Proxy、Sidecar。
Sharding-JDBC的优势
- Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
- 可适用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
- 可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
- 理论上可支持任意实现JDBC规范的数据库。MySQL,Oracle,SQLServer和PostgreSQL等。
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
与常见开源产品对比
下表仅列出在数据库分片领域非常有影响力的几个项目:
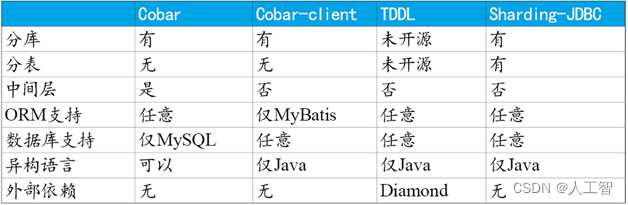
Cobar-Client、TDDL和Sharding-JDBC均属于客户端直连方案。
此方案的优势在于轻便、兼容性、性能以及对DBA影响小。其中Cobar-Client的实现方式基于ORM(Mybatis)框架,其兼容性与扩展性不如基于JDBC协议的后两者
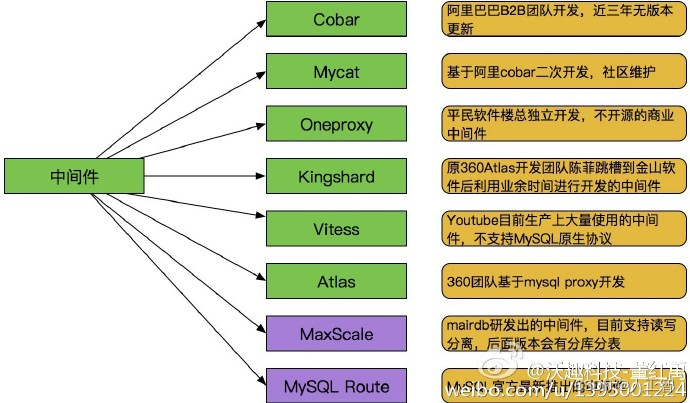
目前常用的就是Cobar(MyCat)与Sharding-JDBC两种方案
Sharding-JDBC 功能列表
- 分库 & 分表
- 读写分离
- 分布式主键
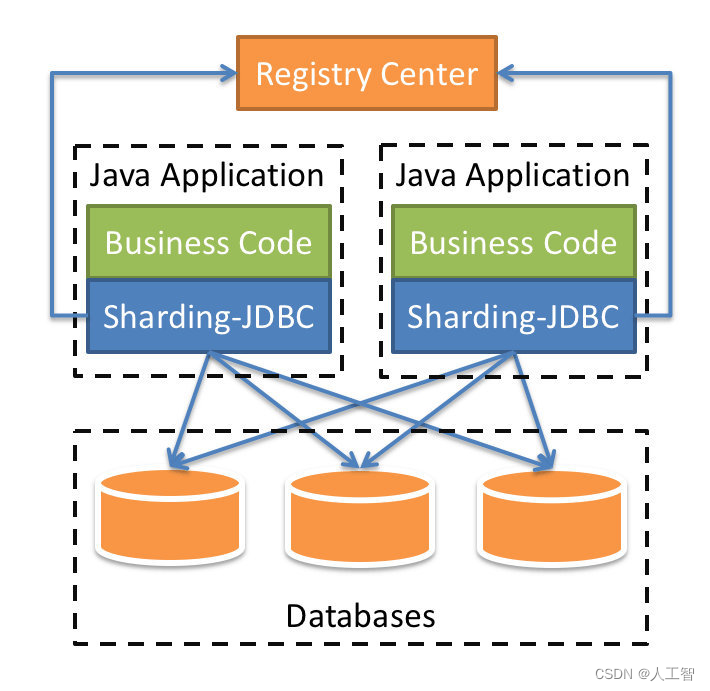
需要注意的是,分库分表并不是由 ShardingSphere-JDBC 来做,它是用来负责操作已经分完之后的 CRUD 操作。
Sharding-JDBC 分表实操
环境使用:Springboot 2.2.11 + MybatisPlus + ShardingSphere-JDBC 4.0.0-RC1 + Druid 连接池
具体 Maven 依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
按照水平分表来创建数据库
- 创建数据库 course_db
- 创建表 course_1 、 course_2
- 约定规则:如果添加的课程 id 为偶数添加到 course_1 中,奇数添加到 course_2 中。
SQL 如下:
create database course_db;
use course_db;
create table course_1 (
cid bigint(20) primary key ,
cname varchar(50) not null,
user_id bigint(20) not null ,
status varchar(10) not null
) engine = InnoDB;
create table course_2 (
cid bigint(20) primary key ,
cname varchar(50) not null,
user_id bigint(20) not null ,
status varchar(10) not null
) engine = InnoDB;
配置对应实体类以及 Mapper
/**
* @author 又坏又迷人
* 公众号: Java菜鸟程序员
* @date 2020/11/19
* @Description: Course实体类
*/
@Data
public class Course {
private Long cid;
private String cname;
private Long userId;
private String status;
}
mapper:
/**
* @author 又坏又迷人
* 公众号: Java菜鸟程序员
* @date 2020/11/19
* @Description: mapper
*/
@Repository
@MapperScan("com.jack.shardingspherejdbc.mapper")
public interface CourseMapper extends BaseMapper<Course> {
}
启动类配置 MapperScan
@SpringBootApplication
@MapperScan("com.jack.shardingspherejdbc.mapper")
public class ShardingsphereJdbcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingsphereJdbcDemoApplication.class, args);
}
}
配置 Sharding-JDBC 分片策略
application.properties 内容:
# sharding-jdbc 水平分表策略
# 配置数据源,给数据源起别名
spring.shardingsphere.datasource.names=m1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置数据源的具体内容,包含连接池,驱动,地址,用户名,密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
# 指定course表分布的情况,配置表在哪个数据库里,表的名称都是什么 m1.course_1,m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
# 指定 course 表里面主键 cid 的生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 配置分表策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show=true
测试代码运行
@RunWith(SpringRunner.class)
@SpringBootTest
class ShardingsphereJdbcDemoApplicationTests {
@Autowired
private CourseMapper courseMapper;
//添加课程
@Test
public void addCourse() {
Course course = new Course();
//cid由我们设置的策略,雪花算法进行生成
course.setCname("Java");
course.setUserId(100L);
course.setStatus("Normal");
courseMapper.insert(course);
}
}
Sharding-JDBC 实现水平分库
需求:
创建两个数据库,edu_db_1、edu_db_2。
每个库中包含:course_1、course_2。
数据库规则:userid 为偶数添加到 edu_db_1 库,奇数添加到 edu_db_2。
表规则:如果添加的 cid 为偶数添加到 course_1 中,奇数添加到 course_2 中。
create database edu_db_1;
create database edu_db_2;
use edu_db_1;
create table course_1 (
`cid` bigint(20) primary key,
`cname` varchar(50) not null,
`user_id` bigint(20) not null,
`status` varchar(10) not null
);
create table course_2 (
`cid` bigint(20) primary key,
`cname` varchar(50) not null,
`user_id` bigint(20) not null,
`status` varchar(10) not null
);
use edu_db_2;
create table course_1 (
`cid` bigint(20) primary key,
`cname` varchar(50) not null,
`user_id` bigint(20) not null,
`status` varchar(10) not null
);
create table course_2 (
`cid` bigint(20) primary key,
`cname` varchar(50) not null,
`user_id` bigint(20) not null,
`status` varchar(10) not null
);
配置分片策略
application.properties 内容:
# sharding-jdbc 水平分库分表策略
# 配置数据源,给数据源起别名
# 水平分库需要配置多个数据库
spring.shardingsphere.datasource.names=m1,m2
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置第一个数据源的具体内容,包含连接池,驱动,地址,用户名,密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
# 配置第二个数据源的具体内容,包含连接池,驱动,地址,用户名,密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456
# 指定数据库分布的情况和数据表分布的情况
# m1 m2 course_1 course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
# 指定 course 表里面主键 cid 的生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定分库策略 约定 user_id 值偶数添加到 m1 库,如果 user_id 是奇数添加到 m2 库
# 默认写法(所有的表的user_id)
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 指定只有course表的user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 指定分表策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show=true
测试代码运行
@Test
public void addCourse() {
Course course = new Course();
//cid由我们设置的策略,雪花算法进行生成
course.setCname("python");
//分库根据user_id
course.setUserId(100L);
course.setStatus("Normal");
courseMapper.insert(course);
course.setCname("c++");
course.setUserId(111L);
courseMapper.insert(course);
}
Sharding-Sphere的分表来实现多租户
首先先进行准备工作,为3个租户分别建表:
CREATE TABLE `t_order_0` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`order_number` varchar(32) DEFAULT NULL,
`money` decimal(18,4) DEFAULT NULL,
`postage` decimal(18,4) DEFAULT NULL,
`address` varchar(128) DEFAULT NULL,
`company` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
)
注意相同表结构的表需要建立三张,分别是t_order_0,t_order_1和t_order_2。
导入Sharding-Sphere依赖和数据库连接池druid的依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
注意这里引入的是druid而不是druid-spring-boot-starter,因为在高版本的sharding-sphere中,如果使用starter版本可能报错找不到url。
在application.yml中进行配置数据源及分表规则:
spring:
shardingsphere:
datasource:
names: ds0
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/tenant?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: hydra
password: 123456
sharding:
defaultDataSourceName: ds0
tables:
t_order:
actualDataNodes: ds0.t_order_$->{0..2}
tableStrategy:
standard:
shardingColumn: company
preciseAlgorithmClassName: com.cn.hydra.shardingtest.algorithm.OrderShardingAlgorithm
props:
sql:
show: true
对上面的参数进行说明:
datasource:这里因为还用不到分库,所以只进行了一个数据源的配置,如果存在多个则与ds0结构相同
defaultDataSourceName:选择默认数据源
tables:开始数据分片规则配置,注意下面的t_order是逻辑表名称
actualDataNodes :由数据源名加表名组成,以小数点分隔,多个表以逗号分隔,支持行表达式
tableStrategy:分表策略
standard:用于单分片键的标准分片场景
shardingColumn:分片列名称
preciseAlgorithmClassName:分片算法实现类,这个类由对我们自己实现,定义分片逻辑
props.sql.show:打印sql语句
创建一个枚举类,存放航空公司名称到租户id的对应关系,并写一个根据航空公司查找租户编码的方法,在后面分片规则中使用:
public enum Rules {
NANHANG(0,Arrays.asList("NANFANG","XIAMEN","CHONGQING")),
HAIHANG(1, Arrays.asList("SHOUDU","CHANGAN","JINPENG")),
GUOHANG(2,Arrays.asList("GUOHANG","SHENZHEN","SHANHANG"));
public static int searchCode(String company){
for (Rules value : Rules.values()) {
if (value.getCompany().contains(company)){
return value.getCode();
}
}
return -1;
}
private int code;
private List<String> company;
Rules(int code,List<String> company){
this.code=code;
this.company=company;
}
public int getCode() {
return code;
}
public List<String> getCompany() {
return company;
}
}
接下来是分表的核心,分片逻辑类需要实现PreciseShardingAlgorithm接口,并重写doSharding方法。之后对订单表的操作都会执行这里的doSharding方法选择实际执行sql的数据库表:
public class OrderShardingAlgorithm implements PreciseShardingAlgorithm<String> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {
int tenant = Rules.searchCode(preciseShardingValue.getValue());
String targetTable="t_order_"+tenant;
if (collection.contains(targetTable)){
return targetTable;
}
throw new UnsupportedOperationException("找不到租户:"+preciseShardingValue);
}
}
之前在yml中定义了分片列是company,因此这里通过preciseShardingValue能够拿到company的值。再根据上面枚举类的对应关系,可以获得租户id,最后返回真正执行sql的表名。(当然你可以在开租的时候给每个租户动态创建一张表,实现一键开租)
@Service
public class OrderService {
@Autowired
OrderMapper orderMapper;
public void createOrder(String company){
Order order=new Order();
order.setOrderNumber(UUID.randomUUID().toString().replaceAll("-",""));
order.setMoney(new BigDecimal(100));
order.setCompany(company);
orderMapper.insert(order);
}
public void getOrder(String company){
List<Order> orders = orderMapper.selectList(new LambdaQueryWrapper<Order>().eq(Order::getCompany, company));
orders.stream().forEach(System.out::println);
}
}
首先调用创建订单方法进行测试,发送一个请求:
http://127.0.0.1:8083/create?company=SHOUDU
查看执行结果的日志打印情况,被分为逻辑sql和实际执行的sql两部分。在逻辑sql语句中,可以看到使用的是逻辑表t_order,在实际sql中实际执行在t_order_1中,因为航空公司名称参数SHOUDU对应的租户编码是1,在分片算法中进行了实际表名的计算
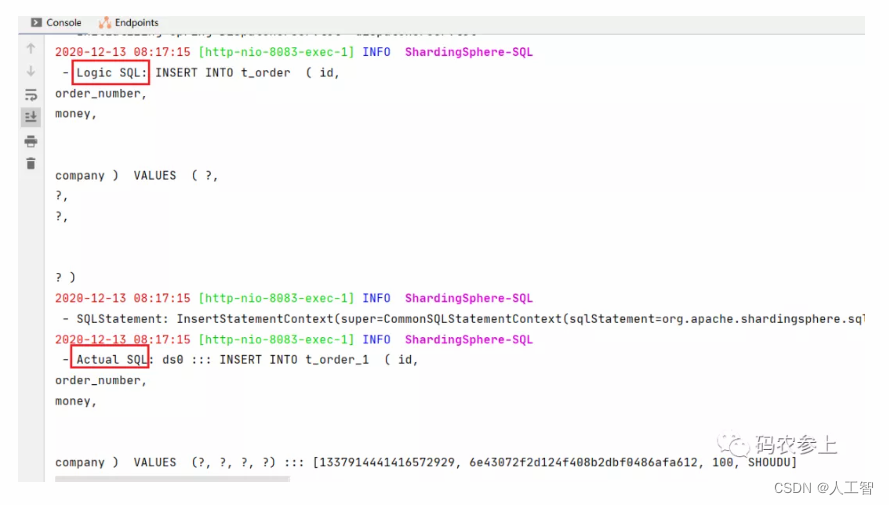
通过上面的实验,可以看出Sharding-Sphere的配置比较简单,在使用起来也是很方便的,通过客户端分片技术,能够很简单的实现基于分表的多租户需求。
参考:
- https://segmentfault.com/a/1190000038241298
- https://developer.aliyun.com/article/856828
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/157147.html

